前言
监控是保障系统稳定性的重要组成部分,在Kubernetes开源生态中,资源类的监控工具与组件百花齐放。除了社区自己孵化的metrics-server,还有从CNCF毕业的Prometheus等等,开发者可选的方案有很多。但是,只有资源类的监控是远远不够的,因为资源监控存在如下两个主要的缺欠:
- 监控的实时性与准确性不足
大部分资源监控都是基于推或者拉的模式进行数据离线,因此通常数据是每隔一段时间采集一次,如果在时间间隔内出现一些毛刺或者异常,而在下一个采集点到达时恢复,大部分的采集系统会吞掉这个异常。而针对毛刺的场景,阶段的采集会自动削峰,从而造成准确性的降低。
- 监控的场景覆盖范围不足
部分监控场景是无法通过资源表述的,比如Pod的启动停止,是无法简单的用资源的利用率来计量的,因为当资源为0的时候,我们是不能区分这个状态产生的真实原因。
基于上述两个问题,Kubernetes是怎么解决的呢?
事件监控-监控的新维度
Kubernetes作为云原生的平台实现,从架构设计上将接口与实现做到了完整的解耦和插拔,以状态机为整体的设计原则,通过设定期望状态、执行状态转换、检查并补偿状态的方式将资源的生命周期进行接管。
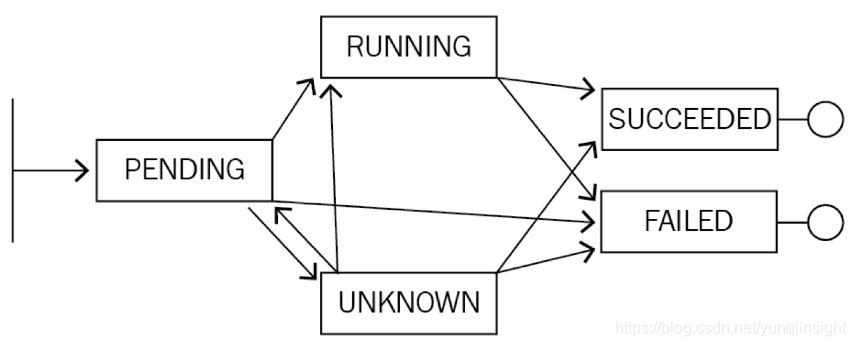
状态之间的转换会产生相应的转换事件,在Kubernetes中,事件分为两种,一种是Warning事件,表示产生这个事件的状态转换是在非预期的状态之间产生的;另外一种是Normal事件,表示期望到达的状态,和目前达到的状态是一致的。我们用一个Pod的生命周期进行举例,当创建一个Pod的时候,首先Pod会进入Pending的状态,等待镜像的拉取,当镜像录取完毕并通过健康检查的时候,Pod的状态就变为Running。此时会生成Normal的事件。而如果在运行中,由于OOM或者其他原因造成Pod宕掉,进入Failed的状态,而这种状态是非预期的,那么此时会在Kubernetes中产生Warning的事件。那么针对这种场景而言,如果我们能够通过监控事件的产生就可以非常及时的查看到一些容易被资源监控忽略的问题。
一个标准的Kubernetes事件有如下几个重要的属性,通过这些属性可以更好地诊断和告警问题。
- Namespace:产生事件的对象所在的命名空间。
- Kind:绑定事件的对象的类型,例如:Node、Pod、Namespace、Componenet等等。
- Timestamp:事件产生的时间等等。
- Reason:产生这个事件的原因。
- Message: 事件的具体描述。
- 其他信息
通过事件的机制,我们可以丰富Kuernetes在监控方面的维度和准确性,弥补其他监控方案的缺欠。
kube-eventer v1.0.0的发布与开源
针对Kubernetes的事件监控场景,Kuernetes社区在Heapter中提供了简单的事件离线能力,后来随着Heapster的废弃,相关的能力也一起被归档了。为了弥补事件监控场景的缺失,阿里云容器服务发布并开源了kubernetes事件离线工具kube-eventer。支持离线kubernetes事件到钉钉机器人、SLS日志服务、Kafka开源消息队列、InfluxDB时序数据库等等。
在本次正式发布的v1.0.0的版本中,作了如下功能的增强。
- 钉钉插件支持Namespace、Kind的过滤
- 支持与NPD插件的集成与部署
- 优化SLS插件的数据离线性能
- 修复InfluxDB插件启动参数失效的问题
- 修复Dockerfile的安全漏洞
- 以及其他共11项功能修复
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















