简介: 订单状态流转是交易系统的最为核心的工作,订单系统往往都会存在状态多、链路长、逻辑复杂的特点,还存在多场景、多类型、多业务维度等业务特性。在保证订单状态流转稳定性的前提下、可扩展性和可维护性是我们需要重点关注和解决的问题。

作者 | 亮言
来源 | 阿里技术公众号
一 背景
订单状态流转是交易系统的最为核心的工作,订单系统往往都会存在状态多、链路长、逻辑复杂的特点,还存在多场景、多类型、多业务维度等业务特性。在保证订单状态流转稳定性的前提下、可扩展性和可维护性是我们需要重点关注和解决的问题。
以高德打车业务的订单状态为例,订单状态就有乘客下单、司机接单、司机已到达乘车点、开始行程、行程结束、确认费用、支付成功、订单取消、订单关闭等;订单车型有专车、快车、出租车等几种车型,而专车又分舒适型、豪华型、商务型等;业务场景接送机、企业用车、城际拼车等等场景。
当订单状态、类型、场景、以及其他一些维度组合时,每一种组合都可能会有不同的处理逻辑、也可能会存在共性的业务逻辑,这种情况下代码中各种if-else肯定是不敢想象的。怎么处理这种"多状态+多类型+多场景+多维度"的复杂订单状态流转业务,又要保证整个系统的可扩展性和可维护性,本文的解决思路和方案同大家一起探讨。
二 实现方案
要解决"多状态+多类型+多场景+多维度"的复杂订单状态流转业务,我们从纵向和横向两个维度进行设计。纵向主要从业务隔离和流程编排的角度出发解决问题、而横向主要从逻辑复用和业务扩展的角度解决问题。
1 纵向解决业务隔离和流程编排
状态模式的应用
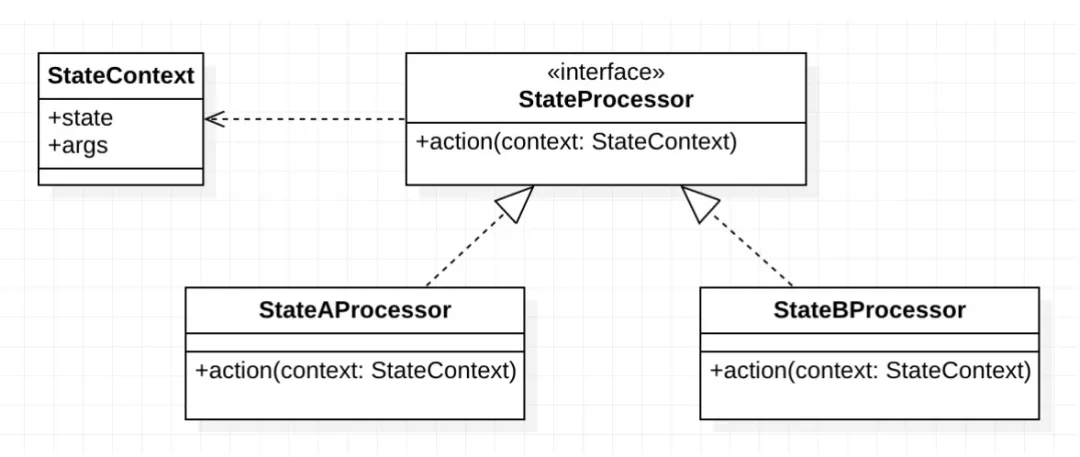
通常我们处理一个多状态或者多维度的业务逻辑,都会采用状态模式或者策略模式来解决,我们这里不讨论两种设计模式的异同,其核心其实可以概括为一个词"分而治之",抽象一个基础逻辑接口、每一个状态或者类型都实现该接口,业务处理时根据不同的状态或者类型调用对应的业务实现,以到达逻辑相互独立互不干扰、代码隔离的目的。
这不仅仅是从可扩展性和可维护性的角度出发,其实我们做架构做稳定性、隔离是一种减少影响面的基本手段,类似的隔离环境做灰度、分批发布等,这里不做扩展。
/*** 状态机处理器接口*/
public interface StateProcessor {/*** 执行状态迁移的入口*/void action(StateContext context) throws Exception;
}/*** 状态A对应的状态处理器*/
public class StateAProcessor interface StateProcessor {/*** 执行状态迁移的入口*/@Overridepublic void action(StateContext context) throws Exception {}
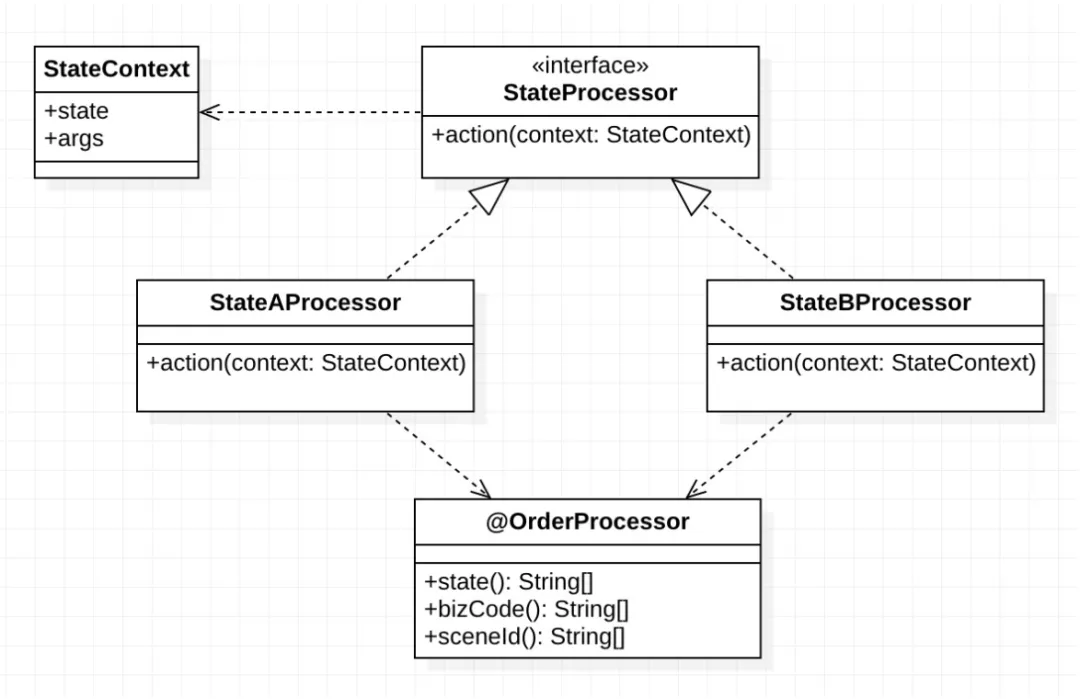
}单一状态或类型可以通过上面的方法解决,那么"多状态+多类型+多场景+多维度"这种组合业务呢,当然也可以采用这种模式或思路来解决。首先在开发阶段通过一个注解@OrderPorcessor将不同的维度予以组合、开发出多个对应的具体实现类,在系统运行阶段,通过判断上下文来动态选择具体使用哪一个实现类执行。@OrderPorcessor中分别定义state代表当前处理器要处理的状态,bizCode和sceneId分别代表业务类型和场景,这两个字段留给业务进行扩展,比如可以用bizCode代表产品或订单类型、sceneId代表业务形态或来源场景等等,如果要扩展多个维度的组合、也可以用多个维度拼接后的字符串赋值到bizCode和sceneId上。
受限于Java枚举不能继承的规范,如果要开发通用的功能、注解中就不能使用枚举、所以此处只好使用String。
/*** 状态机引擎的处理器注解标识*/
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Component
public @interface OrderProcessor {/*** 指定状态,state不能同时存在*/String[] state() default {};/*** 业务*/String[] bizCode() default {};/*** 场景*/String[] sceneId() default {};
}/*** 创建订单状态对应的状态处理器*/
@OrderProcessor(state = "INIT", bizCode = {"CHEAP","POPULAR"}, sceneId = "H5")
public class StateCreateProcessor interface StateProcessor {
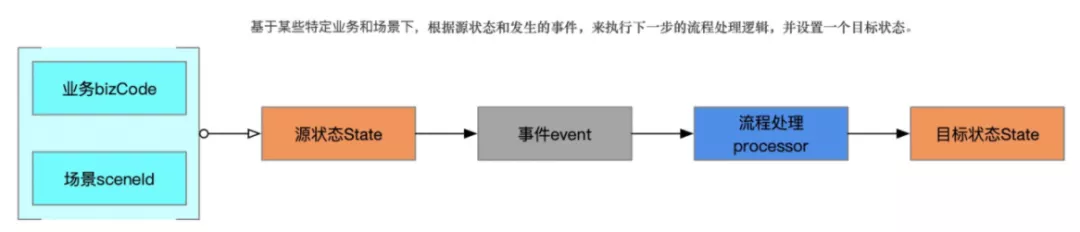
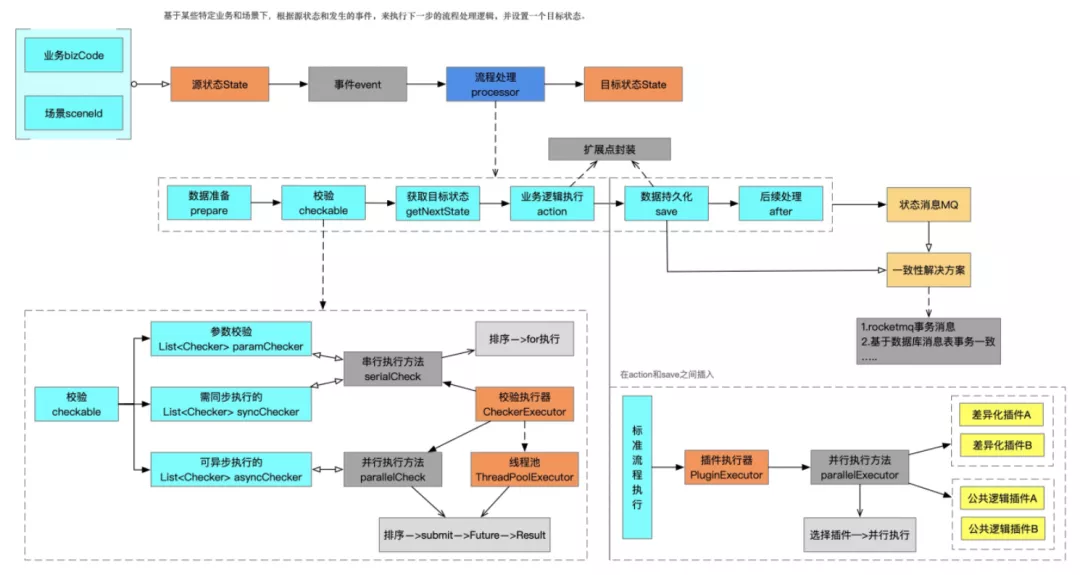
}再想一下,因为涉及到状态流转,不可能会是一个状态A只能流转到状态B、状态A可能在不同的场景下流转到状态B、状态C、状态D;还有虽然都是由状态A流转到状态B、但是不同的场景处理流程也可能不一样,比如都是将订单从从待支付状态进行支付、用户主动发起支付和系统免密支付的流程可能就不一样。针对上面这两种情况、我们把这里的"场景"统一封装为"事件(event)",以"事件驱动"的方式来控制状态的流向,一个状态遇到一个特定的处理事件来决定该状态的业务处理流程和最终状态流向。我们可以总结下,其实状态机模式简单说就是:基于某些特定业务和场景下,根据源状态和发生的事件,来执行下一步的流程处理逻辑,并设置一个目标状态。
这里有人可能有一些疑问,这个"事件"和上面说的"多场景"、"多维度"有什么不一样。解释一下,我们这里说的是"事件"是一个具体的业务要执行的动作,比如用户下单是一个业务事件、用户取消订单是一个业务事件、用户支付订单也是一个业务事件。而"多场景"、"多维度"则是可交由业务自行进行扩展的维度,比如自有标准模式来源的订单、通过开放平台API来的订单、通过第三方标准来源的订单,某某小程序、某某APP来源可以定义为不同场景,而接送机、企业用车、拼车等可以定义为维度。
public @interface OrderProcessor {/*** 指定状态*/String[] state() default {};/*** 订单操作事件*/String event();......
}/*** 订单状态迁移事件*/
public interface OrderStateEvent {/*** 订单状态事件*/String getEventType();/*** 订单ID*/String getOrderId();/*** 如果orderState不为空,则代表只有订单是当前状态才进行迁移*/default String orderState() {return null;}/*** 是否要新创建订单*/boolean newCreate();
}状态迁移流程的封装
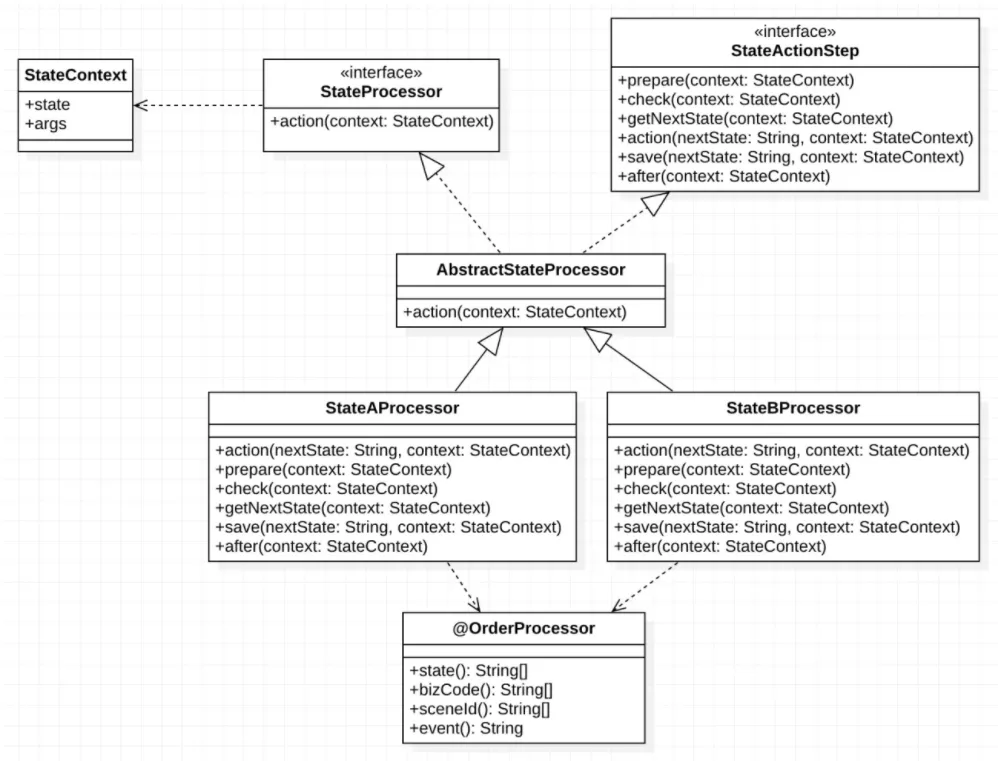
在满足了上面说的多维度组合的业务场景、开发多个实现类来执行的情况,我们思考执行这些实现类在流程上是否有再次抽象和封装的地方、以减少研发工作量和尽量的实现通用流程。我们经过观察和抽象,发现每一个订单状态流转的流程中,都会有三个流程:校验、业务逻辑执行、数据更新持久化;于是再次抽象,可以将一个状态流转分为数据准备(prepare)——>校验(check)——>获取下一个状态(getNextState)——>业务逻辑执行(action)——>数据持久化(save)——>后续处理(after)这六个阶段;然后通过一个模板方法将六个阶段方法串联在一起、形成一个有顺序的执行逻辑。这样一来整个状态流程的执行逻辑就更加清晰和简单了、可维护性上也得到的一定的提升。
/*** 状态迁移动作处理步骤*/
public interface StateActionStep<T, C> {/*** 准备数据*/default void prepare(StateContext<C> context) {}/*** 校验*/ServiceResult<T> check(StateContext<C> context);/*** 获取当前状态处理器处理完毕后,所处于的下一个状态*/String getNextState(StateContext<C> context);/*** 状态动作方法,主要状态迁移逻辑*/ServiceResult<T> action(String nextState, StateContext<C> context) throws Exception;/*** 状态数据持久化*/ServiceResult<T> save(String nextState, StateContext<C> context) throws Exception;/*** 状态迁移成功,持久化后执行的后续处理*/void after(StateContext<C> context);
}/*** 状态机处理器模板类*/
@Component
public abstract class AbstractStateProcessor<T, C> implements StateProcessor<T, C>, StateActionStep<T, C> {@Overridepublic final ServiceResult<T> action(StateContext<C> context) throws Exception {ServiceResult<T> result = null;try {// 数据准备this.prepare(context);// 串行校验器result = this.check(context);if (!result.isSuccess()) {return result;}// getNextState不能在prepare前,因为有的nextState是根据prepare中的数据转换而来String nextState = this.getNextState(context);// 业务逻辑result = this.action(nextState, context);if (!result.isSuccess()) {return result;}// 持久化result = this.save(nextState, context);if (!result.isSuccess()) {return result;}// afterthis.after(context);return result;} catch (Exception e) {throw e;}}/*** 状态A对应的状态处理器*/
@OrderProcessor(state = "INIT", bizCode = {"CHEAP","POPULAR"}, sceneId = "H5")
public class StateCreateProcessor extends AbstractStateProcessor<String, CreateOrderContext> {......
}(1)校验器
上面提到了校验(check),我们都知道任何一个状态的流转甚至接口的调用其实都少不了一些校验规则,尤其是对于复杂的业务、其校验规则和校验逻辑也会更加复杂。那么对于这些校验规则怎么解耦呢,既要将校验逻辑从复杂的业务流程中解耦出来、同时又需要把复杂的校验规则简单化,使整个校验逻辑更具有可扩展性和可维护性。其实做法也比较简单、参考上面的逻辑,只需要抽象一个校验器接口checker、把复杂的校验逻辑拆开、形成多个单一逻辑的校验器实现类,状态处理器在调用check时只需要调用一个接口、由校验器执行多个checker的集合就可以了。将校验器checker进行封装之后,发现要加入一个新的校验逻辑就十分简单了,只需要写一个新的checker实现类加入校验器就行、对其他代码基本没有改动。
/*** 状态机校验器*/
public interface Checker<T, C> {ServiceResult<T> check(StateContext<C> context);/*** 多个checker时的执行顺序*/default int order() {return 0;}
}逻辑简单了、扩展性和维护性解决了、性能问题就会显现出来。多个校验器checker串行执行性能肯定性能比较差,此时很简单的可以想到使用并行执行,是的、此处使用多线程并行执行多个校验器checker能显著提高执行效率。但是也应该意识到,有些校验器逻辑可能是有前后依赖的(其实不应该出现),还有写业务流程中要求某些校验器的执行必须有前后顺序,还有些流程不要求校验器的执行顺序但是要求错误时的返回顺序、那么怎么在并行的前提下保证顺序呢、此处就可以用order+Future实现了。经过一系列的思考和总结,我们把校验器分为参数校验(paramChecker)、同步校验(syncChecker)、异步校验(asyncChecker)三种类型,其中参数校验paramChecker是需要在状态处理器最开始处执行的,为什么这么做、因为参数都不合法了肯定没有继续向下执行的必要了。
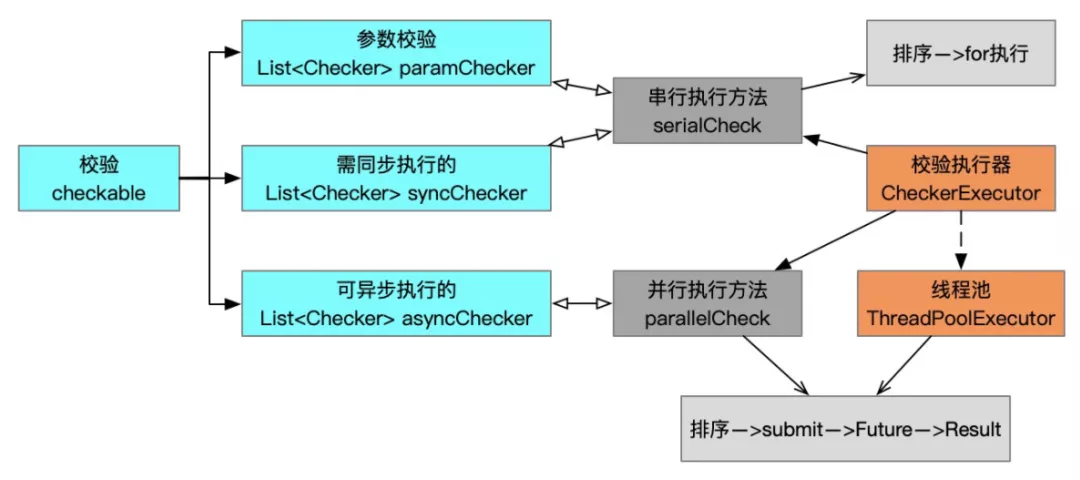
/*** 状态机校验器*/
public interface Checkable {/*** 参数校验*/default List<Checker> getParamChecker() {return Collections.EMPTY_LIST;}/*** 需同步执行的状态检查器*/default List<Checker> getSyncChecker() {return Collections.EMPTY_LIST;}/*** 可异步执行的校验器*/default List<Checker> getAsyncChecker() {return Collections.EMPTY_LIST;}
}/*** 校验器的执行器*/
public class CheckerExecutor {/*** 执行并行校验器,* 按照任务投递的顺序判断返回。*/public ServiceResult<T, C> parallelCheck(List<Checker> checkers, StateContext<C> context) {if (!CollectionUtils.isEmpty(checkers)) {if (checkers.size() == 1) {return checkers.get(0).check(context);}List<Future<ServiceResult>> resultList = Collections.synchronizedList(new ArrayList<>(checkers.size()));checkers.sort(Comparator.comparingInt(Checker::order));for (Checker c : checkers) {Future<ServiceResult> future = executor.submit(() -> c.check(context));resultList.add(future);}for (Future<ServiceResult> future : resultList) {try {ServiceResult sr = future.get();if (!sr.isSuccess()) {return sr;}} catch (Exception e) {log.error("parallelCheck executor.submit error.", e);throw new RuntimeException(e);}}}return new ServiceResult<>();}
}checkable在模板方法中的使用。
public interface StateActionStep<T, C> {Checkable getCheckable(StateContext<C> context);....
}public abstract class AbstractStateProcessor<T, C> implements StateProcessor<T>, StateActionStep<T, C> {@Resourceprivate CheckerExecutor checkerExecutor;@Overridepublic final ServiceResult<T> action(StateContext<C> context) throws Exception {ServiceResult<T> result = null;Checkable checkable = this.getCheckable(context);try {// 参数校验器result = checkerExecutor.serialCheck(checkable.getParamChecker(), context);if (!result.isSuccess()) {return result;}// 数据准备this.prepare(context);// 串行校验器result = checkerExecutor.serialCheck(checkable.getSyncChecker(), context);if (!result.isSuccess()) {return result;}// 并行校验器result = checkerExecutor.parallelCheck(checkable.getAsyncChecker(), context);if (!result.isSuccess()) {return result;}......
}checkable在具体状态处理器中的代码应用举例。
@OrderProcessor(state = "INIT", bizCode = {"CHEAP","POPULAR"}, sceneId = "H5")
public class OrderCreatedProcessor extends AbstractStateProcessor<String, CreateOrderContext> {@Resourceprivate CreateParamChecker createParamChecker;@Resourceprivate UserChecker userChecker;@Resourceprivate UnfinshChecker unfinshChecker;@Overridepublic Checkable getCheckable(StateContext<CreateOrderContext> context) {return new Checkable() {@Overridepublic List<Checker> getParamChecker() {return Arrays.asList(createParamChecker);}@Overridepublic List<Checker> getSyncChecker() {return Collections.EMPTY_LIST;}@Overridepublic List<Checker> getAsyncChecker() {return Arrays.asList(userChecker, unfinshChecker);}};}
......checker的定位是校验器,负责校验参数或业务的合法性,但实际编码过程中、checker中可能会有一些临时状态类操作,比如在校验之前进行计数或者加锁操作、在校验完成后根据结果进行释放,这里就需要支持统一的释放功能。
public interface Checker<T, C> {....../*** 是否需求release*/default boolean needRelease() {return false;}/*** 业务执行完成后的释放方法,* 比如有些业务会在checker中加一些状态操作,等业务执行完成后根据结果选择处理这些状态操作,* 最典型的就是checker中加一把锁,release根据结果释放锁.*/default void release(StateContext<C> context, ServiceResult<T> result) {}
}public class CheckerExecutor {/*** 执行checker的释放操作*/public <T, C> void releaseCheck(Checkable checkable, StateContext<C> context, ServiceResult<T> result) {List<Checker> checkers = new ArrayList<>();checkers.addAll(checkable.getParamChecker());checkers.addAll(checkable.getSyncChecker());checkers.addAll(checkable.getAsyncChecker());checkers.removeIf(Checker::needRelease);if (!CollectionUtils.isEmpty(checkers)) {if (checkers.size() == 1) {checkers.get(0).release(context, result);return;}CountDownLatch latch = new CountDownLatch(checkers.size());for (Checker c : checkers) {executor.execute(() -> {try {c.release(context, result);} finally {latch.countDown();}});}try {latch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}}}
}2)上下文
从上面代码可以发现,整个状态迁移的几个方法都是使用上下文Context对象串联的。Context对象中一共有三类对象,(1)订单的基本信息(订单ID、状态、业务属性、场景属性)、(2)事件对象(其参数基本就是状态迁移行为的入参)、(3)具体处理器决定的泛型类。一般要将数据在多个方法中进行传递有两种方案:一个是包装使用ThreadLocal、每个方法都可以对当前ThreadLocal进行赋值和取值;另一种是使用一个上下文Context对象做为每个方法的入参传递。这种方案都有一些优缺点,使用ThreadLocal其实是一种"隐式调用",虽然可以在"随处"进行调用、但是对使用方其实不明显的、在中间件中会大量使用、在开发业务代码中是需要尽量避免的;而使用Context做为参数在方法中进行传递、可以有效的减少"不可知"的问题。
不管是使用ThreadLocal还是Context做为参数传递,对于实际承载的数据载体有两种方案,常见的是使用Map做为载体,业务在使用的时候可以根据需要随意的设置任何kv,但是这种情况对代码的可维护性和可读性是极大的挑战,所以这里使用泛型类来固定数据格式,一个具体的状态处理流程到底需要对哪些数据做传递需要明确定义好。其实原则是一样的,业务开发尽量用用可见性避免不可知。
public class StateContext<C> {/*** 订单操作事件*/private OrderStateEvent orderStateEvent;/*** 状态机需要的订单基本信息*/private FsmOrder fsmOrder;/*** 业务可定义的上下文泛型对象*/private C context;public StateContext(OrderStateEvent orderStateEvent, FsmOrder fsmOrder) {this.orderStateEvent = orderStateEvent;this.fsmOrder = fsmOrder;}....../*** 状态机引擎所需的订单信息基类信息*/
public interface FsmOrder {/*** 订单ID*/String getOrderId();/*** 订单状态*/String getOrderState();/*** 订单的业务属性*/String bizCode();/*** 订单的场景属性*/String sceneId();
}(3)迁移到的状态判定
为什么要把下一个状态(getNextState)抽象为单独一个步骤、而不是交由业务自己进行设置呢?是因为要迁移到的下一个状态不一定是固定的,就是说根据当前状态和发生的事件、再遇到更加细节的逻辑时也可能会流转到不同的状态。举个例子,当前状态是用户已下单完成、要发生的事件是用户取消订单,此时根据不同的逻辑,订单有可能流转到取消状态、也有可能流转到取消待审核状态、甚至有可能流转到取消待支付费用状态。当然这里要取决于业务系统对状态和事件定义的粗细和状态机的复杂程度,做为状态机引擎、这里把下一个状态的判定交由业务根据上下文对象自己来判断。
getNextState()使用及状态迁移持久化举例:
@OrderProcessor(state = OrderStateEnum.INIT, event = OrderEventEnum.CREATE, bizCode = "BUSINESS")
public class OrderCreatedProcessor extends AbstractStateProcessor<String, CreateOrderContext> {........@Overridepublic String getNextState(StateContext<CreateOrderContext> context) {// if (context.getOrderStateEvent().getEventType().equals("xxx")) {// return OrderStateEnum.INIT;// }return OrderStateEnum.NEW;}@Overridepublic ServiceResult<String> save(String nextState, StateContext<CreateOrderContext> context) throws Exception {OrderInfo orderInfo = context.getContext().getOrderInfo();// 更新状态orderInfo.setOrderState(nextState);// 持久化
// this.updateOrderInfo(orderInfo);log.info("save BUSINESS order success, userId:{}, orderId:{}", orderInfo.getUserId(), orderInfo.getOrderId());return new ServiceResult<>(orderInfo.getOrderId(), "business下单成功");}
}状态消息
一般来说,所有的状态迁移都应该发出对应的消息,由下游消费方订阅进行相应的业务处理。
(1)状态消息内容
对于状态迁移消息的发送内容通常有两种形式,一个是只发状态发生迁移这个通知、举例子就是只发送"订单ID、变更前状态、变更后状态"等几个关键字段,具体下游业务需要哪些具体内容在调用相应的接口进行反查;还有一种是发送所有字段出去、类似于发一个状态变更后的订单内容快照,下游接到消息后几乎不需要在调用接口进行反查。
(2)状态消息的时序
状态迁移是有时序的,因此很多下游依赖方也需要判断消息的顺序。一种实现方案是使用顺序消息(rocketmq、kafka等),但基于并发吞吐量的考虑很少采用这种方案;一般都是在消息体中加入"消息发送时间"或者"状态变更时间"字段,有消费方自己进行处理。
(3)数据库状态变更和消息的一致性
状态变更需要和消息保持一致吗?
很多时候是需要的,如果数据库状态变更成功了、但是状态消息没有发送出去、则会导致一些下游依赖方处理逻辑的缺失。而我们知道,数据库和消息系统是无法保证100%一致的,我们要保证的是主要数据库状态变更了、消息就要尽量接近100%的发送成功。
那么怎么保证呢?
其实通常确实有几种方案:
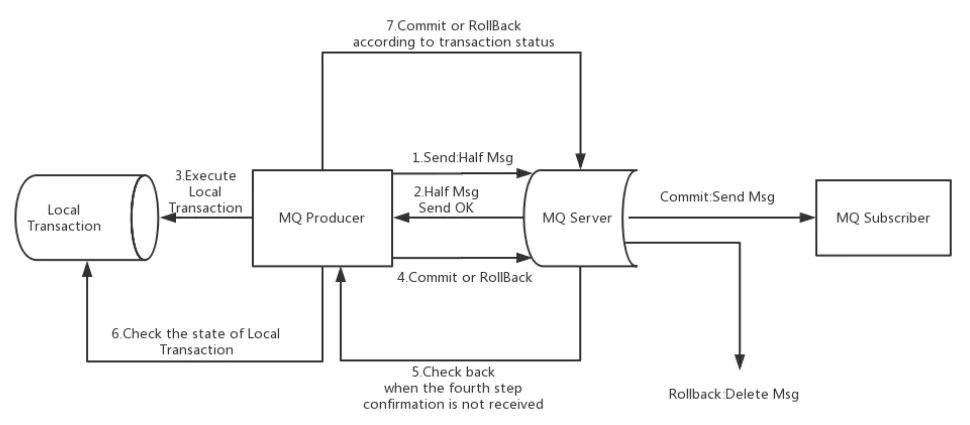
a)使用rocketmq等支持的两阶段式消息提交方式:
- 先向消息服务器发送一条预处理消息
- 当本地数据库变更提交之后、再向消息服务器发送一条确认发送的消息
- 如果本地数据库变更失败、则向消息服务器发送一条取消发送的消息
- 如果长时间没有向消息服务器发生确认发送的消息,消息系统则会回调一个提前约定的接口、来查看本地业务是否成功,以此决定是否真正发生消息
b)使用数据库事务方案保证:
- 创建一个消息发送表,将要发送的消息插入到该表中,同本地业务在一个数据库事务中进行提交
- 之后在由一个定时任务来轮询发送、直到发送成功后在删除当前表记录
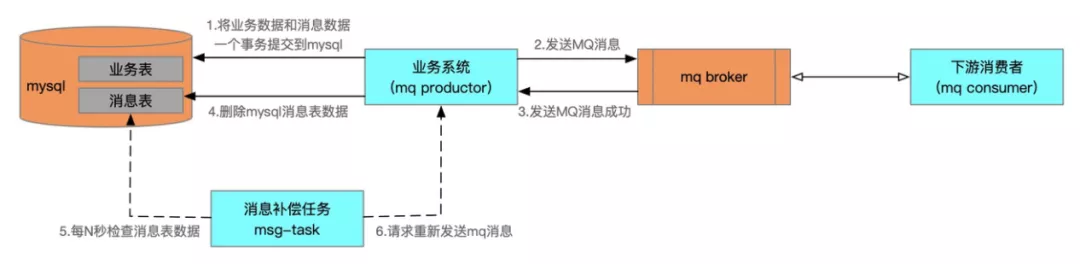
c)还是使用数据库事务方案保证:
- 创建一个消息发送表,将要发送的消息插入到该表中,同本地业务在一个数据库事务中进行提交
- 向消息服务器发送消息
- 发送成功则删除掉当前表记录
- 对于没有发送成功的消息(也就是表里面没有被删除的记录),再由定时任务来轮询发送
还有其他方案吗?有的。
d)数据对账、发现不一致时进行补偿处理、以此保证数据的最终一致。其实不管使用哪种方案来保证数据库状态变更和消息的一致,数据对账的方案都是"必须"要有的一种兜底方案。
那么、还有其他方案吗?还是有的,对于数据库状态变更和消息的一致性的问题,细节比较多,每种方案又都有相应的优缺点,本文主要是介绍状态机引擎的设计,对于消息一致性的问题就不过多介绍,后面也许会有单独的文章对数据库变更和消息的一致性的问题进行介绍和讨论。
2 横向解决逻辑复用和实现业务扩展
实现基于"多类型+多场景+多维度"的代码分离治理、以及标准处理流程模板的状态机模型之后,其实在真正编码的时候会发现不同类型不同维度对于同一个状态的流程处理过程,有时多个处理逻辑中的一部分流程一样的或者是相似的,比如支付环节不管是采用免密还是其他方式、其中核销优惠券的处理逻辑、设置发票金额的处理逻辑等都是一样的;甚至有些时候多个类型间的处理逻辑大部分是相同的而差异是小部分,比如下单流程的处理逻辑基本逻辑都差不多,而出租车对比网约车可能就多了出租车红包、无预估价等个别流程的差异。
对于上面这种情况、其实就是要实现在纵向解决业务隔离和流程编排的基础上,需要支持小部分逻辑或代码段的复用、或者大部分流程的复用,减少重复建设和开发。对此我们在状态机引擎中支持两种解决方案:
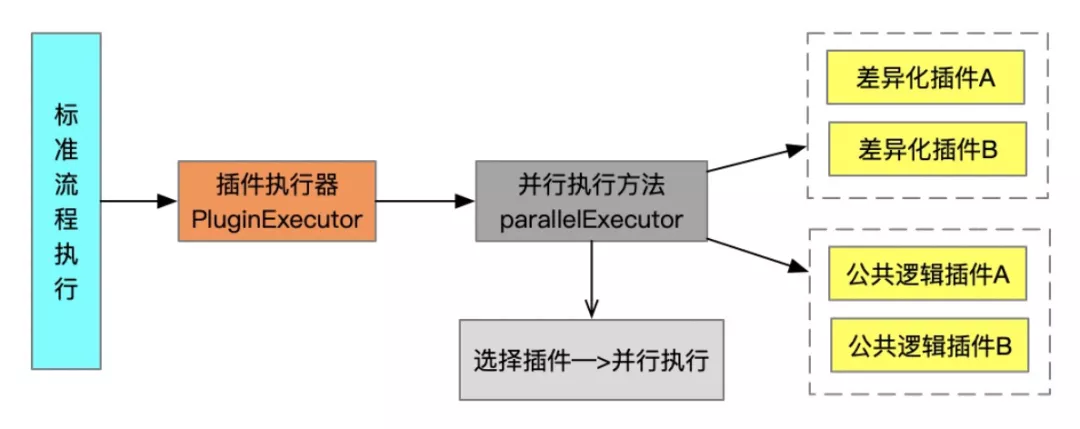
基于插件化的解决方案
插件的主要逻辑是:可以在业务逻辑执行(action)、数据持久化(save)这两个节点前加载对应到的插件类进行执行,主要是对上下文Context对象进行操作、或者根据Context参数发起不同的流程调用,已到达改变业务数据或流程的目的。
(1)标准流程+差异化插件
上面讲到同一个状态模型下、不同的类型或维度有些逻辑或处理流程是一样的小部分逻辑是不同的。于是我们可以把一种处理流程定义为标准的或默认的处理逻辑,把差异化的代码写成插件,当业务执行到具体差异化逻辑时会调用到不同的插件进行处理,这样只需要为不同的类型或维度编写对应有差异逻辑的插件即可、标准的处理流程由默认的处理器执行就行。
(2)差异流程+公用插件
当然对于小部分逻辑和代码可以公用的场景,也可以用插件化的方案解决。比如对于同一个状态下多个维修下不同处理器中、我们可以把相同的逻辑或代码封装成一个插件,多个处理器中都可以识别加载该插件进行执行,从而实现多个差异的流程使用想用插件的形式。
/*** 插件注解*/
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Component
public @interface ProcessorPlugin {/*** 指定状态,state不能同时存在*/String[] state() default {};/*** 订单操作事件*/String event();/*** 业务*/String[] bizCode() default {};/*** 场景*/String[] sceneId() default {};
}
* 插件处理器*/
public interface PluginHandler<T, C> extends StateProcessor<T, C> {
}Plug在处理器模板中的执行逻辑。
public abstract class AbstractStateProcessor<T, C> implements StateProcessor<T>, StateActionStep<T, C> {@Overridepublic final ServiceResult<T> action(StateContext<C> context) throws Exception {ServiceResult<T> result = null;try {......// 业务逻辑result = this.action(nextState, context);if (!result.isSuccess()) {return result;}// 在action和save之间执行插件逻辑this.pluginExecutor.parallelExecutor(context);// 持久化result = this.save(nextState, context));if (!result.isSuccess()) {return result;}......} catch (Exception e) {throw e;}}插件使用的例子:
/*** 预估价插件*/
@ProcessorPlugin(state = OrderStateEnum.INIT, event = OrderEventEnum.CREATE, bizCode = "BUSINESS")
public class EstimatePricePlugin implements PluginHandler<String, CreateOrderContext> {@Overridepublic ServiceResult action(StateContext<CreateOrderContext> context) throws Exception {
// String price = priceSerive.getPrice();String price = "";context.getContext().setEstimatePriceInfo(price);return new ServiceResult();}
}基于代码继承方式的解决方案
当发现新增一个状态不同维度的处理流程,和当前已存在的一个处理器大部分逻辑是相同的,此时就可以使新写的这个处理器B继承已存在的处理器A,只需要让处理器B覆写A中不同方法逻辑、实现差异逻辑的替换。这种方案比较好理解,但是需要处理器A已经规划好一些可以扩展的点、其他处理器可以基于这些扩展点进行覆写替换。当然更好的方案其实是,先实现一个默认的处理器,把所有的标准处理流程和可扩展点进行封装实现、其他处理器进行继承、覆写、替换就好。
@OrderProcessor(state = OrderStateEnum.INIT, event = OrderEventEnum.CREATE, bizCode = "CHEAP")
public class OrderCreatedProcessor extends AbstractStateProcessor<String, CreateOrderContext> {@Overridepublic ServiceResult action(String nextState, StateContext<CreateOrderContext> context) throws Exception {CreateEvent createEvent = (CreateEvent) context.getOrderStateEvent();// 促销信息信息String promtionInfo = this.doPromotion();......}/*** 促销相关扩展点*/protected String doPromotion() {return "1";}
}@OrderProcessor(state = OrderStateEnum.INIT, event = OrderEventEnum.CREATE, bizCode = "TAXI")
public class OrderCreatedProcessor4Taxi extends OrderCreatedProcessor<String, CreateOrderContext> {@Overrideprotected String doPromotion() {return "taxt1";}
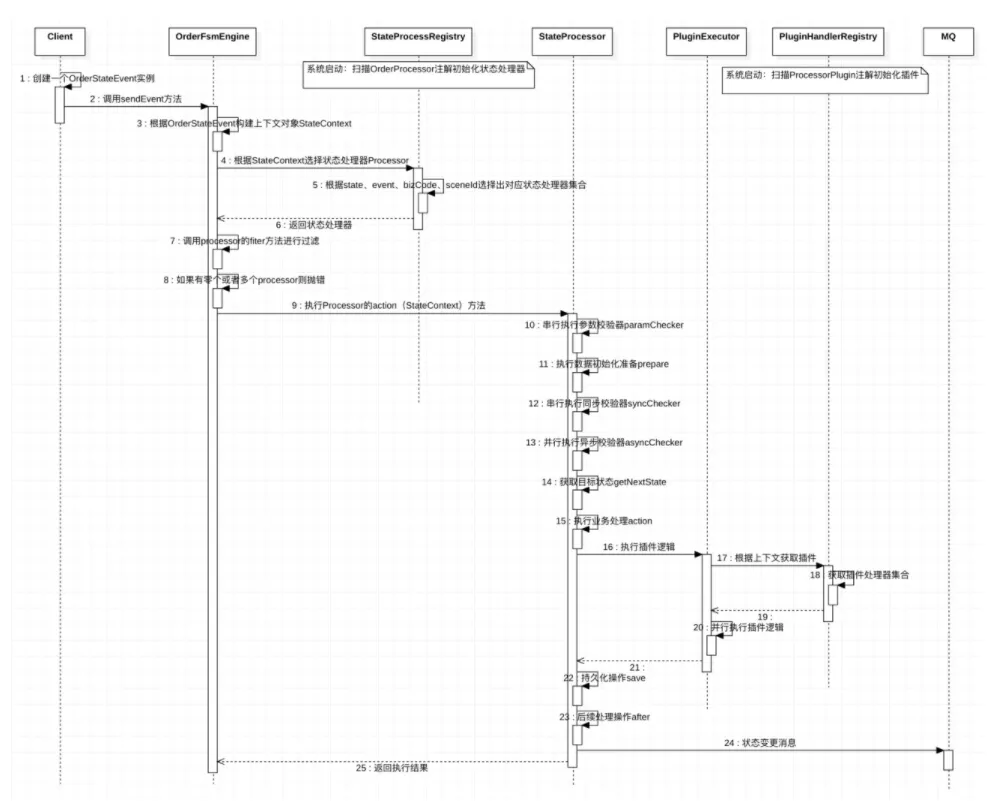
}3 状态迁移流程的执行流程
状态机引擎的执行过程
通过上面的介绍,大体明白了怎么实现状态流程编排、业务隔离和扩展等等,但是状态机引擎具体是怎么把这个过程串联起来的呢?简单说、分为两个阶段:初始化阶段和运行时阶段。
(1)状态机引擎初始化阶段
首先在代码编写阶段、根据上面的分析,业务通过实现AbstractStateProcessor模板类、并添加@OrderProcessor注解来实现自己的多个需要的特定状态处理器。
那么在系统初始化阶段,所有添加了@OrderProcessor注解的实现类都会被spring所管理成为spring bean,状态机引擎在通过监听spring bean的注册(BeanPostProcessor)来将这些状态处理器processor装载到自己管理的容器中。直白来说、这个状态处理器容器其实就是一个多层map实现的,第一层map的key是状态(state),第二层map的key是状态对应的事件(event)、一个状态可以有多个要处理的事件,第三层map的key是具体的场景code(也就是bizCode和sceneId的组合),最后的value是AbstractStateProcessor集合。
public class DefaultStateProcessRegistry implements BeanPostProcessor {/*** 第一层key是订单状态。* 第二层key是订单状态对应的事件,一个状态可以有多个事件。* 第三层key是具体场景code,场景下对应的多个处理器,需要后续进行过滤选择出一个具体的执行。*/private static Map<String, Map<String, Map<String, List<AbstractStateProcessor>>>> stateProcessMap = new ConcurrentHashMap<>();@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {if (bean instanceof AbstractStateProcessor && bean.getClass().isAnnotationPresent(OrderProcessor.class)) {OrderProcessor annotation = bean.getClass().getAnnotation(OrderProcessor.class);String[] states = annotation.state();String event = annotation.event();String[] bizCodes = annotation.bizCode().length == 0 ? new String[]{"#"} : annotation.bizCode();String[] sceneIds = annotation.sceneId().length == 0 ? new String[]{"#"} : annotation.sceneId();initProcessMap(states, event, bizCodes, sceneIds, stateProcessMap, (AbstractStateProcessor) bean);}return bean;}private <E extends StateProcessor> void initProcessMap(String[] states, String event, String[] bizCodes, String[] sceneIds,Map<String, Map<String, Map<String, List<E>>>> map, E processor) {for (String bizCode : bizCodes) {for (String sceneId : sceneIds) {Arrays.asList(states).parallelStream().forEach(orderStateEnum -> {registerStateHandlers(orderStateEnum, event, bizCode, sceneId, map, processor);});}}}/*** 初始化状态机处理器*/public <E extends StateProcessor> void registerStateHandlers(String orderStateEnum, String event, String bizCode, String sceneId,Map<String, Map<String, Map<String, List<E>>>> map, E processor) {// state维度if (!map.containsKey(orderStateEnum)) {map.put(orderStateEnum, new ConcurrentHashMap<>());}Map<String, Map<String, List<E>>> stateTransformEventEnumMap = map.get(orderStateEnum);// event维度if (!stateTransformEventEnumMap.containsKey(event)) {stateTransformEventEnumMap.put(event, new ConcurrentHashMap<>());}// bizCode and sceneIdMap<String, List<E>> processorMap = stateTransformEventEnumMap.get(event);String bizCodeAndSceneId = bizCode + "@" + sceneId;if (!processorMap.containsKey(bizCodeAndSceneId)) {processorMap.put(bizCodeAndSceneId, new CopyOnWriteArrayList<>());}processorMap.get(bizCodeAndSceneId).add(processor);}
}(2)状态机引擎运行时阶段
经过初始化之后,所有的状态处理器processor都被装载到容器。在运行时,通过一个入口来发起对状态机的调用,方法的主要参数是操作事件(event)和业务入参,如果是新创建订单请求需要携带业务(bizCode)和场景(sceneId)信息、如果是已存在订单的更新状态机引擎会根据oderId自动获取业务(bizCode)、场景(sceneId)和当前状态(state)。之后引擎根据state+event+bizCode+sceneId从状态处理器容器中获取到对应的具体处理器processor,从而进行状态迁移处理。
/*** 状态机执行引擎*/
public interface OrderFsmEngine {/*** 执行状态迁移事件,不传FsmOrder默认会根据orderId从FsmOrderService接口获取*/<T> ServiceResult<T> sendEvent(OrderStateEvent orderStateEvent) throws Exception;/*** 执行状态迁移事件,可携带FsmOrder参数*/<T> ServiceResult<T> sendEvent(OrderStateEvent orderStateEvent, FsmOrder fsmOrder) throws Exception;
}@Component
public class DefaultOrderFsmEngine implements OrderFsmEngine {@Overridepublic <T> ServiceResult<T> sendEvent(OrderStateEvent orderStateEvent) throws Exception {FsmOrder fsmOrder = null;if (orderStateEvent.newCreate()) {fsmOrder = this.fsmOrderService.getFsmOrder(orderStateEvent.getOrderId());if (fsmOrder == null) {throw new FsmException(ErrorCodeEnum.ORDER_NOT_FOUND);}}return sendEvent(orderStateEvent, fsmOrder);}@Overridepublic <T> ServiceResult<T> sendEvent(OrderStateEvent orderStateEvent, FsmOrder fsmOrder) throws Exception {// 构造当前事件上下文StateContext context = this.getStateContext(orderStateEvent, fsmOrder);// 获取当前事件处理器StateProcessor<T> stateProcessor = this.getStateProcessor(context);// 执行处理逻辑return stateProcessor.action(context);}private <T> StateProcessor<T, ?> getStateProcessor(StateContext<?> context) {OrderStateEvent stateEvent = context.getOrderStateEvent();FsmOrder fsmOrder = context.getFsmOrder();// 根据状态+事件对象获取所对应的业务处理器集合List<AbstractStateProcessor> processorList = stateProcessorRegistry.acquireStateProcess(fsmOrder.getOrderState(),stateEvent.getEventType(), fsmOrder.bizCode(), fsmOrder.sceneId());if (processorList == null) {// 订单状态发生改变if (!Objects.isNull(stateEvent.orderState()) && !stateEvent.orderState().equals(fsmOrder.getOrderState())) {throw new FsmException(ErrorCodeEnum.ORDER_STATE_NOT_MATCH);}throw new FsmException(ErrorCodeEnum.NOT_FOUND_PROCESSOR);}if (CollectionUtils.isEmpty(processorResult)) {throw new FsmException(ErrorCodeEnum.NOT_FOUND_PROCESSOR);}if (processorResult.size() > 1) {throw new FsmException(ErrorCodeEnum.FOUND_MORE_PROCESSOR);}return processorResult.get(0);}private StateContext<?> getStateContext(OrderStateEvent orderStateEvent, FsmOrder fsmOrder) {StateContext<?> context = new StateContext(orderStateEvent, fsmOrder);return context;}
}检测到多个状态执行器怎么处理
有一点要说明,有可能根据state+event+bizCode+sceneId信息获取到的是多个状态处理器processor,有可能确实业务需要单纯依赖bizCode和sceneId两个属性无法有效识别和定位唯一processor,那么我们这里给业务开一个口、由业务决定从多个处理器中选一个适合当前上下文的,具体做法是业务processor通过filter方法根据当前context来判断是否符合调用条件。
private <T> StateProcessor<T, ?> getStateProcessor(StateContext<?> context) {// 根据状态+事件对象获取所对应的业务处理器集合List<AbstractStateProcessor> processorList = .........List<AbstractStateProcessor> processorResult = new ArrayList<>(processorList.size());// 根据上下文获取唯一的业务处理器for (AbstractStateProcessor processor : processorList) {if (processor.filter(context)) {processorResult.add(processor);}}......
}filter在具体状态处理器processor中的使用举例:
@OrderProcessor(state = OrderStateEnum.INIT, event = OrderEventEnum.CREATE, bizCode = "BUSINESS")
public class OrderCreatedProcessor extends AbstractStateProcessor<String, CreateOrderContext> {......@Overridepublic boolean filter(StateContext<CreateOrderContext> context) {OrderInfo orderInfo = (OrderInfo) context.getFsmOrder();if (orderInfo.getServiceType() == ServiceType.TAKEOFF_CAR) {return true;}return false;}......
}当然,如果最终经过业务filter之后,还是有多个状态处理器符合条件,那么这里只能抛异常处理了。这个需要在开发时,对状态和多维度处理器有详细规划。
4 状态机引擎执行总结
状态机引擎处理流程
简易的状态机引擎的执行流程整理,主要介绍运行时的状态机执行过程。
状态处理器的原理
简易的状态机处理器的原理和依赖整理,主要介绍状态处理器的流程和细节。
三 其他
还有其他问题么,想一下。
1 状态流转并发问题怎么处理?
如果一个订单当前是状态A、此刻从不同的维度或入口分别发起了不同的事件请求,此时怎么处理?
比如当前订单是新创建完成状态,用户发起了取消同时客服也发起了取消,在或者订单是待支付状态、系统发起了免密支付同时客服或者用户发起了改价。这些场景不管是系统照成的并发还是业务操作造成的并发,并发是真实存在的。对于这种情况、原则是同一时刻一个订单只能有一个状态变更事件可进行,其他的请求要么排队、要么返回由上游进行处理或重试等。
我们的做法是:
- 在状态机OrderFsmEngine的sendEvent入口处,针对同一个订单维度加锁(redis分布式锁)、同一时间只允许有一个状态变更操作进行,其他请求则进行排队等待。
- 在数据库层对当前state做校验、类似与乐观锁方式。最终是将其他请求抛错、由上游业务进行处理。
2 能不能动态实现状态流程的切换和编排?
最开始我们有一个版本,状态处理器的定义不是由注解方式实现、而是将state、event、bizCode、sceneId、processor这些通过数据库表来保存,初始化时从数据库加载后进行处理器的装载。同时通过一个后台可以动态的调整state、event、bizCode、sceneId、processor对应关系、以此来达到动态灵活配置流程的效果,但是随着业务的上线,基本从来没有进行动态变更过,其实也不敢操作,毕竟状态流转事十分核心的业务、一旦因变更导致故障是不可想象的。
3 通用性的问题
其实不仅仅订单系统、甚至不仅是状态机逻辑可以用上面讲的这些思路处理,很多日常中其他一些多维度的业务都可以采取这些方案进行处理。
4 与TMF的结合
其实这套状态机引擎还是比较简单的、对于业务扩展点处的定义也不是十分友好,目前我们也正在结合TMF框架来定制扩展点,TMF是从执行具体扩展点实现的角度出发,达到标准流程和具体业务逻辑分离的效果。
当然不管那种方案,扩展点的定义是业务需要核心关心和友好封装的事情。
原文链接
本文为阿里云原创内容,未经允许不得转载。







 undefined_SweetAlert2使用教程)











