背景
微服务场景下,全链路灰度作为一种低成本的新功能验证方式,得到了越来越广泛的应用。除了微服务实例和流量的灰度,微服务应用中的配置项也应该具备相应的灰度能力,以应对灰度应用对特殊配置的诉求。
为什么需要配置标签推送
从全链路灰度谈起
在微服务场景中,应用的灰度发布迎来了新的挑战。不同于单体架构中将应用整体打包即可发布测试版本,微服务应用往往由多个服务组合而成。这些服务通常由不同的团队负责,独立进行开发。一个新功能通常只涉及到部分服务,在测试新特性时,我们只需要对这部分服务进行发布即可。为了让微服务应用正常运行,还需要设计一种方案,让灰度流量也能正常经过其他不需要发布的服务。
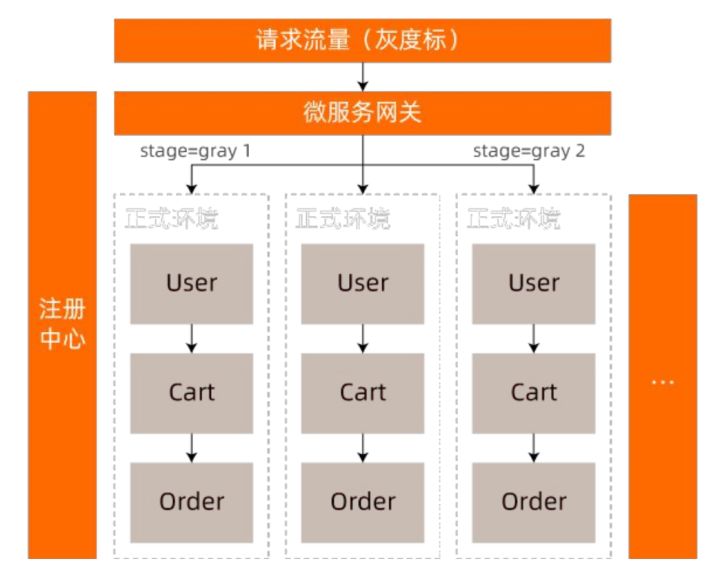
这一功能通常有物理环境隔离和逻辑环境隔离两种解决方案。前者需要为每套灰度环境都搭建一套网络隔离、资源独立的环境,为了应用能正常运行,还需要在环境中为未被灰度到的服务、各种中间件等做冗余发布,如图所示:

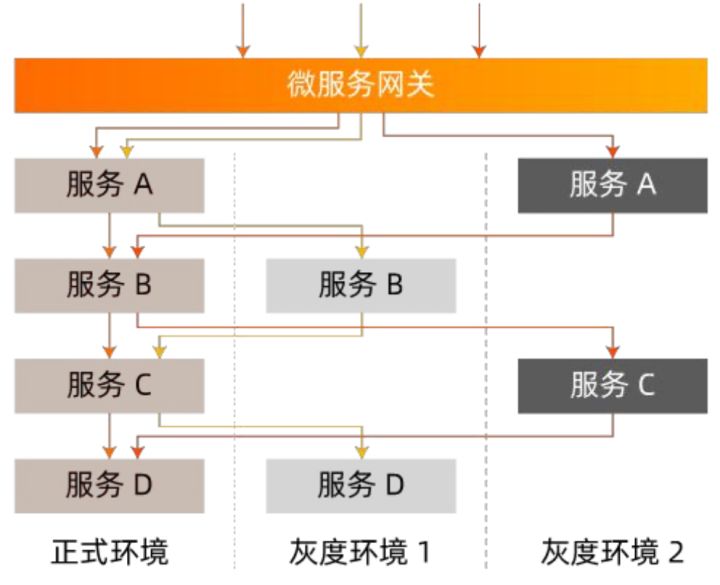
物理环境隔离这一方案存在着大量的机器资源浪费。因此业界普遍采用后者,即逻辑环境隔离的方式做为全链路灰度的解决方案。只需部署灰度服务,通过调用链路上的流量控制使得灰度流量能在灰度环境和正式环境间流转,实现灰度微服务应用的正常运行,帮助业务方进行新功能验证。如图所示:
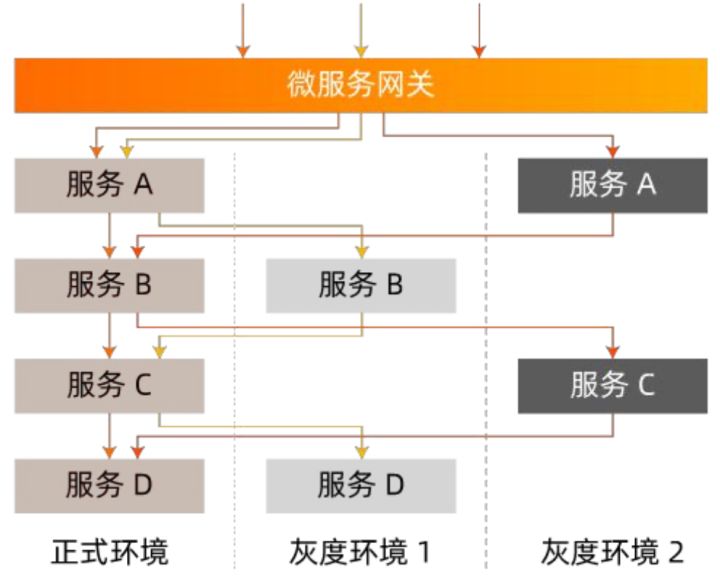
配置灰度的应用场景
在许多业务场景中都可能涉及到配置灰度能力的应用,下面是几个典型场景。
- 金丝雀发布
金丝雀发布已经在业界广泛落地,是新版本发布的常用手段。金丝雀发布会对流量进行比例分隔,一开始为新版本的实例分配较小比例的流量,经过一段时间的运行,确认新版本运行正常后再逐步提高所分配流量的比例,直到最终全量切流。通过这种方式做发布可以在新版本出现问题时控制影响面,提高系统的稳定性。
金丝雀发布通常通过流量染色和机器打标来实现。新版本的机器被打上金丝雀版本标记,同时让部分流量携带上金丝雀版本标记,最终还是演变成全链路灰度的解决方案。金丝雀版本的应用中的配置项可能需要使用和旧版本中不同的配置值,这就需要配置灰度的能力。
- 新功能上线
在改动涉及较大的功能上线时,往往会通过逐步放量的方式来验证功能的稳定性。一种典型的放量方式就是白名单,即配置在白名单中的用户/设备可以使用新功能,未在白名单中的用户仍然使用旧版本。在线上运行一段时间后收集白名单用户的反馈,对功能做优化的同时逐步增加白名单中的用户/设备数,等功能到达最终的稳定状态后再全量发布。
来自于白名单中的用户/设备会被打上特殊的标记,被路由到灰度环境中。如果新功能中的配置需要使用不同于旧版本中的配置值,就需要同步用到配置灰度。
- 数据库迁移
数据库迁移也是业务发展中的常见问题。随着业务的快速增长,原有的数据库可能在容量/性能上都不再能满足未来的业务需要,这时就需要做数据库迁移。为了保证迁移过程的稳定性,迁移通常是渐进式的,这个过程中会存在部分流量写新库,部分流量写老库,待迁移完全完成后再将所有流量切到新库上。迁移过程中我们可以通过流量染色配合配置灰度来实现对不同数据库的操作。
问题及解决方案
微服务应用通常会引入配置中心做配置管理,其提供动态的配置推送能力使得应用无需重启就可以动态地改变运行逻辑。然而配置中心的管理维度仅仅是配置项本身,并不能感知到前来获取配置的服务实例的环境信息,即无法区分请求配置的是正式环境的实例还是灰度环境的实例。在这种背景下,如果某项配置在正式环境和灰度环境中需要使用不同值,它们在配置中心中必须作为不同的配置项,我们可能需要写出这样的代码:
...
if (env == "gray") {cfg = getConfig('cfg1');
} else {cfg = getConfig('cfg2');
}
...假如有多个配置项在灰度环境中存在不同的配置值,这样的代码还需要重复多次。更极端的场景下,如果在测试的灰度环境还有多套,每套环境中的配置值都不同,负责获取配置项的代码还会更复杂。此外,一套灰度环境中往往存在多个服务,每个服务都需要独立维护一套类似的代码。最终的解决方案如图所示,同一配置项在不同环境中使用的配置值需要在用户应用中主动进行区分。
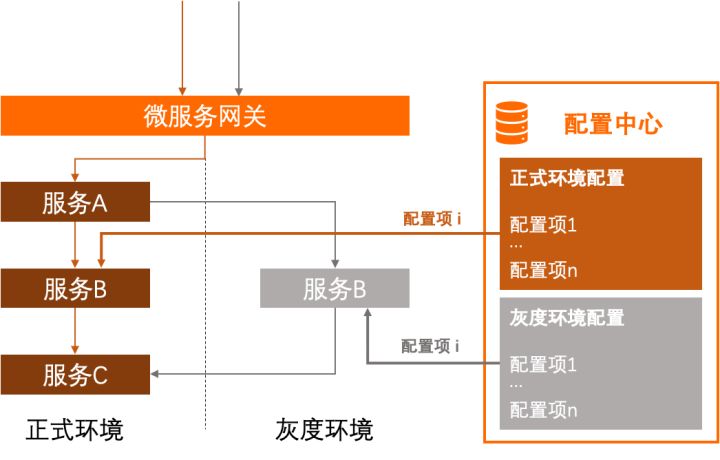
究其原因,还是来自于配置中心无法感知服务实例的环境信息,使得我们必须在代码中代替配置中心行使这一任务,从而导致了环境信息对业务代码产生了侵入。尽管我们可以通过对获取配置的代码做一些封装来降低业务代码的使用复杂度,但只要配置中心无法感知服务实例的环境信息这一事实存在,这种环境信息对业务代码的侵入性就无法避免。
功能介绍
MSE 新上线的配置标签推送功能将配置管理场景下的环境信息的感知下沉到平台侧,由 Agent 负责。用户只需接入 MSE,就可轻松在全链路灰度场景中使用配置推送能力,免去业务代码中繁琐的环境信息检测逻辑。如图所示:
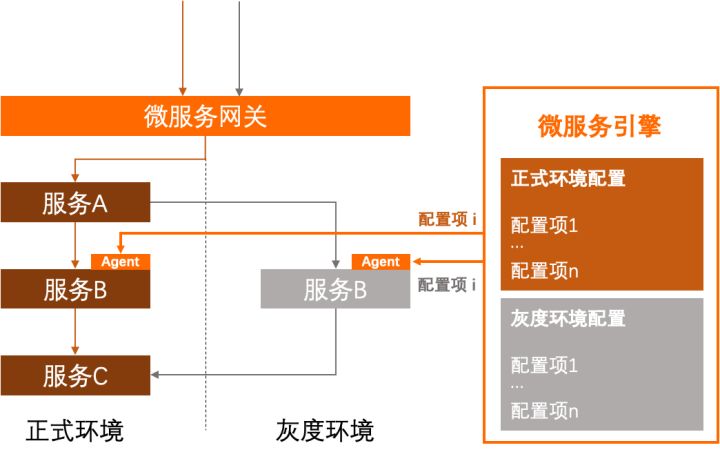
配置标签推送提供的功能包括:
- 标签维度的配置管理
在配置列表页中可以查看应用中的各种配置项。目前 MSE 支持对三类配置进行采集:
-
- 使用 SDK 提供的注解@Switch 标记的配置类
- 使用 Spring 的注解 @Value 标记的配置项
- 使用 SpringBoot 的注解 @ConfigurationProperties 标记的配置类
每个配置项下会展示所有服务实例的配置值,用户可以通过标签名直观地看到不同实例所处的灰度环境,还可以查看不同灰度环境下的配置值分布
- 标签维度的应用配置推送能力
通过“按标签推送”,用户可以便捷地为指定灰度环境中的所有服务实例推送持久化的新配置值。持久化意味着即使应用重启,针对该环境的配置项也不会丢失。
- 配置场景下的实例动态打标
除了在应用启动时通过 MSE 的打标方式为服务实例设置标签,用户可以在 MSE 控制台动态地为服务实例新增/删除标签,以适配不同灰度环境下的配置项管理。
- 围绕整个配置标签推送流程的溯源能力
MSE 为标签推送提供了全流程的溯源能力,包括实例标签变动记录,标签推送记录,帮助用户便捷地排查标签推送流程中的问题。
配置标签推送实践
接下来,我们通过实践来演示配置标签推送的使用流程,只需简单的三步即可完成。
- 准备工作
- 将应用接入 MSE 微服务治理
- 进入 MSE 控制台,选择地域
- 进入 治理中心 > 应用治理,进入刚刚接入的应用
- Step 1:新增标签
配置标签推送的第一步是为服务实例设置标签。服务实例的标签可以在启动时通过 -Dalicloud.service.tag 设置,同时也可以在 MSE 控制台动态设置。
接下来我们演示为服务实例动态打标的过程。选择 应用配置 > 标签列表,这里会展示当前应用下所有的服务实例。点击左上角的“新增标签”按钮,在弹出的节点打标窗口中我们可以选择一批服务实例进行打标。用户可以通过节点 IP 来筛选需要打标的实例。除了按节点 IP 筛选,MSE 提供了按主机名称筛选服务实例的能力。选中需要打标的机器后,输入标签的名称,点击“新增标签”即可完成机器打标。

- Step 2:按标签推送
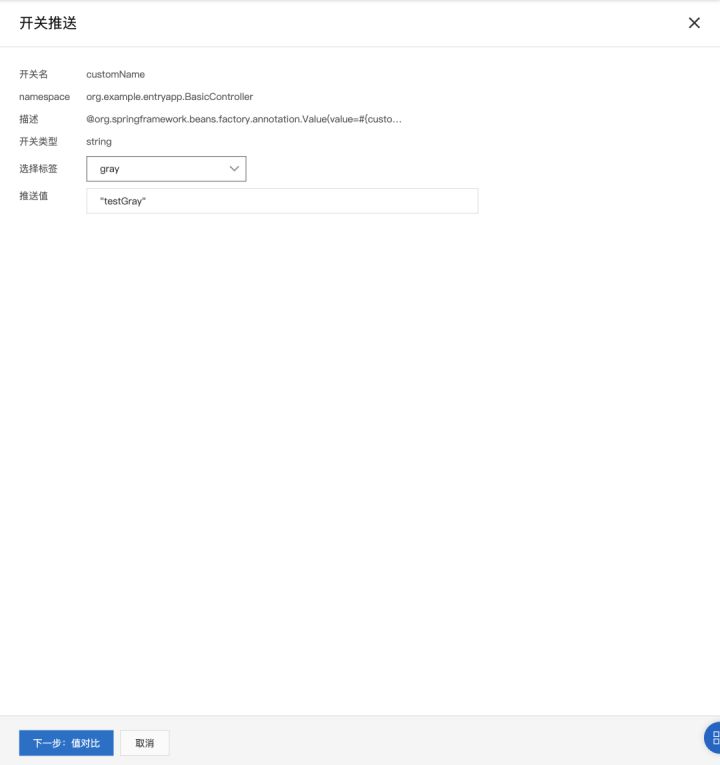
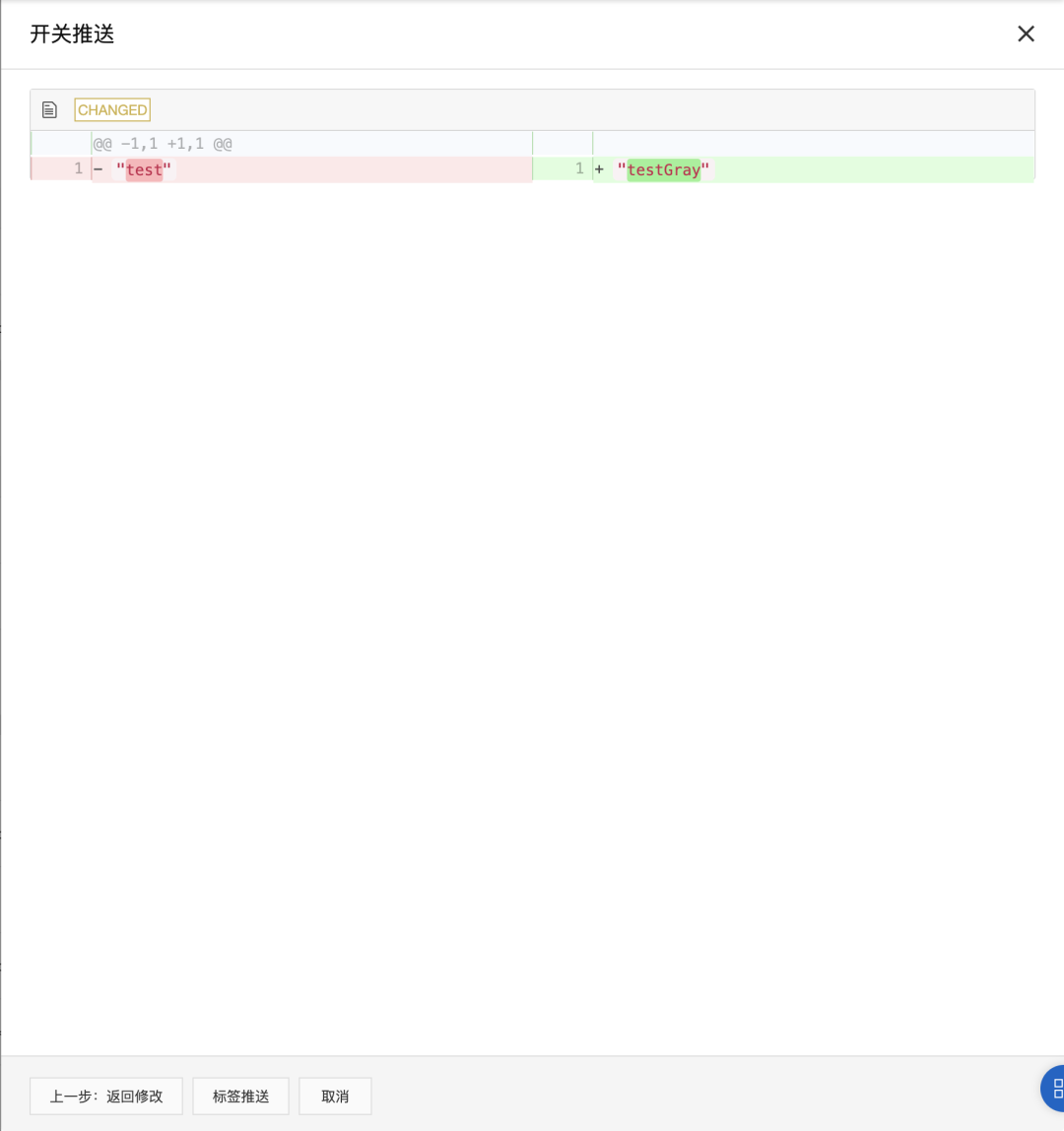
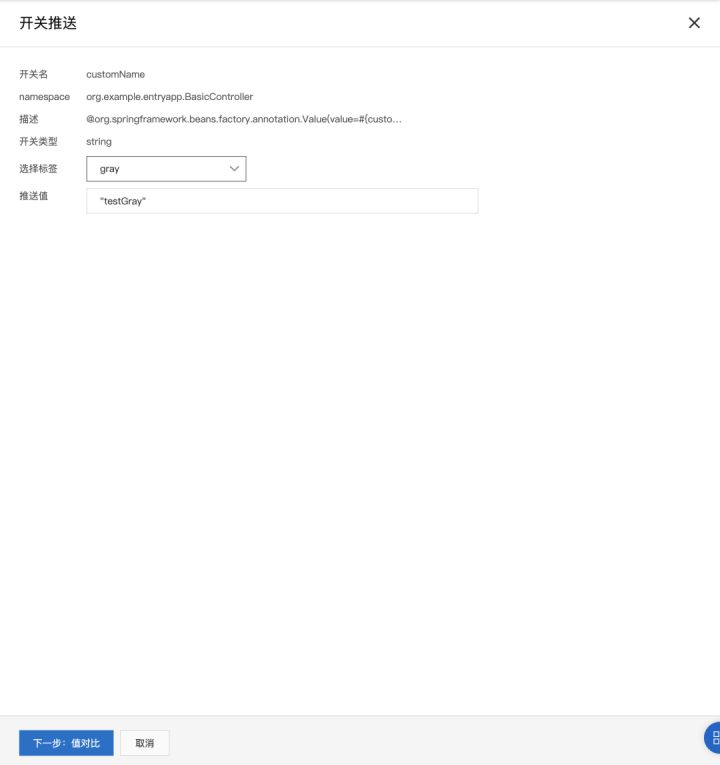
完成机器打标后,我们可以为指定的标签推送配置值。回到 应用配置 > 配置列表,选择“customName”配置项,点击“按标签推送”。在弹出的推送窗口中,我们选择需要推送的标签,并设置待推送的配置值,点击“下一步:值对比”,可以看到新老配置项的差异。之后点击“标签推送”,完成配置下发。
背景
微服务场景下,全链路灰度作为一种低成本的新功能验证方式,得到了越来越广泛的应用。除了微服务实例和流量的灰度,微服务应用中的配置项也应该具备相应的灰度能力,以应对灰度应用对特殊配置的诉求。
为什么需要配置标签推送
从全链路灰度谈起
在微服务场景中,应用的灰度发布迎来了新的挑战。不同于单体架构中将应用整体打包即可发布测试版本,微服务应用往往由多个服务组合而成。这些服务通常由不同的团队负责,独立进行开发。一个新功能通常只涉及到部分服务,在测试新特性时,我们只需要对这部分服务进行发布即可。为了让微服务应用正常运行,还需要设计一种方案,让灰度流量也能正常经过其他不需要发布的服务。
这一功能通常有物理环境隔离和逻辑环境隔离两种解决方案。前者需要为每套灰度环境都搭建一套网络隔离、资源独立的环境,为了应用能正常运行,还需要在环境中为未被灰度到的服务、各种中间件等做冗余发布,如图所示:
物理环境隔离这一方案存在着大量的机器资源浪费。因此业界普遍采用后者,即逻辑环境隔离的方式做为全链路灰度的解决方案。只需部署灰度服务,通过调用链路上的流量控制使得灰度流量能在灰度环境和正式环境间流转,实现灰度微服务应用的正常运行,帮助业务方进行新功能验证。如图所示:
配置灰度的应用场景
在许多业务场景中都可能涉及到配置灰度能力的应用,下面是几个典型场景。
- 金丝雀发布
金丝雀发布已经在业界广泛落地,是新版本发布的常用手段。金丝雀发布会对流量进行比例分隔,一开始为新版本的实例分配较小比例的流量,经过一段时间的运行,确认新版本运行正常后再逐步提高所分配流量的比例,直到最终全量切流。通过这种方式做发布可以在新版本出现问题时控制影响面,提高系统的稳定性。
金丝雀发布通常通过流量染色和机器打标来实现。新版本的机器被打上金丝雀版本标记,同时让部分流量携带上金丝雀版本标记,最终还是演变成全链路灰度的解决方案。金丝雀版本的应用中的配置项可能需要使用和旧版本中不同的配置值,这就需要配置灰度的能力。
- 新功能上线
在改动涉及较大的功能上线时,往往会通过逐步放量的方式来验证功能的稳定性。一种典型的放量方式就是白名单,即配置在白名单中的用户/设备可以使用新功能,未在白名单中的用户仍然使用旧版本。在线上运行一段时间后收集白名单用户的反馈,对功能做优化的同时逐步增加白名单中的用户/设备数,等功能到达最终的稳定状态后再全量发布。
来自于白名单中的用户/设备会被打上特殊的标记,被路由到灰度环境中。如果新功能中的配置需要使用不同于旧版本中的配置值,就需要同步用到配置灰度。
- 数据库迁移
数据库迁移也是业务发展中的常见问题。随着业务的快速增长,原有的数据库可能在容量/性能上都不再能满足未来的业务需要,这时就需要做数据库迁移。为了保证迁移过程的稳定性,迁移通常是渐进式的,这个过程中会存在部分流量写新库,部分流量写老库,待迁移完全完成后再将所有流量切到新库上。迁移过程中我们可以通过流量染色配合配置灰度来实现对不同数据库的操作。
问题及解决方案
微服务应用通常会引入配置中心做配置管理,其提供动态的配置推送能力使得应用无需重启就可以动态地改变运行逻辑。然而配置中心的管理维度仅仅是配置项本身,并不能感知到前来获取配置的服务实例的环境信息,即无法区分请求配置的是正式环境的实例还是灰度环境的实例。在这种背景下,如果某项配置在正式环境和灰度环境中需要使用不同值,它们在配置中心中必须作为不同的配置项,我们可能需要写出这样的代码:
...
if (env == "gray") {cfg = getConfig('cfg1');
} else {cfg = getConfig('cfg2');
}
...假如有多个配置项在灰度环境中存在不同的配置值,这样的代码还需要重复多次。更极端的场景下,如果在测试的灰度环境还有多套,每套环境中的配置值都不同,负责获取配置项的代码还会更复杂。此外,一套灰度环境中往往存在多个服务,每个服务都需要独立维护一套类似的代码。最终的解决方案如图所示,同一配置项在不同环境中使用的配置值需要在用户应用中主动进行区分。
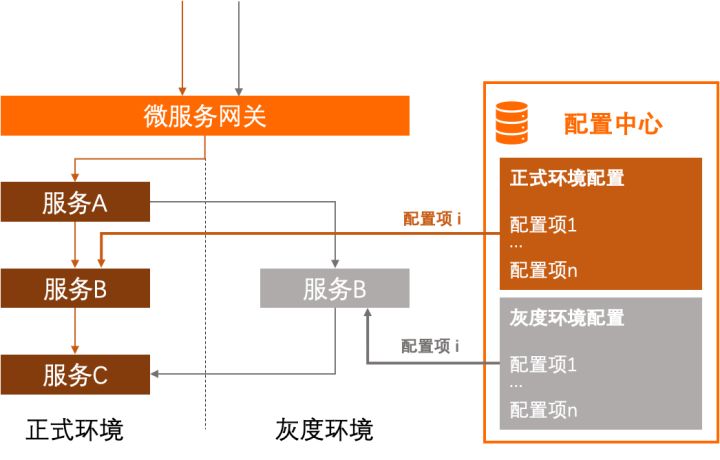
究其原因,还是来自于配置中心无法感知服务实例的环境信息,使得我们必须在代码中代替配置中心行使这一任务,从而导致了环境信息对业务代码产生了侵入。尽管我们可以通过对获取配置的代码做一些封装来降低业务代码的使用复杂度,但只要配置中心无法感知服务实例的环境信息这一事实存在,这种环境信息对业务代码的侵入性就无法避免。
功能介绍
MSE 新上线的配置标签推送功能将配置管理场景下的环境信息的感知下沉到平台侧,由 Agent 负责。用户只需接入 MSE,就可轻松在全链路灰度场景中使用配置推送能力,免去业务代码中繁琐的环境信息检测逻辑。如图所示:
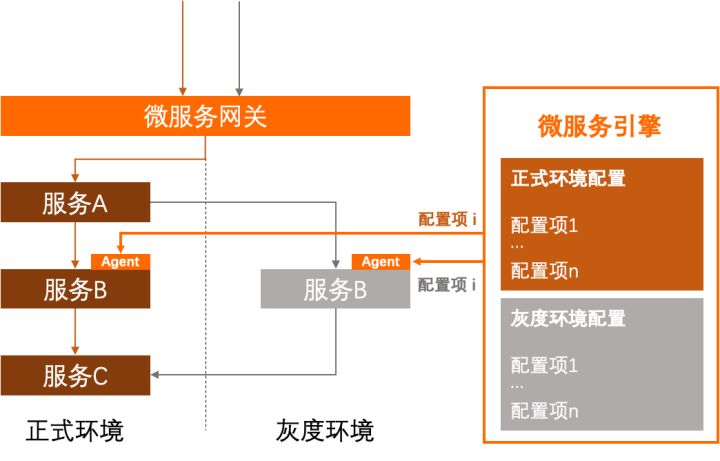
配置标签推送提供的功能包括:
- 标签维度的配置管理
在配置列表页中可以查看应用中的各种配置项。目前 MSE 支持对三类配置进行采集:
-
- 使用 SDK 提供的注解@Switch 标记的配置类
- 使用 Spring 的注解 @Value 标记的配置项
- 使用 SpringBoot 的注解 @ConfigurationProperties 标记的配置类
每个配置项下会展示所有服务实例的配置值,用户可以通过标签名直观地看到不同实例所处的灰度环境,还可以查看不同灰度环境下的配置值分布
- 标签维度的应用配置推送能力
通过“按标签推送”,用户可以便捷地为指定灰度环境中的所有服务实例推送持久化的新配置值。持久化意味着即使应用重启,针对该环境的配置项也不会丢失。
- 配置场景下的实例动态打标
除了在应用启动时通过 MSE 的打标方式为服务实例设置标签,用户可以在 MSE 控制台动态地为服务实例新增/删除标签,以适配不同灰度环境下的配置项管理。
- 围绕整个配置标签推送流程的溯源能力
MSE 为标签推送提供了全流程的溯源能力,包括实例标签变动记录,标签推送记录,帮助用户便捷地排查标签推送流程中的问题。
配置标签推送实践
接下来,我们通过实践来演示配置标签推送的使用流程,只需简单的三步即可完成。
- 准备工作
- 将应用接入 MSE 微服务治理
- 进入 MSE 控制台,选择地域
- 进入 治理中心 > 应用治理,进入刚刚接入的应用
- Step 1:新增标签
配置标签推送的第一步是为服务实例设置标签。服务实例的标签可以在启动时通过 -Dalicloud.service.tag 设置,同时也可以在 MSE 控制台动态设置。
接下来我们演示为服务实例动态打标的过程。选择 应用配置 > 标签列表,这里会展示当前应用下所有的服务实例。点击左上角的“新增标签”按钮,在弹出的节点打标窗口中我们可以选择一批服务实例进行打标。用户可以通过节点 IP 来筛选需要打标的实例。除了按节点 IP 筛选,MSE 提供了按主机名称筛选服务实例的能力。选中需要打标的机器后,输入标签的名称,点击“新增标签”即可完成机器打标。
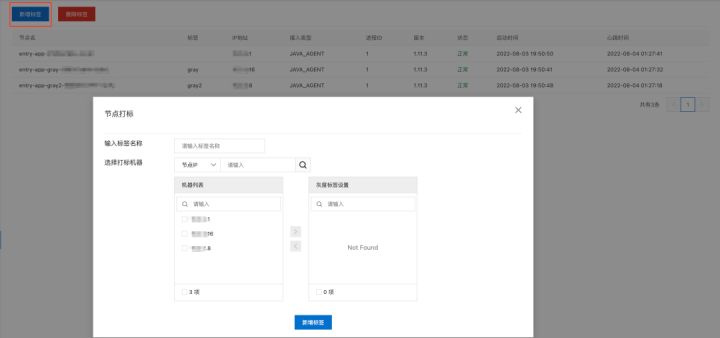
- Step 2:按标签推送
完成机器打标后,我们可以为指定的标签推送配置值。回到 应用配置 > 配置列表,选择“customName”配置项,点击“按标签推送”。在弹出的推送窗口中,我们选择需要推送的标签,并设置待推送的配置值,点击“下一步:值对比”,可以看到新老配置项的差异。之后点击“标签推送”,完成配置下发。
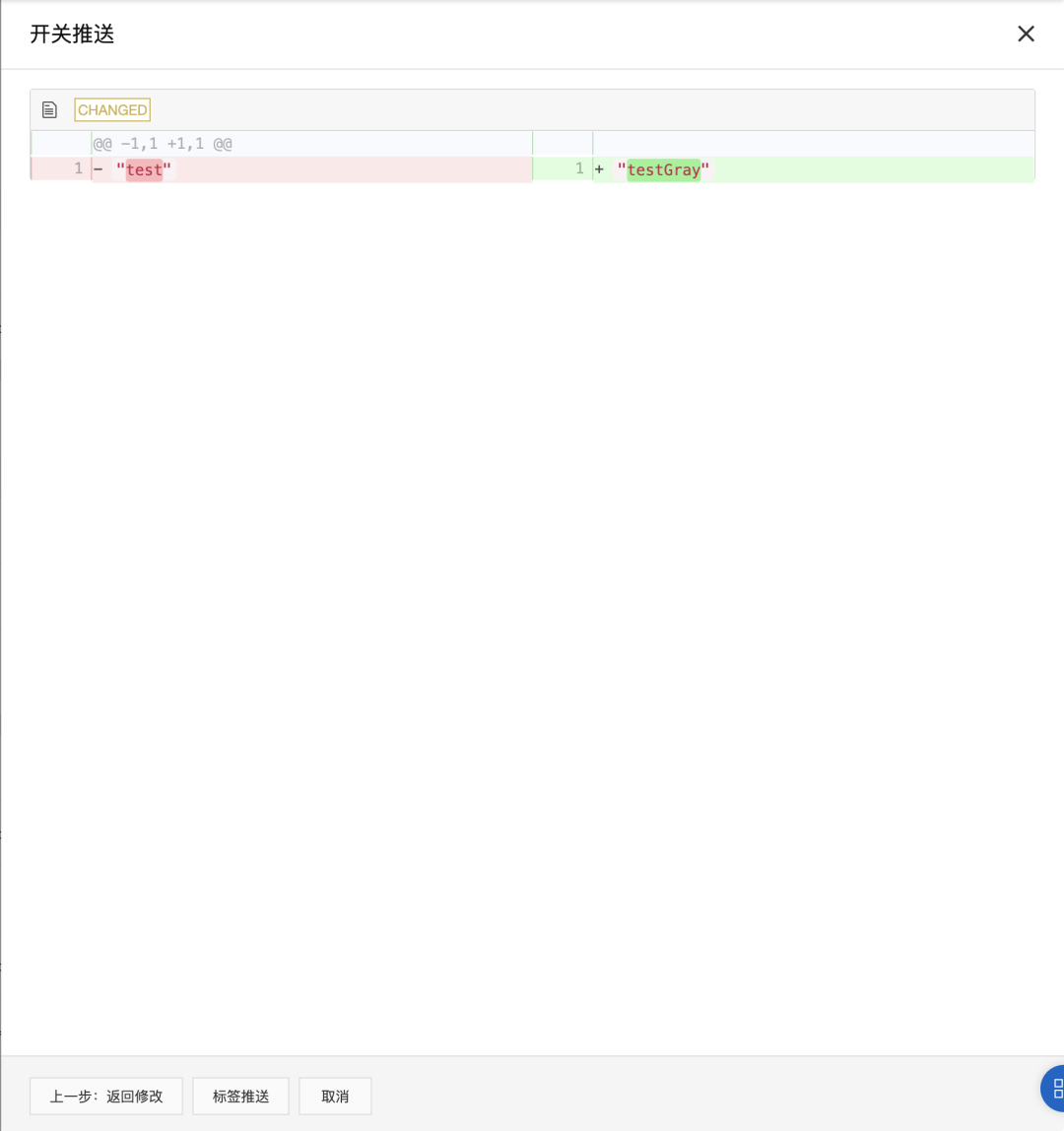
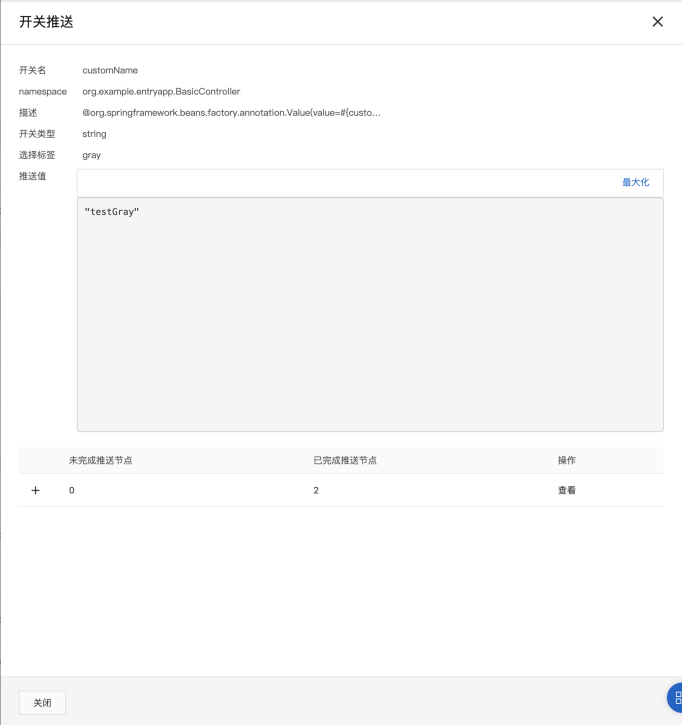
可以看到配置项已经被成功推送到了两个带有“gray”标签的机器实例上。
之后,我们对“gray2”标签也执行同样的操作,推送“testGray2”配置值。
针对标签的配置值推送都是持久化的。用户只需要在控制台上操作一次,之后指定标签的服务实例重启时 MSE 会通过 Agent 将持久化的配置值下发到应用。
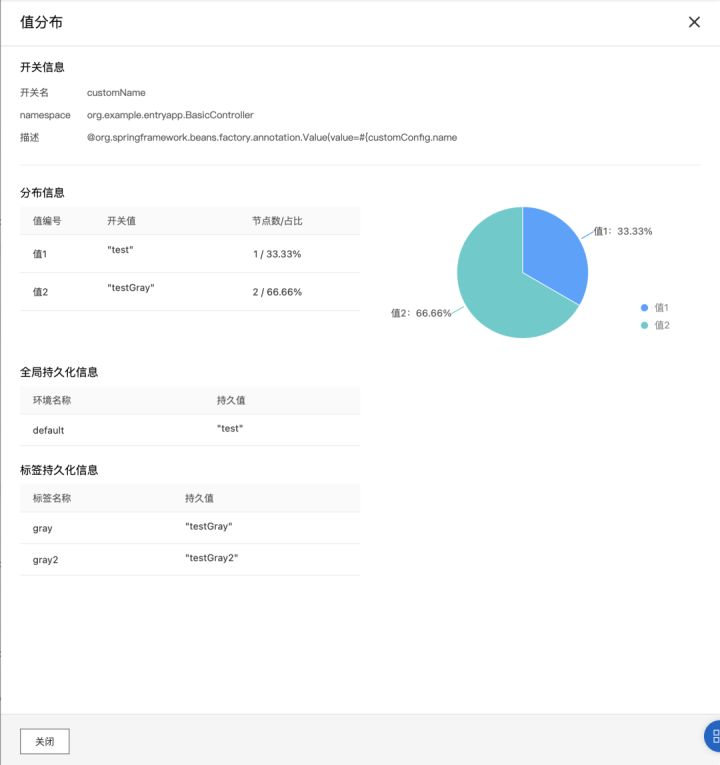
- Step 3:查看配置值分布
回到 应用配置 > 配置列表,选择“customName”配置项,我们可以看到刚刚为标签“gray”和“gray2”推送的两个配置值都已经生效。
点击“值分布”。在弹出的窗口中可以看到该配置项的配置值在所有机器实例上的分布,也能看到其在不同标签下的持久化值。
结束语
本文介绍了全链路灰度场景给配置管理带来的问题,介绍了 MSE 针对这一场景的解决方案,并通过实践的方式展示了配置标签推送的使用流程。后续,MSE 还会针对配置治理做更多的探索,帮助用户更好地解决微服务配置管理中的难题,提高微服务应用的稳定性。
作者:洵沐、流士
原文链接
本文为阿里云原创内容,未经允许不得转载。
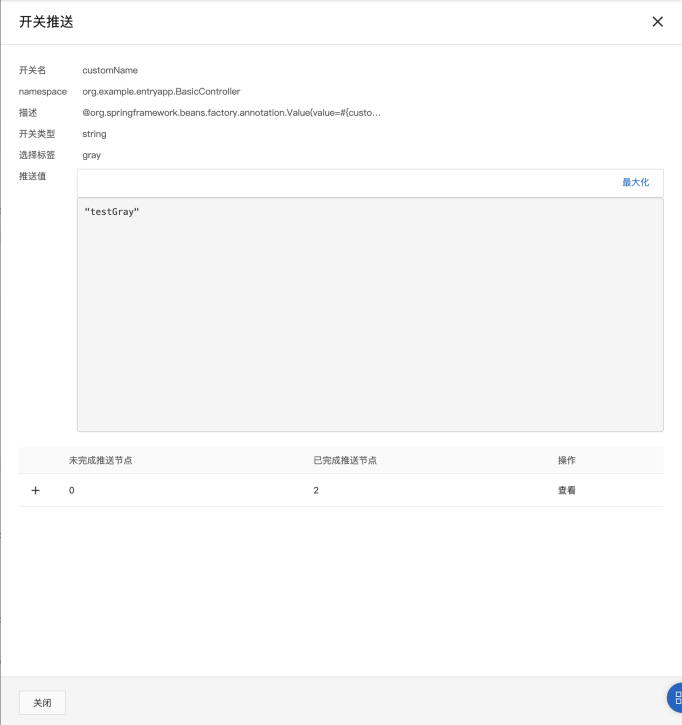
可以看到配置项已经被成功推送到了两个带有“gray”标签的机器实例上。
之后,我们对“gray2”标签也执行同样的操作,推送“testGray2”配置值。
针对标签的配置值推送都是持久化的。用户只需要在控制台上操作一次,之后指定标签的服务实例重启时 MSE 会通过 Agent 将持久化的配置值下发到应用。
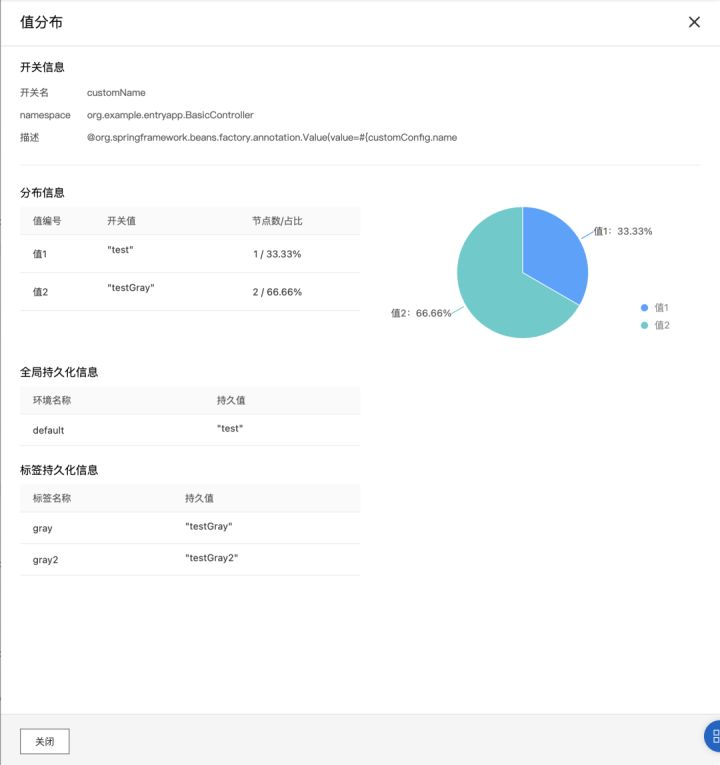
- Step 3:查看配置值分布
回到 应用配置 > 配置列表,选择“customName”配置项,我们可以看到刚刚为标签“gray”和“gray2”推送的两个配置值都已经生效。
点击“值分布”。在弹出的窗口中可以看到该配置项的配置值在所有机器实例上的分布,也能看到其在不同标签下的持久化值。
结束语
本文介绍了全链路灰度场景给配置管理带来的问题,介绍了 MSE 针对这一场景的解决方案,并通过实践的方式展示了配置标签推送的使用流程。后续,MSE 还会针对配置治理做更多的探索,帮助用户更好地解决微服务配置管理中的难题,提高微服务应用的稳定性。
作者:洵沐、流士
原文链接
本文为阿里云原创内容,未经允许不得转载。
)

)


)



)



)


)


