表格存储: 数据存储和数据消费All in one
表格存储(Table Store)是阿里云自研的NoSQL多模型数据库,提供PB级结构化数据存储、千万TPS以及毫秒级延迟的服务能力。在实时计算场景里,表格存储强大的写入能力和多模型的存储形态,使其不仅可以作为计算结果表,同时也完全具备作为实时计算源表的能力。
通道服务是表格存储提供的全增量一体化数据消费功能,为用户提供了增量、全量和增量加全它量三种类型的分布式数据实时消费通道。实时计算场景下,通过为数据表建立数据通道,用户可以以流式计算的方式对表中历史存量和新增数据做数据消费。
利用表格存储存储引擎强大的写入能力和通道服务完备的流式消费能力,用户可以轻松做到数据存储和实时处理all in one!
Blink: 流批一体的数据处理引擎
Blink是阿里云在Apache Flink基础上深度改进的实时计算平台,同Flink一致Blink旨在将流处理和批处理统一,但Blink相对于社区版Flink,在稳定性上有很多优化,在某些场景特别是在大规模场景会比Flink更加稳定。Blink的另一个重大改进是实现了全新的 Flink SQL 技术栈,在功能上,Blink支持现在标准 SQL 几乎所有的语法和语义,在性能上,Blink也比社区Flink更加强大,特别是在批 SQL 的性能方面,当前 Blink 版本是社区版本性能的 10 倍以上,跟 Spark 相比,在 TPCDS 这样的场景 Blink 的性能也能达到 3 倍以上[1]。
从用户技术架构角度分析,结合表格存储和Blink可以做到:1. 存储侧,使用表格存储,则可以做到写一份数据,业务立即可见,同时原生支持后续流式计算消费,无需业务双写;2. 计算侧,使用Blink流批一体处理引擎,可以统一流批计算架构,开发一套代码支持流批两个需求场景。
本文就将为大家介绍实时计算的最佳架构实践:基于表格存储和Blink的实时计算架构,并带快速体验基于表格存储和Blink的数据分析job。
更优的实时计算架构:基于表格存储和Blink的实时计算架构
我们以一个做态势感知的大数据分析系统为例,为大家阐述表格存储和Blink实时计算的架构优势。假如客户是大型餐饮企业CEO,连锁店遍布全国各地,CEO非常关心自己有没有服务好全国各地的吃货,比如台湾顾客和四川顾客在口味评价上会不会有不同?自己的菜品是否已经热度下降了?为了解决这些问题,CEO需要一个大数据分析系统,一方面可以实时监控各地菜品销售额信息,另一方面也希望能有定期的历史数据分析,能给出自己关心的客户变化趋势。
用技术角度来解读,就是客户需要:1. 客户数据的实时处理能力,持续聚合新增的订单信息,能大屏展示和以日报形式展示;2.对历史数据的离线分析能力,分析离线数据做态势感知、决策推荐。
经典的解决方案基本上基于Lambda大数据架构[2],如下图1,用户数据既需要进入消息队列系统(New Data Stream如Kafka)作为实时计算任务的输入源,又需要进入数据库系统(All Data如HBASE)来支持批处理系统,最终两者的结果写入数据库系统(MERGED VIEW),展示给用户。
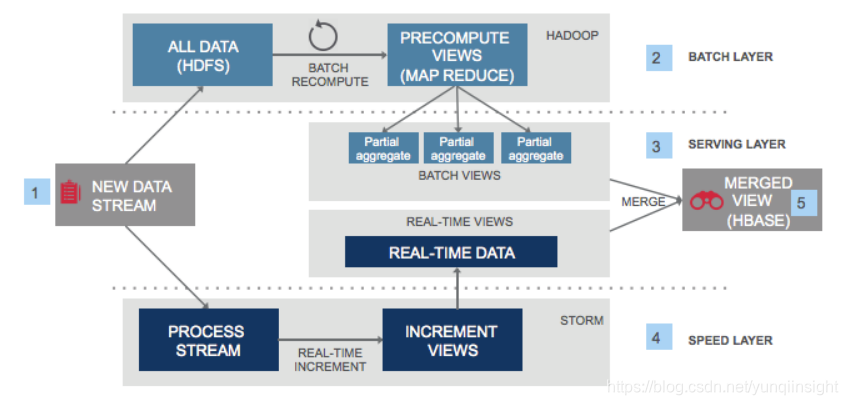
图-1 Lambda大数据架构
这个系统的缺点就是太庞大,需要维护多个分布式子系统,数据既要写入消息队列又要进入数据库,要处理两者的双写一致性或者维护两者的同步方案,计算方面要维护两套计算引擎、开发两套数据分析代码,技术难度和人力成本很高。
利用表格存储同时具备强大的写入能力、实时数据消费能力,Blink + SQL的高性能和流批融合,经典Lambda架构可以精简为下图2,基于表格存储和Blink的实时计算架构:
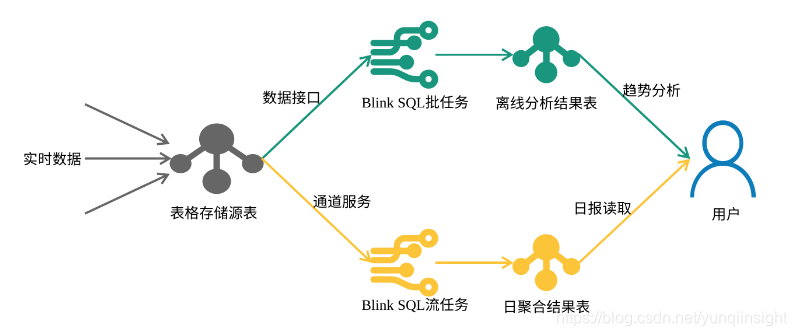
图-2 基于表格存储和Blink的实时计算架构
该架构引入的依赖系统大大减少,人力和资源成本都明显下降,它的基本流程只包括:
- 用户将在线订单数据或者系统抓取数据写入表格存储源表,源表创建通道服务数据通道;
- 实时计算任务(黄线),使用Blink表格存储数据源DDL定义SQL源表和结果表,开发和调试实时订单日聚合SQL job;
- 批处理计算任务(绿线),定义批处理源表结果表[1],开发历史订单分析SQL job;
- 前端服务通过读取表格存储结果表展示日报和历史分析结果;
快速开始
介绍完架构,我们就来迅速开发一个基于TableStore和Blink的日报实时计算SQL,以流计算的方式统计每日各个城市的实时用餐单数和餐费销售额。
- 在表格存储控制台创建消费订单表consume_source_table(primary key: id[string]),并在订单表->通道管理下建立增量通道blink-demo-stream, 创建日统计结果表result_summary_day(primary key: summary_date[string]);
-
在Blink开发界面,创建消费订单源表、日统计结果表、每分钟聚合视图和写入SQL:
---消费订单源表 CREATE TABLE source_order (id VARCHAR,-- 订单IDrestaurant_id VARCHAR, --餐厅IDcustomer_id VARCHAR,--买家IDcity VARCHAR,--用餐城市price VARCHAR,--餐费金额pay_day VARCHAR, --订单时间 yyyy-MM-ddprimary(id) ) WITH (type='ots',endPoint ='http://blink-demo.cn-hangzhou.ots-internal.aliyuncs.com',instanceName = "blink-demo",tableName ='consume_source_table',tunnelName = 'blink-demo-stream', );---日统计结果表 CREATE TABLE result_summary_day (summary_date VARCHAR,--统计日期total_price BIGINT,--订单总额total_order BIGINT,--订单数primary key (summary_date) ) WITH (type= 'ots',endPoint ='http://blink-demo.cn-hangzhou.ots-internal.aliyuncs.com',instanceName = "blink-demo",tableName ='result_summary_day',column='summary_date,total_price,total_order' );INSERT into result_summary_day select cast(pay_day as bigint) as summary_date, --时间分区 count(id) as total_order, --客户端的IP sum(price) as total_order, --客户端去重 from source_ods_fact_log_track_action group by pay_day; - 上线聚合SQL, 在表格存储源表写入订单数据,可以看到result_summary_day持续更新的日订单数,大屏展示系统可以根result_summary_day直接对接;
总结
使用表格存储和Blink的大数据分析架构,相对于传统开源解决方案,有很多优势:
1、强大的存储和计算引擎,表格存储除了海量存储、极高的读写性能外,还提供了多元索引、二级索引、通道服务等多种数据分析功能,相对HBASE等开源方案优势明显,Blink关键性能指标为开源Flink的3到4倍,数据计算延迟优化到秒级甚至亚秒级;
2、全托管服务,表格存储和Blink都全托管的serverless服务,即开即用;
3、低廉的人力和资源成本,依赖服务全serverless免运维,按量付费,避免波峰波谷影响;
篇幅原因,本文主要介绍了表格存储和Blink结合的大数据架构优势,以及简单SQL演示,后续更复杂、贴近场景业务的文章也会陆续推出,敬请期待!
原文链接
本文为云栖社区原创内容,未经允许不得转载。










)




,要求输出两个礼仪的身高。)



