阿里妹导读:提起买家秀和卖家秀,相信大家脑中会立刻浮现出诸多画面。同一件衣服在不同人、光线、角度下,会呈现完全不同的状态。运营小二需从大量的买家秀中挑选出高质量的图片。如果单纯靠人工来完成,工作量过于巨大。下面,我们看看如何使用算法,从海量图片里找出高质量内容。
说到淘宝优质买家秀内容挖掘,必须从买家秀和卖家秀说起。我们总是能在卖家秀和买家秀中找到强烈反差,比如这样:

这样:

又或者这样:


买家秀和卖家秀对比这么一言难尽,那还怎么让运营小二们愉快地玩耍?出于运营社区的需要,运营的小二们得从当前的买家秀中抽取出一批高质量的内容,作为社区的启动数据。
找到高质量的买家秀有那么难吗?就是这么难!这不,运营的小二们碰到了以下几个问题:
买家秀质量良莠不齐
淘宝海量的买家秀无疑都很难入得了运营小二们的法眼,以业务维度进行筛选的买家秀,审核通过率普遍不足三成。这意味着,在海量的买家秀中,能被运营小二们看对眼的,无疑是凤毛麟角。
审核标准严苛
咨询了运营小二,他们要求图片视频必须要美观,有调性,背景不凌乱,不得挡脸,光线充足,构图和谐,不得带有明显的广告意图,以及等等等等……
这么多要求,难怪挑不着!
审核工作量巨大
由于运营小二们审核的买家秀中优质买家秀很少,不得不将大量的时间和精力花费在了审核低质量买家秀上。
有鉴于此,用机器帮助挖掘优质内容刻不容缓。
优质内容挖掘方案
优质内容挖掘的整体方案如下:
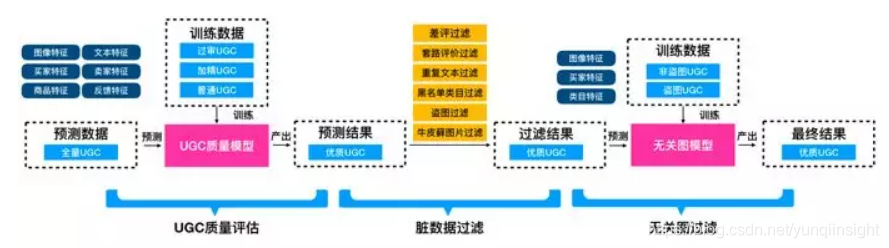
全量UGC(User Generated Content)是指所有含图或含视频的买家秀。过审UGC是指最终审核通过的高质量买家秀,加精UGC是指商家认可的买家秀,普通UGC则是上述两种情况以外的其他买家秀。
我们的核心目标就是要挖掘出丰富而多样的优质UGC。
UGC质量评估模型
运营人员在审核买家秀时,通过综合判断买家秀的图片质量和文本内容等方面的因素,来决定是否审核通过。这促使我们直观地将将问题转化为一个分类问题。
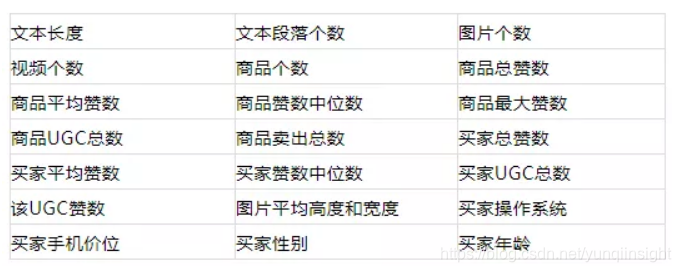
1、特征的选择
我们首先采用了UGC的用户特征、商品特征和反馈特征等统计特征(详见下表),通过GBDT模型来预估UGC的内容质量,并初步验证了将UGC质量评估任务转化为分类问题是可行的。
2、分类问题的转化
一个非常直观地感受是,将审核通过的数据标记为1,审核未通过的数据标记为0,将问题转化为二分类问题。但在实际训练中,我们发现,将审核通过的数据标记为2,将运营审核未通过(商家已加精)的数据标记为1,将商家未加精的数据标记为0,把问题转为三分类问题比把问题转化为二分类问题得到了更好的效果。原因在于,审核人员在原来的链路中只审核了商家加精的数据,在此基础上审核通过与否;而为数众多的商家未加精的数据没有审核到,因此三分类更贴近于真实场景,因此表现更佳。
通过GBDT模型的训练,在全量UGC数据中进行预测,挖掘出了约400万优质UGC。自查后发现,这一批数据能挖掘出部分优质UGC,准确率在50%左右,缺点在于图片质量往往不够美观(即使较为贴近用户的生活场景)。
3、图片语义特征的引入
在与业务同学的交流过程中,我们发现,业务同学需要极高质量的UGC内容,以便营造出良好的社区氛围,让用户在洋葱圈中找到对于美好生活的向往,其核心标准就是宁缺毋滥。在充分理解了业务同学的要求,拿到图片数据后,对于图片质量的评估势在必行。
一个较为直观的方案就是,通过CNN模型训练,进行图片质量的评估。
增加图像特征后,通过对ImageNet预训练的ResNet50进行fine-tuning,模型表现有了极大提升,与原有链路相比,审核通过率提升了100%以上。
其中含小姐姐的UGC业务同学的认可程度较高(小姐姐们更乐意晒单,更乐意发买家秀,质量也更高),而针对不含小姐姐的长尾类目,业务同学认为主要存在图片无美感和图片不相关两类问题。
图片无美感的问题主要是由于,CNN更擅长捕捉图片的语义信息,而对于美学信息不敏感。
4、美学特征的引入
在图片美感方面,目前有一份较为优秀的数据集——AVA Database(A Large-Scale Databasefor Aesthetic Visual Analysis, 参见 Perronnin F ,Marchesotti L , Murray N . AVA: A large-scale database for aesthetic visualanalysis[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition.IEEE Computer Society, 2012.)。
AVA Database是一个美学相关的数据库,包含25万余张图片,每张图片包含语义标注(如自然风光、天空等)、图片风格标注(如互补色、双色调等)和图片美感评分(由数十到数百人评出1-10分)。
在 Zhangyang Wang, Shiyu Chang, Florin Dolcos, Diane Beck, DingLiu, and Thomas S. Huang. 2016. Brain-Inspired Deep Networks for ImageAesthetics Assessment. Michigan Law Review 52, 1 (2016) 一文中提出了Brain-inspired Deep Network,其网络结构如下:
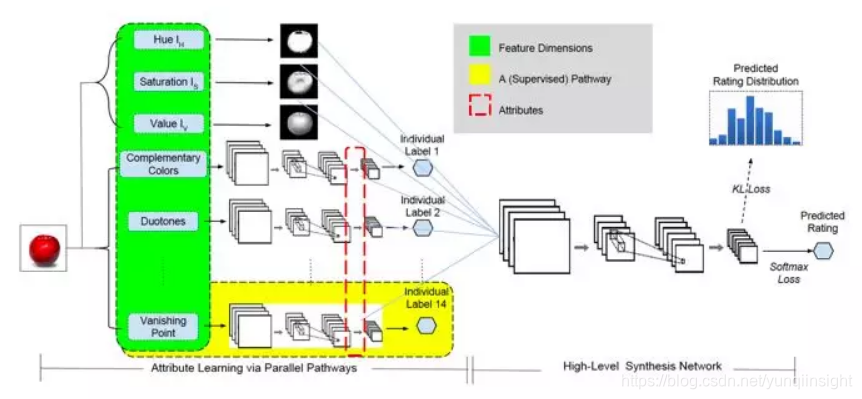
其核心思想是,通过AVA数据集提供的图片风格标签,学习图片风格的隐藏层特征,将图片风格的隐藏层特征和图片经过HSV变换后的特征结合起来,以AVA数据集提供的图片美感分为监督,学习图片的美感特征。
在此基础上,最终在UGC质量审核模型中采用下述结构评判UGC的质量:
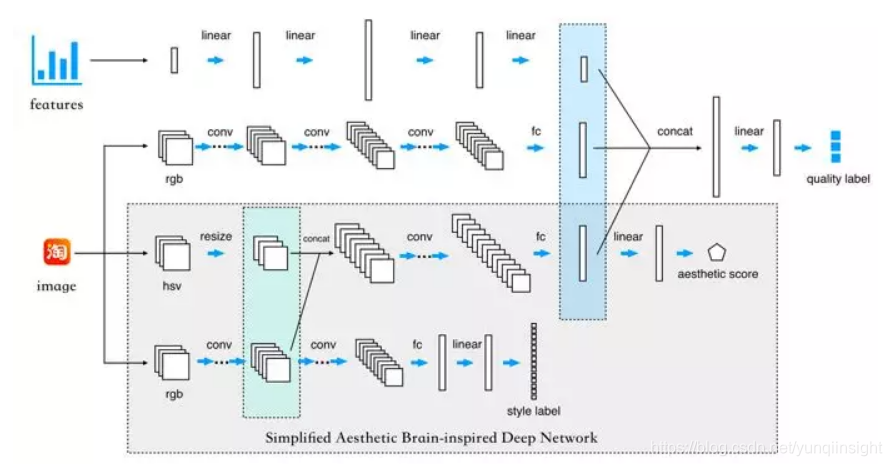
以AVA数据集提供的图片风格标签和美感评分进行预训练,通过Brain-inspiredDeep Network提取图片的美感特征;通过ResNet提取图片的语义特征;通过深度模型刻画统计特征;最后将三种特征拼接起来综合预测UGC的质量。
引入美学特征后,验证集上模型的准确率、召回率和F1值均得到了提升,ABTest显示,与原有模型相比,审核通过率提升6%以上。
脏数据处理
除了业务同学提出的问题,在自查过程中,发现目前挖掘出来的UGC内容中仍有以下脏数据:
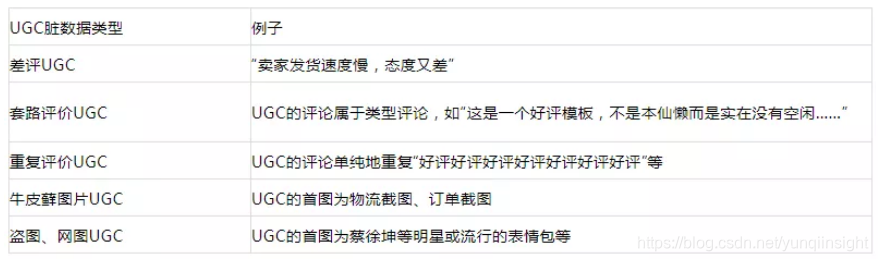
1、评论倾向判定
针对差评UGC,利用现有的组件进行情感分析,发现并不能很好地挖掘出差评评论,容易误伤。基于此,取过审UGC的评论和UGC中的差评进行训练,在验证集上F1值高于0.9,但由于实际预测的数据不同(忽视了中评等),导致容易误判(如将商品名称等判断为差评)。在此基础上取过审UGC的评论、UGC好评、中评、差评分为四档进行训练,在验证集上F1值稍低,但由于训练数据更贴近于真实场景,在实际预测中效果更好;目前基本解决了差评UGC的问题,实际自查过程中,没有再看见差评UGC。
在实际的模型选择上,Attn-BiLSTM(带attention的双向LSTM)效果好于TextCNN(F1score约相差3%),分析原因在于:TextCNN的优势主要在于捕捉局部特征,而很多文本虽然含有吐槽性段落(如批评物流慢等),但整体仍然是对卖家商品的肯定。
2、N-Gram过滤
针对套路评价UGC,通过全局比较UGC的文本内容,将被多名用户重复使用的模板UGC过滤掉。
针对重复评价UGC,通过判断UGC文本内容中重复的2-gram、3-gram、4-gram,结合文本长度和文本信息熵进行过滤。
3、OCR及图像Hash过滤
针对牛皮藓图片,一部分采用了OCR识别和牛皮藓识别进行过滤。
针对盗图、网图UGC,将图片表示为哈希值,通过全局判断哈希值在不同买家、不同卖家间的重复次数,进行过滤。在过滤此项的过程中,我们也发现,买家秀中盗图、网络图的现象较为普遍,很多肉眼看似原创的内容也涉及盗图和网图;此项过滤掉了大多数的UGC。
无关图识别
解决了上述问题后,仍然较为显著的问题是无关图的问题。
无关图的出现原因较为复杂,表现类型也非常多样;既有上述提到的盗图和网络图,也有用户随手拍的风景图,还包括动漫截图等各式各样和商品无关的图片。
一方面,无关图以盗图、表情包、网络图等为主,通过哈希值过滤,能够过滤掉一批无关图;另一方面,即使过滤以后,预估仍然存在10%-15%左右的无关图。这部分无关图的解决较为复杂。
目前所采用的方案是,将盗图、表情包、网络图等重复图片作为负样本,将过审UGC图片作为正样本,通过ResNet提取图片特征,将类目通过embedding作为类目特征,将用户行为(发表重复图的数量和比例)作为用户特征,判断该UGC的图片是否是无关图。
就这样,大家终于又能愉快地欣赏美美的买家秀了~~
划重点
在此分享一些心得体会,希望能对大家有帮助:
数据强于特征,特征强于模型;贴近真实场景的数据对提升任务表现贡献巨大;
如果确实缺乏数据,不妨尝试快速标注数千条数据,可能取得超出预期的效果;
对ImageNet等数据集预训练的模型进行fine-tuning可以在小数据集往往能取得更好的问题;
通过图像翻转、旋转、随机裁剪等方法进行数据增强,可以提升模型泛化能力。
原文链接
本文为云栖社区原创内容,未经允许不得转载。