随着业务的快速发展,应用单体架构暴露出代码可维护性差、容错率低、测试难度大和敏捷交付能力差等诸多问题,微服务应运而生。微服务的诞生一方面解决了上述问题,但是另一方面却引入新的问题,其中主要问题之一就是:如何保证微服务间的业务数据一致性。
本文将通过一个商品采购的业务,来看看在Dubbo的微服务架构下,如何通过Fescar来保障业务的数据一致性。本文所述的例子中,Dubbo 和 Fescar 的注册配置服务中心均使用 Nacos。Fescar 0.2.1+ 开始支持 Nacos 注册配置服务中心。
业务描述
用户采购商品的业务,包含3个微服务:
- 库存服务: 扣减给定商品的库存数量。
- 订单服务: 根据采购请求生成订单。
- 账户服务: 用户账户金额扣减。
业务结构图如下:
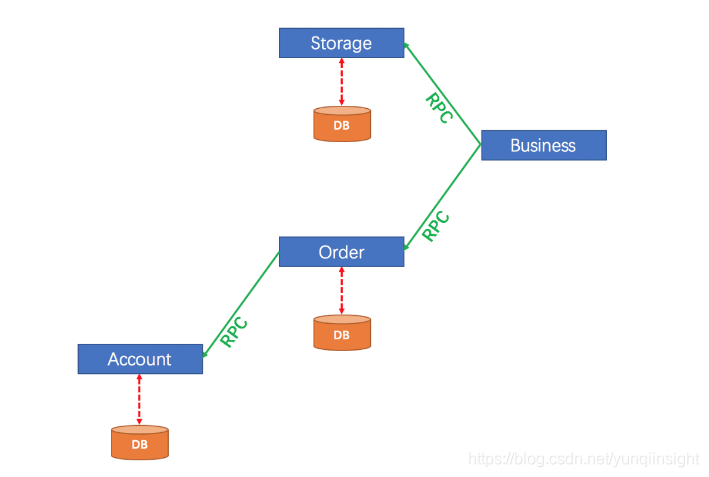
库存服务(StorageService)
public interface StorageService { /** * deduct storage count */void deduct(String commodityCode, int count);
}
订单服务(OrderService)
public interface OrderService { /** * create order */Order create(String userId, String commodityCode, int orderCount);
}
账户服务(AccountService)
public interface AccountService { /** * debit balance of user's account */void debit(String userId, int money);
}说明: 以上三个微服务均是独立部署。
8个步骤实现数据一致性
Step 1:初始化 MySQL 数据库(需要InnoDB 存储引擎)
在 resources/jdbc.properties 修改StorageService、OrderService、AccountService 对应的连接信息。
jdbc.account.url=jdbc:mysql://xxxx/xxxx
jdbc.account.username=xxxx
jdbc.account.password=xxxx
jdbc.account.driver=com.mysql.jdbc.Driver
# storage db config
jdbc.storage.url=jdbc:mysql://xxxx/xxxx
jdbc.storage.username=xxxx
jdbc.storage.password=xxxx
jdbc.storage.driver=com.mysql.jdbc.Driver
# order db config
jdbc.order.url=jdbc:mysql://xxxx/xxxx
jdbc.order.username=xxxx
jdbc.order.password=xxxx
jdbc.order.driver=com.mysql.jdbc.Driver
Step 2:创建 undo_log(用于Fescar AT 模式)表和相关业务表
相关建表脚本可在 resources/sql/ 下获取,在相应数据库中执行 dubbo_biz.sql 中的业务建表脚本,在每个数据库执行 undo_log.sql 建表脚本。
CREATE TABLE undo_log (
`id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`),KEY `idx_unionkey` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;DROP TABLE IF EXISTS `storage_tbl`;
CREATE TABLE `storage_tbl` ( `id` int(11) NOT NULL AUTO_INCREMENT, `commodity_code` varchar(255) DEFAULT NULL, `count` int(11) DEFAULT 0, PRIMARY KEY (`id`),UNIQUE KEY (`commodity_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `order_tbl`;
CREATE TABLE `order_tbl` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` varchar(255) DEFAULT NULL, `commodity_code` varchar(255) DEFAULT NULL, `count` int(11) DEFAULT 0, `money` int(11) DEFAULT 0, PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;DROP TABLE IF EXISTS `account_tbl`;
CREATE TABLE `account_tbl` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` varchar(255) DEFAULT NULL, `money` int(11) DEFAULT 0, PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
说明: 需要保证每个物理库都包含 undo_log 表,此处可使用一个物理库来表示上述三个微服务对应的独立逻辑库。
Step 3:引入 Fescar、Dubbo 和 Nacos 相关 POM 依赖
<properties><fescar.version>0.2.1</fescar.version><dubbo.alibaba.version>2.6.5</dubbo.alibaba.version><dubbo.registry.nacos.version>0.0.2</dubbo.registry.nacos.version></properties><dependency><groupId>com.alibaba.fescar</groupId><artifactId>fescar-spring</artifactId><version>${fescar.version}</version></dependency><dependency><groupId>com.alibaba.fescar</groupId><artifactId>fescar-dubbo-alibaba</artifactId><version>${fescar.version}</version><exclusions><exclusion><artifactId>dubbo</artifactId><groupId>org.apache.dubbo</groupId></exclusion></exclusions></dependency><dependency><groupId>com.alibaba</groupId><artifactId>dubbo</artifactId><version>${dubbo.alibaba.version}</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>dubbo-registry-nacos</artifactId><version>${dubbo.registry.nacos.version}</version></dependency>说明: 由于当前 apache-dubbo 与 dubbo-registry-nacos jar存在兼容性问题,需要排除 fescar-dubbo 中的 apache.dubbo 依赖并手动引入 alibaba-dubbo,后续 apache-dubbo(2.7.1+) 将兼容 dubbo-registry-nacos。在Fescar 中 fescar-dubbo jar 支持 apache.dubbo,fescar-dubbo-alibaba jar 支持 alibaba-dubbo。
Step 4:微服务 Provider Spring配置
分别在三个微服务Spring配置文件(dubbo-account-service.xml、 dubbo-order-service 和 dubbo-storage-service.xml )进行如下配置:
-
配置 Fescar 代理数据源
<bean id="accountDataSourceProxy" class="com.alibaba.fescar.rm.datasource.DataSourceProxy"><constructor-arg ref="accountDataSource"/> </bean><bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate"><property name="dataSource" ref="accountDataSourceProxy"/> </bean>此处需要使用 com.alibaba.fescar.rm.datasource.DataSourceProxy 包装 Druid 数据源作为直接业务数据源,DataSourceProxy 用于业务 SQL 的拦截解析并与 TC 交互协调事务操作状态。
-
配置 Dubbo 注册中心
<dubbo:registry address="nacos://${nacos-server-ip}:8848"/> -
配置 Fescar GlobalTransactionScanner
<bean class="com.alibaba.fescar.spring.annotation.GlobalTransactionScanner"><constructor-arg value="dubbo-demo-account-service"/><constructor-arg value="my_test_tx_group"/> </bean>此处构造方法的第一个参数为业务自定义 applicationId,若在单机部署多微服务需要保证 applicationId 唯一。
构造方法的第二个参数为 Fescar 事务服务逻辑分组,此分组通过配置中心配置项 service.vgroup_mapping.my_test_tx_group 映射到相应的 Fescar-Server 集群名称,然后再根据集群名称.grouplist 获取到可用服务列表。
Step 5:事务发起方配置
在 dubbo-business.xml 配置以下配置:
- 配置 Dubbo 注册中心
同 Step 4
- 配置 Fescar GlobalTransactionScanner
同 Step 4
-
在事务发起方 service 方法上添加 @GlobalTransactional 注解
@GlobalTransactional(timeoutMills = 300000, name = "dubbo-demo-tx")timeoutMills 为事务的总体超时时间默认60s,name 为事务方法签名的别名,默认为空。注解内参数均可省略。
Step 6:启动 Nacos-Server
- 下载 Nacos-Server 最新 release 包并解压
- 运行 Nacos-server
Linux/Unix/Mac
sh startup.sh -m standalone
Windows
cmd startup.cmd -m standalone
访问 Nacos 控制台:http://localhost:8848/nacos/index.html#/configurationManagement?dataId=&group=&appName=&namespace
若访问成功说明 Nacos-Server 服务运行成功(默认账号/密码: nacos/nacos)
Step 7:启动 Fescar-Server
- 下载 Fescar-Server 最新 release 包并解压
- 初始化 Fescar 配置
进入到 Fescar-Server 解压目录 conf 文件夹下,确认 nacos-config.txt 的配置值(一般不需要修改),确认完成后运行 nacos-config.sh 脚本初始化配置。
sh nacos-config.sh $Nacos-Server-IP
eg:
sh nacos-config.sh localhost
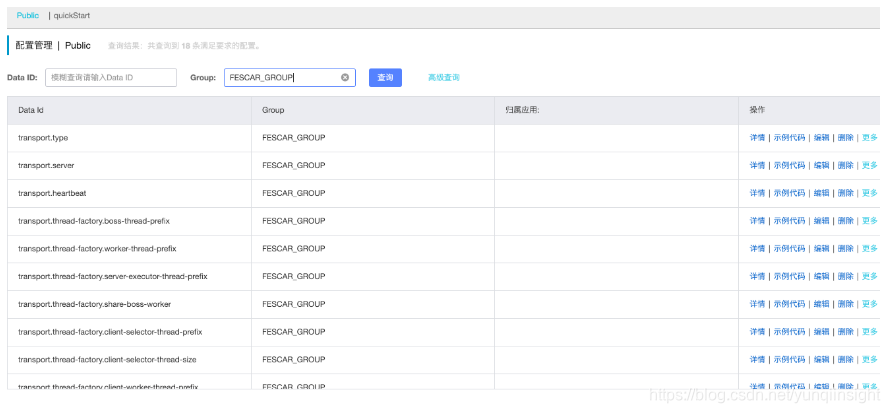
脚本执行最后输出 "init nacos config finished, please start fescar-server." 说明推送配置成功。若想进一步确认可登陆Nacos 控制台 配置列表 筛选 Group=FESCAR_GROUP 的配置项。
- 修改 Fescar-server 服务注册方式为 nacos
进入到 Fescar-Server 解压目录 conf 文件夹下 registry.conf 修改 type="nacos" 并配置 Nacos 的相关属性。
registry { # file nacostype = "nacos"nacos { serverAddr = "localhost"namespace = "public"cluster = "default"}file { name = "file.conf"}
}type: 可配置为 nacos 和 file,配置为 file 时无服务注册功能
nacos.serverAddr: Nacos-Sever 服务地址(不含端口号)
nacos.namespace: Nacos 注册和配置隔离 namespace
nacos.cluster: 注册服务的集群名称
file.name: type = "file" classpath 下配置文件名
- 运行 Fescar-server
Linux/Unix/Mac
sh fescar-server.sh $LISTEN_PORT $PATH_FOR_PERSISTENT_DATA $IP(此参数可选)
Windows
cmd fescar-server.bat $LISTEN_PORT $PATH_FOR_PERSISTENT_DATA $IP(此参数可选)
LISTENPORT:Fescar−Server服务端口PATH_FOR_PERSISTENT_DATA: 事务操作记录文件存储路径(已存在路径)
$IP(可选参数): 用于多 IP 环境下指定 Fescar-Server 注册服务的IP
eg: sh fescar-server.sh 8091 /home/admin/fescar/data/
运行成功后可在 Nacos 控制台看到 服务名 =serverAddr 服务注册列表:
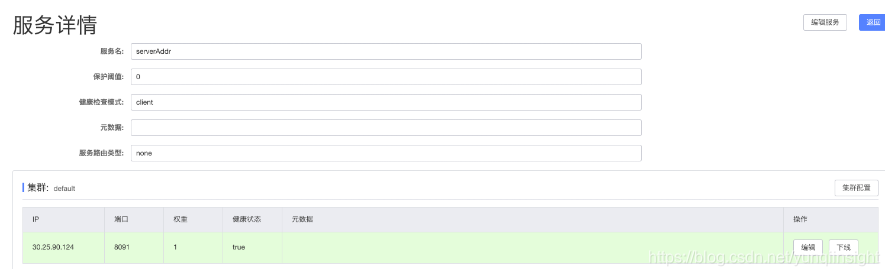
Step 8:启动微服务并测试
- 修改业务客户端发现注册方式为 nacos
同Step 7 中[修改 Fescar-server 服务注册方式为 nacos] 步骤
- 启动 DubboAccountServiceStarter
- 启动 DubboOrderServiceStarter
- 启动 DubboStorageServiceStarter
启动完成可在 Nacos 控制台服务列表 看到启动完成的三个 provider:
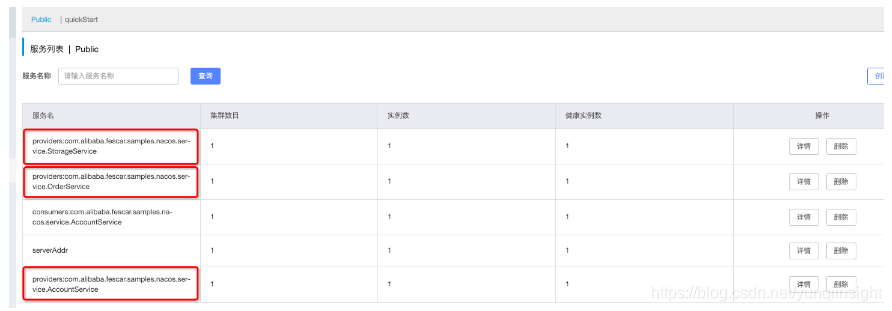
- 启动 DubboBusinessTester 进行测试
注意: 在标注 @GlobalTransactional 注解方法内部显示的抛出异常才会进行事务的回滚。整个 Dubbo 服务调用链路只需要在事务最开始发起方的 service 方法标注注解即可。
通过以上8个步骤,我们实现了用户采购商品的业务中库存、订单和账户3个独立微服务之间的数据一致性。
原文链接
本文为云栖社区原创内容,未经允许不得转载。





:一行代码从 Hystrix 迁移到 Sentinel)




)








