uvm_component与uvm_object
1.
几乎所有的类都派生于uvm_object,包括uvm_component。
uvm_component有两大特性是uvm_object所没有的:
- 一是通过在new的时候指定parent参数来形成一种树形的组织结构;
- 二是有phase的自动执行特点。
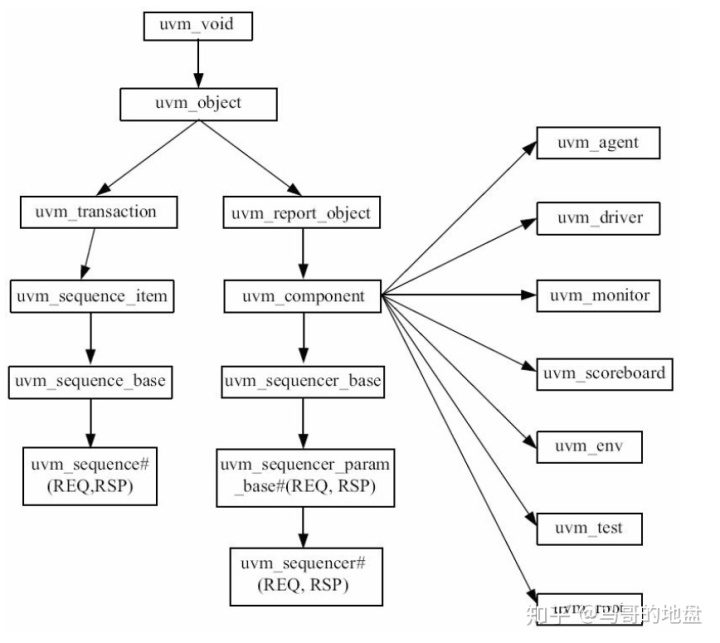
下图是常用的UVM继承关系:
从图中可以看出,从uvm_object派生出了两个分支,所有的UVM树的结点都是由uvm_component组成的,只有基于uvm_component派生的类才可能成为UVM树的结点;最左边分支的类或者直接派生自uvm_object的类,是不可能以结点的形式出现在UVM树上的。
2.
常用的派生自uvm_object类的有:
- uvm_sequence_item:读者定义的所有的transaction要从uvm_sequence_item派生。
- uvm_sequence:所有的sequence要从uvm_sequence派生。
- config:所有的config一般直接从uvm_object派生。config的主要功能就是规范验证平台的行为方式。之前我们已经见识了使用config_db进行参数配置,这里的config其实指的是把所有的参数放在一个object中。
- uvm_reg_item:它派生自uvm_sequence_item,用于register model中。
- uvm_reg_map、uvm_mem、uvm_reg_field、uvm_reg、uvm_reg_file、uvm_reg_block等与寄存器相关的众多的类都是派生自uvm_object,它们都是用于register model。
- uvm_phase:它派生自uvm_object,其主要作用为控制uvm_component的行为方式,使uvm_component平滑地在各个不同的phase之间依次运转。
常用的派生自uvm_component类的有:
- uvm_driver:所有的driver都要派生自uvm_driver。driver的功能主要就是向sequencer索要sequence_item(transaction),并且将sequence_item里的信息驱动到DUT的端口上,这相当于完成了从transaction级别到DUT能够接受的端口级别信息的转换。
- uvm_monitor:所有的monitor都要派生自uvm_monitor。monitor做的事情与driver相反,driver向DUT的pin上发送数据,而monitor则是从DUT的pin上接收数据,并且把接收到的数据转换成transaction级别的sequence_item,再把转换后的数据发送给scoreboard,供其做比较。
- uvm_scoreboard:一般的scoreboard都要派生自uvm_scoreboard。scoreboard的功能就是比较reference model和monitor分别发送来的数据,根据比较结果判断DUT是否正确工作。
- reference model:UVM中并没有针对reference model定义一个类。所以通常来说,reference model都是直接派生自uvm_component。reference model的作用就是模仿DUT,完成与DUT相同的功能。
- uvm_agent:所有的agent要派生自uvm_agent。与前面几个比起来,uvm_agent的作用并不是那么明显。它只是把driver和monitor封装在一起,根据参数值来决定是只实例化monitor还是要同时实例化driver和monitor。
- uvm_env:所有的env(environment的缩写)要派生自uvm_env。env将验证平台上用到的固定不变的component都封装在一起。这样,当要运行不同的测试用例时,只要在测试用例中实例化此env即可。
3.
在UVM中与uvm_object相关的factory宏有如下几个:
- uvm_object_utils:它用于把一个直接或间接派生自uvm_object的类注册到factory中。
- uvm_object_param_utils:它用于把一个直接或间接派生自uvm_object的参数化的类注册到factory中。
- uvm_object_utils_begin:这个宏在第2章介绍my_transaction时出现过,当需要使用field_automation机制时,需要使用此宏。
- uvm_object_param_utils_begin:与uvm_object_utils_begin宏一样,只是它适用于参数化的且其中某些成员变量要使用field_automation机制实现的类。
- uvm_object_utils_end:它总是与uvm_object_*_begin成对出现,作为factory注册的结束标志。
在UVM中与uvm_component相关的factory宏有如下几个:
- uvm_component_utils:它用于把一个直接或间接派生自uvm_component的类注册到factory中。
- uvm_component_param_utils:它用于把一个直接或间接派生自uvm_component的参数化的类注册到factory中。
- uvm_component_utils_begin:这个宏与uvm_object_utils_begin相似,它用于同时需要使用factory机制和field_automation机制注册的类。注意主要为了可以自动地使用config_db来得到某些变量的值,而不是在component中使用field_automation机制。
- uvm_component_param_utils_begin:与uvm_component_utils_begin宏一样,只是它适用于参数化的,且其中某些成员变量要使用field_automation机制实现的类。
- uvm_component_utils_end:它总是与uvm_component_*_begin成对出现,作为factory注册的结束标志。
4.
虽说uvm_component是从uvm_object派生来的,但作为UVM的结点,这使得其失去了某些uvm_object的特性。
比如在uvm_object中有clone函数,它用于分配一块内存空间,并把另一个实例复制到这块新的内存空间中。clone函数的使用方式如下:
class A extends uvm_object;…
endclassclass my_env extends uvm_env;virtual function void build_phase(uvm_phase phase);A a1;A a2;a1 = new("a1");a1.data = 8'h9;$cast(a2, a1.clone());endfunction
endclass
上述的clone函数无法用于uvm_component中,因为一旦使用后,新clone出来的类,其parent参数无法指定。
虽然uvm_component无法使用clone函数,但是可以使用copy函数。因为在调用copy之前,目标实例已经完成了实例化,其parent参数已经指定了。
UVM的树形结构
1.
一般在使用时,parent通常都是this。假设A和B均派生自uvm_component,在A中实例化一个B:
class B extends uvm_component;…
endclass
class A extends uvm_component;B b_inst;virtual function void build_phase(uvm_phase phase);b_inst = new("b_inst", this);endfunction
endclass
在b_inst实例化的时候,把this指针传递给了它,代表A是b_inst的parent。一种常见的观点是,b_inst是A的成员变量,自然而然的,A就是b_inst的parent了。
当b_inst实例化的时候,指定一个parent的变量,同时在每一个component的内部维护一个数组 m_children,当b_inst实例化时,就把b_inst的指针加入到A的m_children数组中。只有这样才能让A知道b_inst是自己的孩子,同时也才能让b_inst知道A是自己的父母。当b_inst有了自己的孩子时,即在b_inst的m_children中加入孩子的指针。
2.
树根应该就是uvm_test。在测试用例里实例化env,在env里实例化scoreboard、reference model、agent、在agent里面实例化sequencer、driver和monitor。
UVM中真正的树根是一个称为uvm_top的东西,完整的UVM树如下图所示。
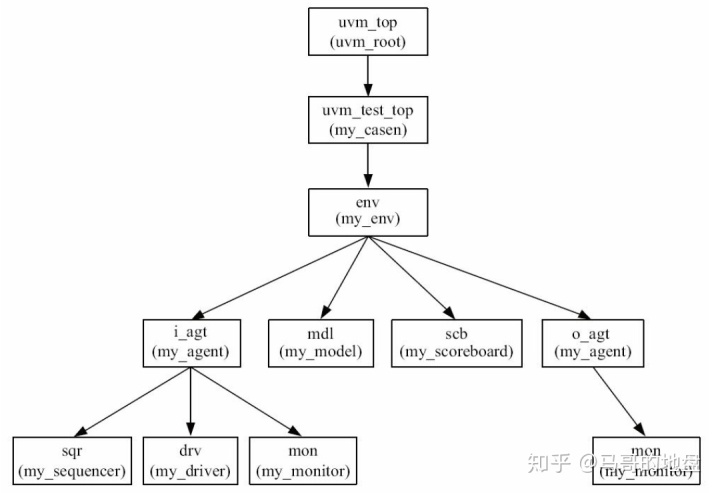
uvm_top是一个全局变量,它是uvm_root的一个实例。而uvm_root派生自uvm_component,所以uvm_top本质上是一个uvm_component。uvm_test_top的parent是uvm_top,而uvm_top的parent则是null。
如果一个component在实例化时,其parent被设置为null,那么这个component的parent将会被系统设置为系统中唯一的uvm_root的实例uvm_top。如下图所示:

可见,uvm_root的存在可以保证整个验证平台中只有一棵树,所有结点都是uvm_top的子结点。
而在之前我们的验证平台中这个parent被设置为null的节点为my_casen,因此其被设置为系统中唯一的uvm_root的实例uvm_top,而我们可以在仿真编译时通过UVM_TESTNAME来指定选择哪个case来进行仿真测试。
另外这里my_casen派生自base_test,但并不因此增加UVM的层级,因此其parent为null。
在验证平台中,有时候需要得到uvm_top,由于uvm_top是一个全局变量,可以直接使用uvm_top。除此之外,还可以使用如下的方式得到它的指针:
uvm_root top;
top=uvm_root::get();
3.
UVM提供了一系列的接口函数用于访问UVM树中的结点。这其中最主要的是以下几个:
- get_parent函数,用于得到当前实例的parent。
extern virtual function uvm_component get_parent ();
- 与get_parent相对的就是get_child函数。与get_parent不同的是,get_child需要一个string类型的参数name,表示此child实例在实例化时指定的名字。因为一个component只有一个parent,所以get_parent不需要指定参数;而可能有多个child,所以必须指定name参数。
extern function uvm_component get_child (string name);
- 为了得到所有的child,可以使用get_children函数:
extern function void get_children(ref uvm_component children[$]);
使用方法为:
uvm_component array[$];
my_comp.get_children(array);
foreach(array[i])do_something(array[i]);//自定义函数
- 除了一次性得到所有的child外,还可以使用get_first_child和get_next_child的组合依次得到所有的child:
string name;
uvm_component child;
if (comp.get_first_child(name))
do beginchild = comp.get_child(name);child.print();
end while (comp.get_next_child(name));
这两个函数的使用依赖于一个string类型的name。在这两个函数的原型中,name是作为ref类型传递的
extern function int get_first_child (ref string name);
extern function int get_next_child (ref string name);
- get_num_children函数用于返回当前component所拥有的child的数量:
extern function int get_num_children ();
field automation机制
1.
最简单的uvm_field系列宏有如下几种:
`define uvm_field_int(ARG,FLAG)
`define uvm_field_real(ARG,FLAG)
`define uvm_field_enum(T,ARG,FLAG)
`define uvm_field_object(ARG,FLAG)
`define uvm_field_event(ARG,FLAG)
`define uvm_field_string(ARG,FLAG)
上述几个宏分别用于要注册的字段是整数、实数、枚举类型、直接或间接派生自uvm_object的类型、事件及字符串类型。
与动态数组有关的uvm_field系列宏有:
`define uvm_field_array_enum(ARG,FLAG)
`define uvm_field_array_int(ARG,FLAG)
`define uvm_field_array_object(ARG,FLAG)
`define uvm_field_array_string(ARG,FLAG)
与静态数组相关的uvm_field系列宏有:
`define uvm_field_sarray_int(ARG,FLAG)
`define uvm_field_sarray_enum(ARG,FLAG)
`define uvm_field_sarray_object(ARG,FLAG)
`define uvm_field_sarray_string(ARG,FLAG)
与队列相关的uvm_field系列宏有:
`define uvm_field_queue_enum(ARG,FLAG)
`define uvm_field_queue_int(ARG,FLAG)
`define uvm_field_queue_object(ARG,FLAG)
`define uvm_field_queue_string(ARG,FLAG)
与联合数组相关的uvm_field宏有:
`define uvm_field_aa_int_string(ARG, FLAG)
`define uvm_field_aa_string_string(ARG, FLAG)
`define uvm_field_aa_object_string(ARG, FLAG)
`define uvm_field_aa_int_int(ARG, FLAG)
`define uvm_field_aa_int_int_unsigned(ARG, FLAG)
`define uvm_field_aa_int_integer(ARG, FLAG)
`define uvm_field_aa_int_integer_unsigned(ARG, FLAG)
`define uvm_field_aa_int_byte(ARG, FLAG)
`define uvm_field_aa_int_byte_unsigned(ARG, FLAG)
`define uvm_field_aa_int_shortint(ARG, FLAG)
`define uvm_field_aa_int_shortint_unsigned(ARG, FLAG)
`define uvm_field_aa_int_longint(ARG, FLAG)
`define uvm_field_aa_int_longint_unsigned(ARG, FLAG)
`define uvm_field_aa_string_int(ARG, FLAG)
`define uvm_field_aa_object_int(ARG, FLAG)
联合数组有两大识别标志,一是索引的类型,二是存储数据的类型。在这一系列uvm_field宏中,出现的第一个类型是存储数据类型,第二个类型是索引类型,如uvm_field_aa_int_string用于声明那些存储的数据是int,而其索引是string类型的联合数组。
2.
field automation机制的常用函数有:
- copy函数用于实例的复制,其原型为:
extern function void copy (uvm_object rhs);
如果要把某个A实例复制到B实例中,那么应该使用B.copy(A)。在使用此函数前,B实例必须已经使用new函数分配好了内存空间。
- compare函数用于比较两个实例是否一样,其原型为:
extern function bit compare (uvm_object rhs, uvm_comparer comparer=null);
如果要比较A与B是否一样,可以使用A.compare(B),也可以使用B.compare(A)。当两者一致时,返回1;否则为0。
- pack_bytes函数用于将所有的字段打包成byte流,其原型为:
extern function int pack_bytes (ref byte unsigned bytestream[],input uvm_packer packer=null);
- unpack_bytes函数用于将一个byte流逐一恢复到某个类的实例中,其原型为:
extern function int unpack_bytes (ref byte unsigned bytestream[],
input uvm_packer packer=null);
- pack函数用于将所有的字段打包成bit流,其原型为:
extern function int pack (ref bit bitstream[],input uvm_packer packer=null);
- pack函数的使用与pack_bytes类似。unpack函数用于将一个bit流逐一恢复到某个类的实例中,unpack的使用与unpack_bytes类似。
extern function int unpack (ref bit bitstream[],input uvm_packer packer=null);
- pack_ints函数用于将所有的字段打包成int(4个byte,或者dword)流。
- unpack_ints函数用于将一个int流逐一恢复到某个类的实例中
- print函数用于打印所有的字段。
- clone函数
- 除了上述函数之外,field automation机制还提供自动得到使用config_db::set设置的参数的功能,之前讲过,这里不再赘述。
3.
在post_randomize中计算CRC前先检查一下crc_err字段,如果为1,那么直接使用随机值,否则使用真实的CRC。
class my_transaction extends uvm_sequence_item;rand bit[47:0] dmac;rand bit[47:0] smac;rand bit[15:0] ether_type;rand byte pload[];rand bit[31:0] crc;rand bit crc_err;function void post_randomize();if(crc_err);//do nothingelsecrc = calc_crc;endfunction
endclass
在sequence中可以使用如下方式产生CRC错误的激励:
`uvm_do_with(tr, {tr.crc_err == 1;})
这里在后面的控制域中加入UVM_NOPACK的形式来实现对crc的控制。
`uvm_object_utils_begin(my_transaction)
`uvm_field_int(dmac, UVM_ALL_ON)
`uvm_field_int(smac, UVM_ALL_ON)
`uvm_field_int(ether_type, UVM_ALL_ON)
`uvm_field_array_int(pload, UVM_ALL_ON)
`uvm_field_int(crc, UVM_ALL_ON)
`uvm_field_int(crc_err, UVM_ALL_ON | UVM_NOPACK)
`uvm_object_utils_end
UVM的这些标志位本身其实是一个17bit的数字:
parameter UVM_ALL_ON = 'b000000101010101;
parameter UVM_COPY = (1<<0);
parameter UVM_NOCOPY = (1<<1);
parameter UVM_COMPARE = (1<<2);
parameter UVM_NOCOMPARE = (1<<3);
parameter UVM_PRINT = (1<<4);
parameter UVM_NOPRINT = (1<<5);
parameter UVM_RECORD = (1<<6);
parameter UVM_NORECORD = (1<<7);
parameter UVM_PACK = (1<<8);
parameter UVM_NOPACK = (1<<9);
在这个17bit的数字中,bit0表示copy,bit1表示no_copy,bit2表示compare,bit3表示no_compare,bit4表示print,bit5表示no_print,bit6表示record,bit7表示no_record,bit8表示pack,bit9表示no_pack。剩余的7bit则另有它用,这里不做讨论。UVM_ALL_ON的值是’b000000101010101,表示打开copy、compare、print、record、pack功能。UVM_ALL_ON|UVM_NOPACK的结果就是‘b000001101010101。这样UVM 在执行pack操作时,首先检查bit9,发现其为1,直接忽略bit8所代表的UVM_PACK。
4.
class my_transaction extends uvm_sequence_item;rand bit[47:0] smac;rand bit[47:0] dmac;rand bit[31:0] vlan[];rand bit[15:0] eth_type;rand byte pload[];rand bit[31:0] crc;`uvm_object_utils_begin(my_transaction)`uvm_field_int(smac, UVM_ALL_ON)`uvm_field_int(dmac, UVM_ALL_ON)`uvm_field_array_int(vlan, UVM_ALL_ON)`uvm_field_int(eth_type, UVM_ALL_ON)`uvm_field_array_int(pload, UVM_ALL_ON)`uvm_object_utils_end
endclass
在随机化普通以太网帧时,可以使用如下的方式:
my_transaction tr;
tr = new();
assert(tr.randomize() with {vlan.size() == 0;});
协议中规定vlan的字段固定为4个字节,所以在随机化VLAN帧时,可以使用如下的方式:
my_transaction tr;
tr = new();
assert(tr.randomize() with {vlan.size() == 1;});
协议中规定vlan的4个字节各自有其不同的含义,这4个字节分别代表4个不同的字段。如果使用上面的方式,问题虽然解决了,但是这4个字段的含义不太明确。 一个可行的解决方案是:
class my_transaction extends uvm_sequence_item;rand bit[47:0] dmac;rand bit[47:0] smac;rand bit[15:0] vlan_info1;rand bit[2:0] vlan_info2;rand bit vlan_info3;rand bit[11:0] vlan_info4;rand bit[15:0] ether_type;rand byte pload[];rand bit[31:0] crc;rand bit is_vlan;`uvm_object_utils_begin(my_transaction)`uvm_field_int(dmac, UVM_ALL_ON)`uvm_field_int(smac, UVM_ALL_ON)if(is_vlan)begin`uvm_field_int(vlan_info1, UVM_ALL_ON)`uvm_field_int(vlan_info2, UVM_ALL_ON)`uvm_field_int(vlan_info3, UVM_ALL_ON)`uvm_field_int(vlan_info4, UVM_ALL_ON)end`uvm_field_int(ether_type, UVM_ALL_ON)`uvm_field_array_int(pload, UVM_ALL_ON)`uvm_field_int(crc, UVM_ALL_ON | UVM_NOPACK)`uvm_field_int(is_vlan, UVM_ALL_ON | UVM_NOPACK)`uvm_object_utils_end
endclass
在随机化普通以太网帧时,可以使用如下的方式:
my_transaction tr;
tr = new();
assert(tr.randomize() with {is_vlan == 0;});
在随机化VLAN帧时,可以使用如下的方式:
my_transaction tr;
tr = new();
assert(tr.randomize() with {is_vlan == 1;});
使用这种方式的VLAN帧,在执行print操作时,4个字段的信息将会非常明显;在调用compare函数时,如果两个transaction不同,将会更加明确地指明是哪个字段不一样。
UVM中打印信息的控制
1.
UVM通过冗余度级别的设置提高了仿真日志的可读性。在打印信息之前,UVM会比较要显示信息的冗余度级别与默认的冗余度阈值,如果小于等于阈值,就会显示,否则不会显示。默认的冗余度阈值是UVM_MEDIUM,所有低于等于UVM_MEDIUM(如UVM_LOW)的信息都会被打印出来。
可以通过get_report_verbosity_level函数得到某个component的冗余度阈值:
virtual function void connect_phase(uvm_phase phase);$display("env.i_agt.drv's verbosity level is %0d", env.i_agt.drv.get_report_verbosity_level());
endfunction
这个函数得到的是一个整数,它代表的含义如下所示:
typedef enum
{UVM_NONE = 0,UVM_LOW = 100,UVM_MEDIUM = 200,UVM_HIGH = 300,UVM_FULL = 400,UVM_DEBUG = 500
} uvm_verbosity;
UVM提供set_report_verbosity_level函数来设置某个特定component的默认冗余度阈值。在base_test中将driver的冗余度阈值设置为UVM_HIGH(UVM_LOW、UVM_MEDIUM、UVM_HIGH的信息都会被打印)代码为:
virtual function void connect_phase(uvm_phase phase);env.i_agt.drv.set_report_verbosity_level(UVM_HIGH);
endfunction
把env.i_agt及其下所有的component的冗余度阈值设置为UVM_HIGH的代码为:
env.i_agt.set_report_verbosity_level_hier(UVM_HIGH);
set_report_verbosity_level会对某个component内所有的uvm_info宏显示的信息产生影响。如果这些宏在调用时使用了不同的ID:
`uvm_info("ID1", "ID1 INFO", UVM_HIGH)
`uvm_info("ID2", "ID2 INFO", UVM_HIGH)
那么可以使用set_report_id_verbosity函数来区分不同的ID的冗余度阈值:
env.i_agt.drv.set_report_id_verbosity("ID1", UVM_HIGH);
除了在代码中设置外,UVM支持在命令行中设置冗余度阈值:
<sim command> +UVM_VERBOSITY=UVM_HIGH
或者:
<sim command> +UVM_VERBOSITY=HIGH
上述的命令行参数会把整个验证平台的冗余度阈值设置为UVM_HIGH。它几乎相当于是在base_test中调用 set_report_verbosity_level_hier函数,把base_test及以下所有component的冗余度级别设置为UVM_HIGH:
set_report_verbosity_level_hier(UVM_HIGH)
综上,通过设置不同env的冗余度级别,可以更好地控制整个芯片验证环境输出信息的质量。
2.
UVM默认有四种信息严重性:UVM_INFO、UVM_WARNING、UVM_ERROR、UVM_FATAL。这四种严重性可以互相重载。如果要把driver中所有的UVM_WARNING显示为UVM_ERROR,可以使用如下的函数:
virtual function void connect_phase(uvm_phase phase);env.i_agt.drv.set_report_severity_override(UVM_WARNING, UVM_ERROR);//env.i_agt.drv.set_report_severity_id_override(UVM_WARNING, "my_driver", UVM_ERROR);
endfunction
重载严重性可以只针对某个component内的某个特定的ID起作用:
env.i_agt.drv.set_report_severity_id_override(UVM_WARNING, "my_driver", UVM_ERROR);
3.
当uvm_fatal出现时,表示出现了致命错误,仿真会马上停止。UVM同样支持UVM_ERROR达到一定数量时结束仿真。实现这个功能的是set_report_max_quit_count函数,其调用方式为:
function void base_test::build_phase(uvm_phase phase);super.build_phase(phase);env = my_env::type_id::create("env", this);set_report_max_quit_count(5);
endfunction
与set_max_quit_count相对应的是get_max_quit_count,可以用于查询当前的退出阈值。
除了在代码中使用set_max_quit_count设置外,还可以在命令行中设置退出阈值:
<sim command> +UVM_MAX_QUIT_COUNT=6,NO
在上一节中,当UVM_ERROR达到一定数量时,可以自动退出仿真。在计数当中,是不包含UVM_WARNING的。可以通过设置set_report_severity_action函数来把UVM_WARNING加入计数目标:
virtual function void connect_phase(uvm_phase phase);set_report_max_quit_count(5);env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY|UVM_COUNT);
endfunction
类似的递归调用方式:
env.i_agt.set_report_severity_action_hier(UVM_WARNING, UVM_DISPLAY| UVM_COUNT);
上述代码把env.i_agt及其下所有结点的UVM_WARNING加入到计数目标中。
除了针对严重性进行计数外,还可以对某个特定的ID进行计数:
env.i_agt.drv.set_report_id_action("my_drv", UVM_DISPLAY| UVM_COUNT);
4.
在程序调试时,断点功能是非常有用的一个功能。在程序运行时,预先在某语句处设置一断点。当程序执行到此处时,停止仿真,进入交互模式,从而进行调试。
当env.i_agt.drv中出现UVM_WARNING时,立即停止仿真,进入交互模式。
virtual function void connect_phase(uvm_phase phase);env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY| UVM_STOP);
endfunction
5.
UVM提供将特定信息输出到特定日志文件的功能:
将env.i_agt.drv的UVM_INFO输出到info.log,UVM_WARNING输出到warning.log,UVM_ERROR输出到error.log,UVM_FATAL输出到fatal.log。这里用到了set_report_severity_file函数。
UVM_FILE info_log;
UVM_FILE warning_log;
UVM_FILE error_log;
UVM_FILE fatal_log;
virtual function void connect_phase(uvm_phase phase);info_log = $fopen("info.log", "w");warning_log = $fopen("warning.log", "w");error_log = $fopen("error.log", "w");fatal_log = $fopen("fatal.log", "w");env.i_agt.drv.set_report_severity_file(UVM_INFO, info_log);env.i_agt.drv.set_report_severity_file(UVM_WARNING, warning_log);env.i_agt.drv.set_report_severity_file(UVM_ERROR, error_log);env.i_agt.drv.set_report_severity_file(UVM_FATAL, fatal_log);env.i_agt.drv.set_report_severity_action(UVM_INFO, UVM_DISPLAY| UVM_LOG);env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY|UVM_LOG);env.i_agt.drv.set_report_severity_action(UVM_ERROR, UVM_DISPLAY| UVM_COUNT | UVM_LOG);env.i_agt.drv.set_report_severity_action(UVM_FATAL, UVM_DISPLAY|UVM_EXIT | UVM_LOG);
endfunction
这个函数同样有递归调用方式:
env.i_agt.set_report_severity_file_hier(UVM_INFO, info_log);
env.i_agt.set_report_severity_file_hier(UVM_WARNING, warning_log);
env.i_agt.set_report_severity_file_hier(UVM_ERROR, error_log);
env.i_agt.set_report_severity_file_hier(UVM_FATAL, fatal_log);
env.i_agt.set_report_severity_action_hier(UVM_INFO, UVM_DISPLAY| UVM_LOG);
env.i_agt.set_report_severity_action_hier(UVM_WARNING, UVM_DISPLAY| UVM_LOG);
env.i_agt.set_report_severity_action_hier(UVM_ERROR, UVM_DISPLAY| UVM_COUNT |UVM_LOG);
env.i_agt.set_report_severity_action_hier(UVM_FATAL, UVM_DISPLAY| UVM_EXIT | UVM_LOG);
当然除了根据严重性设置不同的日志文件外,UVM中还可以根据不同的ID来设置不同的日志文件:
UVM_FILE driver_log;
UVM_FILE drv_log;
virtual function void connect_phase(uvm_phase phase);driver_log = $fopen("driver.log", "w");drv_log = $fopen("drv.log", "w");env.i_agt.drv.set_report_id_file("my_driver", driver_log);env.i_agt.drv.set_report_id_file("my_drv", drv_log);env.i_agt.drv.set_report_id_action("my_driver", UVM_DISPLAY| UVM_LOG);env.i_agt.drv.set_report_id_action("my_drv", UVM_DISPLAY| UVM_LOG);
endfunction
virtual function void final_phase(uvm_phase phase);$fclose(driver_log);$fclose(drv_log);
endfunction
当然也有递归调用方式:
env.i_agt.set_report_id_file_hier("my_driver", driver_log);
env.i_agt.set_report_id_file_hier("my_drv", drv_log);
env.i_agt.set_report_id_action_hier("my_driver", UVM_DISPLAY| UVM_LOG);
env.i_agt.set_report_id_action_hier("my_drv", UVM_DISPLAY| UVM_LOG);
UVM还可以根据严重性和ID的组合来设置不同的日志文件:
UVM_FILE driver_log;
UVM_FILE drv_log;
virtual function void connect_phase(uvm_phase phase);driver_log = $fopen("driver.log", "w");drv_log = $fopen("drv.log", "w");env.i_agt.drv.set_report_severity_id_file(UVM_WARNING, "my_driver",driver_log);env.i_agt.drv.set_report_severity_id_file(UVM_INFO, "my_drv", drv_log);env.i_agt.drv.set_report_id_action("my_driver", UVM_DISPLAY| UVM_LOG);env.i_agt.drv.set_report_id_action("my_drv", UVM_DISPLAY| UVM_LOG);
endfunction
6.
UVM共定义了如下几种行为:
typedef enum
{UVM_NO_ACTION = 'b000000,UVM_DISPLAY = 'b000001,UVM_LOG = 'b000010,UVM_COUNT = 'b000100,UVM_EXIT = 'b001000,UVM_CALL_HOOK = 'b010000,UVM_STOP = 'b100000
} uvm_action_type;
与field automation机制中定义UVM_ALL_ON类似,这里也把UVM_DISPLAY等定义为一个整数。不同的行为有不同的位偏移,所以不同的行为可以使用“或”的方式组合在一起:
UVM_DISPLAY| UVM_COUNT | UVM_LOG
其中
- UVM_NO_ACTION是不做任何操作;
- UVM_DISPLAY是输出到标准输出上;
- UVM_LOG是输出到日志文件中,它能工作的前提是设置好了日志文件;
- UVM_COUNT是作为计数目标;
- UVM_EXIT是直接退出仿真;
- UVM_CALL_HOOK是调用一个回调函数;
- UVM_STOP是停止仿真,进入命令行交互模式。
默认情况下,UVM作如下的设置:
set_severity_action(UVM_INFO, UVM_DISPLAY);
set_severity_action(UVM_WARNING, UVM_DISPLAY);
set_severity_action(UVM_ERROR, UVM_DISPLAY | UVM_COUNT);
set_severity_action(UVM_FATAL, UVM_DISPLAY | UVM_EXIT);
从UVM_INFO到UVM_FATAL,都会输出到标准输出中;UVM_ERROR会作为仿真退出计数器的计数目标;出现 UVM_FATAL时会自动退出仿真。之前是通过设置信息的冗余级别来打开或关闭信息的现实,其实也可以通过设置为UVM_NO_ACTION来实现。
virtual function void connect_phase(uvm_phase phase);env.i_agt.drv.set_report_severity_action(UVM_INFO, UVM_NO_ACTION);
endfunction
无论原本的冗余度是什么,经过上述设置后,env.i_agt.drv的所有的uvm_info信息都不会输出。
config_db机制
1.
一个component(如my_driver)内通过get_full_name()函数可以得到此component的路径:
function void my_driver::build_phase();super.build_phase(phase);$display("%s", get_full_name());
endfunction
上述代码如果是在层次结构中的my_driver中,那么打印出来的值是uvm_test_top.env.i_agt.drv。
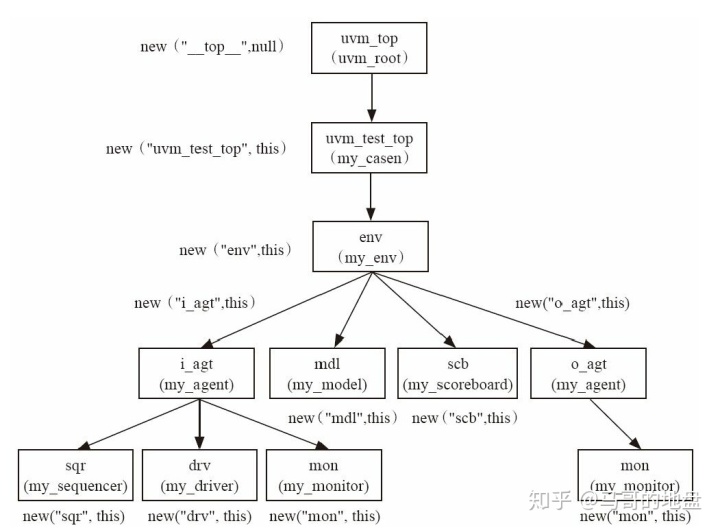
为了方便,上图使用了new函数而不是factory式的create方式来创建实例。在这幅图中,uvm_test_top实例化时的名字是uvm_test_top,这个名字是由UVM在run_test时自动指定的。uvm_top的名字是__top__,但是在显示路径的时候,并不会显示出这个名字,而只显示从uvm_test_top开始的路径。
2.
config_db机制用于在UVM验证平台间传递参数。它们通常都是成对出现的。set函数是寄信,而get函数是收信。如在某个测试用例的build_phase中可以使用如下方式寄信:
uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 100);
其中第一个和第二个参数联合起来组成目标路径,与此路径符合的目标才能收信。第一个参数必须是一个uvm_component实例的指针,第二个参数是相对此实例的路径。第三个参数表示一个记号,用以说明这个值是传给目标中的哪个成员的,第四个参数是要设置的值。
在driver中的build_phase使用如下方式收信:
uvm_config_db#(int)::get(this, "", "pre_num", pre_num);
get函数中的第一个参数和第二个参数联合起来组成路径。第一个参数也必须是一个uvm_component实例的指针,第二个参数是相对此实例的路径。一般的,如果第一个参数被设置为this,那么第二个参数可以是一个空的字符串。第三个参数就是set函数中的第三个参数,这两个参数必须严格匹配,第四个参数则是要设置的变量。
在之前的例子中,在top_tb中通过config_db机制的set函数设置virtual interface时,set函数的第一个参数为null。在这种情况下,UVM会自动把第一个参数替换为uvm_root::get(),即uvm_top。换句话说,以下两种写法是完全等价的:
initial beginuvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env.i_agt.drv", "vif", input_if);
end
initial beginuvm_config_db#(virtual my_if)::set(uvm_root::get(), "uvm_test_top.env.i_ag t. drv", "vif", input_if);
end
既然set函数的第一个和第二个参数联合起来组成路径,那么在某个测试用例的build_phase中可以通过如下的方式设置env.i_agt.drv中pre_num_max的值:
uvm_config_db#(int)::set(this.env, "i_agt.drv", "pre_num_max", 100);
因为前两个参数组合而成的路径和之前的写法一致。
set函数的参数可以使用这种灵活的方式设置,同样的,get函数的参数也可以。在driver的build_phase中:
uvm_config_db#(int)::get(this.parent, "drv", "pre_num_max", pre_num_max);
或者:
uvm_config_db#(int)::get(null, "uvm_test_top.env.i_agt.drv", "pre_num_max", p re_num_max);
整个过程可以形象地这么去理解:
张三给李四寄了一封信,信上写了李四的名字,这样李四可以收到信。但是呢,由于保密的需要,张三只是在信上写了“四”这一个字,只要张三跟李四事先约定好了,那么李四一看到上面写着“四”的信就会收下来。
uvm_config_db#(int)::set(this, "env.i_agt.drv", "p_num", 100);
uvm_config_db#(int)::get(this, "", "p_num", pre_num);
3.
假设在my_driver中有成员变量pre_num,其使用uvm_field_int实现field automation机制:
int pre_num;
`uvm_component_utils_begin(my_driver)`uvm_field_int(pre_num, UVM_ALL_ON)
`uvm_component_utils_end
function new(string name = "my_driver", uvm_component parent = null);super.new(name, parent);pre_num = 3;
endfunction
virtual function void build_phase(uvm_phase phase);`uvm_info("my_driver", $sformatf("before super.build_phase, the pre_num is %0d", pre_num),super.build_phase(phase);`uvm_info("my_driver", $sformatf("after super.build_phase, the pre_num is %0d", pre_num),if(!uvm_config_db#(virtual my_if)::get(this, "", "vif", vif))`uvm_fatal("my_driver", "virtual interface must be set for vif!!!")
endfunction
只要使用uvm_field_int注册,并且在build_phase中调用super.build_phase(),就可以省略在build_phase中的如下get语句:
uvm_config_db#(int)::get(this, "", "pre_num", pre_num);
这里的关键是build_phase中的super.build_phase语句,当执行到driver的super.build_phase时,会自动执行get语句。这种做法的前提是:
- 第一,my_driver必须使用uvm_component_utils宏注册;
- 第二,pre_num必须使用uvm_field_int宏注册;
- 第三,在调用set函数的时候,set函数的第三个参数必须与要get函数中变量的名字相一致,即必须是pre_num。
所以上节中,虽然说这两个参数可以不一致,但是最好的情况下还是一致。李四的信就是给李四的,不要打什么暗语,用一个“四”来代替李四。
4.
在前面的所有例子中,都是设置一次,获取一次。但是假如设置多次,而只获取一次,即跨层次的多重设置时,UVM采用如下机制决定最终收到信息的内容,即:先看发信人,哪个发信人最权威就听谁的,当同一个发信人先后发了两封信时,那么最近收到的一封权威高,也就是发信人的优先级最高,而时间的优先级低。
假如uvm_test_top和env中都对driver的pre_num的值进行了设置,在uvm_test_top中的设置语句如下:
function void my_case0::build_phase(uvm_phase phase);super.build_phase(phase);uvm_config_db#(int)::set(this,"env.i_agt.drv","pre_num",999);`uvm_info("my_case0", "in my_case0, env.i_agt.drv.pre_num is set to 999",UVM_LOW)
在env的设置语句如下:
virtual function void build_phase(uvm_phase phase);super.build_phase(phase);uvm_config_db#(int)::set(this,"i_agt.drv","pre_num",100);`uvm_info("my_env", "in my_env, env.i_agt.drv.pre_num is set to 100",UVM_LOW)
endfunction
那么driver中获取到的值是100还是999呢?答案是999。UVM规定层次越高,那么它的优先级越高。这里的层次指的是在UVM树中的位置,越靠近根结点uvm_top,则认为其层次越高。uvm_test_top的层次是高于env的,所以uvm_test_top中的set函数的优先级高。
上述结论在set函数的第一个参数为this时是成立的,但是假如set函数的第一个参数不是this会如何呢?假设uvm_test_top的set语句是:
function void my_case0::build_phase(uvm_phase phase);super.build_phase(phase);uvm_config_db#(int)::set(uvm_root::get(),"uvm_test_top.env.i_agt.drv","pre_num",999);`uvm_info("my_case0", "in my_case0, env.i_agt.drv.pre_num is set to 999", UVM_LOW)
而env的set语句是:
virtual function void build_phase(uvm_phase phase);super.build_phase(phase);uvm_config_db#(int)::set(uvm_root::get(),"uvm_test_top.env.i_agt.drv","pre_num",100);`uvm_info("my_env", "in my_env, env.i_agt.drv.pre_num is set to 100",UVM_LOW)
endfunction
这种情况下,driver得到的pre_num的值是100。由于set函数的第一个参数是uvm_root::get(),所以寄信人变成了uvm_top。在这种情况下,只能比较寄信的时间。UVM的build_phase是自上而下执行的,my_case0的build_phase先于my_env的build_phase执行。所以my_env对pre_num的设置在后,其设置成为最终的设置。
假如uvm_test_top中set函数的第一个参数是this,而env中set函数的第一个参数是uvm_root::get(),那么driver得到的pre_num的值也是100。这是因为env中set函数的寄信人变成了uvm_top,在UVM树中具有最高的优先级。
因此,无论如何,在调用set函数时其第一个参数应该尽量使用this。在无法得到this指针的情况下(如在top_tb中),使用null或者uvm_root::get()。
5.
关于同一层次的多重设置:
pre_num在99%的测试用例中的值都是7,只有在1%的测试用例中才会是其他值。
可以这么实现:
classs base_test extends uvm_test;function void build_phase(uvm_phase phase);super.build_phase(phase);uvm_config_db#(int)::set(this, "env.i_agt.drv", pre_num_max, 7);endfunction
endclass
class case1 extends base_test;function void build_phase(uvm_phase phase);super.build_phase(phase);endfunction
endclass
…
class case99 extends base_test;function void build_phase(uvm_phase phase);super.build_phase(phase);endfunction
endclass
但是对于第100个测试用例,则依然需要这么写:
class case100 extends base_test;function void build_phase(uvm_phase phase);super.build_phase(phase);uvm_config_db#(int)::set(this, "env.i_agt.drv", pre_num_max, 100);endfunction
endclass
case100的build_phase相当于如下所示连续设置了两次:
uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 7);
uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 100);
按照时间优先的原则,后面config_db::set的值将最终被driver得到。
6.
可以使用同配符设置config_db。
initial beginuvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env.i_agt*", "vif", input_if);
end
尽可能不要使用通配符*,尽量写清楚,避免给同事添麻烦。
7.
用于connect_phase的check_config_usage可以显示出截止到此函数调用时有哪些参数是被设置过但是却没有被获取过,这可以用来检查使用config_db时的第二个参数,即路径字符串出错的情况。
virtual function void connect_phase(uvm_phase phase);super.connect_phase(phase);check_config_usage();
endfunction使用例子:
function void my_case0::build_phase(uvm_phase phase);uvm_config_db#(uvm_object_wrapper)::set(this,"env.i_agt.sqr.main_phase","default_sequence",case0_sequence::type_id::get());uvm_config_db#(int)::set(this,"env.i_atg.drv","pre_num",999);uvm_config_db#(int)::set(this,"env.mdl","rm_value",10);
endfunction
仿真打印结果如下:
# UVM_INFO @ 0: uvm_test_top [CFGNRD] ::: The following resources have at least one write and no reads # default_sequence [/^uvm_test_top.env.i_agt.sqr.main_phase$/] : (class uvm_pkg::uvm_object_wrapper) # -
# --------
# uvm_test_top reads: 0 @ 0 writes: 1 @ 0
##
pre_num [/^uvm_test_top.env.i_atg.drv$/] : (int) 999
# -
# --------
# uvm_test_top reads: 0 @ 0 writes: 1 @ 0
#上述结果显示有两条设置信息分别被写过(set)1次,但是一次也没有被读取(get)。其中pre_num未被读取是因为错把i_agt写成了i_atg。default sequence的设置也没有被读取,是因为default sequence是设置main_phase的,它在main_phase的时候被获取,而main_phase是在connect_phase之后执行的。
8.
print_config函数用于config_db调试。其中参数1表示递归的查询,若为0,则只显示当前component的信息。它会遍历整个验证平台的所有结点,找出哪些被设置过的信息对于它们是可见的。打印的信息大致如下:
# UVM_INFO @ 0: uvm_test_top [CFGPRT] visible resources:
# <none>
# UVM_INFO @ 0: uvm_test_top.env [CFGPRT] visible resources:
# <none>
# UVM_INFO @ 0: uvm_test_top.env.agt_mdl_fifo [CFGPRT] visible resources:
# <none>
…
参考自张强《UVM实战》公众号:程序员Marshall







)




,要求输出两个礼仪的身高。)




;设p1指向字符串s)

