前言
随着人工智能技术的不断进步,多模态成为备受瞩目的研究方向。多模态技术旨在融合不同类型的数据和信息,以实现更准确、高效的人工智能应用。有学者认为它代表了所有模型发展的最终趋势。这类模型旨在接受多种不同的输入方式,例如图像、文本、语音,并在某些情况下生成不同模态的输出。其中,CLIP(Contrastive Language-Image Pre-training)模型是多模态深度学习领域的一项具有里程碑意义的成果。CLIP模型提出了一种融合文本和图像数据的对比学习范式,通过将文本信息作为弱监督信号,用于监督相关的视觉任务训练,在相关的视觉任务中取得了较好的结果。
一、多模态的定义
多模态(Multimodality)是指利用两种或多种感官同时进行信息交互的方式。在人工智能领域,多模态技术通过融合来自不同感官的数据和信息,提升人工智能系统对复杂信息的理解和处理能力,从而提高性能和应用范围。
二、多模态研究内容
多模态研究涵盖多个方面,包括多模态数据采集、多模态数据融合和多模态学习等。
- 多模态数据采集
多模态数据采集指同时获取多种类型的数据和信息。在人工智能领域,这包括图像、音频、视频、文本等多样数据形式。通过使用不同传感器或设备,如摄像头、麦克风、雷达等,实现对多模态数据的综合采集。这种方法提供更丰富、全面的信息,有助于提高系统性能和准确性。
- 多模态数据融合
多模态数据融合旨在整合不同类型的数据和信息,以获取更准确、全面的信息。这些数据和信息涉及多个感官和传感器,如视觉、听觉、触觉等。融合方法包括特征融合和深度融合等。通过多模态数据融合,人工智能系统能更好地理解和处理复杂信息,提高性能和应用范围。
- 多模态学习
多模态学习是指在机器学习任务中同时利用多种类型的数据和信息。在人工智能领域,多模态学习涉及图像分类、语音识别、自然语言处理等多个方面。通过多模态学习,系统能够更充分地利用各种类型的数据和信息,提升性能和适用范围。
CLIP
1、简介
大部分计算机视觉任务通常依赖于预先定义的标签进行监督式训练,然而这种方式存在一定的局限,限制了模型的泛化能力和实用性。与此不同的是,自然语言处理领域已经通过自监督学习的方法,有效地利用大量语料数据进行模型训练。在这一启发下,本文提出了一种有潜力的方法,即通过直接从图像的描述文本中学习,以获取更多的监督信号。本文借助从互联网采集的4亿个图像和文本对数据,在这个思想的指导下,通过对比学习的方式执行图像与文本的匹配任务,将自然语言作为监督信号,从而学习图像的特征表示。在预训练完成后,该模型在给定一张图片和一组多样的文本描述时,能够判断哪个文本描述与图片最匹配。这一过程实现了模型在各种下游任务上的零样本迁移能力。在30个不同类型的计算机视觉下游任务上进行的基准测试中,本文的预训练模型CLIP无需额外数据即能够取得与完全监督基准线相当的效果,凸显了模型强大的迁移能力。
2. 零样本迁移学习
Zero-shot learning指的是模型能够对其从未见过的类别进行分类,使得机器具备推理能力,实现真正的智能。在传统监督学习中,模型通常需要在每个类别上具有大量标记样本的支持。然而,零样本学习的独特之处在于,它能够处理模型在训练过程中未见过的类别。
零样本学习通过学习不同类别之间的关系来进行分类。具体而言,模型在训练时学习到了从已知类别到新类别之间的映射或关联。这通常通过使用语义嵌入(semantic embeddings)或属性信息来实现。在测试阶段,当模型遇到新类别时,它能够利用先前学到的关系,将新类别映射到合适的类别标签,实现对该类别的分类。
零样本学习的应用场景包括在自然语言处理、计算机视觉等领域中,当存在大量已知类别但只有少数或没有样本可用于新类别时。这使得模型能够适应新类别,而无需重新训练整个模型。零样本学习克服了传统监督学习对大量标记样本的依赖,为模型处理新领域或未知类别提供了更大的灵活性。
假设小明和爸爸去了动物园。他们看到了马,爸爸告诉小明:“这就是马。” 接着,他们看到了老虎,爸爸解释说:“看,这种身上有条纹的动物就是老虎。” 最后,他们去看了熊猫,爸爸告诉小明:“你看,这熊猫是黑白色的。”
然后,爸爸给小明提出一个任务,让他在动物园里找一种他从未见过的动物,名字叫斑马,并告诉了小明关于斑马的信息:“斑马有着马的轮廓,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。” 最终,小明根据爸爸的提示,在动物园里找到了斑马。
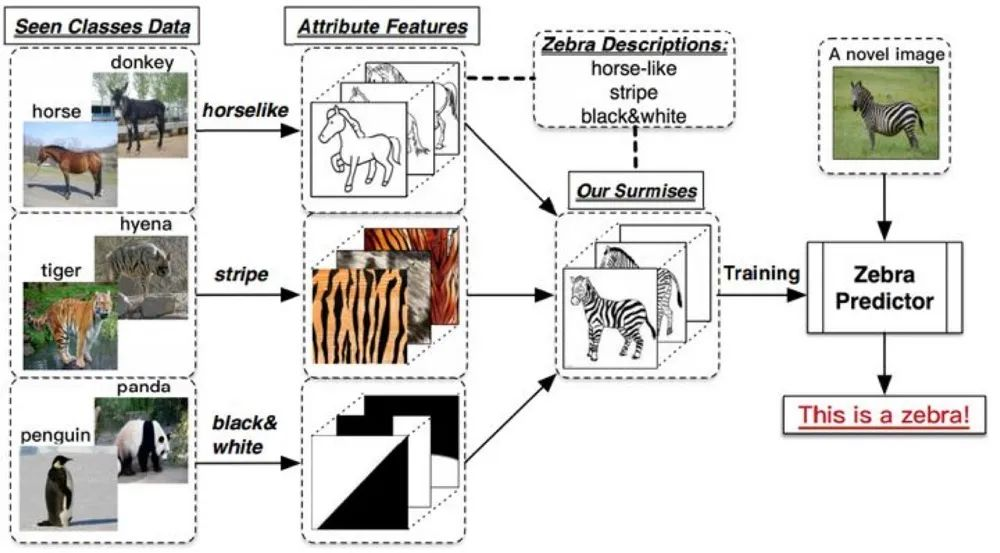
对于机器而言,Zero-shot learning的本质是根据一定的提示信息自动学习不同类别动物的特征,并进行总结归纳,以实现推理。这使得模型能够处理未知类别,展示出类似人类的学习和推理能力。
3.CLIP模型
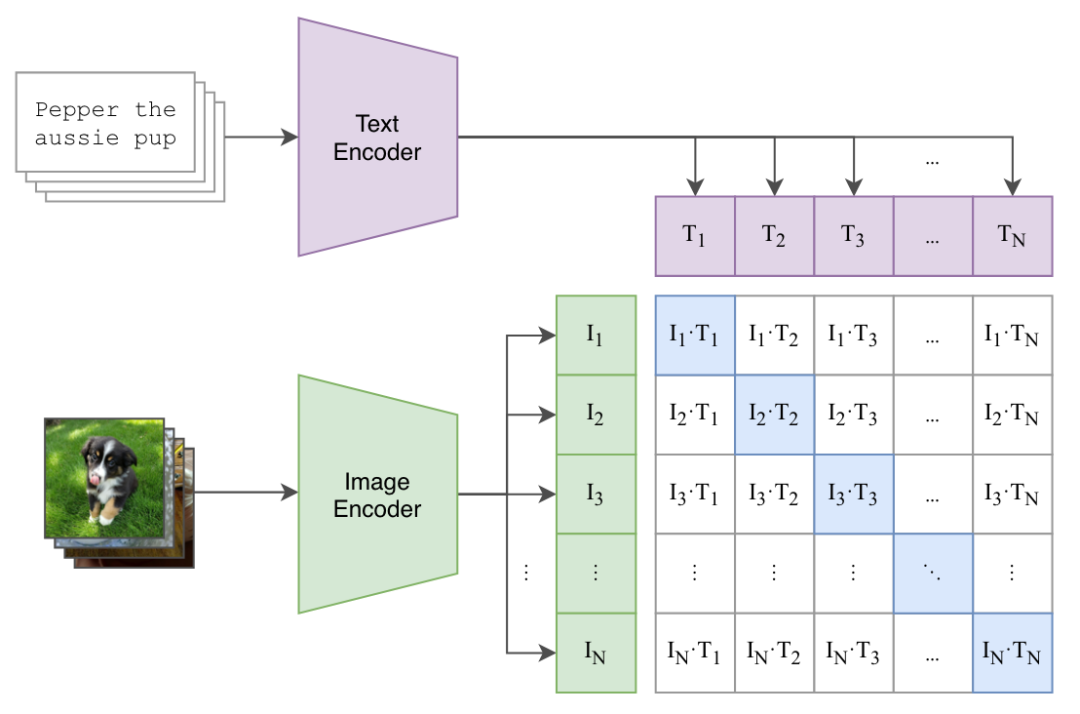
CLIP模型的核心思想是通过文本的弱监督信号训练一个优秀的视觉模型。该模型的输入包括图片和文字的配对数据,其中图片输入到Image Encoder获取相应的图像特征表征向量,文本输入到Text Encoder得到对应的文本特征向量。在每个训练批次中,包含n个图片-文本对,分别得到n个图片的特征和n个文本的特征,然后通过对比学习在这些特征上进行训练。特征矩阵中对角线上的元素表示正样本,即真实匹配的文本和图像对,而其他元素则表示负样本,共有n个正样本和n^2 - n个负样本。
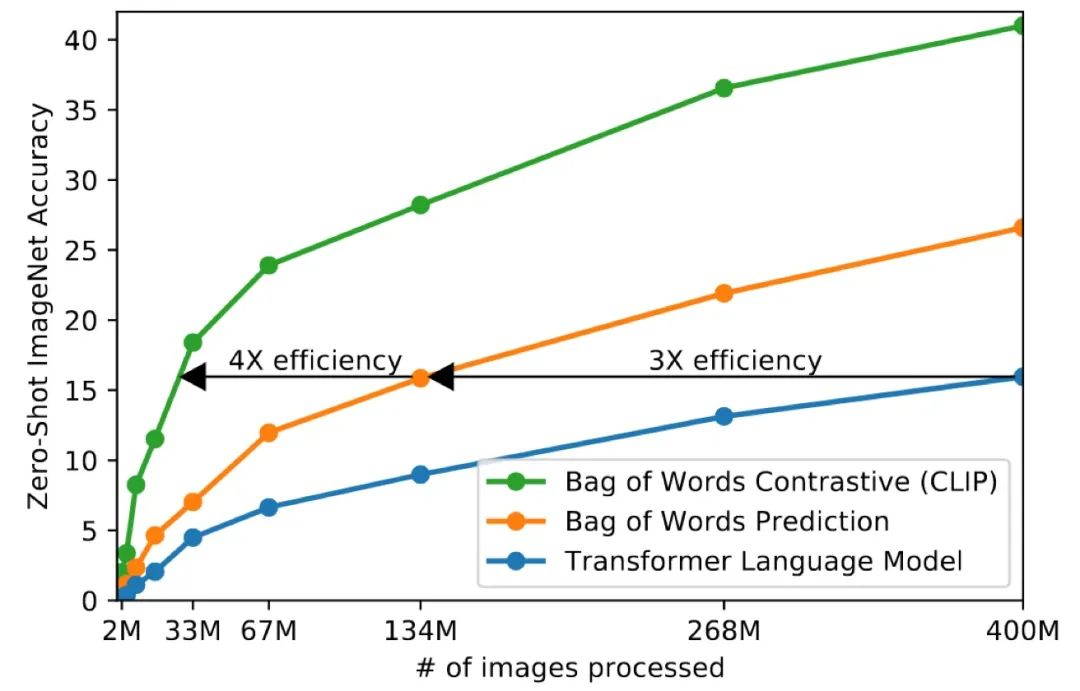
相对于预测性任务,例如图片预测文本,对比学习将任务转化为图片和文本的匹配问题,降低了任务的复杂性和难度。通过将任务简化为相似度度量问题,避免了涉及具体文本和图像概率分布的问题,从而显著提高了训练效率。CLIP模型通过对比学习进行模型训练,如图中所示,对比学习策略大幅提升了训练速度。
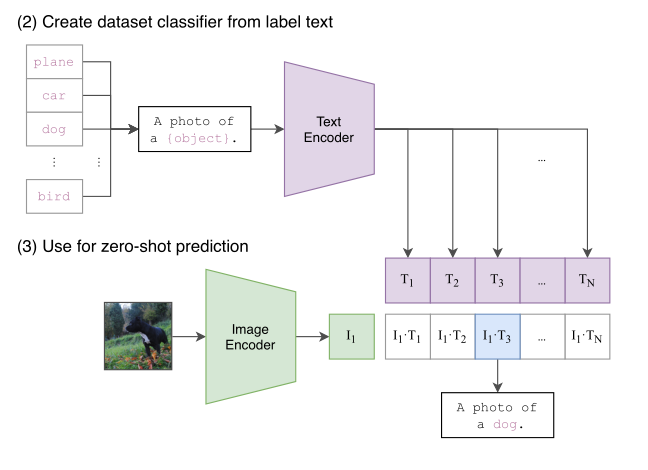
此外,CLIP模型设计了两个额外的阶段以实现更好的零迁移学习。首先,从标签文本创建数据集分类器,其过程涉及提示学习对文本进行修饰,然后进行编码以及通过Image Encoder获取的图像编码向量进行相似性评估,得到相应的标签。
其次,在零迁移学习阶段,通过对比学习来评估文本特征向量和图像特征向量的相似度。在提示学习中,采用了“A photo of a {object}”这样的提示模板,将原始ImageNet图片数据的标签填入花括号中生成完整的句子。这种方式符合了模型在预训练时文本端输出是句子的要求,并更符合互联网文本的特征。添加提示模板有助于模型挖掘更深层次的信息,作者设计了80个模板,其中一些包含更丰富的信息,有助于模型更好地区分图片中的物体。

最后的评估阶段使用对比学习来比较文本特征向量和图像特征向量的相似度。需要注意的是,由于文本和图像两者的分布空间差异较大,它们在特征提取和编码之后所在的表示空间也存在差异。因此,在进行相似度评估之前,需要分别设置两个投影头W_i和W_t,并采用L2正则化操作,以尽可能整合图片和文本的表征子空间。

4.实验
在实验分析中,作者对CLIP模型的性能进行了详细对比,主要关注了其强大的迁移学习能力、模型的稳定性和鲁棒性,以及可能存在的数据泄露问题。以下是部分实验内容的介绍,包括零样本学习(Zero-shot)、少样本学习(Few-shot linear probing)以及使用全部数据进行线性探测(Linear probing)这三个方面。
4.1 零样本学习(Zero-shot Classification)
在零样本分类推理中,CLIP模型的输入是一张图片。对于每个可能的分类标签,使用句子模板构建描述文本,例如"A photo of {label}"。通过对图像和描述文本进行编码,得到它们的嵌入特征。随后,计算图像嵌入特征与每个标签嵌入特征之间的余弦相似度,并选择具有最高相似度的标签作为预测的分类结果。此过程中,句子模板被称为“prompt”(提示),而对prompt的设计被称为“prompt engineering”。
CLIP模型在这个任务中的创新之处在于可以自由设置不同的分类标签,打破了传统分类问题中预先定义标签类别的范例。对于类别数量和内容,CLIP没有固定限制,这使得它在处理具有不同类别的问题时更加灵活。
4.2 零样本 CLIP
通过在27个数据集上比较零样本 CLIP 和在 ImageNet 数据上预训练的 ResNet50 线性探测的性能,结果显示 CLIP 在16个数据集上优于基于 ResNet-50 特征的完全监督线性分类器。然而,在某些复杂或抽象的数据集上,如卫星图像分类和淋巴结转移检测,CLIP的表现相对较差,这表明处理这些复杂数据集时通常需要一定的先验知识。
此外,在 MNIST 数据集上,CLIP的分类准确率仅为 88%。作者分析了CLIP的训练数据,发现在 4 亿个样本中几乎没有与 MNIST 相似的数据,这表明 CLIP 在处理域外数据时存在泛化困难的问题。
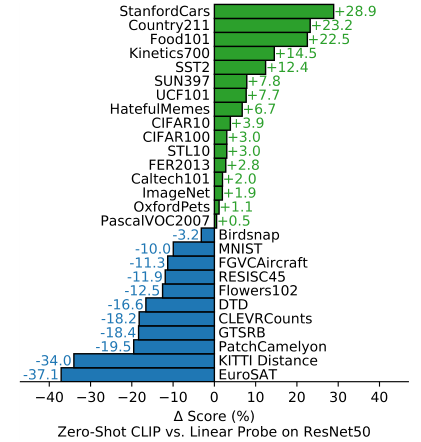
4.3 少样本学习(Few-shot CLIP)
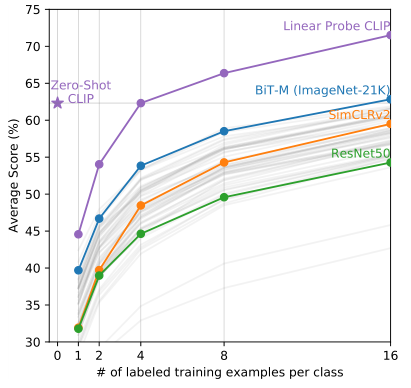
CLIP在复杂任务上的表现相对较弱,因此作者探讨了向CLIP提供少量样本是否能够改善其性能。Few-shot CLIP的表现明显超越了当前公开性能最佳的模型BiT-M,表明当CLIP获得少量样本用于学习时,其在处理复杂任务上的性能有望显著提升。
在少量样本的情况下,Few-shot CLIP的性能高于零样本情况,但在提供一个或两个样本的情况下,性能低于零样本情况,这是一个有趣的现象。作者解释称,零样本分类器类似于已经训练好的最终分类器,而在进行线性探测时,由于需要放弃文本编码器,每个类别只有一个标注样本可能不足够,初始性能可能会下降。
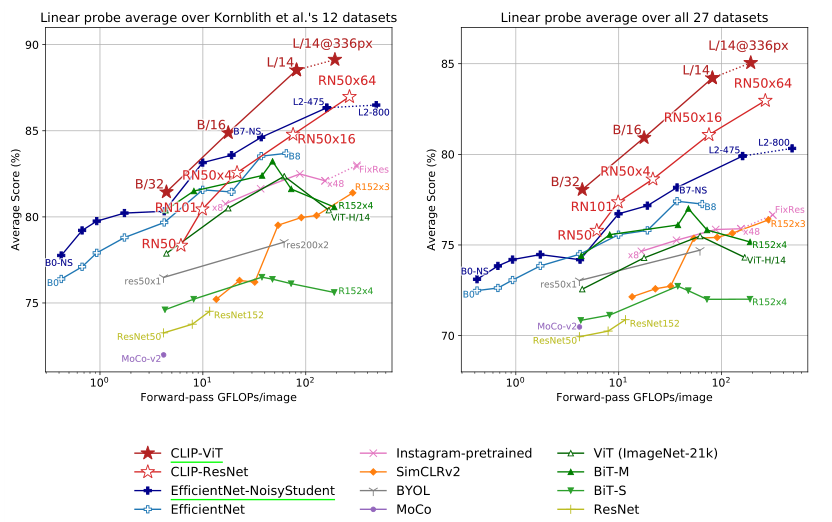
4.4 线性探测 CLIP 性能
在使用全部下游任务数据进行线性探测的实验中,CLIP表现出色,这加强了其在迁移学习方面的优势。




)







)



、RocketMQ消息重复消费问题)
)

