
文章目录
- 说明
- 🚩数组笔试题
- 💻一维数组
- 📄练习:
- 💡解析
- 💻字符数组
- 📄练习1:
- 💡解析
- 📄练习2:
- 💡解析
- 📄练习3:
- 💡解析
- 📄练习4:
- 💡解析
- 📄练习5:
- 💡解析
- 📄练习6:
- 💡解析
- 💻二维数组
- 📄练习:
- 💡解析
- 🗞️小结
- 🚩指针运算笔试题
- 📄练习1:
- 💡解析
- 📄练习2:
- 💡解析
- 📄练习3:
- 💡解析
- 📄练习4:
- 💡解析
- 📄练习5:
- 💡解析
- 📄练习6:
- 💡解析
- 📄练习7:
- 💡解析
- 📄练习8:
- 💡解析
- 🚩总结
说明
X64环境下,8个字节
X86环境下,4个字节
小编在运行代码,数据是在VS 2019 X86环境下打印的。
🚩数组笔试题
💻一维数组
📄练习:
code:
#include<stdio.h>int main()
{int a[] = { 1,2,3,4 };printf("%zd\n", sizeof(a));printf("%zd\n", sizeof(a + 0));printf("%zd\n", sizeof(*a));printf("%zd\n", sizeof(a + 1));printf("%zd\n", sizeof(a[1]));printf("%zd\n", sizeof(&a));printf("%zd\n", sizeof(*&a));printf("%zd\n", sizeof(&a + 1));printf("%zd\n", sizeof(&a[0]));printf("%zd\n", sizeof(&a[0] + 1));return 0;
}
运行结果:
16
4
4
4
4
4
16
4
4
4
💡解析
printf("%zd\n", sizeof(a)); //16
➿➿数组名的理解:
数组名是数组首元素的地址
但是有2个例外:
- sizeof(数组名),数组名表示整个数组,计算的是整个数组的大小,单位是字节
- &数组名,数组名表示整个数组,取出的是数组的地址
⭕所以在此代码中,有四个整型,一个整型占4个字节,故总共占16个字节。
printf("%zd\n", sizeof(a + 0)); //4
数组名a没有单独放在sizeof()中,也没有进行单独取地址&,因此,(a+0)不是数组名,这里的a是数组首元素地址,加上0,相当于没有加
a+0<======>&a[ 0 ]
⭕故,是地址大小,4或者8个字节(X64环境下和X86环境下不一样)
printf("%zd\n", sizeof(*a)); //4
这里没有将单独的一个a放进sizeof()中,也没有取地址&,那么a就是除那两种情况之外,即a就是数组首元素地址,a==>&a[ 0 ]
⭕故,*a 其实就是第一个元素,也就是a[ 0 ] 的大小:4个字节
printf("%zd\n", sizeof(a + 1)); //4
和上面(a+0)一样,a是首元素地址
(a+0)–>&a[ 0 ]
(a+1)–>&a[ 1 ]
⭕故,(a+1)就是第2个元素的地址,大小是4或者8个字节
printf("%zd\n", sizeof(a[1])); //4
a[1]就是这个数组的第二个元素
⭕故,大小是4个字节
printf("%zd\n", sizeof(&a));
&a➡️取出的是数组的地址,但是数组的地址也是一个地址呀😏,数组的地址可没有高人一等。是地址大小就是4或者8个字节
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(*&a)); //16
两种解读方式:
1️⃣抵消:
·这里取地址,然后再解引用,抵消掉了,相当于就是a
2️⃣数组指针类型:
· &a类型是一个数组指针,&a<==>int(*p)[ 4 ]
· 我们知道,指针在进行加一或者解引用的时候,跳过多少个字节是取决于指针类型:
*p访问一个数组的大小
p+1是跳过一个数组的大小
·
那么现在p指向一个大小为4,类型为整型的一个数组
取出整个数组的地址,再进行解引用,访问的就是整个数组
因此:
printf("%zd\n", sizeof(*&a));
<==>
printf("%zd\n", sizeof(a));
⭕故,大小是16个字节
printf("%zd\n", sizeof(&a + 1)); //4
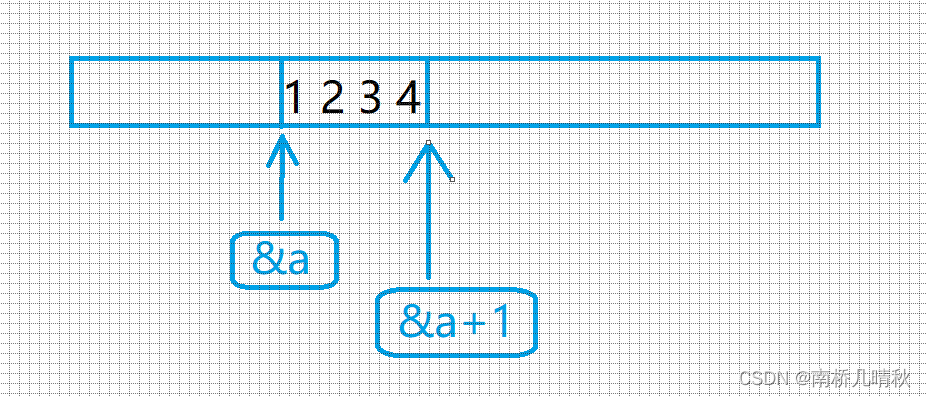
&a+1是跳过整个数组后的地址,是地址大小就是4或者8个字节。
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(&a[0])); //4
没什么好说的,就是首元素地址🤨,是地址大小就是4或者8个字节。
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(&a[0] + 1)); //4
&a[0] + 1表示第二个元素的地址(&a[ 1 ])
⭕故,大小是4或者8个字节
💻字符数组
📄练习1:
code:
#include<stdio.h>
int main()
{char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(arr));printf("%d\n", sizeof(arr + 0));printf("%d\n", sizeof(*arr));printf("%d\n", sizeof(arr[1]));printf("%d\n", sizeof(&arr));printf("%d\n", sizeof(&arr + 1));printf("%d\n", sizeof(&arr[0] + 1));return 0;
}
运行结果:
6
4
1
1
4
4
4
💡解析
printf("%d\n", sizeof(arr)); //6
arr表示整个数组,计算的是整个数组的大小
此数组有6个字符,一个字符1个字节
⭕故,一共有6个字节
printf("%d\n", sizeof(arr + 0)); //4
arr是数组首元素的地址,arr+0还是首元素的地址
⭕故,是地址,大小就是4或者8个字节
printf("%d\n", sizeof(*arr)); //1
arr就是首元素地址,*arr解引用,就是首元素,就站一个字符,即1个字节
⭕故,大小就是1个字节
printf("%d\n", sizeof(arr[1])); //1
arr[ 1 ]表示数组第2个元素,即占一个字节
⭕故,大小就是1个字节
printf("%d\n", sizeof(&arr)); //4
&arr是数组的地址,数组的地址也是地址
⭕故,是地址,大小就是4或者8个字节
printf("%d\n", sizeof(&arr + 1));
&arr+1跳过整个数组,指向的是f后面,
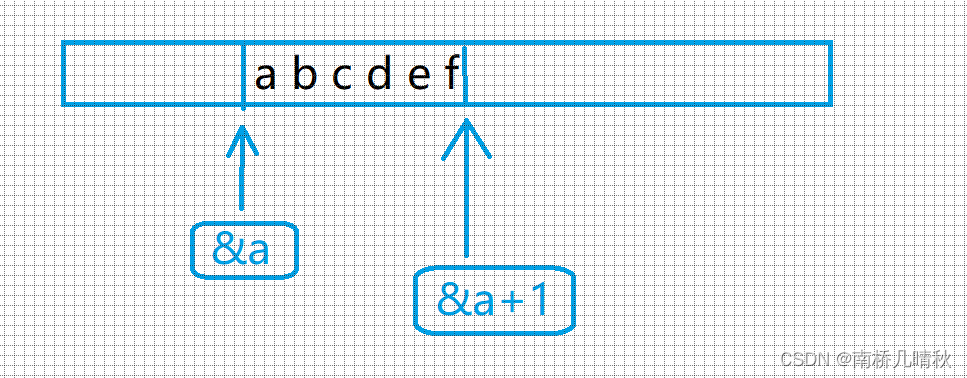
⭕故,是地址,大小就是4或者8个字节
printf("%d\n", sizeof(&arr[0] + 1)); //4
&arr[0]是首元素地址,+1后变成第二个元素地址
⭕故,是地址,大小就是4或者8个字节
📄练习2:
code:
#include<stdio.h>
#include<string.h>
int main()
{char arr[] = { 'a','b','c','d','e','f' };printf("%zd\n", strlen(arr));printf("%zd\n", strlen(arr + 0));printf("%zd\n", strlen(*arr));printf("%zd\n", strlen(arr[1]));printf("%zd\n", strlen(&arr));printf("%zd\n", strlen(&arr + 1));printf("%zd\n", strlen(&arr[0] + 1));return 0;
}
💡解析
printf("%zd\n", strlen(arr)); //随机值
数组中没有明确给出\0
⭕故,计算出的结果是随机值
printf("%zd\n", strlen(arr + 0)); //随机值
arr+0:首元素地址+0,和没加一样,依然表示arr,数组中也是没有明确给出\0
⭕故,计算出的结果是随机值
printf("%zd\n", strlen(*arr)); //非法访问-err
strlen()函数参数是指针类型
size_t strlen ( const char * str );
而*arr得到是首元素‘a’
这样就意味着将’a’(97)传递给strlen,将97当作地址传递给strlen
⭕故,形成非法访问
printf("%zd\n", strlen(arr[1])); //非法访问-err
arr[1]表示数组第二个元素,‘b’(98)
将98当作地址传递给strlen,依然是非法访问,和上面一样
⭕故,形成非法访问
printf("%zd\n", strlen(&arr)); //随机值
&arr是一个字符数组指针类型–>char (*p)[ 6 ]
对于strlen依然是找到首元素地址,往后读取,但是没有\0
⭕故,计算出的结果是随机值
printf("%zd\n", strlen(&arr + 1)); //随机值
加一后,跳过整个数组
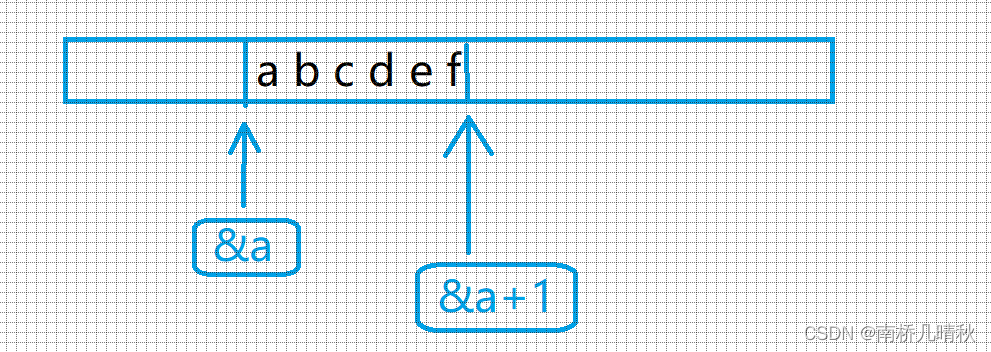
跳过一个数组后再去往后找,不知道找什么
和上面的随机值是不一样的
差6个字节
⭕故,计算出的结果是随机值
printf("%zd\n", strlen(&arr[0] + 1)); //随机值
&arr[0] + 1表示数组第二个元素,即’b’,从‘b’开始往后数,没有明确给出\0
⭕故,计算出的结果是随机值
📄练习3:
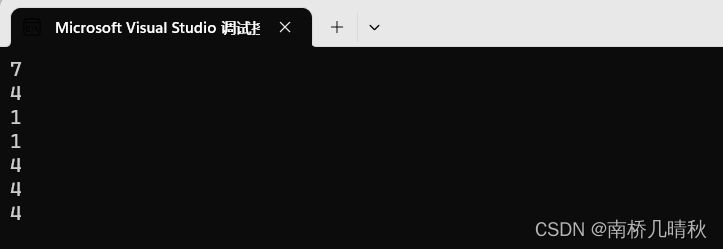
code:
#include<stdio.h>
int main()
{char arr[] = "abcdef";//[ a b c d e f \0 ]printf("%zd\n", sizeof(arr));printf("%zd\n", sizeof(arr + 0));printf("%zd\n", sizeof(*arr));printf("%zd\n", sizeof(arr[1]));printf("%zd\n", sizeof(&arr));printf("%zd\n", sizeof(&arr + 1)); printf("%zd\n", sizeof(&arr[0] + 1));return 0;
}
运行结果:
7
4
1
1
4
4
4
💡解析
printf("%zd\n", sizeof(arr)); //7
不管有没有\0,只管占了多少字节
有7个元素
⭕故,占7个字节
printf("%zd\n", sizeof(arr + 0)); //4
arr表示首元素地址,即arr+0也表示数组首元素地址,是地址,大小就是4或者8个字节
⭕故,占4或者8个字节
printf("%zd\n", sizeof(*arr)); //1
arr表示首元素地址,*arr就是首元素,大小就是1个字节
⭕故,占1个字节
printf("%zd\n", sizeof(arr[1])); //1
arr[1]表示数组第二个元素,大小1个字节
⭕故,占1个字节
printf("%zd\n", sizeof(&arr)); //4
&arr是数组的地址,是地址,大小就是4或者8个字节
⭕故,占4或者8个字节
printf("%zd\n", sizeof(&arr + 1));
&arr是数组地址
&arr+1是跳过整个数组的那个地址
是地址,大小就是4或者8个字节
⭕故,占4或者8个字节
printf("%zd\n", sizeof(&arr[0] + 1)); //4
&arr[0] + 1表示第二个元素地址
是地址,大小就是4或者8个字节
⭕故,占4或者8个字节
📄练习4:
code:
#include<stdio.h>
#include <string.h>int main()
{char arr[] = "abcdef";printf("%zd\n", strlen(arr));printf("%zd\n", strlen(arr + 0));//printf("%lld\n", strlen(*arr)); //printf("%lld\n", strlen(arr[1])); printf("%zd\n", strlen(&arr)); printf("%zd\n", strlen(&arr + 1));printf("%zd\n", strlen(&arr[0] + 1));return 0;
}
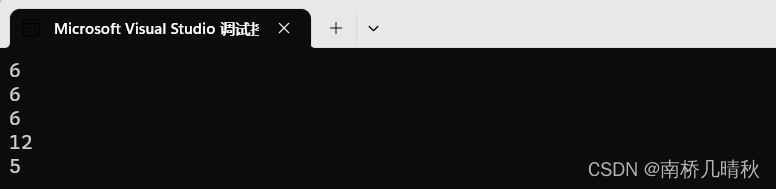
运行结果:
6
6
6
12
5
💡解析
printf("%zd\n", strlen(arr)); //6
arr是数组首元素地址,顺着往后读取,读到\0结束
strlen统计的是\0之前的字符串个数
⭕故,计算结果是6
printf("%zd\n", strlen(arr + 0)); //6
arr是数组名,首元素地址
arr+0 还是首元素地址,顺着往后读取,读到\0结束
⭕故,计算结果是6
//printf("%lld\n", strlen(*arr)); //err - 非法访问
*arr表示’a’(97)
将97当作地址传递给strlen
非法访问
⭕故,非法访问
//printf("%lld\n", strlen(arr[1])); //err - 非法访问
arr[1]表示数组第二个元素,即‘b’(98)
将987当作地址传递给strlen
非法访问
⭕故,非法访问
printf("%zd\n", strlen(&arr)); //6
&arr取的是整个数组的地址
但这个地址依然指的是数组的起始位置
传递给strlen后,依然从起始位置往后读取,直到\0停止
⭕故,计算结果是6
printf("%zd\n", strlen(&arr + 1)); //随机值
&arr取的是整个数组的地址
&arr+1跳过整个数组后的地址
从跳过后的地址开始找\0,就是随机值
⭕故,随机值
printf("%zd\n", strlen(&arr[0] + 1)); //5
&arr[0] 表示第一个元素地址
&arr[0] + 1第二个元素地址,即b的地址
从b的地址开始找\0,找到\0后停止
⭕故,计算结果是5
📄练习5:
code:
#include<stdio.h>
int main()
{char* p = "abcdef";printf("%zd\n", sizeof(p));printf("%zd\n", sizeof(p + 1));printf("%zd\n", sizeof(*p));printf("%zd\n", sizeof(p[0]));printf("%zd\n", sizeof(&p));printf("%zd\n", sizeof(&p + 1));printf("%zd\n", sizeof(&p[0] + 1));return 0;
}
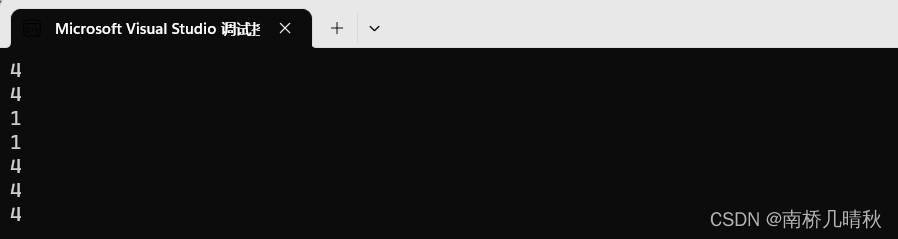
运行结果:
4
4
1
1
4
4
4
💡解析
思路:这里是常量字符串,将常量字符串首字符放在p中。
图示:
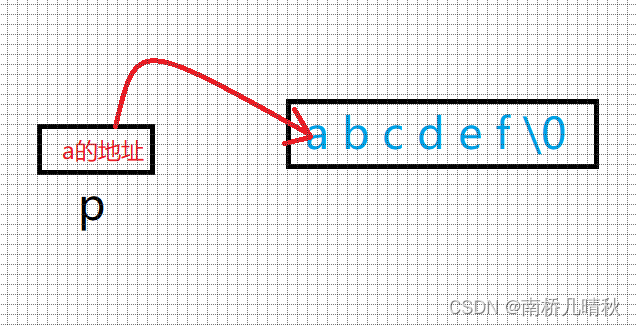
printf("%zd\n", sizeof(p));
p是一个指针变量
sizeof(p)求的就是指针变量的大小
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(p + 1)); //4
p放的是‘a’的地址
p+1则放的是’b’的地址
依然是地址
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(*p)); //1
p指向’a’
*p解引用,是首字符
⭕故,大小是1个字节
printf("%zd\n", sizeof(p[0])); //1
两种解读方式:
1️⃣类似数组:
这里,可以把字符串“abcdef”也当作有个数组
p是数组名
那么,p[0]访问的就是‘a’
2️⃣计算:
p[0]===>*(p+0)
⭕故,大小是1个字节
printf("%zd\n", sizeof(&p)); //4
&p是取出p所占的地址
也是个地址
是地址,大小就是4或者8个字节
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(&p + 1));
&p + 1也是地址
跳过p变量的地址,指向的是p后面的地址
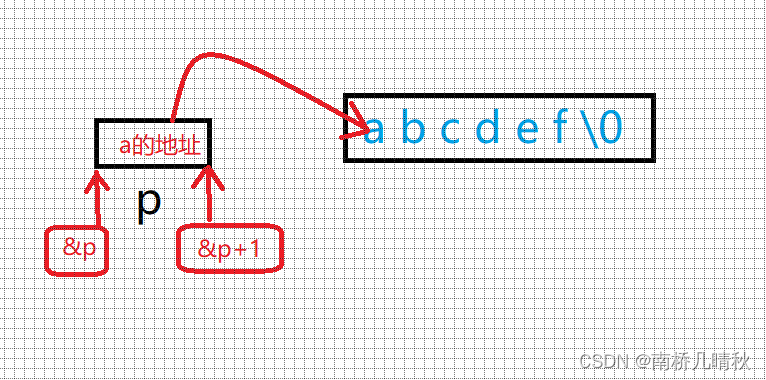
是地址,大小就是4或者8个字节
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(&p[0] + 1));
&p[0]是’a’的地址
&p[0] + 1是“b’的地址
是地址,大小就是4或者8个字节
⭕故,大小是4或者8个字节
📄练习6:
code:
#include<stdio.h>
#include<string.h>int main()
{char* p = "abcdef";printf("%zd\n", strlen(p));printf("%zd\n", strlen(p + 1));//printf("%zd\n", strlen(*p));//printf("%zd\n", strlen(p[0]));printf("%zd\n", strlen(&p));printf("%zd\n", strlen(&p + 1));printf("%zd\n", strlen(&p[0] + 1));return 0;
}
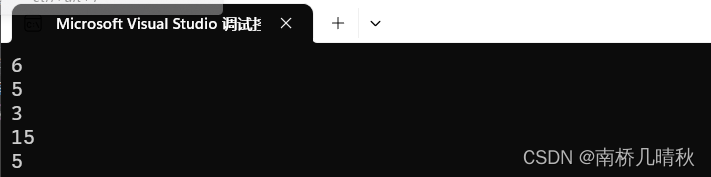
运行结果:
6
5
3
11
5
💡解析
printf("%zdd\n", strlen(p)); //6
字符串中有\0
p中存放的是a的地址
从a的地址开始向后访问
⭕故,长度是6
printf("%zd\n", strlen(p + 1)); //5
p指向a
p+1指向b
从b开始往后数,直到遇到\0为止
⭕故,长度是5
//printf("%zd\n", strlen(*p));//err
p指向a
*p就是a
将p的值传递给strlen
⭕故,非法访问
//printf("%zd\n", strlen(p[0]));//err
p[0]=>*(p+0)=>*p
⭕故,非法访问
printf("%zd\n", strlen(&p)); //随机值
&p是p的地址
从p所占空间的起始位置开始查找的
完全不可知的
⭕故,随机值
printf("%zd\n", strlen(&p + 1));//随机值
&p+1指向的是p的地址后面
从&p后面的地址开始读取
也是不可知的
⭕故,随机值
printf("%zd\n", strlen(&p[0] + 1)); //5
&p[0] + 1是‘b’的地址
从’b’后面开始数
⭕故,长度是5
💻二维数组
📄练习:
code:
#include<stdio.h>int main()
{int a[3][4] = { 0 };printf("%zd\n", sizeof(a));printf("%zd\n", sizeof(a[0][0]));printf("%zd\n", sizeof(a[0]));printf("%zd\n", sizeof(a[0] + 1));printf("%zd\n", sizeof(*(a[0] + 1)));printf("%zd\n", sizeof(a + 1));printf("%zd\n", sizeof(*(a + 1)));printf("%zd\n", sizeof(&a[0] + 1));printf("%zd\n", sizeof(*(&a[0] + 1)));printf("%zd\n", sizeof(*a));printf("%zd\n", sizeof(a[3]));return 0;
}
运行结果:
48
4
16
4
4
4
16
4
16
16
16
💡解析
printf("%zd\n", sizeof(a)); //48
计算的是整个二维数组的大小,单位是字节
数组里共有3*4=12个元素
每个元素都是int类型
则344
⭕故,大小是48个字节
printf("%zd\n", sizeof(a[0][0])); //4
a[0][0]表示第一行第一个元素
⭕故,大小是4个字节
printf("%zd\n", sizeof(a[0])); //16
a[0]表示第一行数组名
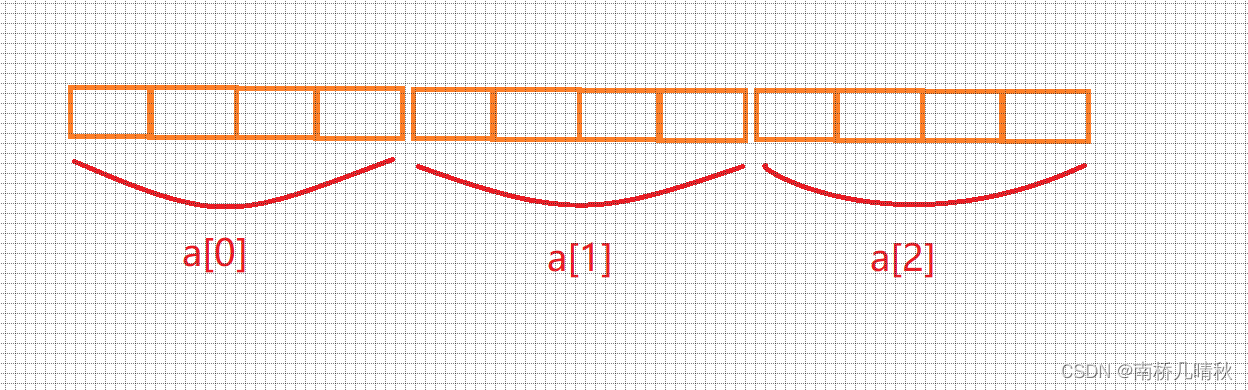
将第一行数组名单独放在sizeof内部
计算的是第一行大小
⭕故,大小是16个字节
printf("%zd\n", sizeof(a[0] + 1)); //4
a[0]是第一行数组名,但是没有把a[0]单独放在sizeof中
这里的a[0]表示第一行第一个元素的地址
a[0] + 1表示第一行第一个元素地址+1,即第一行第二个元素地址==>a[0][1]的地址
是地址,大小是4或者8个字节
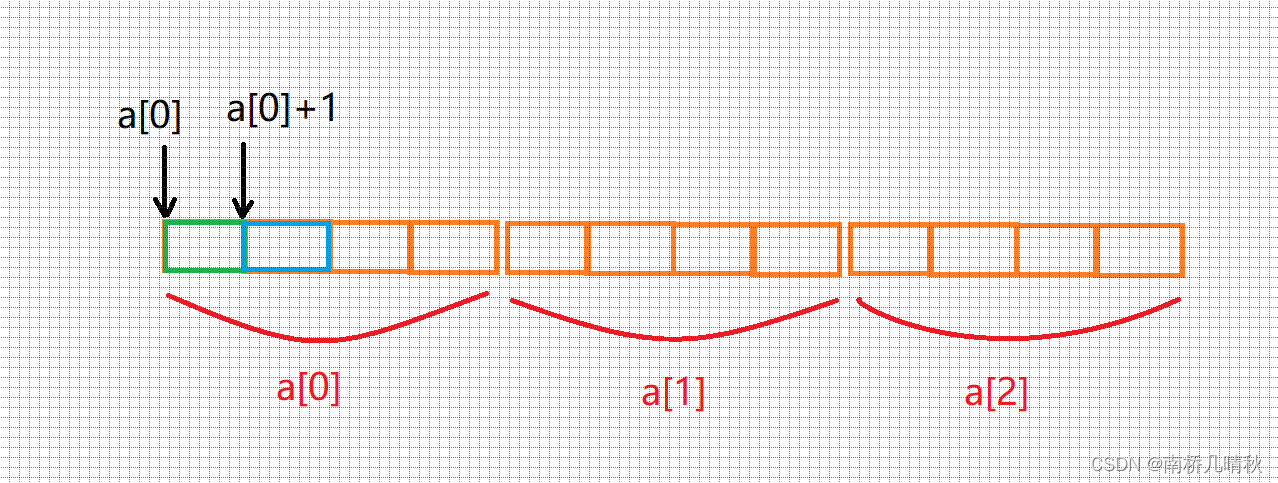
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(*(a[0] + 1))); //4
a[0] + 1是第一行第二个元素的地址
*(a[0] + 1)解引用,访问的就是第一行第二个元素
⭕故,大小是4个字节
printf("%zd\n", sizeof(a + 1)); //4
这里的a是二维数组的数组名
没有将a单独放在sizeof中
那么,a就是数组首元素地址,也就是第一行的地址😏
a+1跳过一行的地址,就是第二行地址
既然是地址,那么…
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(*(a + 1))); //16
a+1是第二行地址
*(a + 1)解引用,表示第二行
*(a + 1)==>a[1]
printf("%zd\n", sizeof(*(a + 1)));
<==>
printf("%zd\n", sizeof(a[1]);
两种表示方法,你get到了嘛??😏
⭕故,大小是16个字节
printf("%zd\n", sizeof(&a[0] + 1)); //4
a[0]是第一行数组名
&a[0]取出第一行的地址
&a[0] + 1第一行的地址+1,表示第二行地址
是地址…
⭕故,大小是4或者8个字节
printf("%zd\n", sizeof(*(&a[0] + 1))); //16
&a[0] + 1是第二行的地址
*(&a[0] + 1))对第二行地址解引用,访问第二行数组
⭕故,大小是16个字节
printf("%zd\n", sizeof(*a)); //16
a表示首元素地址,也就是第一行地址
*a对一行地址解引用,就是第一行
⭕故,大小是16个字节
printf("%zd\n", sizeof(a[3])); //16
a[3]是第四行,但是刚开始我们开的数组没有第四行
我们知道,sizeof()是根据类型计算的
实际上不会访问a[3]
a[3]和前面a[0]类型是一样的
⭕故,大小是16个字节
🗞️小结
- sizeof(数组名),这⾥的数组名表⽰整个数组,计算的是整个数组的⼤⼩。
- &数组名,这⾥的数组名表⽰整个数组,取出的是整个数组的地址。
- 除此之外所有的数组名都表⽰⾸元素的地址。
关于sizeof和strlen的介绍,可以看小编的文章《sizeof和strlen的对比》,里面有详细解释!!!
🚩指针运算笔试题
📄练习1:
code:
#include <stdio.h>
int main()
{int a[5] = { 1, 2, 3, 4, 5 };int* ptr = (int*)(&a + 1);printf("%d,%d", *(a + 1), *(ptr - 1));return 0;
}
运行结果:
2,5
💡解析
1️⃣对*(a + 1)的分析:
-
a表示数组首元素地址
-
a+1首元素地址+1,表示第二个元素地址
-
*(a + 1)解引用,表示第二个元素,即2
2️⃣对*(ptr - 1)的分析:
-
首先分析int* ptr = (int*)(&a + 1);
-
&a表示整个数组地址
-
&a+1表示跳过整个数组地址
-
&a的类型是int(*)[5] ,+1后的类型还是这个类型
-
现在要将(&a + 1)赋值给ptr
-
ptr是int* 类型,所以需要强制类型转换
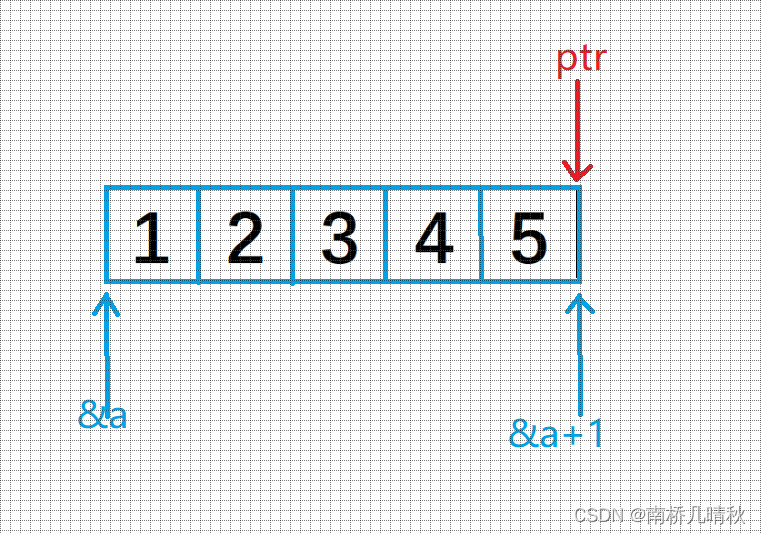
-
分析*(ptr - 1)
-
ptr-1表示前移动,即5的地址:
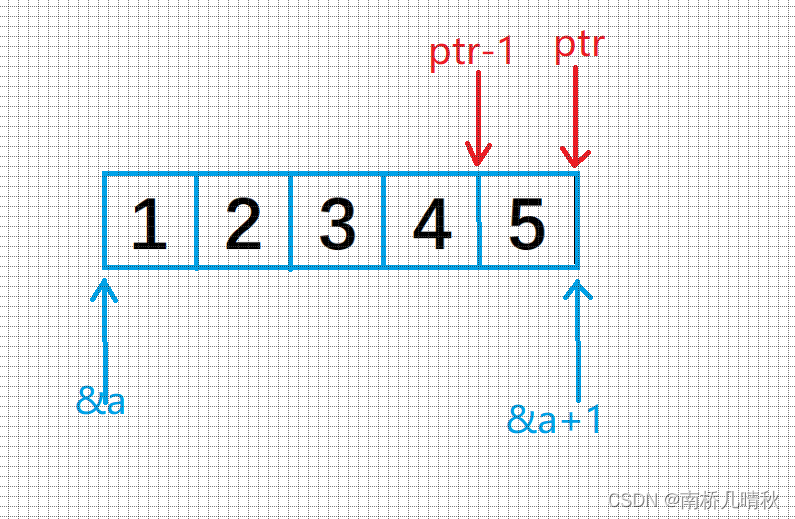
- *(ptr-1)解引用,表示5
📄练习2:
在X86环境下
假设结构体的⼤⼩是20个字节
code:
#include <stdio.h>struct Test
{int Num;char* pcName;short sDate;char cha[2];short sBa[4];
}*p = (struct Test*)0x100000;
int main()
{printf("%p\n", p + 0x1);printf("%p\n", (unsigned long)p + 0x1);printf("%p\n", (unsigned int*)p + 0x1);return 0;
}
运行结果:
00100014
00100001
00100004
💡解析
printf("%p\n", p + 0x1); //00100014
0x1表示1(在16进制中)
p+0x1即p+1
那么,指针+1到底加几呢??😥
这个取决于指针类型,现在是一个结构体指针
那么加1就是跳过一个结构体大小
结构体大小是20个字节,加的是0x100014
⭕所以,大小变成00100014(16进制中)
printf("%p\n", (unsigned long)p + 0x1); //00100001
p的类型被强制转换成unsigned long,无符号整型
此时就不是指针类型啦
那么就是:整型+1
不再是整型指针+1,小小的细节,要清楚
0x100000+1=0x100001
⭕所以,输出结果:00100001
printf("%p\n", (unsigned int*)p + 0x1); //00100004
p被强制转换成整型指针(unsigned int)
整型指针+1就是+4,即0x100004
⭕所以,输出结果:00100004
📄练习3:
cod:
#include <stdio.h>
int main()
{int a[4] = { 1, 2, 3, 4 };int* ptr1 = (int*)(&a + 1);int* ptr2 = (int*)((int)a + 1);printf("%x,%x", ptr1[-1], *ptr2);return 0;
}
运行结果:
4,2000000
💡解析
-
&a:取数组 a 的地址
-
&a + 1:将指向数组的指针做加法运算,相当于移动了一个整个数组的大小。由于 a 是一个包含4个元素的 int 数组,所以加上1后指向数组之外的内存。
-
(int*)(&a + 1):将指向数组之外的内存地址转换为 int 指针。
ptr1[-1]:通过指针 ptr1 往前访问前一个位置的值,即指向数组的最后一个元素。 -
(int)a:将数组 a 转换为 int 类型的值,实际上是取数组首元素的地址。
-
(int*)((int)a + 1):将数组首元素地址加上1后再转换为 int 指针。
-
*ptr2:通过指针 ptr2 访问指向的值。
-
根据上述分析,我们可以预测输出结果。
-
由于 a 是一个包含4个 int 类型元素的数组,在内存中占用4个 int 大小的连续空间。
-
ptr1[-1]:指向数组最后一个元素,即 a[3] 的值为4。
-
*ptr2:指向数组首元素后面的1字节内存,此内存内容未定义。
-
因此,我们可以预测输出结果为 4,未定义的值(可能是未初始化的值或者随机值)。
这道题在随着后面的学习,会有更深刻的理解,可以在学习完《数组在内存中的储存》后,再来看这道题
📄练习4:
code:
#include <stdio.h>
int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };int* p;p = a[0];printf("%d", p[0]);return 0;
}
运行结果:
1
💡解析
这里的数组初始化可不是下面这样:
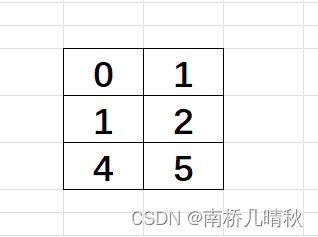
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
里面是逗号表达式
逗号表达式:从左向右依次计算,但是整个表达式的结果是最后一个表达式的结果
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
<===>
int a[3][2] = { 1, 3, 5 };
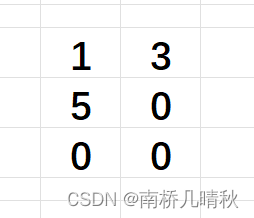
a[0]表示第一行数组名,是第一行首元素的地址,即a[0]==>&a[0][0]
p[0]==>*(p+0),即1
⭕所以,输出结果:1
📄练习5:
X86环境:
code:
#include <stdio.h>
int main()
{int a[5][5];int(*p)[4];p = a;printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);return 0;
}
运行结果:
FFFFFFFC,-4
💡解析
int a[5][5];
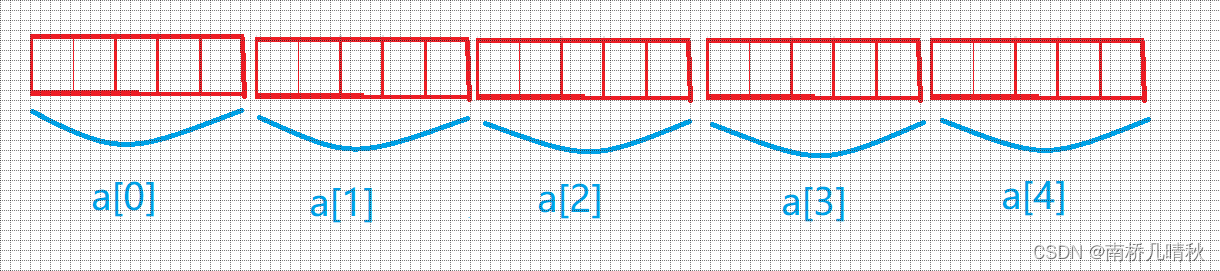
int(*p)[4];p = a;
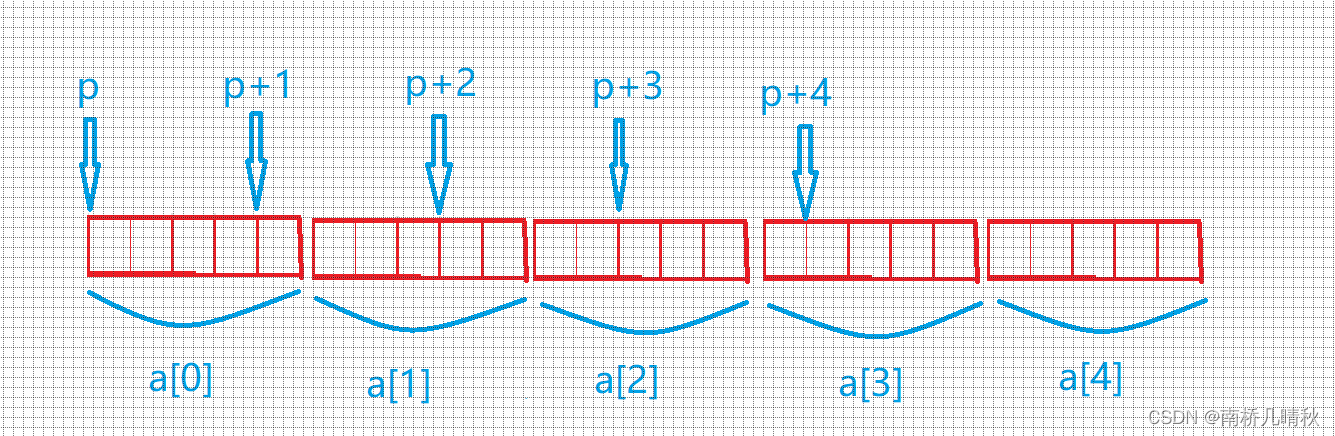
&p[4][2]
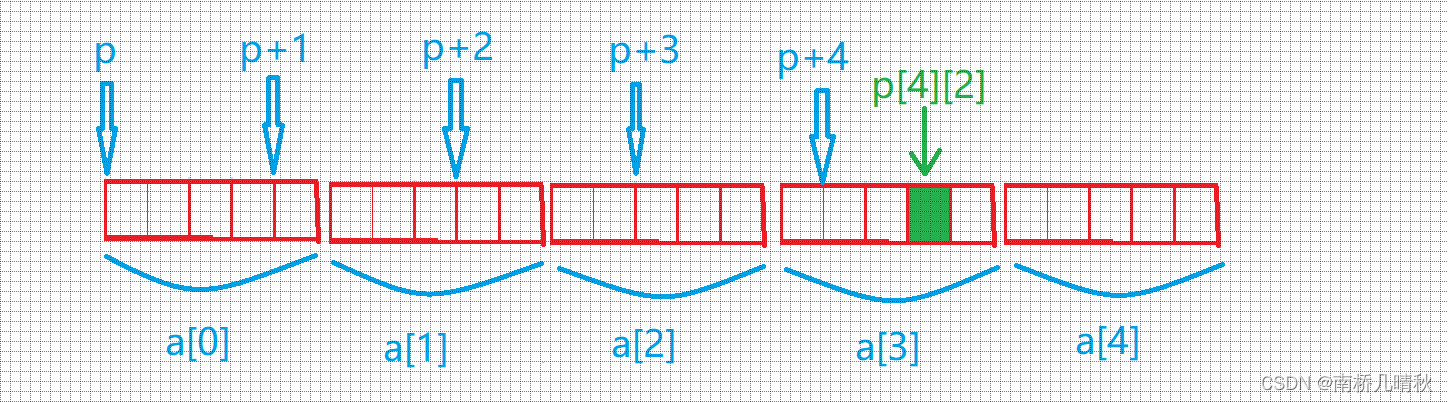
&p[4][2] - &a[4][2]
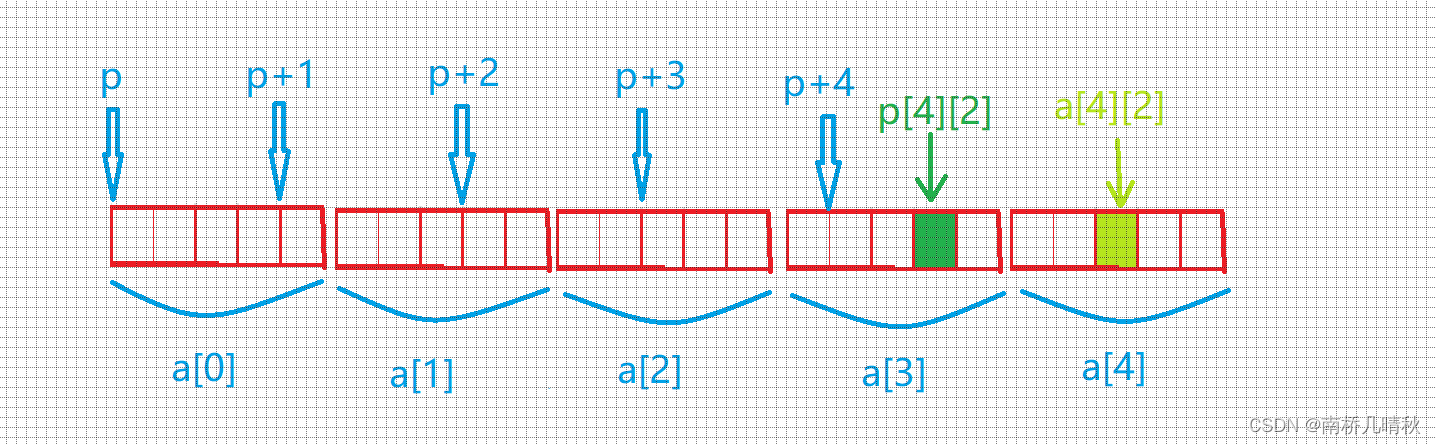
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
以%p打印和以%d打印是不一样的
%d打印就直接是-4
%p打印的是-4的补码,即FFFFFFFC
📄练习6:
code:
#include <stdio.h>
int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int* ptr1 = (int*)(&aa + 1);int* ptr2 = (int*)(*(aa + 1));printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));return 0;
}
运行结果:
10,5
💡解析
int* ptr1 = (int*)(&aa + 1);

将&aa + 1强制转换成int* 型,因为ptr1是int*型
然后赋值给ptr1
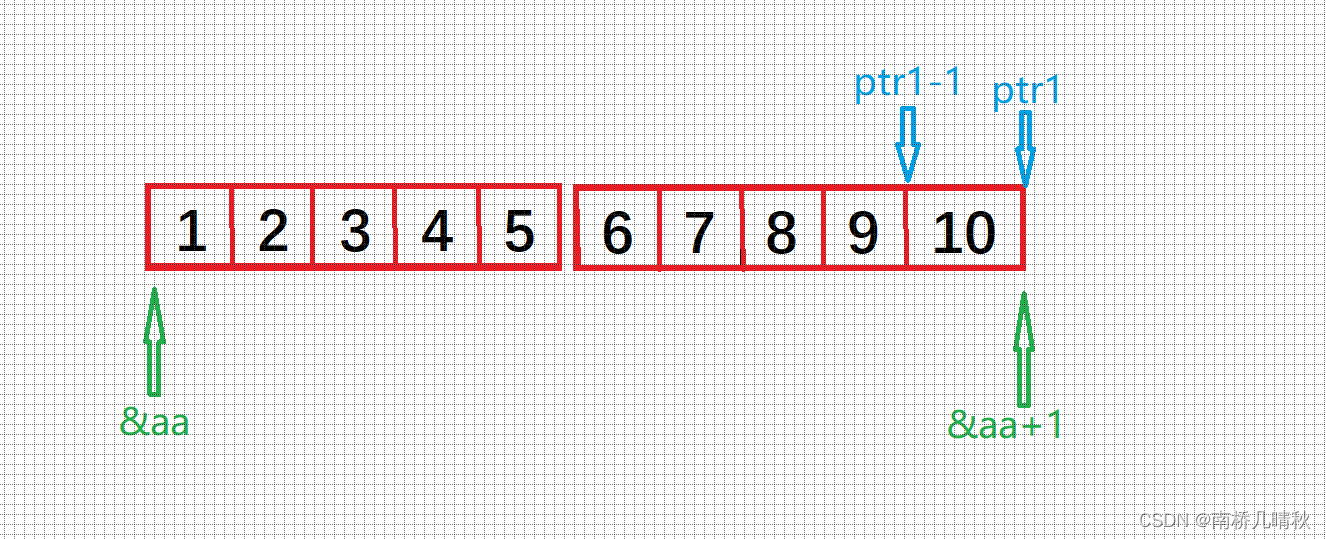
*(ptr1 - 1)是10
int* ptr2 = (int*)(*(aa + 1));
*(aa + 1)<==>aa[1]
aa[1]本来就是一个地址,这里的强制类型转换其实是没有意义的,完全就是迷惑人的
将aa[1]赋值给ptr2
那么*(ptr2 - 1)就是5
📄练习7:
code:
#include <stdio.h>
int main()
{char* a[] = { "work","at","alibaba" };char** pa = a;pa++;printf("%s\n", *pa);return 0;
}
运行结果:
at
💡解析
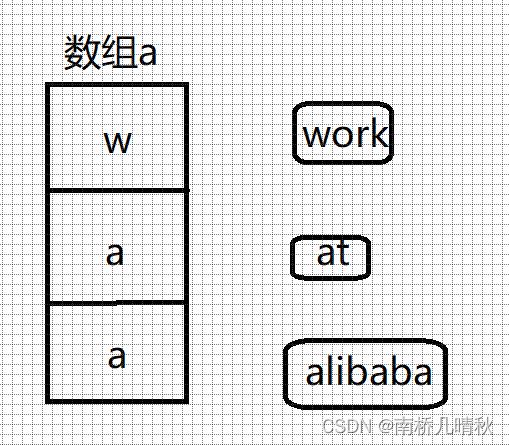
这里是将‘w’,’a’,‘a’的地址存到数组里面去
内存布局:
char** pa = a;
pa++;
a是数组首元素地址,即char*的地址
pa存放首元素地址
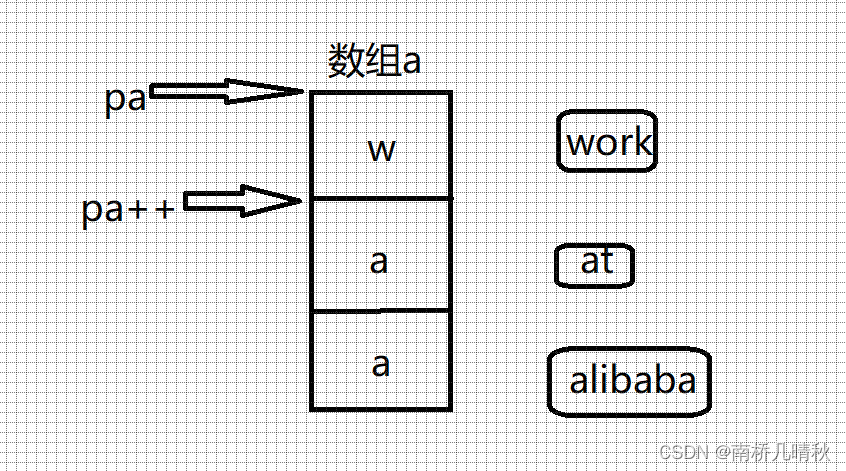
printf("%s\n", *pa);
对pa解引用,访问的就是第二个元素,即打印at
📄练习8:
code:
#include <stdio.h>
int main()
{char* c[] = { "ENTER","NEW","POINT","FIRST" };char** cp[] = { c + 3,c + 2,c + 1,c };char*** cpp = cp;printf("%s\n", **++cpp);printf("%s\n", *-- * ++cpp + 3);printf("%s\n", *cpp[-2] + 3);printf("%s\n", cpp[-1][-1] + 1);return 0;
}
运行结果:
POINT
ER
ST
EW
💡解析
本道题是比较难的一道题目!!!笔试原题
char* c[] = { "ENTER","NEW","POINT","FIRST" };
内存布局:
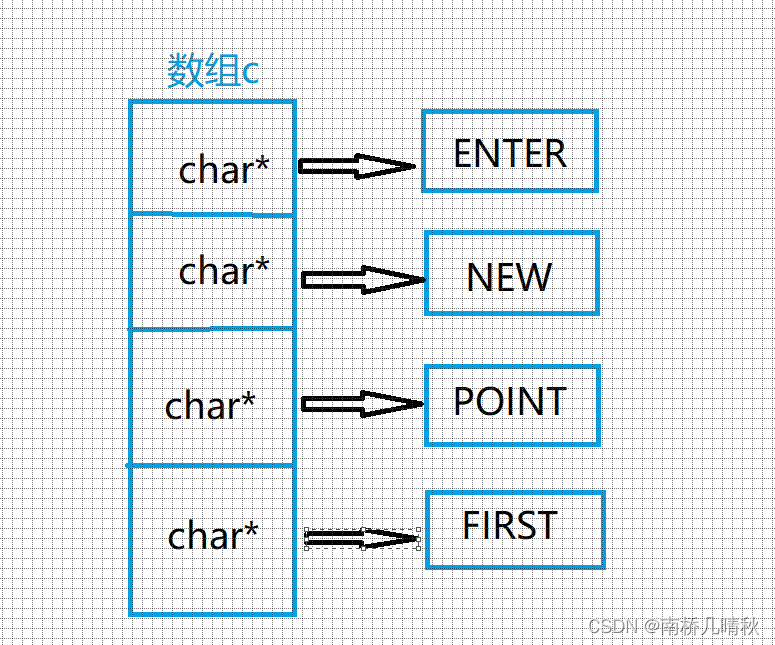
char** cp[] = { c + 3,c + 2,c + 1,c };
内存布局:
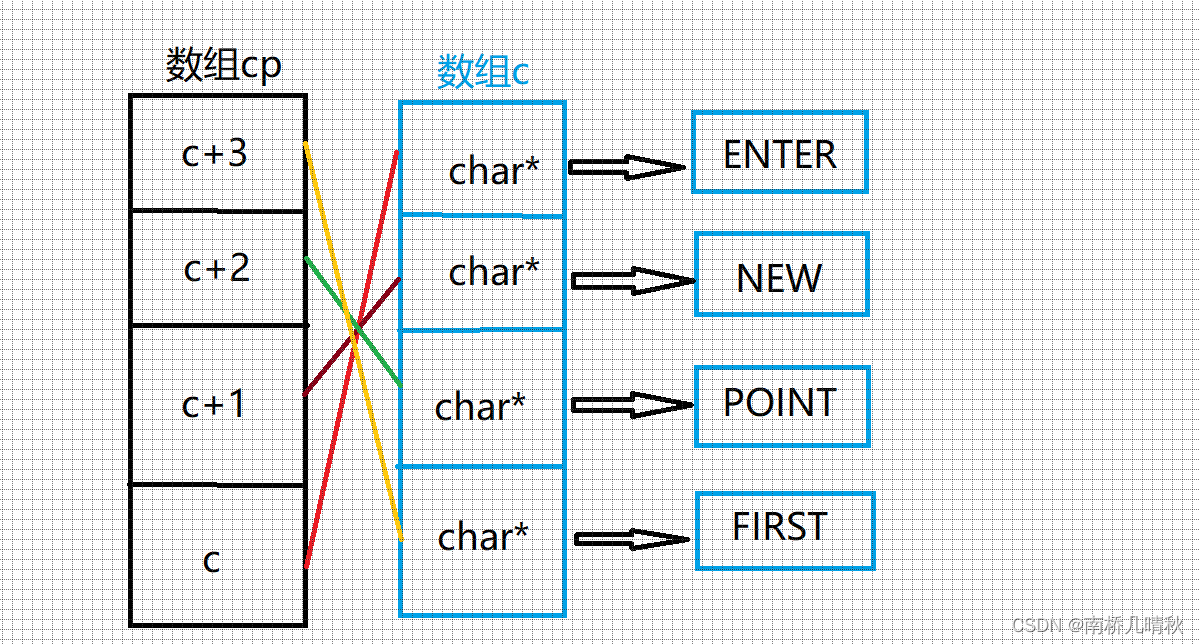
char*** cpp = cp;
图解:
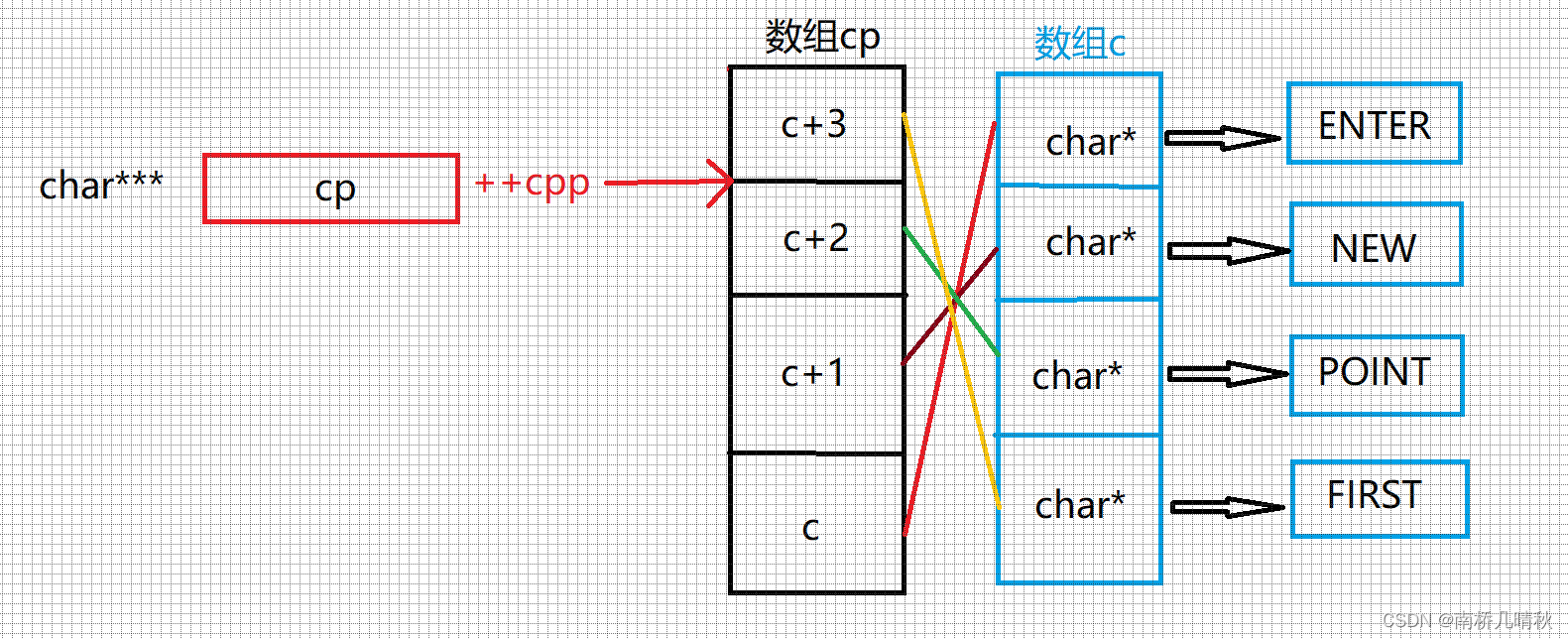
printf("%s\n", **++cpp);
++cpp=cpp+1
在这里插入图片描述
*++cpp第一层解引用,访问到的是c+2
通过c+2,得到的是P的地址
则再次解引用,以%s打印,得到POINT
printf("%s\n", *-- * ++cpp + 3);
再次++cpp
从上面基础上再+1
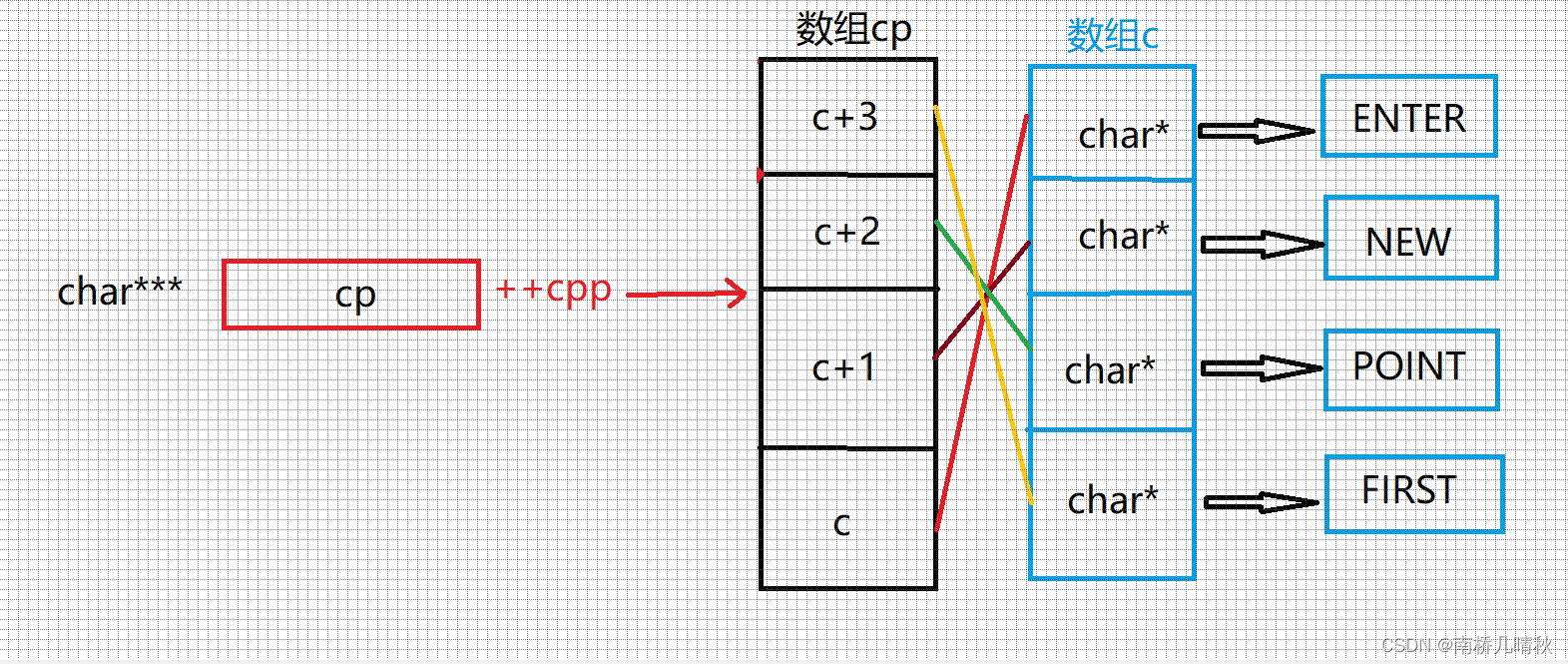
*++cpp解引用,得到c+1
– * ++cpp:在c+1上减去1,得到c
此时也就不再指向N,而是指向E
*-- * ++cpp:再解引用,得到E的地址
*-- * ++cpp + 3:得到ER
printf("%s\n", *cpp[-2] + 3);
cpp[-2]其实就是*(cpp-2)
*cpp[-2]+3也就是 * *(cpp-2)+3
cpp-2在上面的额基础上减2,cpp不会变
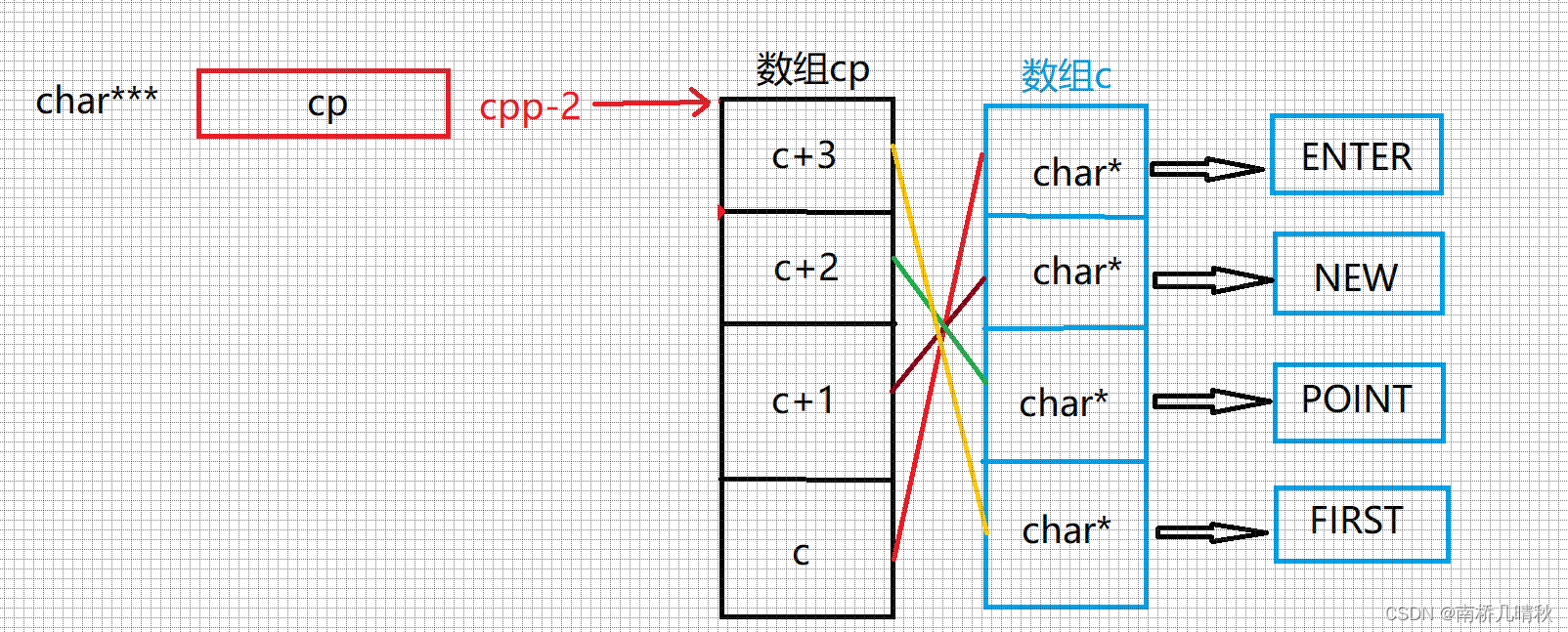
*(cpp-2)通过解引用,得到c+3
**(cpp-2) 再次解引用,得到F
**(cpp-2)+3 ,得到ST
printf("%s\n", cpp[-1][-1] + 1);
cpp[-1][-1]也就是 * (*(cpp-1)-1)
即, * (*(cpp-1)-1)+1
cpp-1图解:
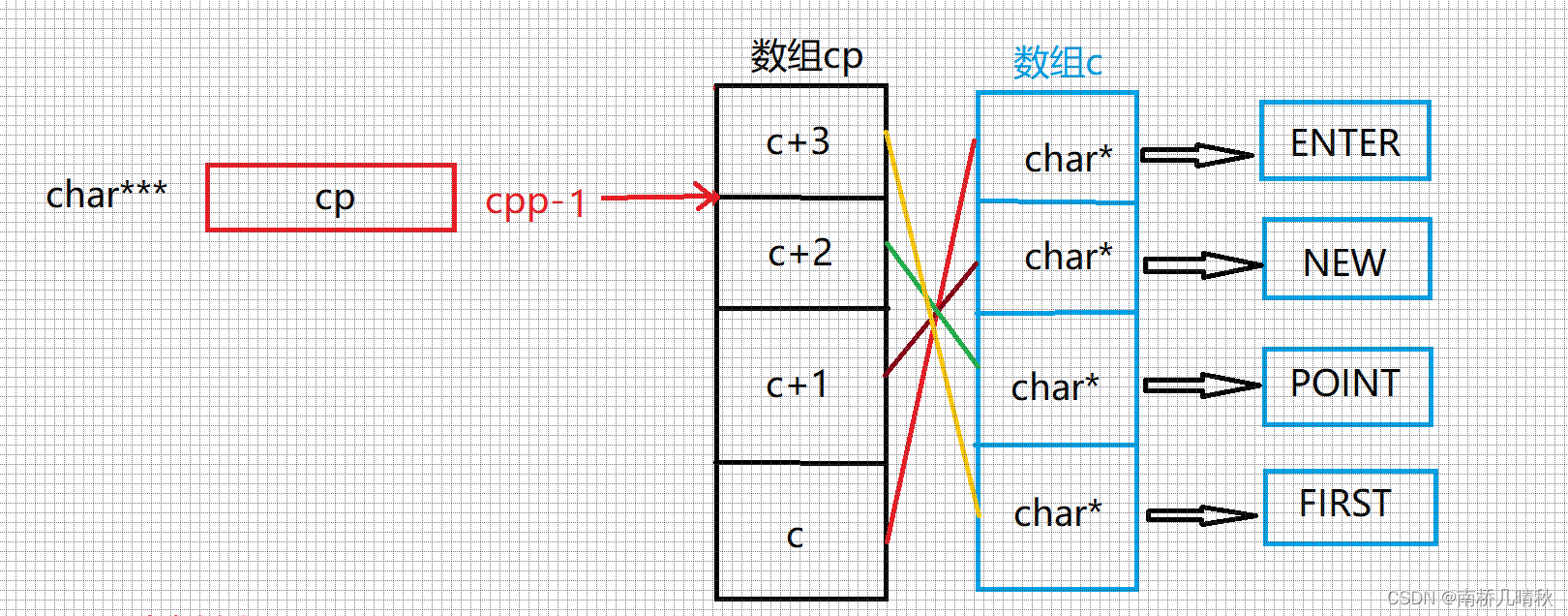
*(cpp-1)解引用,得到c+2,也就是P的地址
*(cpp-1)-1,得到N的地址
*(*(cpp-1)-1)再次解引用,拿到N的值* (*(cpp-1)-1)+1 ,再加1,得到EW
🚩总结
本节题目来自于公司笔试,前面的题目不算很难,需要我们熟练掌握
后面的题目比较难,需要我们逐个分析
理解完这些题目,相信大家对指针有更深刻理解
😏😏😏😏😏😏😏😏😏😏😏😏😏😏😏😏😏😏😏😏😏😏😏





模型SPAM拟合非线性数据和可视化)
-可观测-Metrics)



登录认证)



 线性空间)





