1.背景介绍
流式计算一个很常见的场景是基于事件时间进行处理,常用于检测、监控、根据时间进行统计等系统中。比如埋点日志中每条日志记录了埋点处操作的时间,或者业务系统中记录了用户操作时间,用于统计各种操作处理的频率等,或者根据规则匹配,进行异常行为检测或监控系统告警。这样的时间数据都会包含在事件数据中,需要提取时间字段并根据一定的时间范围进行统计或者规则匹配等。
使用Spark Streaming SQL可以很方便的对事件数据中的时间字段进行处理,同时Spark Streaming SQL提供的时间窗口函数可以将事件时间按照一定的时间区间对数据进行统计操作。
本文通过讲解一个统计用户在过去5秒钟内点击网页次数的案例,介绍如何使用Spark Streaming SQL对事件时间进行操作。
2.时间窗语法说明
Spark Streaming SQL支持两类窗口操作:滚动窗口(TUMBLING)和滑动窗口(HOPPING)。
2.1滚动窗口
滚动窗口(TUMBLING)根据每条数据的时间字段将数据分配到一个指定大小的窗口中进行操作,窗口以窗口大小为步长进行滑动,窗口之间不会出现重叠。例如:如果指定了一个5分钟大小的滚动窗口,数据会根据时间划分到 [0:00 - 0:05)、 [0:05, 0:10)、[0:10, 0:15)等窗口。
- 语法
GROUP BY TUMBLING ( colName, windowDuration ) - 示例
对inventory表的inv_data_time时间列进行窗口操作,统计inv_quantity_on_hand的均值;窗口大小为1分钟。
SELECT avg(inv_quantity_on_hand) qoh
FROM inventory
GROUP BY TUMBLING (inv_data_time, interval 1 minute)2.2滑动窗口
滑动窗口(HOPPING),也被称作Sliding Window。不同于滚动窗口,滑动窗口可以设置窗口滑动的步长,所以窗口可以重叠。滑动窗口有两个参数:windowDuration和slideDuration。slideDuration为每次滑动的步长,windowDuration为窗口的大小。当slideDuration < windowDuration时窗口会重叠,每个元素会被分配到多个窗口中。
所以,滚动窗口其实是滑动窗口的一种特殊情况,即slideDuration = windowDuration则等同于滚动窗口。
- 语法
GROUP BY HOPPING ( colName, windowDuration, slideDuration ) - 示例
对inventory表的inv_data_time时间列进行窗口操作,统计inv_quantity_on_hand的均值;窗口为1分钟,滑动步长为30秒。
SELECT avg(inv_quantity_on_hand) qoh
FROM inventory
GROUP BY HOPPING (inv_data_time, interval 1 minute, interval 30 second)3.系统架构
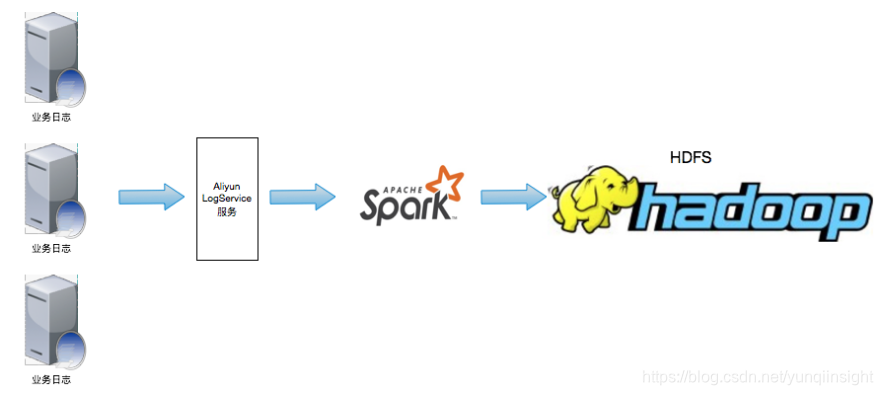
业务日志收集到Aliyun SLS后,Spark对接SLS,通过Streaming SQL对数据进行处理并将统计后的结果写入HDFS中。后续的操作流程主要集中在Spark Streaming SQL接收SLS数据并写入HDFS的部分,有关日志的采集请参考日志服务。
4.操作流程
4.1环境准备
- 创建E-MapReduce 3.21.0以上版本的Hadoop集群。
- 下载并编译E-MapReduce-SDK包
git clone git@github.com:aliyun/aliyun-emapreduce-sdk.git
cd aliyun-emapreduce-sdk
git checkout -b master-2.x origin/master-2.x
mvn clean package -DskipTests编译完后, assembly/target目录下会生成emr-datasources_shaded_${version}.jar,其中${version}为sdk的版本。
4.2创建表
命令行启动spark-sql客户端
spark-sql --master yarn-client --num-executors 2 --executor-memory 2g --executor-cores 2 --jars emr-datasources_shaded_2.11-${version}.jar --driver-class-path emr-datasources_shaded_2.11-${version}.jar创建SLS和HDFS表
spark-sql> CREATE DATABASE IF NOT EXISTS default;
spark-sql> USE default;-- 数据源表
spark-sql> CREATE TABLE IF NOT EXISTS sls_user_log
USING loghub
OPTIONS (
sls.project = "${logProjectName}",
sls.store = "${logStoreName}",
access.key.id = "${accessKeyId}",
access.key.secret = "${accessKeySecret}",
endpoint = "${endpoint}");--结果表
spark-sql> CREATE TABLE hdfs_user_click_count
USING org.apache.spark.sql.json
OPTIONS (path '${hdfsPath}');
4.3统计用户点击数
spark-sql>SET streaming.query.name=user_click_count;
spark-sql>SET spark.sql.streaming.checkpointLocation.user_click_count=hdfs:///tmp/spark/sql/streaming/test/user_click_count;
spark-sql>insert into hdfs_user_click_count
select sum(cast(action_click as int)) as click, userId, window from sls_user_log
where delay(__time__)<"1 minute"
group by TUMBLING(__time__, interval 5 second), userId;其中,内建函数delay()用来设置Streaming SQL中的watermark,后续会有专门的文章介绍Streaming SQL watermark的相关内容。
4.4查看结果

可以看到,产生的结果会自动生成一个window列,包含窗口的起止时间信息。
5.结语
本文简要介绍了流式处理中基于事件时间进行处理的场景,以及Spark Streaming SQL时间窗口的相关内容,并通过一个简单案例介绍了时间窗口的使用。后续文章,我将介绍Spark Streaming SQL的更多内容。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















