前言
在当今大数据时代,搜索引擎已经是许多应用的核心组件之一,近年随着大模型以及AI技术(如:自然语言处理NLP)的流行,这些技术的结合将会创造出更多的应用场景,比如:电商商品搜索、图像识别、非结构化数据向量化等
本博客将介绍如何使用 Elasticsearch8.x 结合 OpenAI 提供的强大 CLIP 模型构建一个生产环境可用的向量搜索引擎,它不仅能够通过关键字匹配搜索,还可以通过向量相似度搜索,从而实现更智能和灵活的搜索体验,先上效果图
环境准备
Elasticsearch 8 及 Knn Search 介绍
在老版本Elasticsearch 7.x 中,KNN(K-Nearest Neighbors)插件默认并不是包含在其核心功能中的,需要手动安装 KNN 插件,而 Elasticsearch 8.0+ 则默认集成了 Knn Search 功能
接下来我们将了解如何配置和使用 Knn Search,以及它如何与 CLIP 模型集成
Elasticsearch8.x安装教程
Knn相似度查询官方文档
OpenAI CLIP 模型介绍
CLIP模型是 OpenAI 公司在 2021 年初发布的用于匹配图像和文本的预训练神经网络模型,CLIP模型的训练数据收集了约4亿张图片和文本信息进行自监督学习,使它拥有强大的特征抽取能力,在多模态研究领域堪称经典之作
本案例将重点演示两个子模型
clip-vit-base-patch32
clip-vit-base-patch32 是一个在视觉和语言任务中表现出色的模型,它使用 Vision Transformer (ViT) 架构,并经过大量的互联网数据训练,可以将图像和文本映射为统一的向量空间,这使得我们可以使用相同的向量空间进行图像和文本的搜索,为跨模态搜索提供了强大的支持
clip-ViT-B-32-multilingual-v1
clip-ViT-B-32-multilingual-v1 是一个支持多语言的 CLIP 模型。它继承了 clip-vit-base-patch32 的优秀特性,同时具备对多语言文本和图像的强大处理能力,对于多语言搜索应用程序,这个模型是一个理想的选择
图片向量化
图片向量化采用clip-vit-base-patch32模型对图片进行矢量计算,使用Dataset进行图片加载,迭代图片返回图片编号、图片路径、图片文件
from torch.utils.data import DataLoader, Dataset
# 定义图片目录
IMG_PATH = Path(__file__).resolve().parents[1] / "images"
# DataSet类型
class ImageDataset(Dataset):def __init__(self):self.image_files = list(IMG_PATH.glob("*.png"))def __len__(self):return len(self.image_files)#迭代返回图片编号、路径、图片def __getitem__(self, idx):image_file = self.image_files[idx]image_id = image_file.name.split(".")[0]image = utils.pil_loader(image_file)image_url = image_file.namereturn image_id, image_url, image
本地图片矢量计算
def get_image_features(image):model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")inputs = processor(images=images, return_tensors="pt")image_features = self.model.get_image_features(**inputs)image_features /= image_features.norm(dim=-1, keepdim=True)image_features = image_features.tolist()return image_features
创建ES索引,这里向量索引定义为 index_image_search,"dims":512 表示字段的向量维度为512,"similarity":"l2_norm" 表示使用 L2 范数作为相似度计算的方法,L2 范数也被称为欧氏距离
"mappings": {"properties": {"feature_vector": {"type": "dense_vector","dims": 512,"similarity": "l2_norm"},"image_path": {"type": "keyword",}}}
组装ES文档和向量数据,批量插入到 ES
from elasticsearch.helpers import bulk
#循环迭代图片集合
def define_data():dataloader = DataLoader(ImageDataset(), batch_size=64)for batch in tqdm(dataloader):image_ids, image_urls, images = batchimage_features = get_image_features(images)batch_size = len(image_ids)for i in range(batch_size):yield {"_index": "index_image_search","_id": image_ids[i],"image_path": image_urls[i],"feature_vector": image_features[i],}
# 批量插入
def bulk_ingest(self, chunk_size=128):return bulk(self.client, generate_data(), chunk_size=chunk_size, ignore_status=500)
至此以上步骤完成了对素材图片的向量化存储,接下来我们将启动一个python web页面来演示图片搜索功能
Streamlit 构建 Web 搜索页面
为了展示构建的搜索引擎,我们将使用 Streamlit 框架构建一个简单而强大的 Web 搜索页面,Streamlit 的简洁性和实时性使得构建交互式搜索界面变得非常容易
案例中页面表单元素组件主要包括:
- 搜索类型(文搜图/图搜图)
- 向量模型
- 搜索数量
- 搜索文本或图片地址

总结
使用过程中我们发现clip-vit-base-patch32模型对部分中文的支持效果不是很好,所以我们引入了clip-ViT-B-32-multilingual-v1模型,实践下来它对中文的识别效果还是不错的,毕竟其具备支持多语言文本的解析能力。当然,如果场景中只用到英文来搜索,那么clip-vit-base-patch32模型足够了
其它语言模型可在官网搜索下载:Hugging Face
案例展示
下面给出几组搜索对比结果图:
Model:ViT-B-32-Multi/ViT-B-32
搜索词:不见啄木鸟,但闻啄木声


Model:ViT-B-32-Multi/ViT-B-32
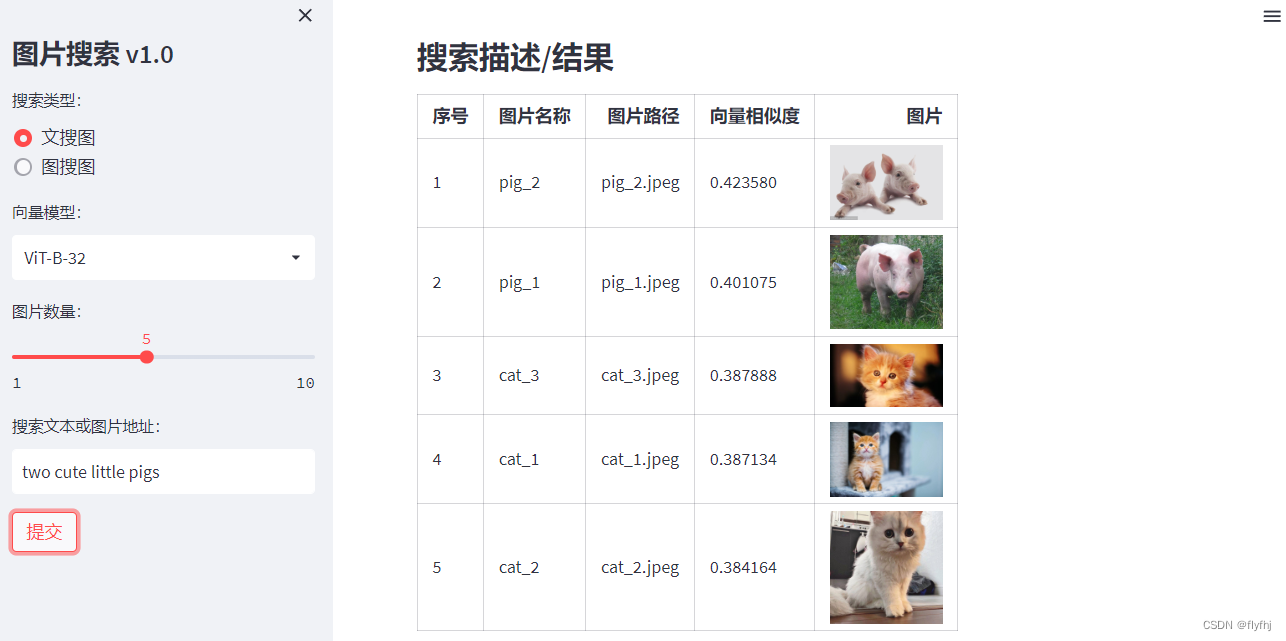
搜索词:two cute little pigs


Model:ViT-B-32-Multi/ViT-B-32
搜索词:かわいい2匹の子豚

图片搜索

欢迎大家讨论学习(完)
、RocketMQ消息重复消费问题)
)




)
)







)
)


