摘要: 本文主要介绍多任务学习和单任务学习的对比优势以及在工业界的一些使用。如何从单任务学习转变为多任务学习?怎样使AUC和预估的准确率达到最佳?如何对实时性要求较高的在线应用更加友好?本文将以淘宝实例为大家进行分享多任务学习实现电商应用中的个性化服务搜索和推荐。
演讲嘉宾简介:
刘士琛(花名:席奈),阿里巴巴搜索事业部高级算法专家。本科就读于中国科学技术大学少年班系,计算机专业博士。目前是阿里巴巴高级算法专家,服务淘宝网搜索、排序、个性化相关的业务;专注于搜索排序方面的算法研究及应用,涉及实时计算、深度学习、强化学习等领域,相关工作发表于sigKDD、WWW等会议中。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本文将围绕以下几个方面进行介绍:
1. 背景
2. 相关知识介绍
3. 多任务模型
4. 实验及效果
5. 生效技巧及注意事项
一. 背景
多任务学习的研究目的:使用机器学习和数据挖掘的相关技术帮助更好的实现电商应用中的个性化服务搜索和推荐。
为什么使用多任务学习:
1) 以前在服务搜索和推荐中大多使用单任务学习方法,但在真实的工业界应用场景中,更多的是多任务并存的情况,因此多任务学习更具有实践意义。
2) 一个多任务学习模型会比多个单任务学习模型更加小,在线CPU使用率更低,对于在线服务更加友好。
3) 在淘宝中,多任务学习可以帮助获得更通用的用户、商品理解与表达。
二. 相关知识介绍
1. 学术界背景
首先为大家介绍相关的学术背景知识,以及使用DNN和RNN完成的一些推荐工作。说到推荐,大家可能立即想到协同过滤,2000年左右就有大量的协同过滤算法出现,包括基于模型的,基于内存的等。使用DNN做推荐的历史也比较久,开始大多使用RBM(Restricted Boltzmann Machines, 限制波尔兹曼机)来做推荐,当时在协同过滤上有比较好的表现,比基于用户的协同过滤推荐(User-based Collaborative Filtering Recommendation)和基于项目的协同过滤推荐(Item-based Collaborative Filtering Recommendation)的效果更佳。近年来,主要使用的推荐方法是DAE(denoising auto-encoders)。
在工业界内,推荐算法有更多的应用,例如微软提出了DSSM(deep structured semantic models),一种Pair Wise Ranking方法。Google提出了神经网络(a wide and deep network)来做推荐和排序。近期,大家可能更多使用RNN/CNN或者Attention的技术来做推荐。因为用户在某一个平台上,会存在一个天然的行为序列,这个性质使得RNN/CNN或者Attention具有更佳的可用性。
2. 多任务表达学习(Multi-task Representation Learning)
近年来,多任务表达学习越来越热,因为机器学习以及深度学习的成功主要归功于模型能更好的获取数据表达,能从数据中挖掘出需要的信息。而多任务表达学习能从数据中获取更加综合的、更加可变化的信息。单任务模型提取出的特征只针对该单任务有效,单个特征并不能很好地描述一个样本。当任务量较大,并且要求学习到的特征为每一个任务服务,即要求特征有一定的通用性时,多任务学习就更加合适。多任务学习一般分为两种,一种分为主目标及其他附属目标(Main task and auxiliary tasks),附属目标是为了帮助主目标来训练;另一种为多个平等目标(Equal tasks),没有主次之分。
3. 系统背景
淘宝主要将多任务学习应用于搜索系统中。该流程主要如下图所示:
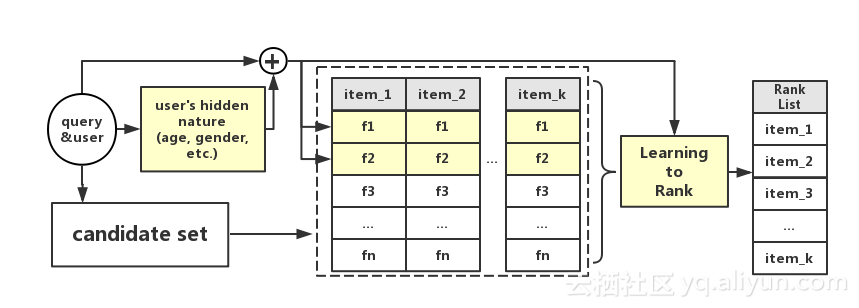
首先,用户会输入一个查询(query),然后搜索引擎会根据倒排索引,返回一个相关的候选集合。同时也会设置预测任务获得用户的相关信息,比如性别、年龄、购买力、购买风格、购买偏好等。基于候选集和用户信息,可以获取候选集中的所有商品的属性和特征,如下表所示:
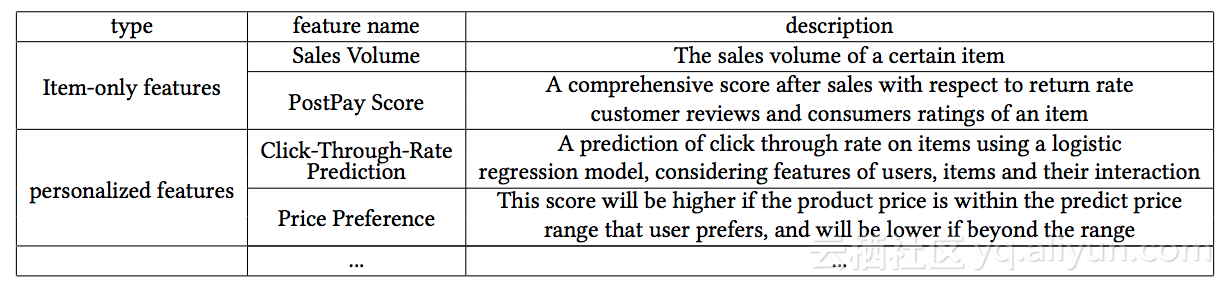
与商品相关的特征有销量、售后满意度等,个性化特征包括商品的个性化预估、用户对该商品的价格偏好等。对于某一商品,可能有几十维或者上百维的特征描述,接着使用模型整合这些特征的单个评分,最后根据总得分进行排序。流程图中黄色的部分为商品个性化相关的部分,即需要模型去预估的部分。每个黄色块可以看作是一个任务或多个任务。由此可见,在线排序过程中通常存在多个任务,因此需要使用多任务表达学习来解决。
三. 多任务模型
淘宝多任务模型的整体结构如下图所示:
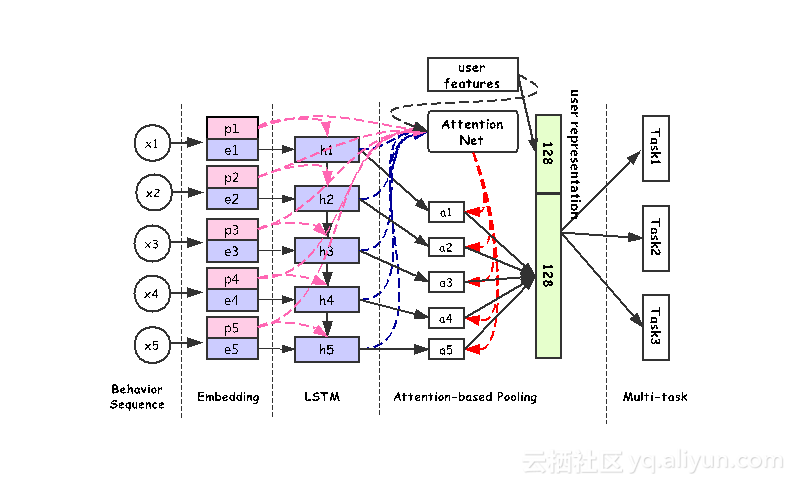
模型的输入信息是用户在淘宝上的行为序列。每个行为包括两部分:第一部分是行为动作,例如行为类型可能为点击、搜索以及推荐等,行为时间可能为1分钟前、五分钟前或半小时前,这些属性是用户的动作本身而与商品无关;第二部分是与商品相关的部分。这里每个行为x被表达成一个性质描述p(property)和e(embedding)。然后建立LSTM(Long Short-Term Memory)将用户行为序列串接起来。接下来使用attention net做池化(pooling)得到一个128维向量的用户表达。将该向量和用户的其他信息组合,得到最终的可以被多个任务共享学习的用户表达。综上所述,该多任务模型可以分为五层:输入层Behavior Sequence, Embedding层,LSTM层,Attention-based Pooling层,Multi-task接收输出层。其中涉及的技术包括:
- Embedding
- CNN/RNN/Memory Net
- Attention
- Multi-task Learning
- Lifelong Leaning/Transfer Learning
因此采用多任务表达模型,旨在构造可以共享给多个任务学习使用并且方便转化的用户表达。接下来将详细介绍每一层结构。
1. Embedding层
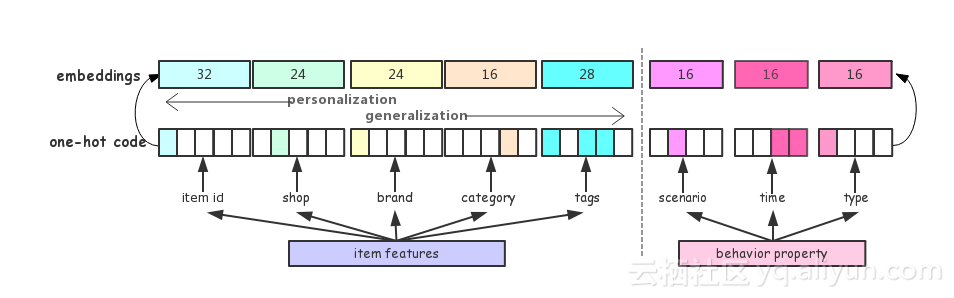
Embedding层主要将用户的行为转化为向量。如上述所说,用户的一个行为由行为描述(behavior property)和商品特征(item features)组成。商品特征包括商品ID、所属店铺、品牌、所属类目(例如服饰箱包)等信息,此外商品还会有一些更加泛化的标签,例如商品价格是否昂贵,商品颜色是什么,风格是韩版还是欧美风等等。上图中对商品的描述信息从左向右越来越泛化。这里认为,越泛化越个性化特征能更综合地表示商品信息,例如若某个商品非常热销,那么该商品ID就能表示它,但当商品销量特别低时,商品ID就无法表示它,还需要该商品的所属店铺、品牌、所属类目以及更个性化的便签。用户的行为描述包括三方面:一是行为场景,例如行为是发生在搜索时、推荐时或者在聚划算时;二是行为时间,可以是一分钟以内、五分钟以内或是半小时以内,淘宝对行为时间进行了分窗口划档,将行为按照行为时间分至不同的档位;三是事件类型,分为成交、点击、加购物车、收藏。向量转化后的维度可以从上图中得知,商品特征的五种属性维度分别是32、24、24、16、28,行为描述的三个属性维度为16、16、16。最后将所有的向量组合,得到最终的用户行为向量。
2. Property Gated LSTM和Attention Net
但是用户在淘宝上通常是一系列较长的行为序列,例如浏览商品,点击商品以及购买商品等。那么这里希望可以从这段行为序列中分析该用户的相关信息。那么类似于自然语言处理,可以将多个词以序列的形式embedding成一句话,这里可以使用LSTM将多个行为以序列的形式embedding成行为序列。与原始LSTM的区别是,此处输入信息包括两方面,商品特征和行为描述。相信大家知道,LSTM是RNN(循环神经网络)的一种,它的创新点是包括很多门,这一方面可以保证网络训练时不会发生梯度消失或梯度爆炸的现象,另一方面可以强调或弱化序列中的一些个体。在一般的RNN中,序列中的每个元素都是平等的,但在LSTM中可以为个体设置权重,提示哪些元素可以被强调,哪些元素可以被忽略,这会对用户行为学习产生比较重要的影响。例如,用户在半年前的一次点击行为和用户在近期的一次成交行为相比,后者明显会更重要。那么这在模型中如何体现呢?这里将用户的行为描述放置在三个门中,即遗忘门(forget gate)、输入门(input gate)、输出门(output gate)。那么用户行为描述便可以决定一次用户行为中分别需要注意和忽视的内容。因此这里提出了如下图所示结构的Property Gated LSTM:
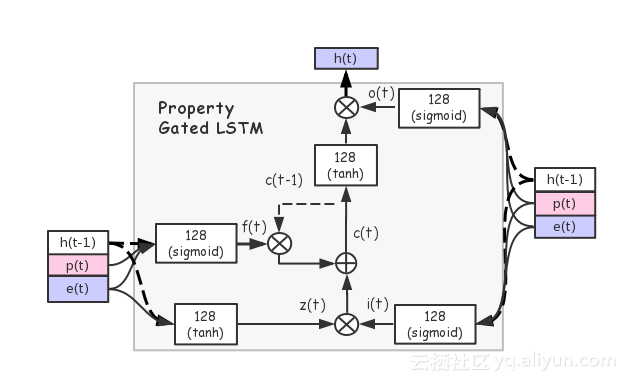
上图中,p表示property,e表示embedding,h(t-1)表示前一个LSTM的输出,h(t)表示当前LSTM的输出。具体的Property Gated LSTM公式如下所示:
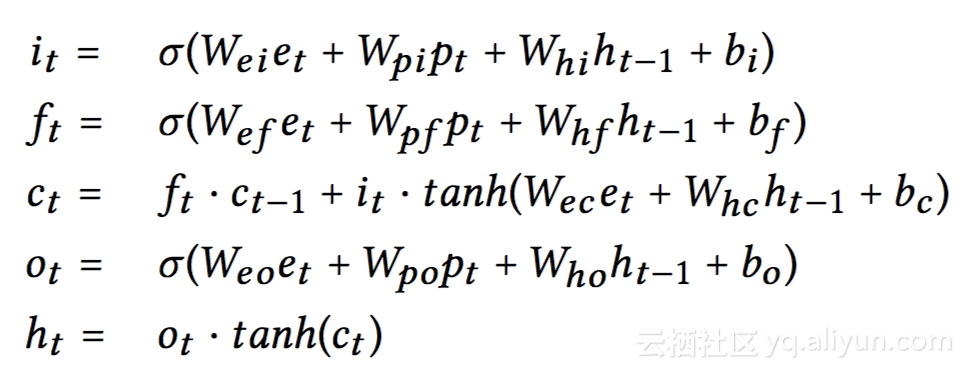
在LSTM网络之后,淘宝也仿照自然语言处理,加入了attention net机制,其作用和门比较类似,也可以决定行为的重要性程度。但与门有所区别的是,门在处理行为重要性时只能根据当前行为的信息来决定,attention net机制中可以加入一些额外的信息,例如可以加入用户query信息和user信息,user会包含用户年龄、性别、购买力、购买偏好等信息,query会包含自身的ID、分词以及一些内幕信息等。具体如下图所示:
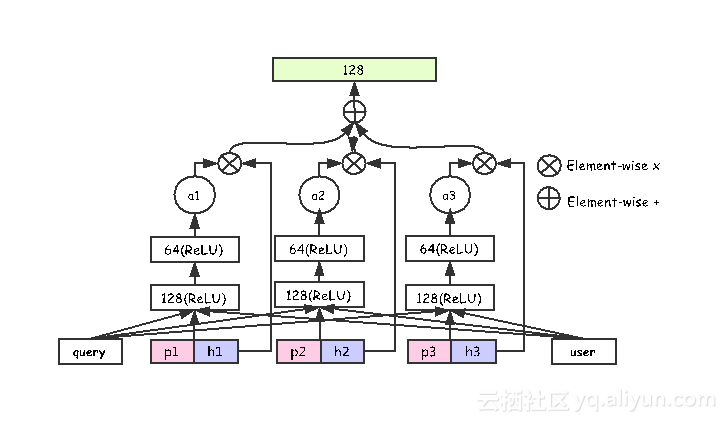
假设输入30个用户行为序列,LSTM输出30个向量结果h,attention net机制会决定输出的h重要性程度,最后做池化(pooling)。例如,某用户点击浏览一条连衣裙,然后购买了一个手机,浏览了一些扫地机器人、笔记本电脑等。如果此时该用户输入搜索query为iphone,那么用户行为中关于服饰的记录重要性明显降低,因为这些记录并不能反映该用户当前的兴趣,而之前关于手机的行为记录能更多的表达用户当前的兴趣。
3. 多任务模型(Multi-tasks)
用户行为序列在Embedding后,经过LSTM层,然后使用attention net做池化(pooling),最终得到一个256维向量的用户表达。假设得到一个这样通用的用户表达,准备将其应用于以下五个任务。
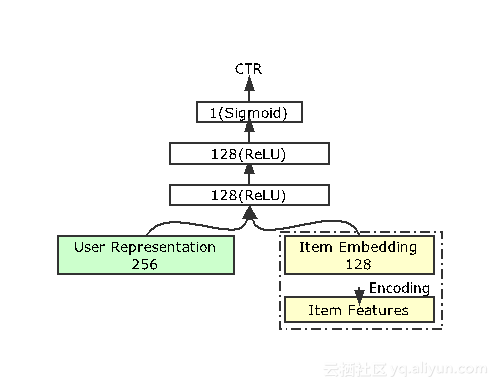
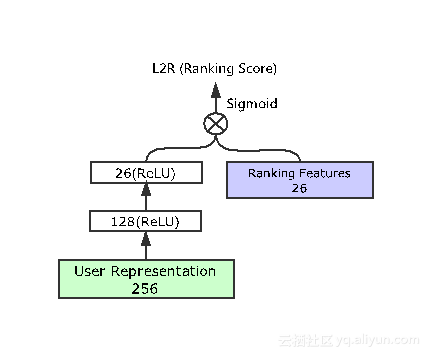
任务一是CTR预估任务,这在广告和排序推荐中较为常用,例如预估用户对某电影视频或者音乐的点击率。淘宝会使用CTR来预估用户对某些商品的点击率。公式中主要运用似然函数来表示。输入包括256位的用户表达和商品的embedding,此处的embedding即为用户行为序列中的embedding,两处共享。这些输入信息经过三层网络便可以得到预估结果。
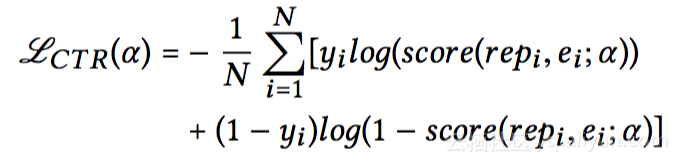
任务二是L2R(Learning to Rank,也可做LTR)任务,形式上与CTR预估类似,但不同的是输入信息中需要包含具体的商品排序特征(Ranking Features)。在CTR预估中将用户表达与embedding做全连接操作,而L2R任务中是将用户表达经过两层网络后和商品特征进行线性相乘。它的优势是最上一层网络容易理解,并且便于查错。而公式中与CTR不同的是加入了权重信息,来表示注重或者忽略哪些行为。比如用户点击商品、购买商品的行为需要较大的权重,而浏览商品后无任何行为可以予以忽视。
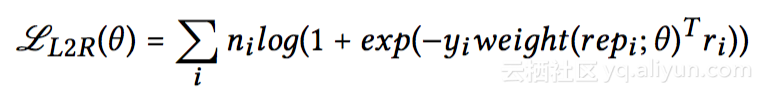
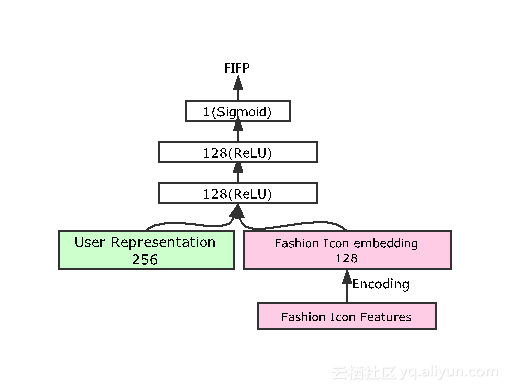
任务三是用户对达人的偏好。因为这里希望最终学习到的用户表达比较通用,而不是所有的任务都和商品相关,如此学习到的用户个性较为局限。因此任务三主要学习用户喜爱的达人类型。此处任务三的输入除了256位的用户表达外,还需输入相关达人的特征,然后解决用户是否会follow的二次类问题。
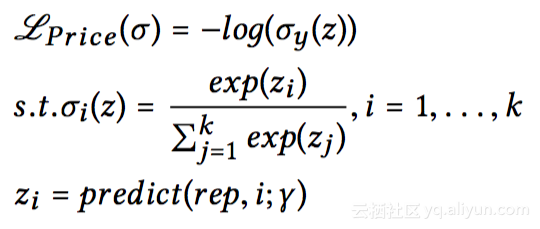
任务四是预估用户购买力(PPP)。这里将用户的购买力分为7档,1档最低,7档最高。这可以预估出用户是否是追求品质,购买力较高,还是追求性价比,偏爱价格较低的商品。购买力预估和商品无关,根据输入的256位的用户表达进行一个切分即可。
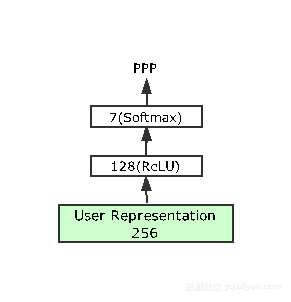
上述四个任务是网络中需要学习用户表达的任务,可同时进行学习得到任务模型,从而得到最终的用户表达。那么接下来需要验证最终的用户表达是否可以应用到其他任务中,因此设置了transfer task。transfer task用来预估用户的店铺偏好,但是该任务并非和上述四个任务同时学习,而是取上述四个任务学习之后的用户表达进行学习,验证其是否可以直接使用在新任务中。因此相比其他四个任务需要链接到一个较大的网络背景下进行,transfer task的深度较浅。
四. 实现及效果
模型设计完成后,需要进行实验验证模型的效果。首先关注训练过程。由上述可知这里将有5个任务,因此有5个独立的训练数据集,4个数据集同时进行训练,最后一个进行验证。关于数据集,每天的样本数据量大约为60亿,在没有取样的情况下数据量会达到200亿左右。然后采用10天的数据完成训练过程,10天之后一天的数据完成预测过程。训练过程中使用mini-batch,每个batch的样本为1024条。关于在线环境,CTR和LTR会对线上效果产生影响。CTR预估会作为Ranking Feature在线上生效。LTR会影响Ranking Feature的排序过程,因此影响更大。此外还会使用PPP来预估用户购买力。
下图列出了实验中的一些参数。例如LSTM的用户序列为100个,Dropout rate为0.8,采用L2正则,AdaGrad中的learning rate为0.001,训练使用分布式的TensorFlow环境,其中有2000个worker,96个server,15个CPU核,没有使用GPU,整个训练需要4天来完成。

1. DUPN与Baselines方法比较
首先分析第一组实验结果。第一组实验将上述提出的方法(命名为DUPN),与其他Baselines方法(包括Wide, Wide & Deep, DSSM, CNN-max四种)进行比较。Wide方法是单层网络,可能会包含较多的单特征和交叉特征,然后进行逻辑回归LR(logistic regression)。第二和第三种方法分别是由Google提出的Wide & Deep,以及由微软提出的DSSM。最后CNN-max是采用CNN提取用户行为特征,然后做max-pooling,得到用户表达。而上文中提出的DUPN方法包含5个子方法,DUPN-nobp/bplstm/bpatt/all/w2v。DUPN-nobp/bplstm/bpatt这三种子方法是指用户行为描述property只使用在LSTM或Attention Net中。DUPN-all表示最完整的算法。DUPN-w2v表示并不使用end to end学习方式,而是加入pre-training,采用word to vector将每个商品训练为向量形式,然后直接将该向量输入到后续的网络中,这样可以大大减小网络的参数空间。接下来将这些方法应用到任务1-4中,得到以下的结果对比:
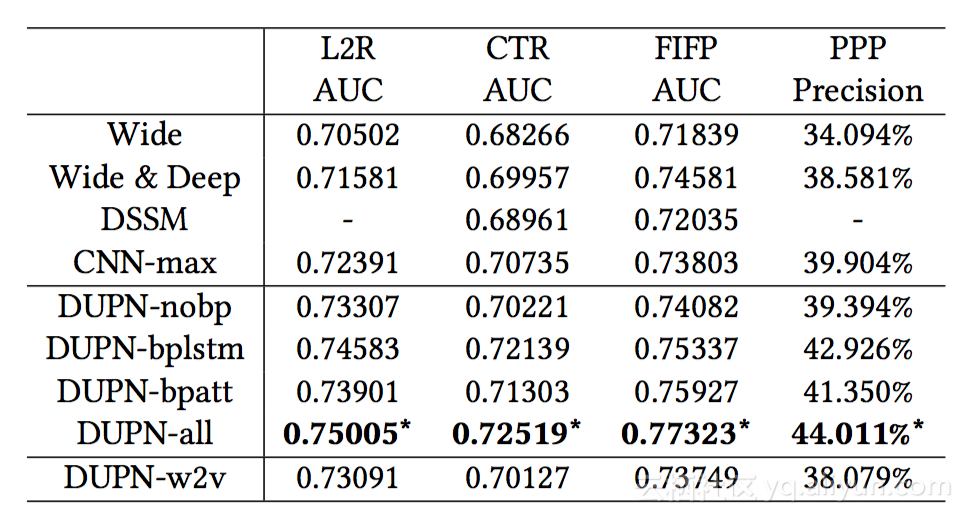
如上表所示,四种baseline方法中效果最佳的为CNN-max。Wide & Deep和DSSM并未将用户的行为序列纳入考虑范围,只是将用户的特征进行一个组合。而CNN-max则是从用户的行为序列中提取特征。因此它在前三个任务中的AUC以及任务四中的准确率最高。前四个DUPN算法中,DUPN-all效果最佳。完全不使用property的DUPN-nobp算法效果和CNN-max比较接近,这也印证了当只有LSTM层时,效果和CNN相差不多。但分别加入了Property Gated LSTM和Attention Net后,即方法DUPN-bplstm/bpatt,相对于DUPN-nobp都有较大的提升。因此最完整的DUPN-all可以达到最佳效果,各AUC都上升了一至三个百分点,购买力预估有5个百分点的提升。最后一种方法DUPN-w2v,使用了pre-training来减小参数的空间来简便训练,但这里可以看到效果并没有比前几种更佳,原因可能是DUPN-w2v在训练数据过程中只能得到哪些商品具有类似属性,但不能得到商品本身的信息,例如热销度等。因此由第一个实验可以得出,上述提出的DUPN-all算法,在各个任务中都比传统方法效果更佳。
2. 多任务学习和单任务学习比较
接下来验证多任务学习和单任务学习的差异。上述任务一至任务四可以作为多个单任务独立学习,也可以作为多任务学习同时执行。下图即为两种方式的结果比较:

上方四张图为各任务在两种情况下AUC的比较值,下方四张图为Loss的下降情况。以第一张图L2R Rank AUC为例,首先关注AUC的变化趋势。开始阶段AUC值会飞快的增长到0.68左右,然后增长速度放缓直到0.75。因为抽取的用户特征中会存在一些泛化特征,这些泛化特征在每个样本中都存在,开始阶段泛化特征会起到主要作用,学习速度较快。但是对于后续稀疏的特征,例如店铺特征或商品ID等,学习速度非常慢,但依然可以使AUC值逐渐上涨。而图中红色曲线为多任务学习结果,蓝色曲线为单任务学习。这里可以清晰的看到在所有图像中,多任务学习的AUC和准确度都高于单任务学习。那么该如何理解这种现象呢?大家可能会猜想由于多任务同时学习会使某些任务学习速度降低,然而并不如此。在四个任务同时进行时,可以将其他三个任务看成正则,例如在学习时加入L2正则,会使AUC值更高。但这三个任务与L2正则的差异是他们并不只是单纯的防止过拟合,同时也可以使基础特征学习的更加泛化。因此多任务学习其实对每个单任务来说都会更加有利,AUC值也会更高。
这里值得注意的是上述所有实验结果都是基于测试集,如果在训练集进行上述实验,多任务的数值结果相比来说会较低,但二者之间的差异仍存在。因此基于准确率,多任务学习会比单任务更佳。
3. 模型迁移能力
接下来验证一些模型是否具有迁移能力。例如在学习完上述四个任务后,任务五为学习用户对店铺的偏好,这里可以从四种学习方法中进行选择:End-to-end Re-training with Single task (RS), End-to-end Re-training with All tasks (RA), Representation Transfer (RT), Network Fine Tuning (FT)。RS与DUPN网络类似,将任务五作为一个全新的任务,单独进行学习。RA是指将任务五和前四个任务同时进行,重新训练。RT是指不再训练整个大网络,而是将最后更新的用户向量和店铺的属性输入,进行一个浅层训练。FT是指在上述大网络的后端直接接入任务五的学习,对初始网络进行微调,得到最终结果。上述四种方法的训练过程如下图所示:
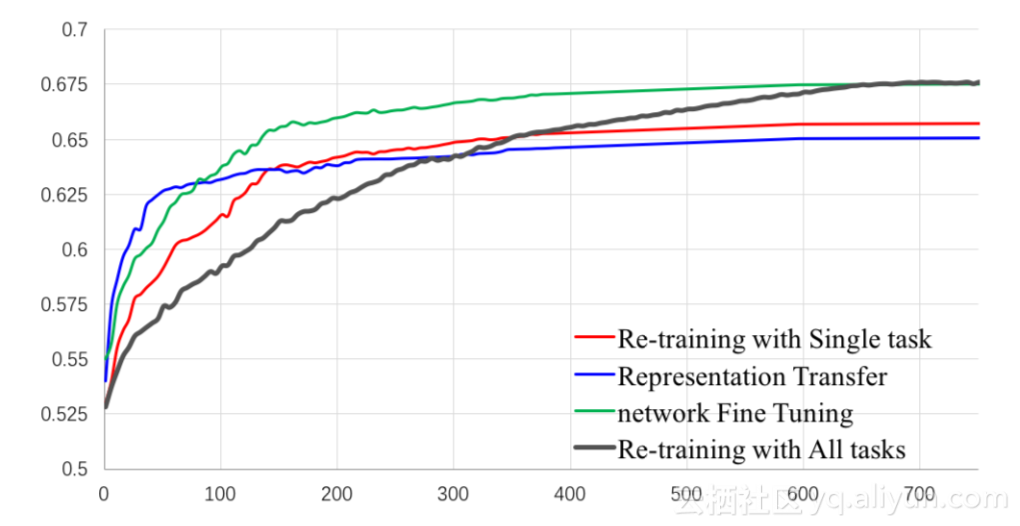
上图中横坐标为训练时长,纵坐标为AUC值。效果最佳的为绿色曲线FT,一方面FT收敛较快,另一方面其最终AUC值也最高,为0.675左右。这说明之前的网络已经达到了较好的训练效果,进行一些微调后便可以很快的得到最终结果。而黑色曲线RA虽然收敛速度较慢,最后仍然可以达到和FT同样高的AUC值。但显而易见FT的代价较低,RA需要完成一个整体的重新训练,可能需要四天或以上的时间,并且消耗大量计算和存储资源。RT曲线只需要输入最后更新的256位用户向量和店铺的特征,学习的参数较少,因此收敛速度最快,但学习效果也相应的较低,比FT低2%左右。RT的优势在于对初始网络没有任何更改,只是在其后嫁接了一个新的学习任务,如果是在线应用消耗较小,并且得到的AUC值也勉强可观。试想若五个任务是在线执行,并且规模相对较大,可能五个任务根本无法同时学习,并且对于一个实时系统,需要及时的给予用户反馈,那么此时RT便是一个最佳选择。这四种方法中,除了RT为一个模型,其他三种方法都至少有两个模型,这意味着在线的计算量和存储量几乎都需要翻倍。因此若在线资源比较充足,推荐使用FT方法;若在线性能受到限制,需要一个内存较小速度较快的方法,那么RT方法较为合适。
4. 用户attention分析
然后从两方面对用户的attention进行分析。一方面是用户输入的query信息,如下图所示。最下一行是用户在淘宝上曾经有相关行为的商品,从左向右行为时间越近。那么用户再次输入不同的query,对这些历史行为的attention也不同,颜色深浅代表attention的大小。例如当用户再次搜索laptop时, 那么attention更多的会集中在耳机、手机之类,而搜索连衣裙T恤之类,服饰相关的类目会起到比较大的作用。由此可见,query能够非常有效的决定历史行为的重要性程度。

另一方面用户行为信息也可以帮助分析。下图中横坐标为行为时间,纵坐标为行为类型,不同的行为类型有不同的attention权重。整体来说,用户的成交行为重要性最高,远远高于点击、加购物车和收藏行为。收藏行为可能对分析用户行为表达重要性最低。但比较有趣的是,用户越近的一些点击行为越能反映用户的兴趣,但是最近的成交行为并不能反映。这和大家的认知相同,当用户购买了某件商品后,近期可能不会再购买该类型商品,因此颜色较浅,相反,几个小时以后或者几天以后的购买行为能更反映用户兴趣。这也是将用户行为信息(property)加入到学习网络中准确率会上涨的原因。
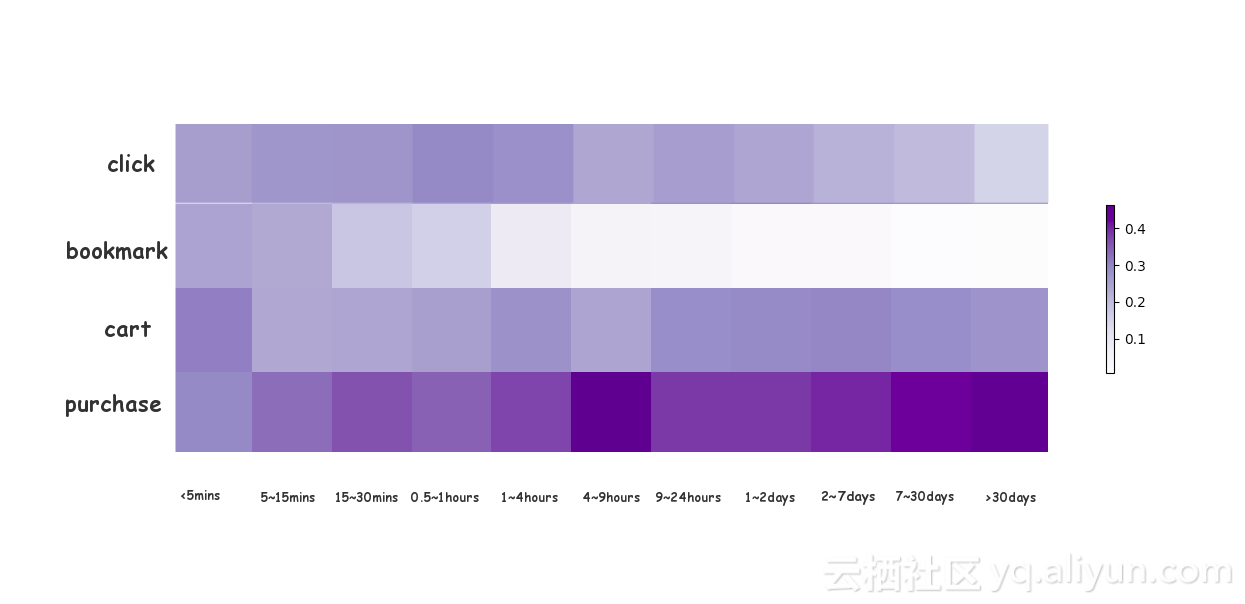
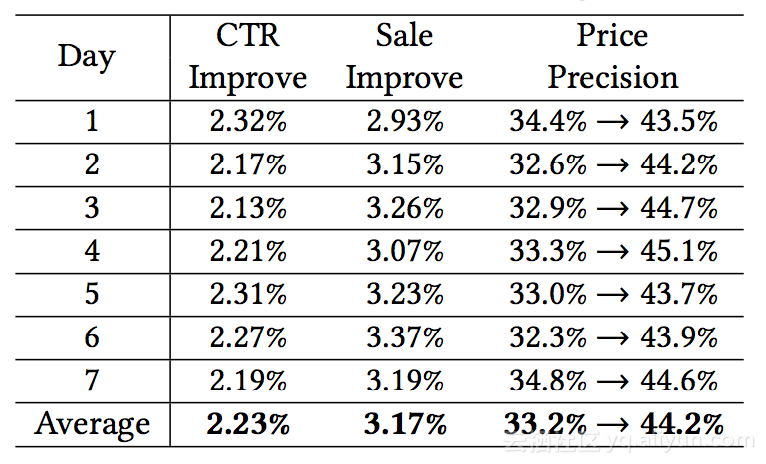
最后将这个算法应用到淘宝的一个在线系统,现在已全面生效。淘宝统计了其在线上7天内的运行效果,如下表所示,CTR可以提升2%左右,销量可以提升3%左右,购买力预估从以前的33%提升到44%。
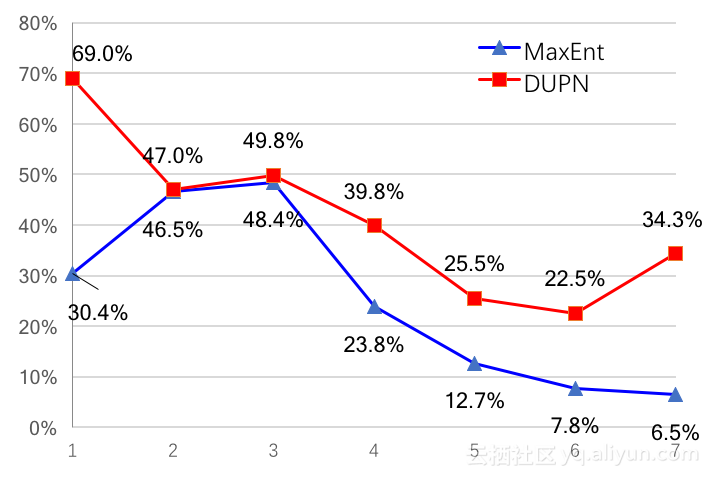
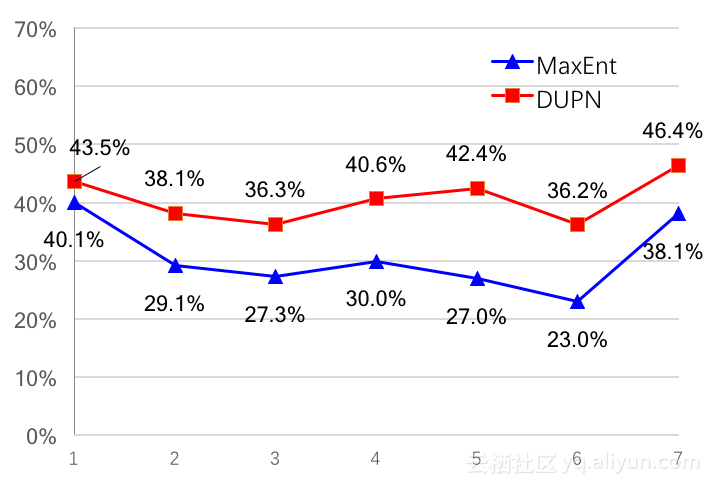
以下两图更详细的展示了算法的效率提升。淘宝上用户的购买力分为7分,因此这里需要观察每个分档下的准确率(上图)和召回率(下图)。由图可见,准确率和召回率都有提升,但提升的幅度并不一致。在准确率中,1档和7档提升较多,而23档提升较少。在召回率中,各档提升较为均匀,大致在5%至10%之间。
五. 生效技巧及注意事项
1. 模型需要高频的更新
商品的ID特征属性经常变化,例如商品的流行程度、随季节变换而变化的风格、用户的兴趣也在随时变化等,因此embedding也需要随之改变。实际应用中如果不更新模型,模型效果会逐渐变差。大量的ID特征导致模型的训练非常缓慢,一次全量训练可能需要长达4天时间。因此可以在开始时使用10天的数据进行一次全量学习,之后每天使用前一天的数据做增量学习。这一方面能使训练时间大幅下降,能在一天内完成;另一方面可以让模型更贴近近期数据。例如在双11时,因为当天的样本与日常有很大不同,淘宝使用了当天不同时段的数据对模型进行了两次更新,更新后可以看到训练的指标得到了明显提升。
2. 拆分模型
在模型生效时可以对模型进行一定的拆分。在排序任务中,需要对每一个商品做CRT预估或者LTR估分,如果商品数量巨大,学习过程会非常耗时,那么该如何使计算量下降呢?这里可以将模型拆分成用户部分(红色)和商品部分(蓝色),如下图所示:
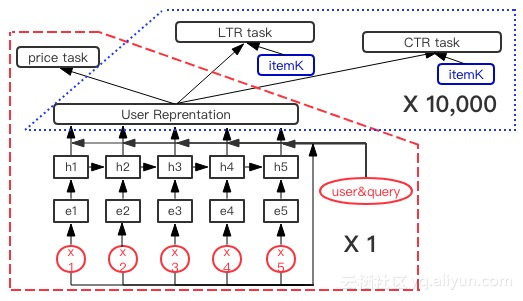
用户部分和商品部分几乎没有关联性,因此对于某一用户,输入query之后可以只计算一次用户部分,得到用户对商品的向量表达。然后计算商品部分的CRT预估和LTR,此时只有商品部分需要重复计算。而大规模的计算量其实都聚集在红色用户部分,因此这样的拆分对线上运行非常友好,能够几千倍的降低线上计算量,使得模型在线上更高效。
3. BN中一致性问题
Batch normalization能很好的提升模型效果,使AUC显著提升。但需要注意的是,训练样本中BN记住的离线均值和方差和在线数据中一定要保持一致。举例来说,在训练样本中会做各种过滤和采样,例如把点击和成交样本采样,那么这样会导致某些维度的均值会远远高于实际线上的均值,虽然在测试集上的AUC也能提升,但这对在线效果非常不利。从实验来看,用户的向量表达的确具有不错的迁移能力,即在其他任务中也能表现出不错的效果。但这一点在很多参考文献中是不一致甚至矛盾的。应用的时候需要根据场景的不同多加注意。
4. 淘宝相关部分简介
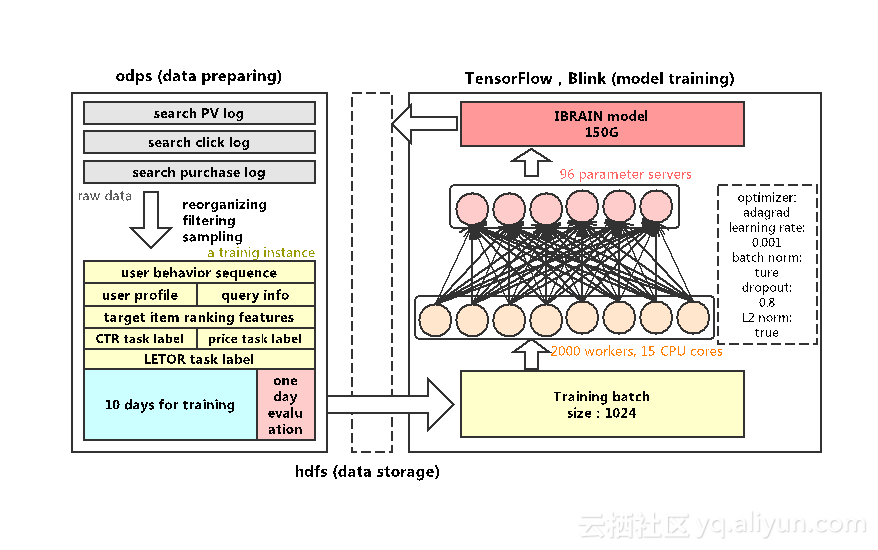
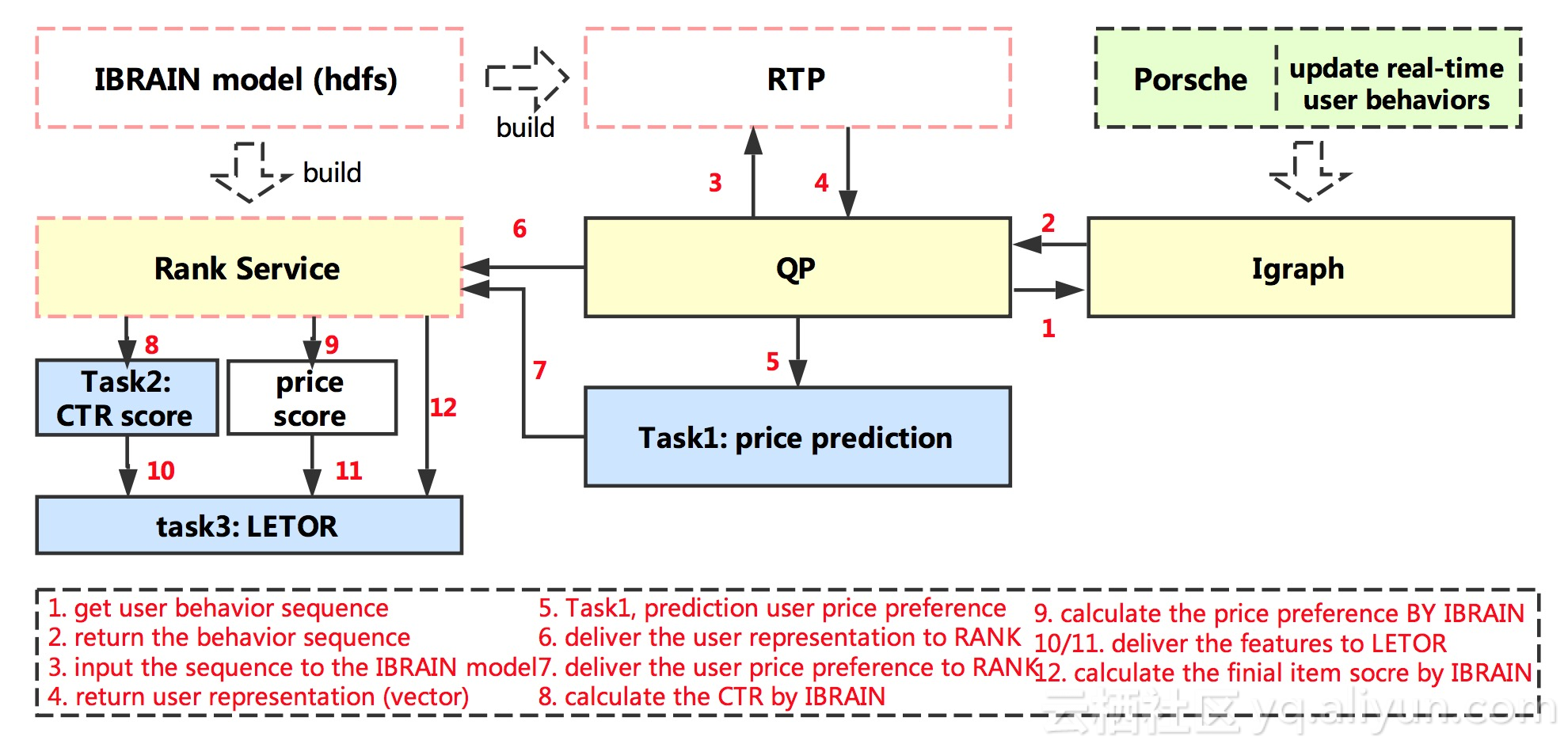
后续是模型生效过程,因为这些过程和淘宝相关性太高,只做一个简单介绍,如下图所示。首先通过OPDS将用户的点击、购买和PV行为合并,10天做训练,一天做评估,然后将这些数据放在HDFS,在TensorFlow上进行训练。这样一个模型大约在150G左右。因此当模型数增多,至五个以上时,线上内存是无法容纳的。这也是采用多任务学习的一个重要原因,来减小模型的存储和计算效率。
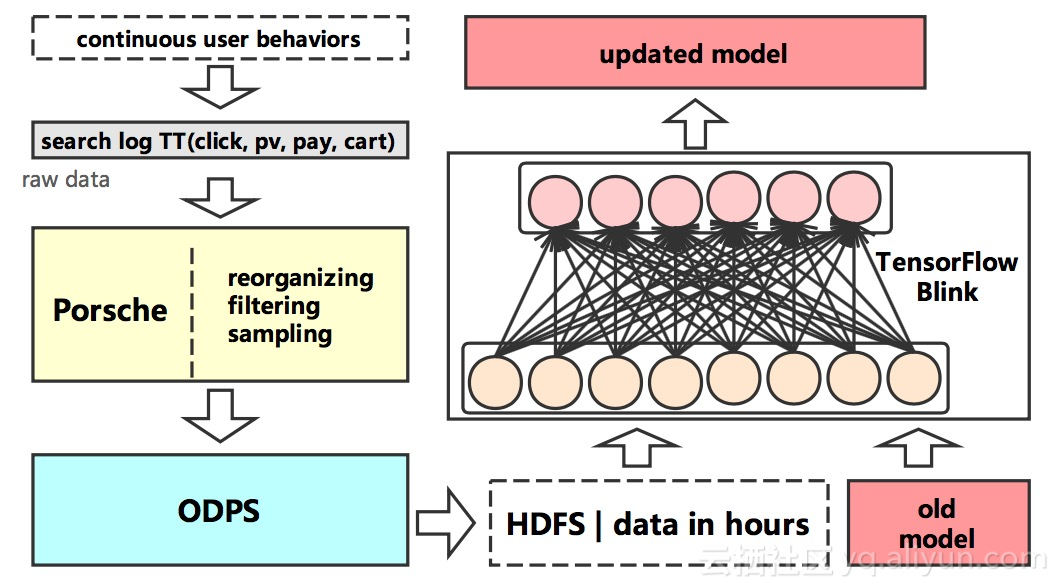
下图表示增量模式的过程。将以往的用户行为数据输入一个在线平台,导出到ODPS,然后将老的模型和新的数据进行增量训练,得到更新的模型。
最后一张图是生效过程。上文讲到模型拆分成两个部分,因此生效需要在两处进行。一处在用户query process部分,然后将用户表达和商品属性在另一处计算得到商品的分数。
原文链接
干货好文,请关注扫描以下二维码:










 函数)




)



是骗人的吗?如何查看自己的交易费率是多少?万一免五最新问题汇总!...)
