简介: 最佳实践,以DLA为例子。DLA致力于帮助客户构建低成本、简单易用、弹性的数据平台,比传统Hadoop至少节约50%的成本。其中DLA Meta支持云上15+种数据数据源(OSS、HDFS、DB、DW)的统一视图,引入多租户、元数据发现,追求边际成本为0,免费提供使用。DLA Lakehouse基于Apache Hudi实现,主要目标是提供高效的湖仓,支持CDC及消息的增量写入,目前这块在加紧产品化中。DLA Serverless Presto是基于Apache PrestoDB研发的,主要是做联邦交互式查询与轻量级ETL。
背景
数据湖当前在国内外是比较热的方案,MarketsandMarkets (https://www.marketsandmarkets.com/Market-Reports/data-lakes-market-213787749.html)市场调研显示预计数据湖市场规模在2024年会从2019年的79亿美金增长到201亿美金。一些企业已经构建了自己的云原生数据湖方案,有效解决了业务痛点;还有很多企业在构建或者计划构建自己的数据湖。Gartner 2020年发布的报告显示(https://www.gartner.com/smarterwithgartner/the-best-ways-to-organize-your-data-structures/)目前已经有39%的用户在使用数据湖,34%的用户考虑在1年内使用数据湖。随着对象存储等云原生存储技术的成熟,一开始大家会先把结构化、半结构化、图片、视频等数据存储在对象存储中。当需要对这些数据进行分析时,会选择比如Hadoop或者阿里云的云原生数据湖分析服务DLA进行数据处理。对象存储相比部署HDFS在分析性能上面有一定的劣势,目前业界做了广泛的探索和落地。
一、基于对象存储分析面临的挑战
1、什么是数据湖
Wikipedia上说数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件,包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如email、文档、PDF、图像、音频、视频)。
从上面可以总结出数据湖具有以下特性:
- 数据来源:原始数据、转换数据
- 数据类型:结构化数据、半结构化数据、非结构化数据、二进制
- 数据湖存储:可扩展的海量数据存储服务
2、数据湖分析方案架构
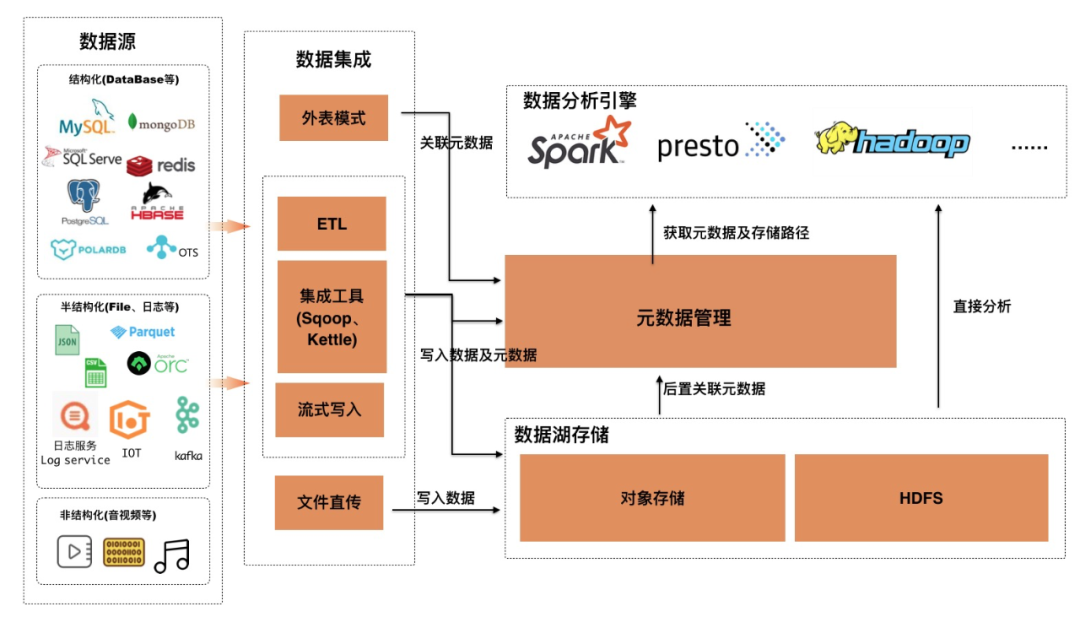
主要包括五个模块:
- 数据源:原始数据存储模块,包括结构化数据(Database等)、半结构化(File、日志等)、非结构化(音视频等);
- 数据集成:为了将数据统一到数据湖存储及管理,目前数据集成主要分为三种形态外表关联、ETL、异步元数据构建;
- 数据湖存储:目前业界数据湖存储包括对象存储以及自建HDFS。随着云原生的演进,对象存储在扩展性、成本、免运维有大量的优化,目前客户更多的选择云原生对象存储作为数据湖存储底座,而不是自建HDFS。
- 元数据管理:元数据管理,作为连接数据集成、存储和分析引擎的总线;
- 数据分析引擎:目前有丰富的分析引擎,比如Spark、Hadoop、Presto等。
3、面向对象存储分析面临的挑战
对象存储相比HDFS为了保证高扩展性,在元数据管理方面选择的是扁平的方式;元数据管理没有维护目录结构,因此可以做到元数据服务的水平扩展,而不像HDFS的NameNode会有单点瓶颈。同时对象存储相比HDFS可以做到免运维,按需进行存储和读取,构建完全的存储计算分离架构。但是面向分析与计算也带来了一些问题:
- List慢:对象存储按照目录/进行list相比HDFS怎么慢这么多?
- 请求次数过多:分析计算的时候怎么对象存储的请求次数费用比计算费用还要高?
- Rename慢:Spark、Hadoop分析写入数据怎么一直卡在commit阶段?
- 读取慢:1TB数据的分析,相比自建的HDFS集群居然要慢这么多!
- ......
4、业界面向对象存储分析优化现状
上面这些是大家基于对象存储构建数据湖分析方案遇到的典型问题。解决这些问题需要理解对象存储相比传统HDFS的架构区别进行针对性的优化。目前业界做了大量的探索和实践:
- JuiceFS:维护独立的元数据服务,使用对象存储作为存储介质。通过独立元数据服务来提供高效的文件管理语义,比如list、rename等。但是需要部署额外服务,所有的分析读取对象存储依赖该服务;
- Hadoop:由于Hadoop、Spark写入数据使用的是基于OutputCommitter两阶段提交协议,在OutputCommitter V1版本在commitTask以及commitJob会进行两次rename。在对象存储上面进行rename会进行对象的拷贝,成本很高。因此提出了OutputCommitter V2,该算法只用做一次rename,但是在commitjob过程中断会产生脏数据;
- Alluxio:通过部署独立的Cache服务,将远程的对象存储文件Cache到本地,分析计算本地读取数据加速;
- HUDI:当前出现的HUDI、Delta Lake、Iceberg通过metadata的方式将dataset的文件元信息独立存储来规避list操作 ,同时提供和传统数据库类似的ACID以及读写隔离性;
- 阿里云云原生数据湖分析服务DLA:DLA服务在读写对象存储OSS上面做了大量的优化,包括Rename优化、InputStream优化、Data Cache等。
二、DLA面向对象存储OSS的架构优化
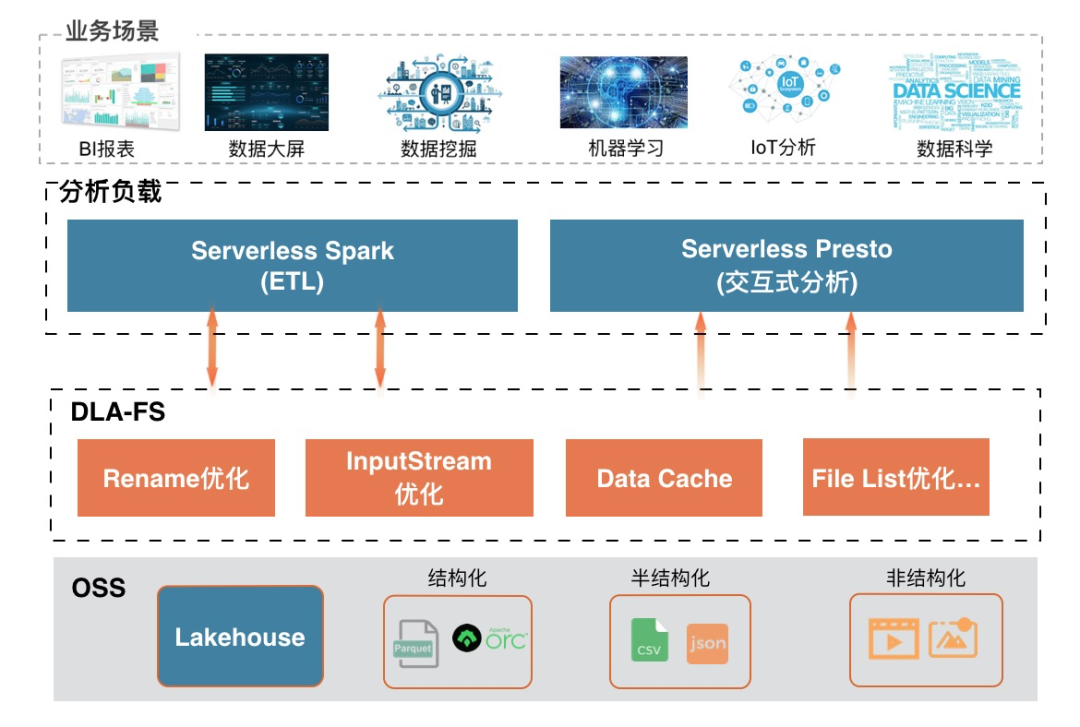
由于对象存储面向分析场景具有上面的问题,DLA构建了统一的DLA FS层来解决对象存储元信息访问、Rename、读取慢等问题。DLA FS同时支持DLA的Serverless Spark进行ETL读写、DLA Serverless Presto数据交互式查询、Lakehouse入湖建仓数据的高效读取等。面向对象存储OSS的架构优化整体分为四层:
- 数据湖存储OSS:存储结构化、半结构化、非结构化,以及通过DLA Lakehouse入湖建仓的HUDI格式;
- DLA FS:统一解决面向对象存储OSS的分析优化问题,包括Rename优化、Read Buffer、Data Cache、File List优化等;
- 分析负载:DLA Serverless Spark主要读取OSS中的数据ETL后再写回OSS,Serverless Presto主要对OSS上面建仓的数据进行交互式查询;
- 业务场景:基于DLA的双引擎Spark和Presto可以支持多种模式的业务场景。
三、DLA FS面向对象存储OSS优化技术解析
下面主要介绍DLA FS面向对象存储OSS的优化技术:
1、Rename优化
在Hadoop生态中使用OutputCommitter接口来保证写入过程的数据一致性,它的原理类似于二阶段提交协议。
开源Hadoop提供了Hadoop FileSystem的实现来读写OSS文件,它默认使用的OutputCommitter的实现是FileOutputCommitter。为了数据一致性,不让用户看到中间结果,在执行task时先把结果输出到一个临时工作目录,所有task都确认输出完成时,再由driver统一将临时工作目录rename到生产数据路径中去。如下图:
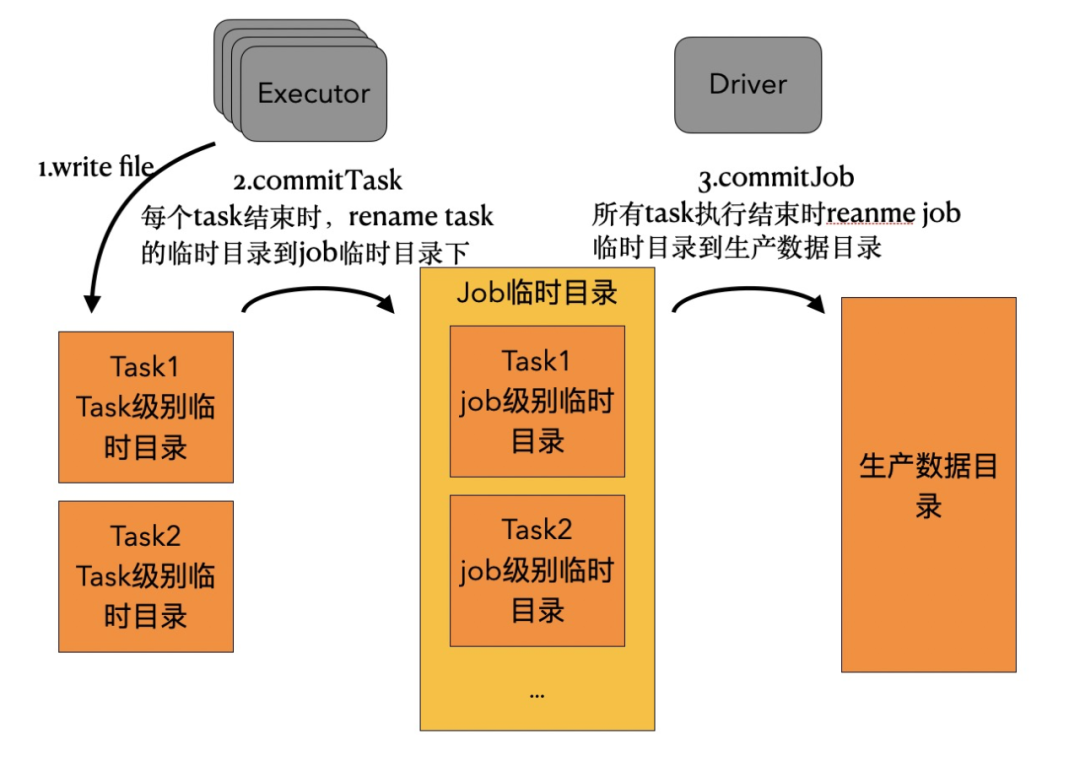
由于OSS相比HDFS它的Rename操作十分昂贵,是copy&delete操作,而HDFS则是NameNode上的一个元数据操作。在DLA的分析引擎继续使用开源Hadoop的FileOutputCommitter性能很差,为了解决这个问题,我们决定在DLA FS中引入OSS Multipart Upload特性来优化写入性能。
3.1 DLA FS支持Multipart Upload模式写入OSS对象
阿里云OSS支持Multipart Upload功能,原理是把一个文件分割成多个数据片并发上传,上传完成后,让用户自己选择一个时机调用Multipart Upload的完成接口,将这些数据片合并成原来的文件,以此来提高文件写入OSS的吞吐。由于Multipart Upload可以控制文件对用户可见的时机,所以我们可以利用它代替rename操作来优化DLA FS在OutputCommitter场景写OSS时的性能。
基于Multipart Upload实现的OutputCommitter,整个算法流程如下图:
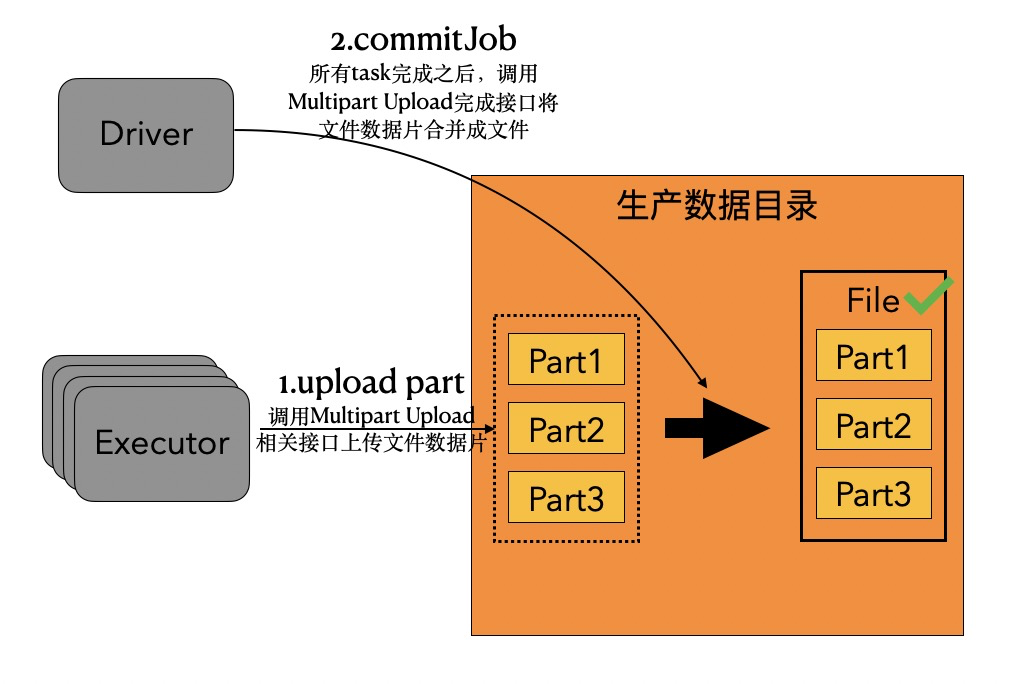
利用OSS Multipart Upload,有以下几个好处:
- 写入文件不需要多次拷贝。可以看到,本来昂贵的rename操作已经不需要了,写入文件不需要copy&delete。另外相比于rename,OSS 的completeMultipartUpload接口是一个非常轻量的操作。
- 出现数据不一致的几率更小。虽然如果一次要写入多个文件,此时进行completeMultipartUpload仍然不是原子性操作,但是相比于原先的rename会copy数据,他的时间窗口会缩短很多,出现数据不一致的几率会小很多,可以满足绝大部分场景。
- rename中的文件元信息相关操作不再需要。经过我们的统计,算法1中一个文件的元数据操作可以从13次下降到6次,算法2则可以从8次下降到4次。
OSS Multipart Upload中控制用户可见性的接口是CompleteMultipartUpload和abortMultipartUpload,这种接口的语义类似于commit/abort。Hadoop FileSystem标准接口没有提供commit/abort这样的语义。
为了解决这个问题,我们在DLA FS中引入Semi-Transaction层。
3.2 DLA FS引入Semi-Transaction层
前面有提到过,OutputCommitter类似于一个二阶段提交协议,因此我们可以把这个过程抽象为一个分布式事务。可以理解为Driver开启一个全局事务,各个Executor开启各自的本地事务,当Driver收到所有本地事务完成的信息之后,会提交这个全局事务。
基于这个抽象,我们引入了一个Semi-Transaction层(我们没有实现所有的事务语义),其中定义了Transaction等接口。在这个抽象之下,我们把适配OSS Multipart Upload特性的一致性保证机制封装进去。另外我们还实现了OSSTransactionalOutputCommitter,它实现了OutputCommitter接口,上层的计算引擎比如Spark通过它和我们DLA FS的Semi-Transaction层交互,结构如下图:
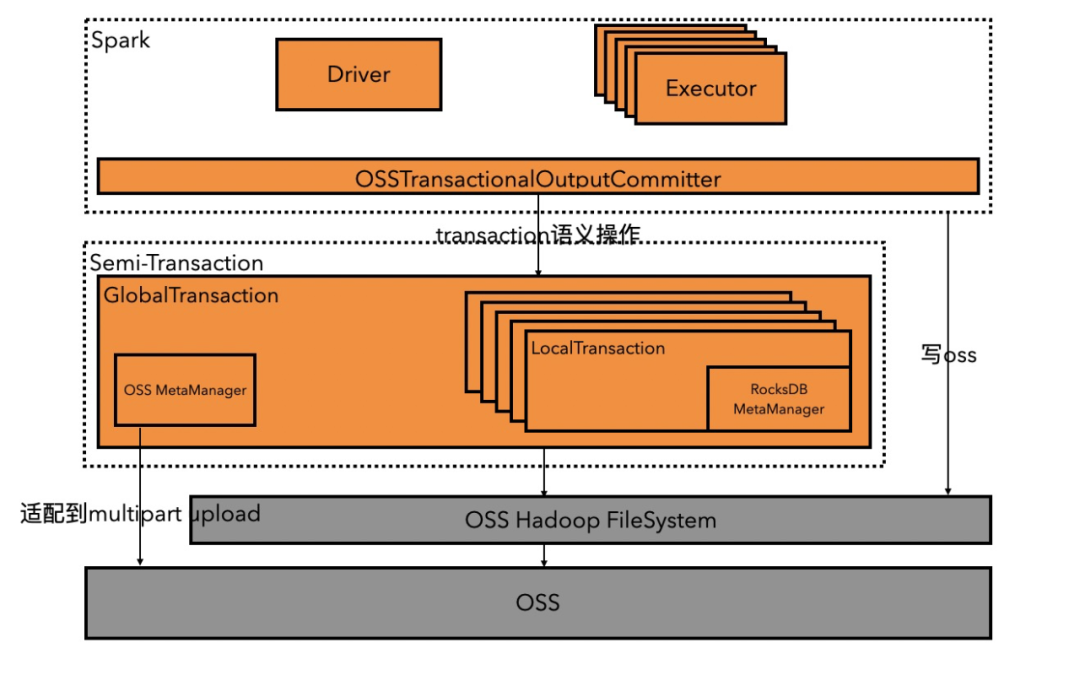
下面以DLA Serverless Spark的使用来说明DLA FS的OSSTransactionalOutputCommitter的大体流程:
- setupJob。Driver开启一个GlobalTransaction,GlobalTransaction在初始化的时候会在OSS上新建一个隐藏的属于这个GlobalTransaction的工作目录,用来存放本job的文件元数据。
- setupTask。Executor使用Driver序列化过来的GlobalTransaction生成LocalTransaction。并监听文件的写入完成状态。
- Executor写文件。文件的元数据信息会被LocalTransaction监听到,并储存到本地的RocksDB里面,OSS远程调用比较耗时,我们把元数据存储到本地RocksDB上等到后续一次提交能够减少远程调用耗时。
- commitTask。当Executor调用LocalTransaction commit操作时,LocalTransaction会上传这个Task它所相关的元数据到OSS对应的工作目录中去,不再监听文件完成状态。
- commitJob。Driver会调用GlobalTransaction的commit操作,全局事务会读取工作目录中的所有元数据中的待提交文件列表,调用OSS completeMultipartUpload接口,让所有文件对用户可见。
引入DLA FS的Semi-Transaction,有两个好处:
- 它不对任何计算引擎的接口有依赖,因此后面可以比较方便的移植到另外的一个计算引擎,通过适配可以将它所提供的实现给Presto或者其它计算引擎使用。
- 可以在Transaction的语义下添加更多的实现。例如对于分区合并的这种场景,可以加入MVCC的特性,在合并数据的同时不影响线上对数据的使用。
2、InputStream优化
用户反馈OSS请求费用高,甚至超过了DLA费用(OSS请求费用=请求次数×每万次请求的单价÷10000)。调查发现,是因为开源的OSSFileSystem在读取数据的过程中,会按照512KB为一个单位进行预读操作。例如,用户如果顺序读一个1MB的文件,会产生两个对OSS的调用:第一个请求读前512KB,第二个请求读后面的512KB。这样的实现就会造成读大文件时请求次数比较多,另外由于预读的数据是缓存在内存里面的,如果同时读取的文件比较多,也会给内存造成一些压力。
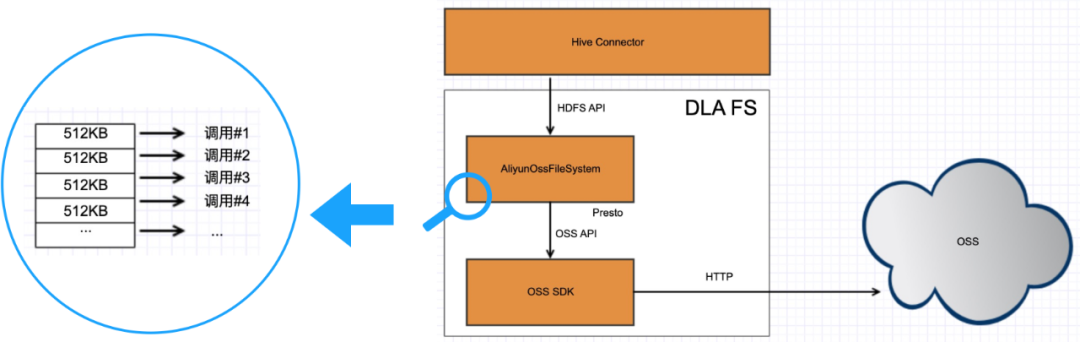
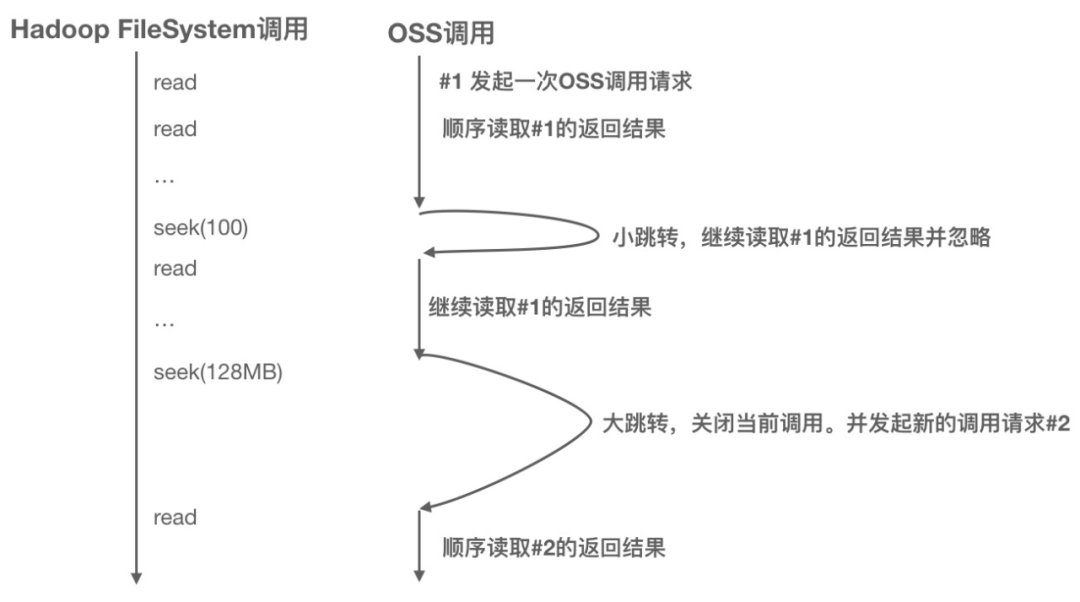
因此,在DLA FS的实现中,我们去掉了预读的操作,用户调用hadoop的read时,底层会向OSS请求读取从当前位置到文件结尾整个范围的数据,然后从OSS返回的流中读取用户需要的数据并返回。这样如果用户是顺序读取,下一个read调用就自然从同一个流中读取数据,不需要发起新的调用,即使顺序读一个很大的文件也只需要一次对OSS的调用就可以完成。
另外,对于小的跳转(seek)操作,DLA FS的实现是从流中读取出要跳过的数据并丢弃,这样也不需要产生新的调用,只有大的跳转才会关闭当前的流并且产生一个新的调用(这是因为大的跳转读取-丢弃会导致seek的延时变大)。这样的实现保证了DLA FS的优化在ORC/Parquet等文件格式上面也会有减少调用次数的效果。
3、Data Cache加速
基于对象存储OSS的存储计算分离的架构,通过网络从远端存储读取数据仍然是一个代价较大的操作,往往会带来性能的损耗。云原生数据湖分析DLA FS中引入了本地缓存机制,将热数据缓存在本地磁盘,拉近数据和计算的距离,减少从远端读取数据带来的延时和IO限制,实现更小的查询延时和更高的吞吐。
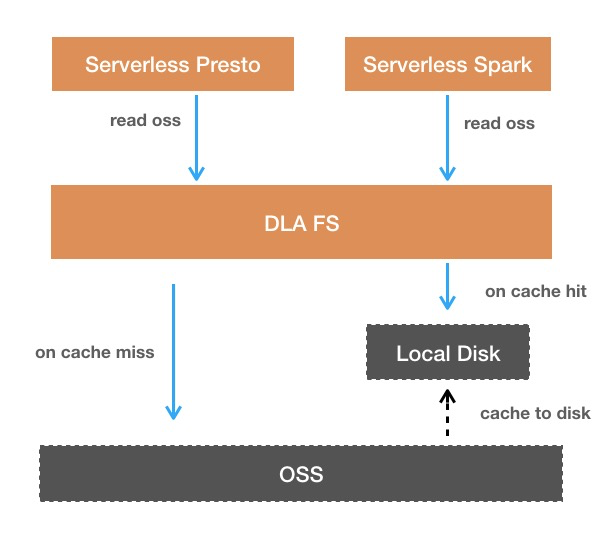
3.1 Local Cache架构
我们把缓存的处理逻辑封装在DLA FS中。如果要读取的数据存在于缓存中,会直接从本地缓存返回,不需要从OSS拉取数据。如果数据不在缓存中,会直接从OSS读取同时异步缓存到本地磁盘。
3.2 Data Cache命中率提高策略
这里以DLA Serverless Presto来说明如何提高DLA FS的local Cache的命中率提高。Presto默认的split提交策略是NO_PREFERENCE,在这种策略下面,主要考虑的因素是worker的负载,因此某个split会被分到哪个worker上面很大程度上是随机的。在DLA Presto中,我们使用SOFT_AFFINITY提交策略。在提交Hive的split时,会通过计算split的hash值,尽可能将同一个split提交到同一个worker上面,从而提高Cache的命中率。
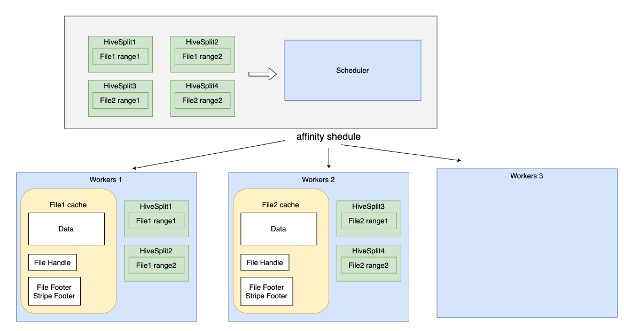
使用_SOFT_AFFINITY_策略时,split的提交策略是这样的:
- 通过split的hash值确定split的首选worker和备选worker。
- 如果首选worker空闲,则提交到首选worker。
- 如果首选worker繁忙,则提交到备选worker。
- 如果备选worker也繁忙,则提交到最不繁忙的worker。
四、DLA FS带来的价值
1、Rename优化在ETL写入场景的效果
客户在使用DLA过程中,通常使用DLA Serverless Spark做大规模数据的ETL。我们用TPC-H 100G数据集中的orders表进行写入测试,新建一个以o_ordermonth字段为分区的orders_test表。在Spark中执行sql:"insert overwrite table `tpc_h_test`.`orders_test` select * from `tpc_h_test`.`orders`"。使用同样的资源配置,使用的Spark版本一个为开源Spark,另外一个为DLA Serverless Spark,将它们的结果进行对比。
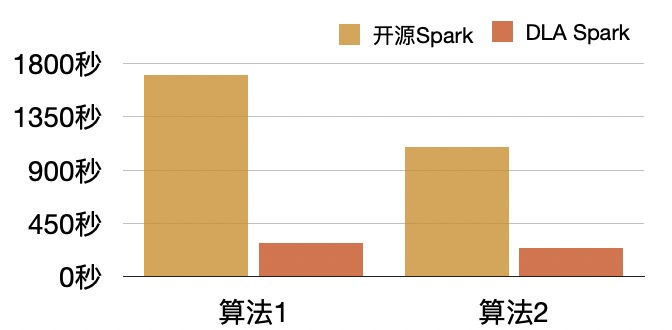
从图中可以得出:
- 这次优化对算法1和算法2都有比较大的提升。
- 算法1和算法2开启这个特性以后都会得到优化,但是算法1更明显。这是由于算法1需要进行两次rename,并且有一次rename是在driver上单点进行的;算法2是各executor进行分布式rename操作且只要进行一次。
- 在当前这个数据量下,算法1和算法2在开启这个特性之后,差距没有那么明显。两种方式都不需要进行rename操作,只不过是completeMultipart是否是在driver上单点执行(算法2我们的改造是completeMultipartUpload在commitTask的时候执行),大数据量可能仍会有比较大的影响。
2、InputStream优化在交互式场景的效果
DLA客户会使用DLA的Serverless Presto对多种格式进行分析,比如Text、ORC、Parquet等。下面对比基于DLA FS以及社区OSSFS在1GB Text及ORC格式的访问请求次数。
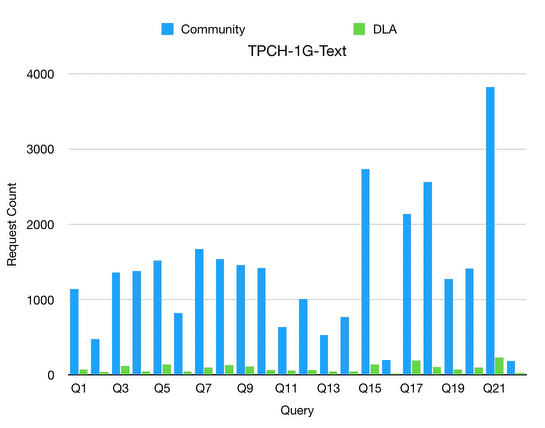
1GB Text文件分析的请求次数对比
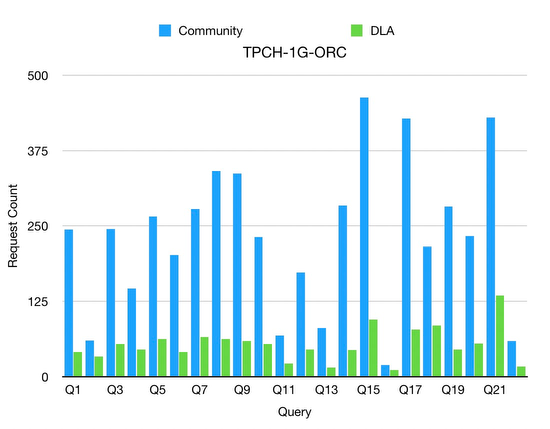
- Text类调用次数降低为开源实现的1/10左右;
- ORC格式调用次数降低为开源实现1/3左右;
- 平均来看可以节省OSS调用费用60%到90%;
3、Data Cache在交互式场景的效果
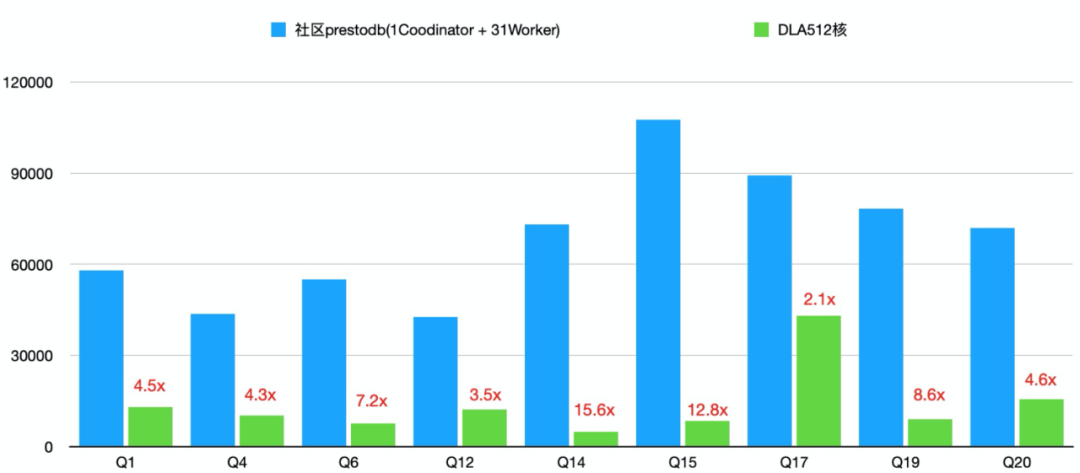
我们针对社区版本prestodb和DLA做了性能对比测试。社区版本我们选择了prestodb 0.228版本,并通过复制jar包以及修改配置的方式增加对oss数据源的支持。我们对DLA Presto CU版512核2048GB通社区版本集群进行了对比。
测试的查询我们选择TPC-H 1TB数据测试集。由于TPC-H的大部分查询并不是IO密集型的,所以我们只从中挑选出符合如下两个标准的查询来做比较:
- 查询中包含了对最大的表lineitem的扫描,这样扫描的数据量足够大,IO有可能成为瓶颈。
- 查询中不涉及多个表的join操作,这样就不会有大数据量参与计算,因而计算不会先于IO而成为瓶颈。
按照这两个标准,我们选择了对lineitem单个表进行查询的Q1和Q6,以及lineitem和另一个表进行join操作的Q4、Q12、Q14、Q15、Q17、Q19和Q20。
可以看到Cache加速能管理在这几个query都有明显的效果。
五、云原生数据湖最佳实践
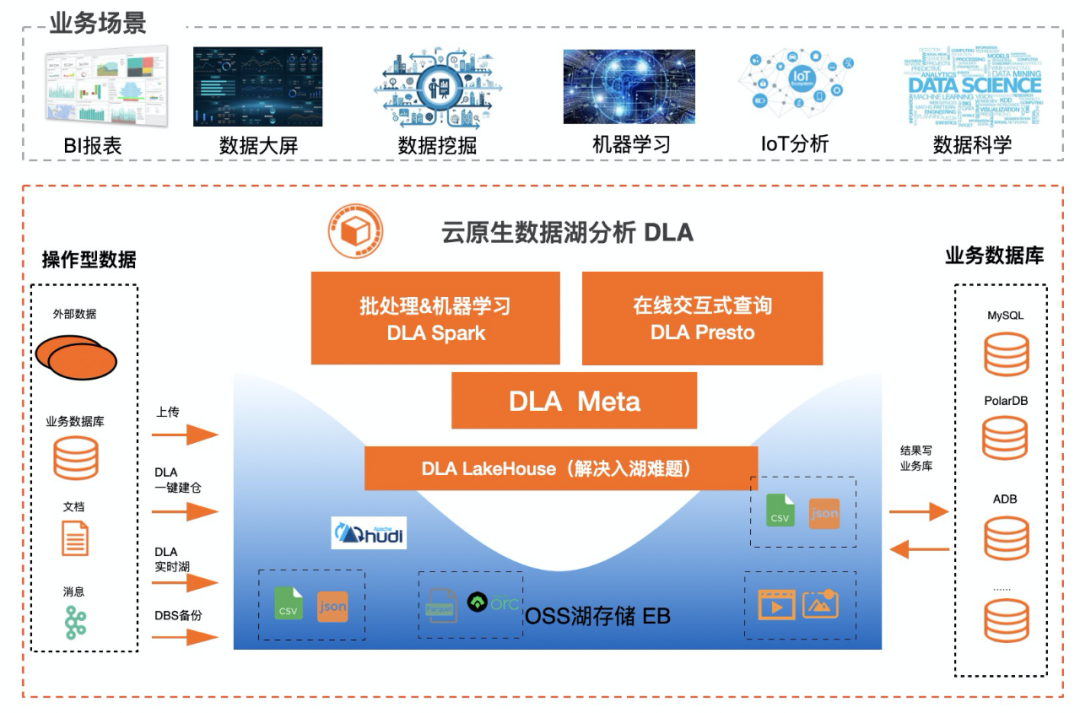
最佳实践,以DLA为例子。DLA致力于帮助客户构建低成本、简单易用、弹性的数据平台,比传统Hadoop至少节约50%的成本。其中DLA Meta支持云上15+种数据数据源(OSS、HDFS、DB、DW)的统一视图,引入多租户、元数据发现,追求边际成本为0,免费提供使用。DLA Lakehouse基于Apache Hudi实现,主要目标是提供高效的湖仓,支持CDC及消息的增量写入,目前这块在加紧产品化中。DLA Serverless Presto是基于Apache PrestoDB研发的,主要是做联邦交互式查询与轻量级ETL。DLA支持Spark主要是为在湖上做大规模的ETL,并支持流计算、机器学习;比传统自建Spark有着300%的性价比提升,从ECS自建Spark或者Hive批处理迁移到DLA Spark可以节约50%的成本。基于DLA的一体化数据处理方案,可以支持BI报表、数据大屏、数据挖掘、机器学习、IOT分析、数据科学等多种业务场景。
原文链接
本文为阿里云原创内容,未经允许不得转载。
)
)

















