1. Pycharm连接远程服务器
1.1 进入配置页面
Pycharm菜单栏,如下图所示,依次点击 Tools -> Deployment -> Configration…
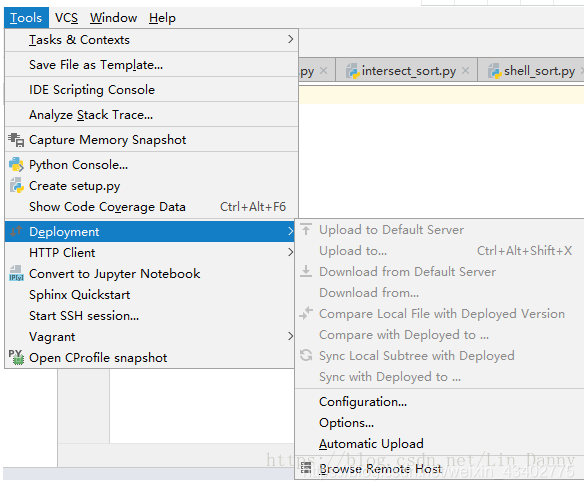
1.2 配置连接服务器
如下图。name随便写个就行。
Connection下,协议最好选择sftp,接下来填写服务器主机IP,用户名,密码。
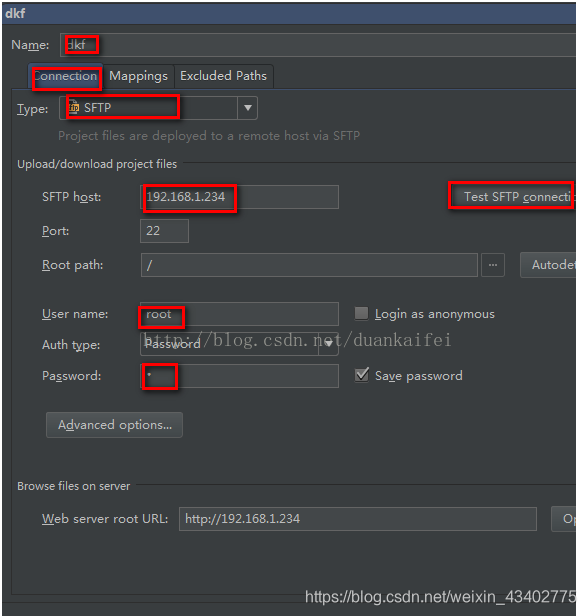
点击Test SFTP connection会发现,成功
2.1 将Python解释器设置为远程服务器上的
在菜单栏,File -> Settings… -> Project ×× -> Project Interpreter,点击右侧 Add按钮,添加解释器。
这里写图片描述
选择SSH Interpreter,填写服务器的 Host 地址,端口Port,用户名Username,填好后,下一步Next。
填写密码 Password,下一步Next。
选择远程服务器上Python解释器的位置,服务器上的远程同步文件夹Sync folders,可以选择多个。如果不知道Python安装在哪,可以远程连接服务器后,使用 命令 which python 找到Python安装位置。
这里写图片描述
Finish,配置结束。该项目现在使用的就是远程服务器上的Python解释器了。以后的项目若想/不想使用该解释器,手动更改解释器即可。


 must match the size of tensor b (3) at non-singleton)

 getattr() setattr() 函数使用)


![Pytorch RuntimeERROR: Given groups=1 weights of size [256,64,1,1] expected input[1,16,256,256] to](http://pic.xiahunao.cn/Pytorch RuntimeERROR: Given groups=1 weights of size [256,64,1,1] expected input[1,16,256,256] to)


 pytorch 0.2.1)








