背景及现状
系统架构简介

上图为阿里云内部实际使用的系统架构,系统主要用途为实时数据流的计算和存储。使用阿里云的容器服务 ACK 作为系统底座,容器化的部署、发布、管控等全部基于 K8s 标准。使用自己开发的 Gateway service 作为系统流量入口,并基于 LoadBalancer 类型的 service 部署。
此架构也是应用 K8s 做系统较为常见的做法,通过 ACK 提供的 CCM 组件自动将 service 和底层 SLB 实例进行绑定,通过此实例承接外部流量。Gateway 收到上报的数据流后,将数据放入 Kafka 并在某个 topic 中进行数据缓冲。当 Consumer 感知到数据流的上报后,则会从 Kafka 相应的 topic 中对数据进行进一步计算处理,并将最终结果写入存储介质。
此处存在两种存储介质:其中阿里云块存储 ESSD 相对较快,但价格较高;文件存储 NAS 主要用于存放性能要求较低的数据。元数据由 ACM 进行管理,自研的组件 Consumer 和 Center 负责从存储介质中查询计算结果,并返回给用户。
系统现状

系统目前为全球开服,部署在全球将近 20 个 region 中,从图中也可以间接看出数据读写链路较长,需要经过多个组件的处理。监控对象也较为复杂,包括基础设施(调度、存储、网络等)、中间件(Kafka)、业务组件(Gateway、Center、Consumer)。
工作内容
- 可观测数据的收集
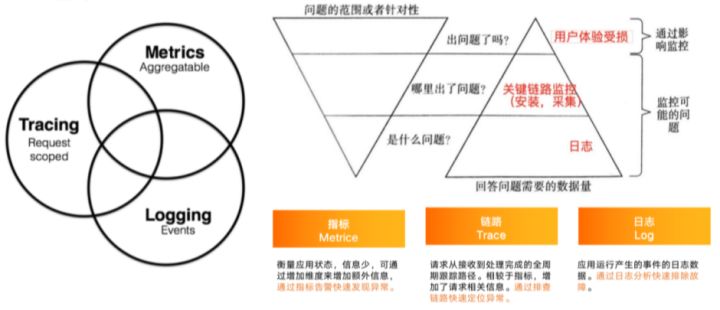
可观测性主要包含Metrics、Tracing 和 Logging三类数据。三类数据各司其职,相辅相成。
Metrics 负责回答系统是否出现问题,它也是系统的自监控体系入口。针对 Metrics 做异常的告警或问题的排查,可以快速确定系统是否有问题,是否需要人为介入处理。
Tracing 负责回答系统问题出现在什么位置,它能够提供组件之间的调用关系、每一次请求以及哪两个组件之间的调用过程出现了问题等具体细节。
找到出现问题的组件后,需要通过最详细的问题日志即 Logging 来定位问题根因。
- 数据可视化&问题排查
收集到三类数据后,下一步需要通过大盘将数据用可视化的方式展现,能够一眼确定问题所在,使问题排查更高效。
- 告警&应急处理

确定问题后,需要通过告警和应急处理流程来解决问题。
应急处理过程主要有以下几个要点:
第一,需要分级的告警通知和升级策略,能够快速找到相应的人员处理告警。与此同时,若原定人员因为某些原因无法及时处理,还需将告警升级到其他人员以及时处理。
第二,问题认领和处理流程标准化。
第三,事后统计及复盘。系统出现故障并解决后,还需要事后的统计以及复盘工作,让系统通过故障和教训避免后续再出现相同的问题,让系统更稳定。
第四,运维处理工具化、白屏化,尽量减少手动输入命令的工作,将整套标准的处理动作用工具进行固化。
实践经验分享
可观测数据收集&接入
- 指标(Metrics)数据
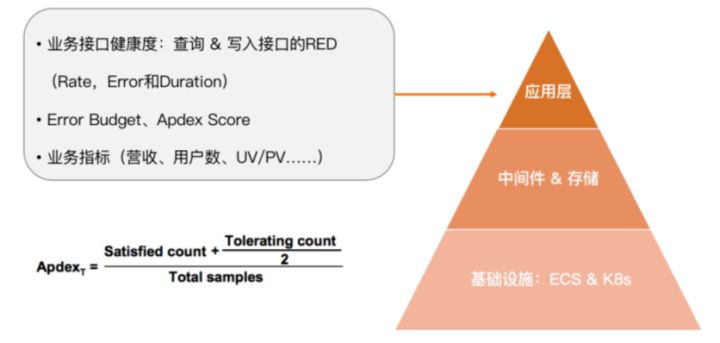
监控的第一步是收集可观测数据,这些数据在系统里可以分为三个层面。
最上层为应用层,主要关心核心业务接口的健康度,通过RED(Rate、Error、Duration)三个黄金指标进行衡量。其中 Rate 指接口的 QPS 或 TPS ,Error 指错误率或错误数,Duration 指接口在多长时间内能够返回。可以通过黄金指标来定义 SLO 并分配 Error Budget 。如果 Error Budget 很快耗尽,则应及时调整 SLO,直到系统优化到足够完善后,再将其调高。也可以通过 Apdex Score 衡量服务的健康度,计算公式如上图所示。此外,应用层也会关心与业务强相关的指标,比如营收、用户数、UV、PV 等。
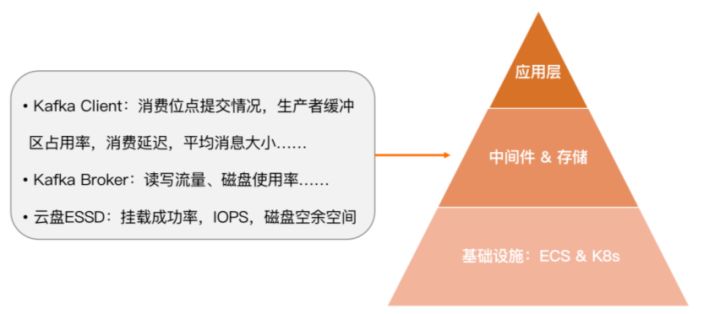
中间层为中间件和存储,主要关心系统里大量应用的 Kafka client 端消费位点的提交状况、生产者缓冲区的占用率、是否会提前将缓冲区占满导致新的消息进不来、消费延迟、平均消息大小等,比如 Kafka Broker 端的水位、读写流量、磁盘使用率等,再比如云盘 ESSD 的挂载成功率、IOPS、磁盘空余空间等。
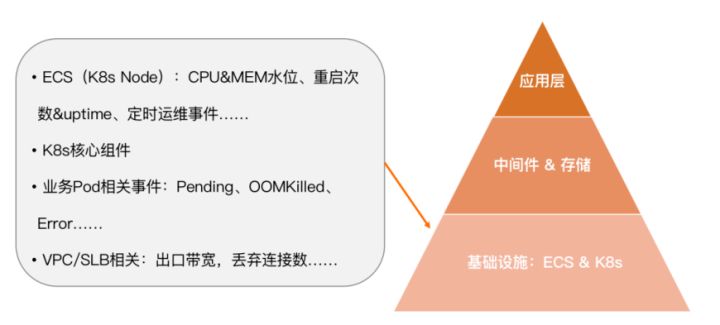
最下层是基础设施层,关心的指标较为复杂,典型的有比如 ECS(K8s Node) CPU 内存水位、重启次数、定时运维事件等,比如 K8s 核心组件的 API server、 ETCD、调度相关指标等,比如业务 Pod 的 Pending 状态、是否有资源可供足够的调度、OOMKilled 事件、Error 事件等,再比如 VPC/SLB 相关的出口带宽、丢弃连接数等。
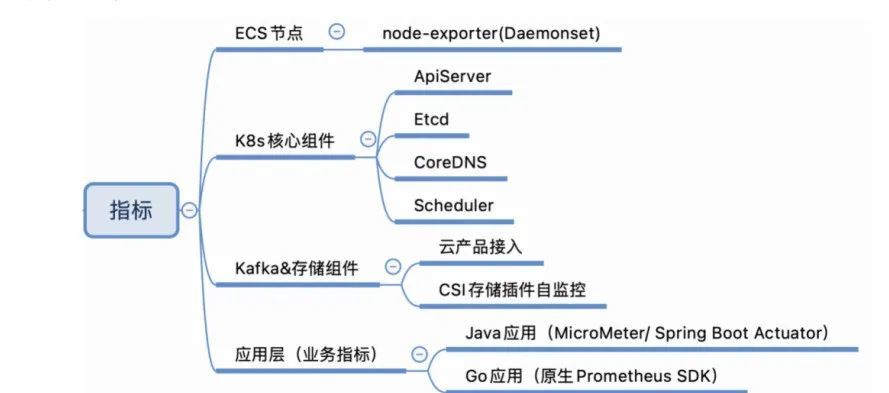
监控 ECS 节点需要使用 node-exporter Daemonset 的方式部署,K8s 云原生的核心组件可以通过 Metrics 接口将指标暴露,供 Prometheus 抓取。Kafka 或存储组件由于使用了阿里云的云产品,本身提供了基础监控指标,可以直接接入。ACK 对 CSI 存储插件也提供了非常核心的指标比如挂载率、iops、空间占用率等,也需要接入。应用层包括 Java 应用和 Go 应用,Java 使用 MicroMeter 或 Spring Boot Actuator 做监控,Go 应用直接使用 Prometheus 官方 SDK 做埋点。

基于 ACK 和 K8s 体系, Metrics 协议的最佳选型即 Prometheus。开源自建的 Prometheus 与云托管的接入难度不相上下,但可靠性、运维成本等方面,云托管的 Prometheus 更优于自建。比如使用 ARMS 体系,可以直接在集群里安装非常轻量级的探针,然后将数据中心化存储在全托管的存储组件,并围绕它做监控、告警、可视化等,整个过程非常方便,不需要自建开源组件。云托管在采集能力和存储能力上也更有优势。

Prometheus 针对 ECS 节点、K8s 核心组件、Kafka 和存储组件都提供了一键接入的能力。
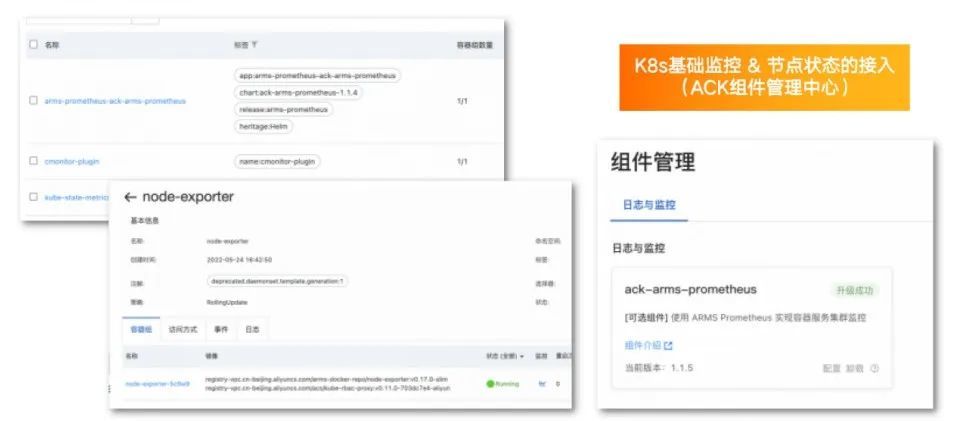
K8s 基础监控和节点状态接入主要通过 ACK 组件管理中心,只需简单地安装相关组件,即可使用该能力。

Kafka 的接入主要通过 Prometheus 云服务实例,云服务实例目前已经接入阿里云非常完整的 PaaS 层云产品。接入 Kafka 时,所需填写的指标都为常见指标,无需额外学习成本。

云盘 ESSD 监控的接入主要通过 CSI 存储插件监控。ACK 里的 csi-provisioner 组件提供了很有用的可观测性能力,可以通过它提供的信息及时查看哪块盘没有挂载上、哪块盘挂在后 iops 达不到要求或配置告警,以及时发现云盘的异常状况。
通过 ARMS Prometheus 接入,预置采集的 job 比如 K8s cluster 级别、node 级别的 PV 状态都可以很方便地进行监控。
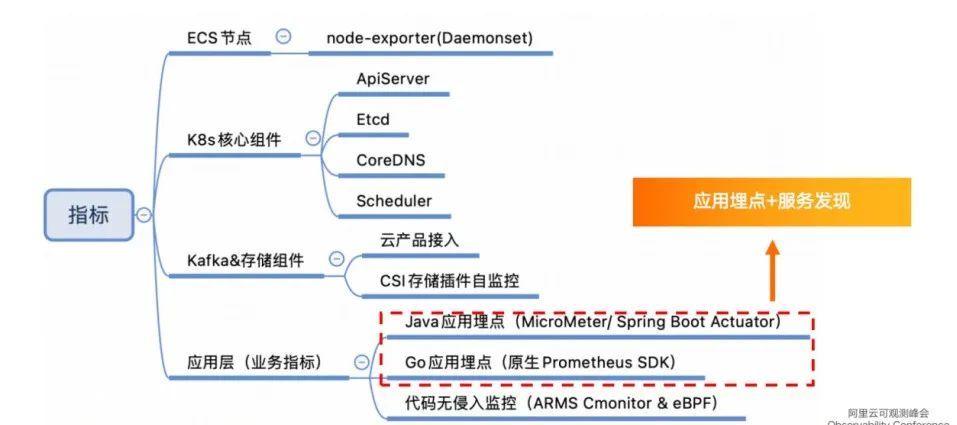
应用层不存在一键接入的便捷方式,需要通过应用埋点+服务发现的方式,将整个应用的 Metrics 接口暴露出来,提供给 ARMS Prometheus 的探针抓取。

Java 应用需要使用 MicroMeter 或 Spring Boot Actuator 进行埋点。
以上图代码为例,MicroMeter 中很多 JVM 相关信息可以简单地通过几行代码进行暴露,其他更有帮助的信息,比如进程级别的 memory 或 thread、system 信息等也可以通过很简单的方式将其接入。设置完埋点后,需要在内部启动 server ,将 Metrics 信息通过 HTTP 接口的方式暴露,最后绑定指定的端口。至此,埋点流程结束。
此外,如果有业务指标,只需将自己的指标注册到全局的 Prometheus Registry 即可。

ARMS 探针抓取暴露的端点,只需添加 ServiceMonitor ,由 ServiceMonitor 直接通过控制台白屏化的方式,简单地写几行 YAML 的定义,即可完整地将整个监控的采集、存储和可视化跑通。
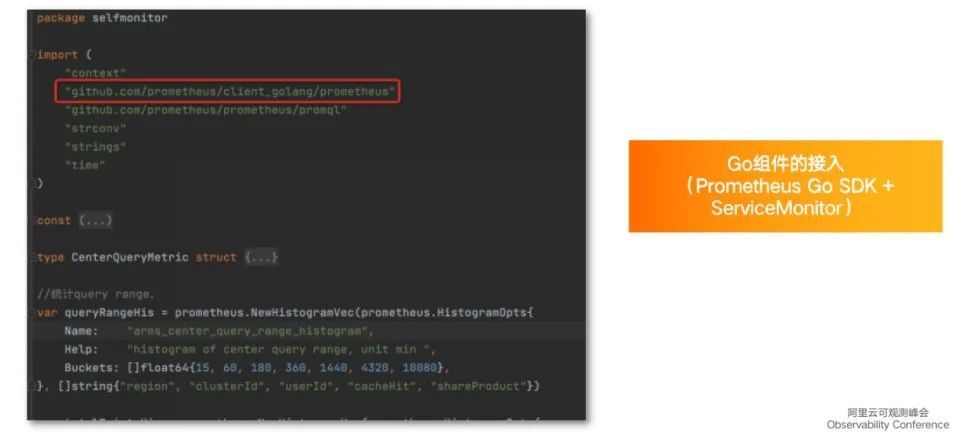
Go 应用与 Java 大同小异,只是埋点方式有所区别,主要使用 Prometheus 官方的 SDK 埋点。
以上图为例,比如系统里有一个查询组件关心每一条查询的时间分布,可以使用 Prometheus 里面直方图类型的指标,记录每个请求的时间分布,并在埋点的时候指定常用的分统进行统计。再由 ServiceMonitor 将 Go 应用的 endpoint 写入,最终在控制台上完成整套应用的接入。

ARMS 还提供了基于 eBPF 的无侵入可观测性实现方案,主要适用于不希望修改代码的场景,使用无侵入的方式监控系统接口的 RED,通过 ARMS Cmonitor 探针结合 eBPF 的方式,通过系统内核的 filter 实现信息的抓取和存储。

使用上述方式需要在集群里额外安装 Cmonitor App,安装后可在 Daemonset 看到 Cmonitor Agent,每个节点都需要启动 Cmonitor Agent,作用是通过 eBPF 的方式注册到系统内核中,抓取整台机器的网络流量,然后过滤出想要的 service 网络的拓扑等信息。如上图,它可以监控整个系统的 QPS 、响应时间的分布等信息。
- 链路(Trace)和日志(Log)数据

Trace 也使用 Cmonitor 来实现相关能力。日志方面,系统组件的日志、K8s 控制面的日志、JVM 的 DCLog 等,主要通过 arms-Promtail (采集应用日志的探针)将日志投递到 Loki 内做长期存储。
K8s 系统事件的日志,主要基于 ARMS 事件中心的功能对 K8s 的关键事件、Pod 调度上的 OOM 、Error 等事件进行监护。
- 读写链路监控和问题定位
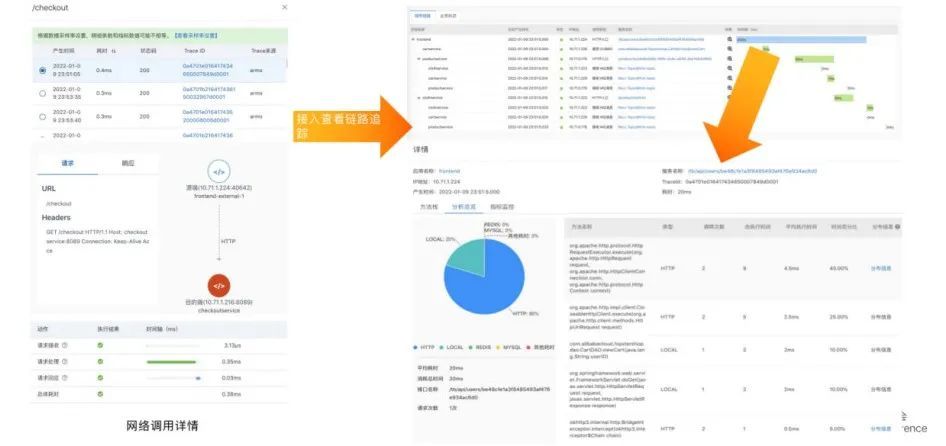
上图为部分系统截图。
比如 trace 相关控制台可以查看每个请求经过的组件、接收用时、处理时长、回应耗时等标准信息。
- 组件运行日志收集和存储
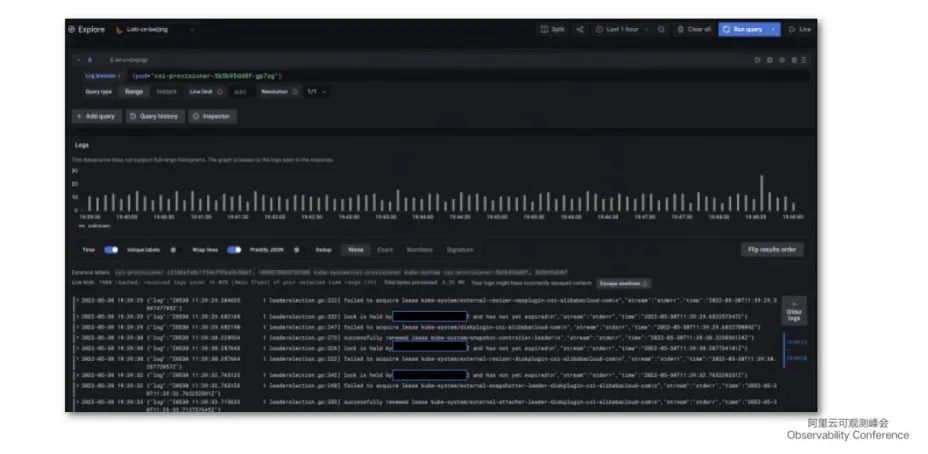
日志收集方面,通过在 Grafana 里配置 Loki 的数据源,即可轻松根据关键字或 Pod 标签快速获取到 Pod 或某个 service 下挂载的 Pod 日志,对排查问题提供了极大便利。
- K8s 运行事件收集和监控
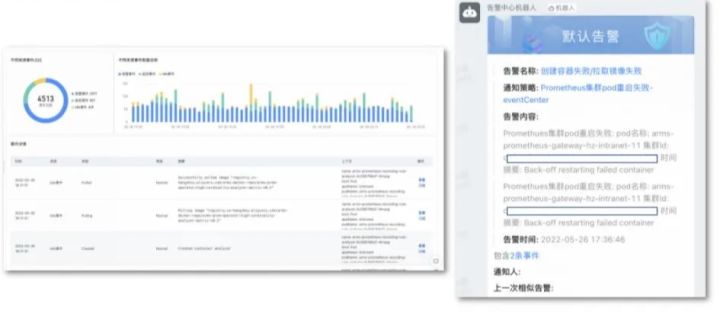
上图为 ARMS 提供的事件中心工作台截图。工作台提供了关键事件列表,可以对等级较高的事件进行订阅,订阅只需简单几步:填写基本规则,选择需要匹配事件的模式,选择告警发送对象,即可对关键事件进行监控,实现及时响应的目的。
数据可视化及问题排查
- Grafana 大盘配置实践

完成数据收集后,下一步需要打造高效可用的数据可视化和问题排查工具。
Prometheus 与 Grafana 是一对黄金搭档,因此我们也选择了 Grafana 作为数据可视化的工具。上图列举了大盘配置过程中的要点:
- 加载大盘时需要控制每个 panel 上的查询时间线,避免在前端展现过多时间线,导致浏览器渲染压力大。而且,对于问题排查而言,一次性显示多时间线并没有帮助。
- 大盘配置了很多灵活的 Variable ,可以随意在一张大盘上切换各种数据源和查询条件。
- 使用 Transform 让 Table Panel 灵活展现统计信息。
- 分清 Range 和 Instant 查询开关,避免无用的范围查询拖慢大盘显示速度。
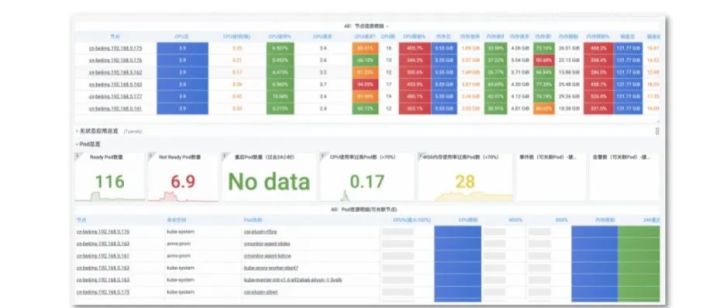
K8s集群总览
上图为监控节点信息、 K8s 集群 Pod 信息的大盘。整体布局一目了然,通过不同颜色对关键信息进行标记,通过 Grafana 的动态阈值功能将数字以不同的形式展现,提升问题排查效率。
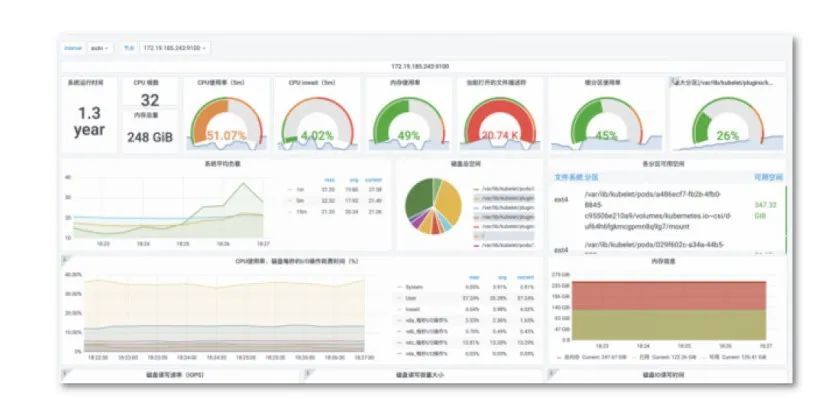
节点水位
上图为节点水位大盘,展示了磁盘iops 、读写时间、网络流量、内存使用率、CPU使用率等重要信息。
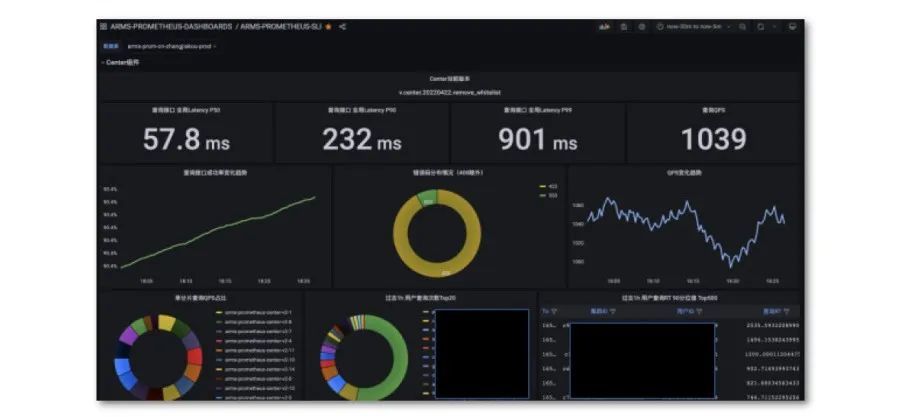
全局 SLO
上图为全局 SLO 大盘 。通过 Grafana 托管服务配置自定义大盘,这也是 ARMS 最新上线的功能,在云上托管 Grafana 实例,即可通过云账号直接登录到 Grafana 界面,其中包含阿里云定制的特有功能。
大盘中包含了全局 latency、QPS、成功率、错误码的分布情况、QPS 的变化趋势,以及一些较细粒度的信息,比如单分片、负载均衡、Gateway 组件、center 组件等。如遇发版,可以通过带上版本号查看前后版本的区别,可以在 pannel 中以变量的形式展现 datasource,也可以选择全球各个 region 进行切换查看。
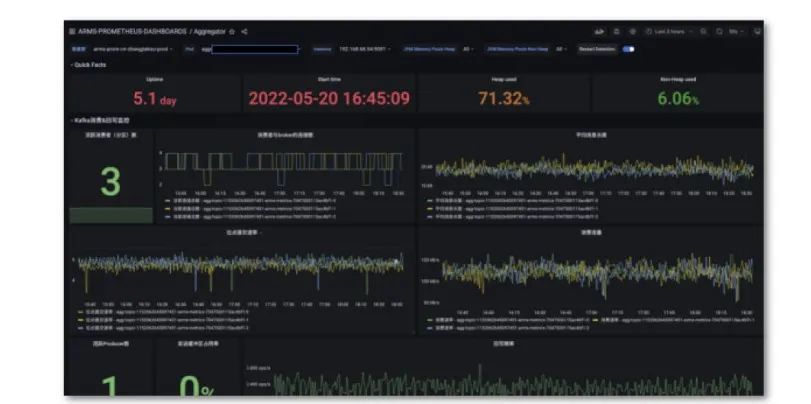
Kafka 客户端及服务端监控
集群中依赖 Kafka 客户端和服务端,其监控来源于云监控集成。
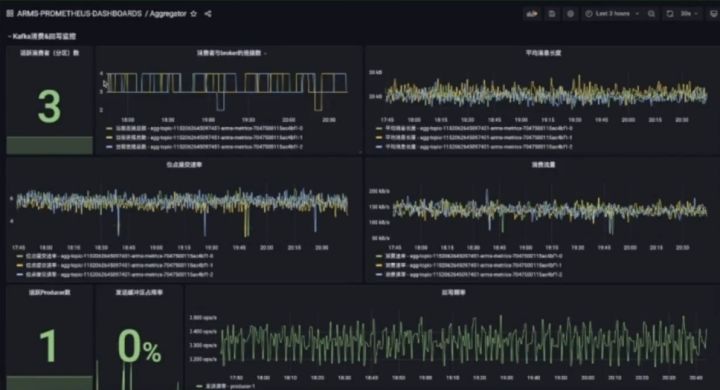
内部组件强依赖于 Kafka,通过指标监控 Kafka 以及它与 broker 之间的连接数、平均消息长度、位点提交速率、消费流量等。Producer 端提供了缓冲区的占用率、活跃的 producer 数等信息。
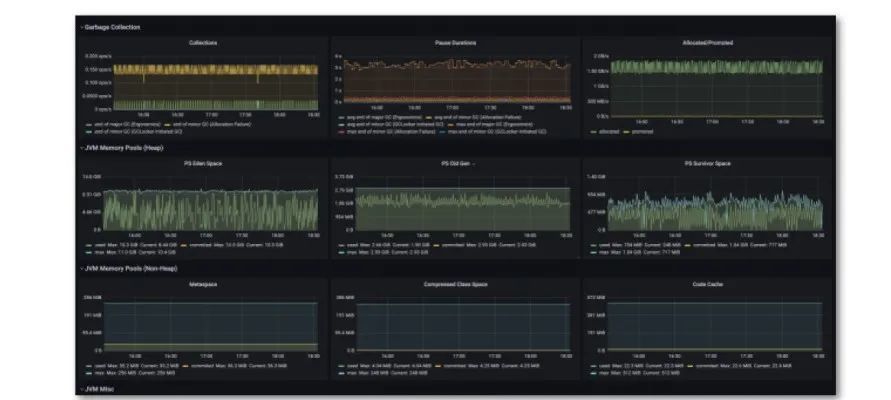
Java 应用运行情况监控
如果组件使用 Java 编写,还需要监控 JVM 相关的 GC 情况,大盘能够提供 JVM memory 的情况、GC 相关情况、CPU 使用率、线程数、线程状态等。此外,比如发版或有动态加载的类,在加载类的统计中可以查看是否存在持续上升的状态等。

Table 格式的错误类型复盘统计表
如果希望使用电子表格统计集群中的安装状态或重点客户状态,可以使用 Grafana 的 transform 功能将整个大盘打造成电子表格式的体验。可以用 transform 将字段映射到一张电子表格上,打开 filter 后还可通过筛选各种字段得出查询结果。
- 问题排查案例分享
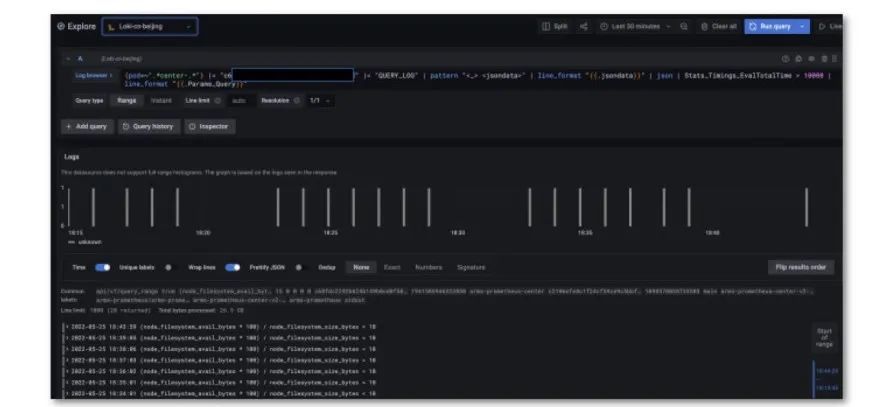
日志信息的展示需要通过在 Grafana 里查询 Loki 的数据,比如 center 里有查询日志,其中包含很多原始信息,比如此次查询的时间、UID 等。通过后处理的方式,首先将想要的日志按行的方式进行筛选,然后通过模式匹配提取信息,后续还可以按照 PromQL 将其中某些字段的做大小关系的匹配,最终将匹配出来的日志格式进行二次处理。
告警和分级响应机制

上图为告警和分级响应机制流程,依次为告警配置、人员排班、告警触发、应急处理、事后复盘和机制优化,最后将机制优化体现在告警配置上,形成完整的闭环。
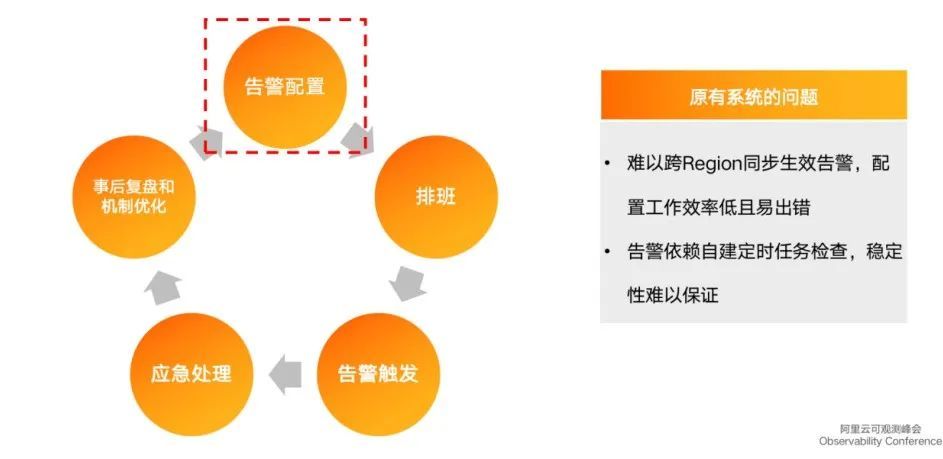
以上流程是自建的告警系统,通过依赖自建系统定时跑任务检查指标,然后调用钉钉的 webhook 或其他运维系统的 webhook 发出告警,流程中存在几点不足:
1. 自建系统的稳定性需要自己负责,如果告警系统的稳定性比运维系统更差,则告警系统的存在无意义。其次,随着整个集群开服的 region 越来越多,配置越来越复杂,自己维护配置并保证配置全球生效难以实现。
2. 依赖手工排班,极易出现漏排或 backup 缺失。
3. 告警触发阶段触发条件非常单一,难以在告警触发链路上增加额外的业务逻辑,如动态阈值、动态打标等。

4. 应急处理阶段,信息发送非常频繁,无法主动认领和主动关闭。系统出现问题时,同类告警会在群里高密度发送,无法主动屏蔽告警也是缺陷之一。
5. 事后复盘优化的时候没有数据支撑,无法根据已有的告警统计信息来优化整个流程。
因此,我们选择基于 ARMS 来建立告警系统。ARMS 强大的告警和分级响应机制为我们带来了诸多便利:
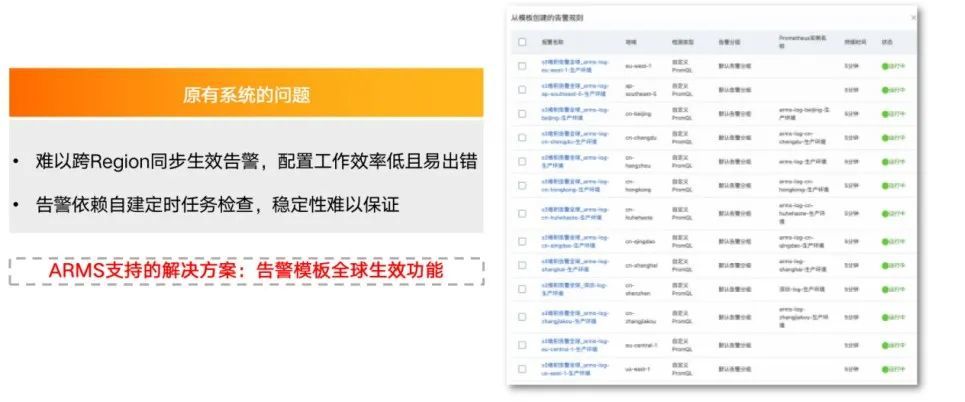
1. 告警模板全球生效功能:只需配置一次告警规则,即可使不同的集群生效告警规则。比如没有告警模板时需要对每个 cluster 里的指标单独配置告警。而有了模板后,只需通过告警规则模板的方式将 PromQL 或告警的 AlertRule apply 到全球各个 region 集群,非常方便。
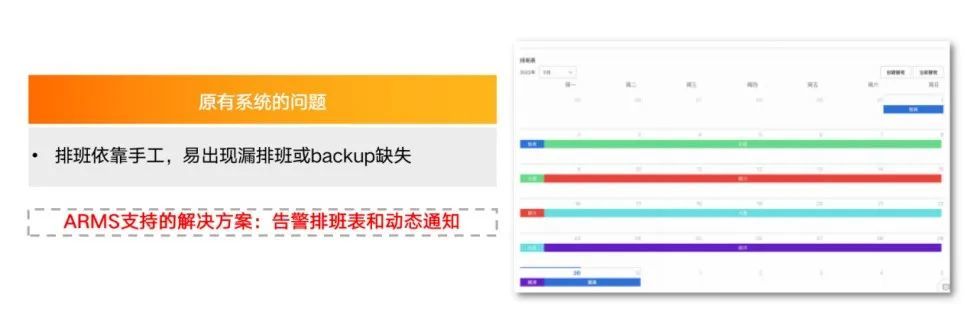
2. 告警排班表和动态通知:系统能够动态实现轮班替班工作,比手工排班更靠谱。
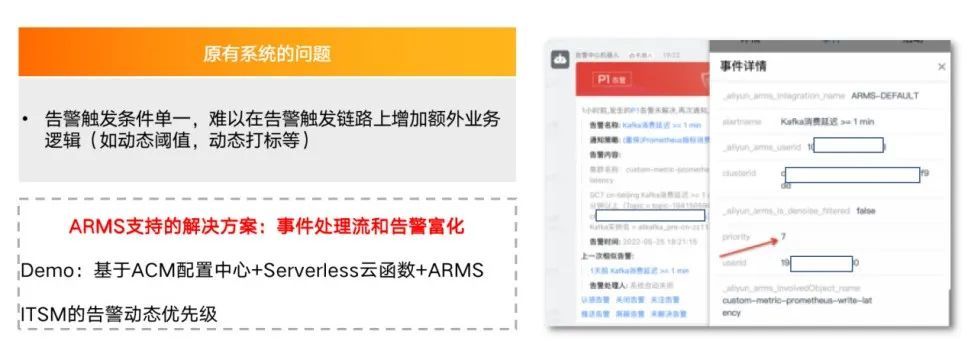
3. 事件处理流和告警富化:可以通过 ARMS 的事件处理流、告警中心的事件处理流和告警富化功能,在告警触发后动态地打上标记,并且做分级处理。如上图,可以给告警打上优先级标签,优先级较高的告警等级升级为 P1,并且可以动态地修改告警接收人。
为了实现上述功能,首先需要有数据源来提供打标的依据。在告警运维中心的控制台上有数据源的功能,告警触发时可以通过 HTTP 请求或 RPC 请求调用数据源,而后可以从 HTTP URL 里获取打标的结果。此接口的实现主要通过 IFC 轻量工具在线写好代码,代码主要负责读取 ACM 配置中心里的信息配置项,然后读取配置项并对外暴露 HTTP 接口,提供给告警运维中心动态地调用。
完成以上步骤后,还需配置事件处理流,将需要的信息通过匹配更新模式的方式传递到上述接口,并返回优先级,最终打到告警上。
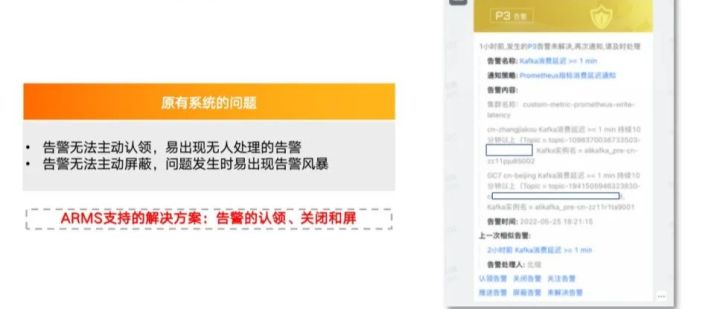
4. 告警的认领、关闭和屏蔽:ARMS 提供了认领、关闭、关注、屏蔽等实用功能,显著提升了告警质量。
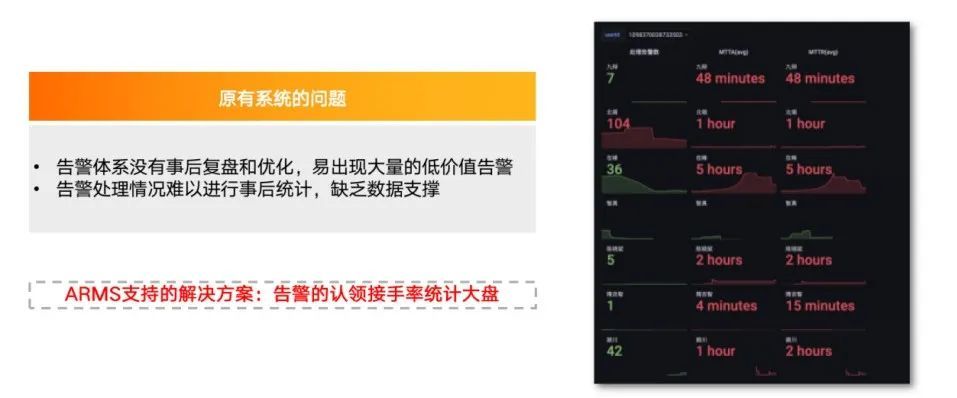
5. 告警的认领接手率统计大盘:复盘的时候需要知道每个人处理了多少告警、处理时长、告警平均恢复时间等,引入了认领、关闭、恢复、屏蔽机制后,ARMS告警中心在后台记录了事件的日志,通过对日志的分析即可提供有用的复盘信息。
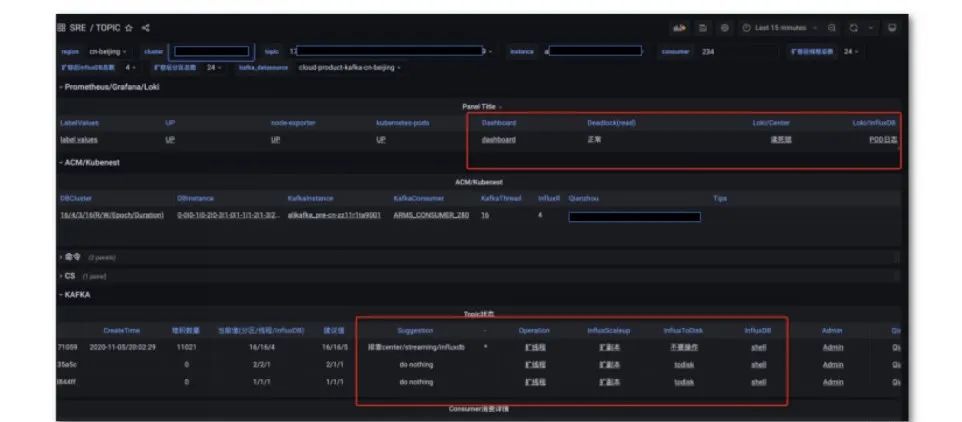
得到告警信息后,用户希望可以在白屏化的界面上处理问题,因此我们引入了基于 Grafana 的白屏化运维工具链。其原理为,在配置大盘的时候引入动态信息,并将其以链接的形式拼接到大盘里。
我们内部有各种系统,如果没有官方的链接拼接,则需要自己首拼 URL 或手动搜索,效率非常低。而通过在 Grafana 里嵌入链接的方式,将运维动作固化成链接之间的跳转,对于效率的提升非常有帮助。能够通过 Grafana 一套工具将所有工作完成,将运维动作标准化、固化,减少人工出错的可能性
总结和未来工作

第一,告警准确度和接手率的优化。目前还没有很好的方式能够将告警的复盘信息高效地利用起来,未来我们将尝试通过告警准确度和接手率的信息,及时调整不合理的告警阈值,也可能会尝试多阈值的告警,比如告警在 A 到 B 范围之内是多少等级,在 B 以上是多少等级。
第二,多类型数据联动。比如在排查问题的时候,除了 Metrics 、Trace 和 Log 之外,还有 profiler、CPU 的火焰图等信息,而目前这些信息与可观测数据的联动较低。提升数据联动,可以提升问题排查效率。
第三,埋点成本控制。对于外部客户而言,埋点成本直接关系到客户使用阿里云的成本。我们将定期地对自监控指标的维度、发散的维度等进行针对性的治理,并且对于无用的维度进行数据清理,将埋点成本控制在较低水平。
作者:宋傲(凡星)
原文链接
本文为阿里云原创内容,未经允许不得转载。
)


)



)



)


)



)
