1. 前言
Schedulerx2.0是阿里中间件自研的基于akka架构的新一代分布式任务调度平台,提供定时、任务编排、分布式跑批等功能,具有高可靠、海量任务、秒级调度等能力。
Schedulerx2.0提供可视化的工作流进行任务编排,该文章将详细介绍如何使用schedulerx2.0的工作流进行上下游任务的数据传输。
2. 接口介绍
2.1 支持的执行方式和任务类型
当前只有java任务支持数据传输,网格计算请使用MapReduce模型进行数据传输。
2.2 返回执行结果
/**** @param status* @param result, the size should less than 1000 bytes* @throws Exception*/
public ProcessResult(boolean status, String result) throws Exception;在Processor结尾,通过该结果替代ProcessResult(boolean status),可以返回执行结果。
result的长度不能超过1000个字节(注意,不是String的长度,如果有中文字符,可能会超过1000个字节!),如果超过1000个字节,任务会失败。
2.3 获取上游数据
List<JobInstanceData> upstreamDatas = JobContext.getUpstreamData();在Processor里,可以通过该接口从JobContext中拿到上游的数据。上游的数据是一个list(可能有多个父节点),JobInstanceData里有两个属性,分别是jobName和data(String类型)。
3. Demo演示
首先我们写三个jobProcessor
public class TestSimpleJobA extends JavaProcessor {@Overridepublic ProcessResult process(JobContext context) throws Exception {System.out.println("TestSimpleJobA " + DateTime.now().toString("yyyy-MM-dd HH:mm:ss"));return new ProcessResult(true, String.valueOf(1));}
}public class TestSimpleJobB extends JavaProcessor {@Overridepublic ProcessResult process(JobContext context) throws Exception {System.out.println("TestSimpleJobB " + DateTime.now().toString("yyyy-MM-dd HH:mm:ss"));return new ProcessResult(true, String.valueOf(2));}
}public class TestSimpleJobC extends JavaProcessor {@Overridepublic ProcessResult process(JobContext context) throws Exception {List<JobInstanceData> upstreamDatas = context.getUpstreamData();int sum = 0;for (JobInstanceData jobInstanceData : upstreamDatas) {System.out.println("jobName=" + jobInstanceData.getJobName() + ", data=" + jobInstanceData.getData());sum += Integer.valueOf(jobInstanceData.getData());}System.out.println("TestSimpleJobC sum=" + sum);return new ProcessResult(true, String.valueOf(sum));}}通过控制台配置工作流如下图所示
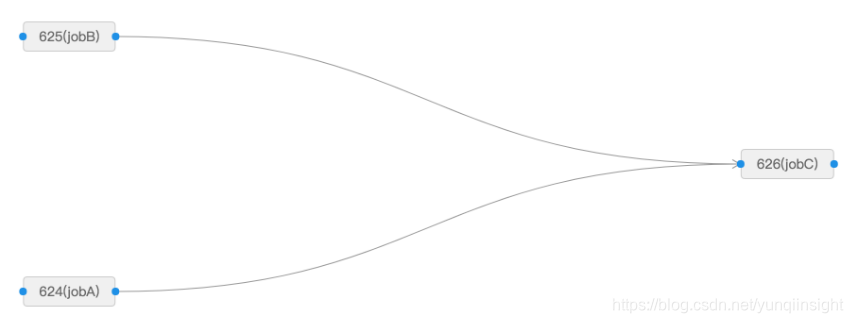
触发一次该工作流,然后进入工作流实例图,右键jobA的实例,进入详情,可以看到jobA实例结果=1,如下图
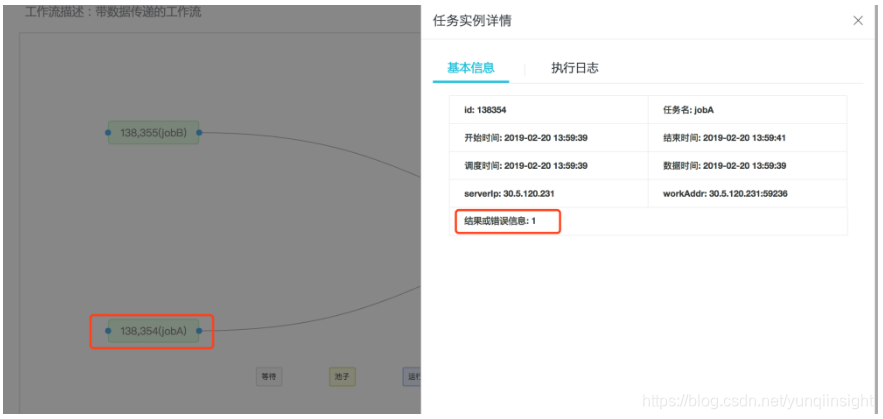
同理,可以看到jobB的实例结果=2, jobC的实例结果=3
控制台也能看到jobC的机器打印
jobName=jobB, data=2
jobName=jobA, data=1
TestSimpleJobC sum=3
原文链接
本文为云栖社区原创内容,未经允许不得转载。















简单使用)



