导读
多模态内容(例如图像、文本、语音、视频等)在互联网上的爆炸性增长推动了各种跨模态模型的研究与发展,支持了多种跨模态内容理解任务。在这些跨模态模型中,CLIP(Contrastive Language-Image Pre-training)是一种经典的文图跨模态检索模型,它在大规模图文数据集上进行了对比学习预训练,具有很强的文图跨模态表征学习能力。在先前的工作(看这里)中,中⽂NLP/多模态算法框架EasyNLP支持了CLIP的基础功能,包括模型的Finetune、文图向量抽取等。在本期的工作中,我们对EasyNLP框架进行了再一次升级,推出了融合了丰富电商场景知识的CLIP模型,在电商文图检索效果上刷新了SOTA结果,并且将上述模型免费开源,贡献给开源社区。
EasyNLP(https://github.com/alibaba/EasyNLP)是阿⾥云机器学习PAI 团队基于 PyTorch 开发的易⽤且丰富的NLP算法框架,⽀持常⽤的中⽂预训练模型和⼤模型落地技术,并且提供了从训练到部署的⼀站式 NLP 开发体验。EasyNLP 提供了简洁的接⼝供⽤户开发 NLP 模型,包括NLP应⽤ AppZoo 和预训练 ModelZoo,同时提供技术帮助⽤户⾼效的落地超⼤预训练模型到业务。由于跨模态理解需求的不断增加,EasyNLP也⽀持各种跨模态模型,推向开源社区,希望能够服务更多的 NLP 和多模态算法开发者和研 究者,也希望和社区⼀起推动 NLP /多模态技术的发展和模型落地。
本⽂简要介绍我们在电商下对CLIP模型的优化,以及上述模型在公开数据集上的评测结果。最后,我们介绍如何在EasyNLP框架中调用上述电商CLIP模型。
CLIP模型技术概览
OpenAI于2021年提出的CLIP(Contrastive Language-Image Pre-training)模型,收集了4亿文本-图像对进行图文对比学习训练,建立了图像和文本的关联性。CLIP模型包含两部分,分别为图像和文本的Encoder,用于对图像和文本分别进行特征抽取。CLIP的图像的Backbone有多个选择,既可以使用经典的ResNet系列模型,也可以选择近两年更先进的Transfomer类模型,例如ViT等。对于文本而言,CLIP一般使用BERT类模型,RoBERTa等也可以作为选择。
CLIP模型基础技术
CLIP在特征抽取后,分别对图文向量进行Normalization,之后进一步进行内积计算,获取样本间的相似度。在模型Loss Function层面,由于我们对进行Normalization之后的图像和文本向量直接使用相乘以计算余弦距离,目的是使得匹配的图文对的结果趋近于1,不匹配的图文对的结果趋近于0;并且优化对比学习损失InfoNCE进行模型的预训练。

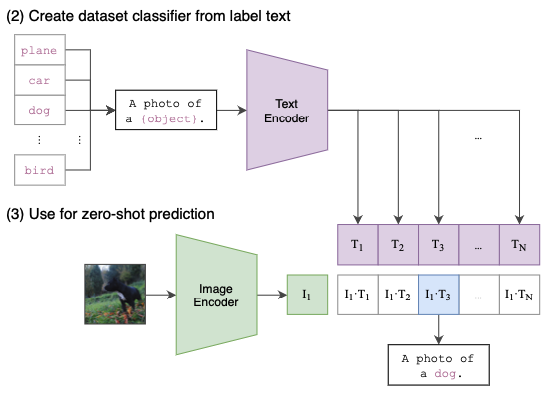
CLIP的双流架构使得其在推理阶段可以非常方便地用于计算图文相似度,因为CLIP已经将图文的表示映射到同一个向量空间。此外,通过对类别标签设计Prompt,CLIP的还具有强大的Zero-shot Classification能力。如下图所示,将文本标签转化为Prompt “A photo of a {object}.”,并且使用目标图像作为输出。如果文本“A photo of a dog.”于当前图像匹配度最高(具有最大的余弦相似度),即可以说明,当前图像的物体是“dog”。由此可见,预训练后的CLIP模型可以非常好的直接应用于图像分类模型,而不需要额外的训练。
电商场景下CLIP模型的优化
EasyNLP借鉴CLIP的轻量化、易迁移的预训练架构,构建基于CLIP包含图像和文本Encoder两部分的双流模型,同时基于商品数据,以优化电商场景的文图检索优化。具体来说,我们采样了200万的商品图文数据,在OpenCLIP公开的模型权重上进行了继续预训练,使得模型具有电商领域的感知能力。同时,由于电商场景的文本概念分布稀疏,图像以商品图为主,具有较低的场景丰富性,因此,我们在预训练过程中更加关注电商概念的相关知识,引入了图文知识的细粒度交互,使得模型具备电商知识的识别能力。特别地,我们重点参考了DeCLIP的工作,对于电商概念构建其Prototype表征,存储在Feature Queue中,从而在训练过程中关注当前图文对与电商概念Prototype表征的匹配信息(见参考文献8)。
对图像部分的输入,我们将图像统一Resize为224×224的大小,并考虑不同的应用和部署场景,采用ViT-B-32(Vision Transformer层数为12,图像Patch大小为32×32)和ViT-L-14(Vision Transformer层数为24,图像patch大小为14×14)两种模型作为图像侧的Encoder。对于文本部分的输入,我们和CLIP一样采用12层Text Transformer作为文本侧Encoder,通过BPE分词器做文本预处理,并限定文本词长小于77。这两个电商场景的CLIP模型参数配置如下表:
| 模型配置 | alibaba-pai/pai-clip-commercial-base-en | alibaba-pai/pai-clip-commercial-large-en |
| 参数量(Parameters) | 151M | 428M |
| 层数(Number of Layers) | 12 | 24 |
| 注意力头数(Attention Heads) | 12 | 16 |
| 隐向量维度(Hidden Size) | 768 | 1024 |
| 文本长度(Text Length) | 77 | 77 |
| 图像序列长度(Image Patch Size) | 32 x 32 | 14 x 14 |
| 图像尺寸(Image Size) | 224 x 224 | 224 x 224 |
| 词表大小(Vocabulary Size) | 49408 | 49408 |
如上表所述,电商CLIP模型包含了两个不同的图像Encoder架构,为表中的pai-clip-commercial-base-en和pai-clip-commercial-large-en模型,分别代表ViT-B-32和ViT-L-14作为图像Backbone。
此外,我们也提供了两个中文的预训练CLIP模型,贡献到开源社区,相关配置如下:
| 模型配置 | alibaba-pai/clip_chinese_roberta_base_vit_base | alibaba-pai/clip_chinese_roberta_base_vit_large |
| 参数量(Parameters) | 188M | 406M |
| 层数(Number of Layers) | 12 | 24 |
| 注意力头数(Attention Heads) | 12 | 16 |
| 隐向量维度(Hidden Size) | 768 | 1024 |
| 文本长度(Text Length) | 77 | 77 |
| 图像序列长度(Image Patch Size) | 16 x 16 | 16 x 16 |
| 图像尺寸(Image Size) | 224 x 224 | 224 x 224 |
| 词表大小(Vocabulary Size) | 21128 | 21128 |
电商CLIP模型效果评测
Fashion-Gen数据集是一个大规模的时尚场景的图文数据集,是电商领域FashionBERT、KaleidoBERT、CommerceMM等模型用来评测检索效果的较为通用的数据集。Fashion-Gen共包含293,088条商品图文数据,其中训练集包含260,480个图文对,验证集和测试集包含32,528条图文对。Fashion-Gen中的商品数据包含48个大类别,121个小类别,在训练和测试数据中类别最多的包括"tops","sweaters","jackets & coats"等。我们基于pai-clip-commercial-base-en和pai-clip-commercial-large-en这两个模型在Fashion-Gen数据集上进行了20个epoch的微调。
如下表所示,实验结果表明,相比于现公布的SOTA模型(CommerceMM),在文到图和图到文的检索结果上,我们的电商CLIP已经有了显著的效果提升。其中,Rank@1,Rank@5和Rank@10分别代表图文或文图检索结果Top 1、Top 5和Top 10中含有正确结果的准确率。我们的电商CLIP-large模型,在图文检索的结果上提升了2.9~5.6个百分点,在文图检索上的表现更加优秀,在三个评测指标上提升了8.7~15个百分点。电商base模型在文到图的检索结果上与CommerceMM相当,却使用了更少的参数量。电商CLIP无论在large还是base图像Encoder的设置下,都取得了有竞争力的电商场景跨模态检索能力。
文到图检索评测结果

图到文检索评测结果

如下展示了EasyNLP电商CLIP在Fashion-Gen验证集上的文图检索结果,对于相同的文本,我们分别展示了我们模型和开源CLIP模型的Top-1图像检索结果:

通过上述案例展示可以看出,EasyNLP电商CLIP在图文交互过程中可以捕捉更细粒度的时尚信息,更进一步在概念知识层级实现图文样本的跨模态对齐。如case 1所示,EasyNLP电商CLIP更准确的捕捉了目标商品图片的主体为“Midi skirt in pine green.”,并使得包含了“midi skirt”,“pine green”,“bow accent”,“ruffled detail”等细粒度时尚正确的图像——正面荷叶边、腰部含有蝴蝶结装饰、松绿色、中长半身裙的商品图与文本有更高的相似度。没有在预训练过程中注入电商知识的模型虽然也检索到了松绿色的商品图,但在商品主体定位上即产生了错误。case 4则更关注到了细粒度的时尚概念“three-button placket.”,使包含这些特征的正确图片(第二列)排名更靠前。case 4第三列的商品图虽然同样可以匹配“long sleeve”,“'medium' grey”等特征,但相比于ground-truth图像,其仅反映了query的部分信息。同样的,case 5中的错误图像仅关注了“in black”,“fringed edges”等细节概念,而忽视了query中特征的主体应为“sandals”。通过EasyNLP电商CLIP对于图文时尚概念的对齐,则可以很好的避免这些错误的匹配。
EasyNLP框架中电商CLIP模型的实现
在EasyNLP框架中,我们在模型层构建了CLIP模型的Backbone,其核⼼代码如下所示:
def forward(self, inputs,feat=None):if self.model_type=='open_clip':_device=self.open_clip.text_projection.devicelogit_scale = self.open_clip.logit_scale.exp()elif self.model_type=='chinese_clip':_device=self.chinese_clip.text_projection.devicelogit_scale = self.chinese_clip.logit_scale.exp()else:_device=self.text_projection.weight.devicelogit_scale = self.logit_scale.exp()if 'pixel_values' in inputs:inputs['pixel_values']=inputs['pixel_values'].to(_device)else:inputs['pixel_values']=Noneif 'input_ids' in inputs:inputs['input_ids']=inputs['input_ids'].to(_device)else:inputs['input_ids']=Noneif self.model_type=='open_clip':image_embeds, text_embeds = self.open_clip(inputs['pixel_values'], inputs['input_ids']) elif self.model_type=='chinese_clip':image_embeds, text_embeds = self.chinese_clip(inputs['pixel_values'], inputs['input_ids']) else:image_embeds=Nonetext_embeds=Noneif 'input_ids' in inputs:text_outputs = self.text_encoder(input_ids=inputs['input_ids'],token_type_ids=inputs['token_type_ids'].to(_device),attention_mask=inputs['attention_mask'].to(_device))text_embeds = text_outputs[1]text_embeds = self.text_projection(text_embeds)text_embeds = text_embeds / text_embeds.norm(dim=-1, keepdim=True)if 'pixel_values' in inputs:vision_outputs = self.vision_encoder(pixel_values=inputs['pixel_values'])image_embeds = vision_outputs[1].detach()image_embeds = self.vision_projection(image_embeds)image_embeds = image_embeds / image_embeds.norm(dim=-1, keepdim=True)if feat is True:return {'image_embeds':image_embeds,'text_embeds':text_embeds}# cosine similarity as logitslogits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scalelogits_per_image = logits_per_text.Treturn {'logits_per_text':logits_per_text,'logits_per_image':logits_per_image,'image_embeds':image_embeds,'text_embeds':text_embeds}# contrastive loss function, adapted from# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.htmldef contrastive_loss(self,logits: torch.Tensor) -> torch.Tensor:return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))def clip_loss(self,similarity: torch.Tensor) -> torch.Tensor:caption_loss = self.contrastive_loss(similarity)image_loss = self.contrastive_loss(similarity.T)return (caption_loss + image_loss) / 2.0 def compute_loss(self, forward_outputs, label_ids, **kwargs):loss = self.clip_loss(forward_outputs['logits_per_text'])return {'loss': loss}中英文CLIP模型使⽤教程
以下我们简要介绍如何在EasyNLP框架使⽤CLIP模型。
安装EasyNLP
⽤户可以直接参考GitHub(https://github.com/alibaba/EasyNLP)上的说明安装EasyNLP算法框架。
数据准备
CLIP是一个finetune模型,需要用户准备下游任务的训练与验证数据,为tsv文件。这⼀⽂件包含以制表符\t分隔的两列,第一列是文本,第二列是图片的base64编码。样例如下:
Long sleeve stretch jersey pullover in 'burnt' red. Turtleneck collar. Tonal stitching. /9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAEAAQADASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD3+iiigAooooAKKKKACiiigAooooAKKKKACiio5JUhiaSRgqICzE9gKAK2o6nZaRYyXt/cJBbxjLO5x+Hua8W8S/G26uJnt9CjS3hHAnmGXb3A7VxfxI8dXPibXpY4pmWwhYrAmeAP731NchapHICDuDH+LOKycm9jVRS3O6sPiX4r028+3Ndtcrn5o3YsrD6Z/lXp3hn4y6bqxji1O2Nk7Y/eK25P8RXz2LORpWSCaQsqluenApbedoASxAL8AHjHqaSbWw2k9z7PimjuIllidXjcZVlOQRUteP8AwR8VyajZ3OjXMm4w/vYMn+HuPz5/GvYK1TujJqzCiiimIKKKKACiiigAooooAKKKKACiiigAooooAKKKKACiiigAooooAKKKKACiiigBK8++LXiuHQfCk9mjn7ber5aKvZf4iT24/nXoVfOHxiafU/G32KI71tYlVscgM3JJ/MflUTdkXTV5HmNpZzahdrFEpaWRsAV6r4Y+GVuUWXUZi0h52r0FYPg/T2sBNdyR72V9nHoK9C0vxnYef5BtbhcYBfadoz0zXHOcm7LY74U1GN3uTf8ACvtGt2kaNHPmLtbcc5rz7xt4LtrK3a4slY7OSp54r17UdbsbC2SW5cqr8rgZJ/CuN1TWtN1iFktGd9+VIIxU80k7opRUlZnFfBq+ez+IdjHnCTh4z/3yf8K+p6+aPAegyw+L9NvAWRYr8IF29Rnnn/Pevpeu2m01ocFWLi1cWiiitDIKKKKACiiigAooooAKKKKACiiigAooooAKKKKACiiigAooooAKKKKACiiigBDXj/jrw1Npl1qOtrH5sMoZpQo+8pO78CCB+Few1g+LLC61fw/daZZbVmul8vzH+7GuRkn8O1RON0XTlyyueLeDdQs5725jj3bPM+4/Vcjoa71tPtba2eSOMDcK4G38LyeE/Fl1p0plMcsayRTuuA7Drj867Ka/T+zRHcGQbhjdGpJB/CuCS5ZWPSg+eKZc+zxTXUSSqGIiG0kdPpWXqmnWGmQO8aKrY4OBx9KWzvVF4GlmuJG2bUDwsoA/LrVTXfNurec/M7BSI0Xu1J9i7Wdw+HN3Zajr1tbK6vLC0t2SvTpgD6/Nn8K9nryv4VeBrrRJH1XUR5dwylY4scgNgkn8hXqtd9KPLE8ytLmlcKKKK0MgooooAKKKKACiiigAooooAKKKKACiiigAooooAKKKKACiiigAooooAKKKKACiiigDhviXq2iaVoAl1NQ10c/ZVX7+7uQfQd64bw94l06/hVZZUI9Saq/HfVoLjUdP0+CW3laBHaXY+XRiRwfTp0rxyOae2l8y3laNvVTj9K5Ky5pHq4ak1ST7n0Nf6ppNnbmSOSMf7rVB4C1XS/EviO4tTK3n26ebGq8qwzg8+oyK8DuNQv7sbZ7mR19C3H5Cuq+Gepvo/jfTJVnWGKSURSu3Qq3BH8uaiEFGSbLqU5Om7H1gkaxrtUYFOpoIIBBBB7inV3HjhRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQAUUUUAJWBf+NPDmmMUutXtVcdUR97D8FzXL/FvxXPoWiR2NlJ5d1e5BcdVjHXH1zj86+ejMSMk81jUq8rsjuw2D9rHmk7I+gtV+M+gWasLK3ub1x0IXy1P4nn9K88174zeItURobBItNibgmL5nI/3j0/AV54059aiL5NYurJnfHA0o7IS6ke5kaSZi8jHJdjkk+9Vyjnpg/hVjIPWnZWoudfKrFMxSd1A/CpYlZGDdSOlTHBoyMUXBRSOu8O/ErxJ4cVIre6Fxaqf+Pe4G5QPY9R+FeqaD8btGvQserWk9hL0LoPMj/TkflXz4GqRZcVcakonLVwdOo77H1tY+LfD+psi2msWkjt0TzArH8DzW2MHoa+MxPgZB6V6/8IfHF1JfL4f1CVpUkBNs7nJRgM7c+hFawrXdmcFfA8keaLvY9vooorc4AooooAKKKKACiiigAooooAKKKKACiiigAooooAKKKKACiiigDwD44TF/FVtFniO0Xj0yzV5O2e1ekfGOQv47uVP8EMYH/fOf615u7KvWuGfxs+hwqtRiMopSBgEU3PNSdQ7oKaTTs8ZNMJoAXNGaSgCmAuaM0maOtACgnFdR4BnMHjTRnBx/pcY/M4/rXLjHStvwu5i8SaY46rdRH/x4ULcyqq8H6H2B2oo7UV3nzIUUUUAFFFFABRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQB85/GWEx+O5WI4kt42H5Y/pXmUy5zXr3xyjC+JrGQDlrPH5M1eRTDvXFPSbPoMI70YjIG3qRnpTivNR2YA3DPepiRmpe50U23EYRgUw1IxFRmgoKM0hpRQMcBmiTEQ3E8UqnFMuyDDjOM0LcmcuWLaEi559ea6bwdbm58XaRDjO67i/9CFczFwAK7j4aIJPH+jAjOJs/kpNNfEjKq7Um/I+pu1FFFdx82FFFFABRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQAUUUUAeF/HVf+J3pZ9bZh/49Xjsw4r2T47Ef2vpQ/wCnd/8A0KvHJRmuKp8bPfwX8GJSTcjlh0zU+4tzitW70/yvDGl3g58+adSf90r/AI1mkYFKRvS1QwmkJBoYc02kagaBRSigBQ2Oab5M10ksqKTHDgufQE4H6mnsPlrrfCtir+DfF12ygiO3hQEjuZQf/ZaqJhXdl935nJxpiu4+F/8AyUPSB/00b/0E1xROK7X4WDd8Q9I/32P/AI41KPxIMR/Cl6H1FRRRXcfNhRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQAUUUUAFFFFAHgvx1mH/AAkGnR5GVtc49Msf8K8jZs12vxW1M6j47vjnKW5EC/8AAev65rhc/NXFPWTZ9FhY8tKKPRdf0pYPg34auwBuN1MT/wADJ/8AiRXnzCvTvEV2v/Cj/DUDffe6fb9FL5/mK8xbtRPdBhb2lfu/zIyKZTzTTUnSJTlpvenLQA8/dr0rwbahvhD4xmIGGaID/gJB/rXmw5FepeHR5HwK8QuDzJdqp+mUqobnLi/hXqvzPK5D81d18J2A+IWk57lwP++GrhJDlzXUfD6+XT/GukzyfdW5UE+zfL/WlHRo0rrmpSXkfWdFFFdx80FFFFABRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQAUh4FLTX+430oA+P/EtwbnxBqE5OS9xI35saxRyav6qf+JjP7u386i022a91K2tUGWmlWMfUnFcB9NH3aZ2/jRGs/BPg7TmBDfZpLlh/vtkfpXBP1rrPH+tz6nr7W7rB5Omg2cHk5wURiAee9cezMTyv605avQWHTjTV93r94Gm0pNIBSNg6GnA0mD3oFAXJlxXqvhOP7f8ABXxNaIMvBMJsewCn/wBlNeUKcGvT/hDrFpFfahoV2SI9Wi8pOMjfgjB+oJqofFY5cWr0+ZdLM8tYYc1b0+Uw3kUinlWDD8DRqVo9lqNxaycPDI0bfUHFR23+uWpNtHA+zraTzraKT++gb8xU5qlpBJ0axJ6m3j/9BFXTXej5l7hRRRQIKKKKACiiigAooooAKKKKACiiigAooooAKKKKACmnlSPanUHpQB8aa0uzVblfSVh+pqrZzyWl5FNEzLIh3KynBU9j+dXtf51y94/5eJP/AEI1mID5hOeMVwH08NYIkmlLEkkknqTVckmpGPPamZ+n5UIsQCnim04ZPQZoEJ+FJxQQw6gim49zQMerYNa2h6lJper2d9F9+3mWQfgc1j1PC3NDJkrqzOl+IcSJ421N4v8AVTyC4T3DqG/rXOWozMtbPiK4F9baTeAHcbMQSE92jJX/ANB21kWQH2lM9MinLciF1Ss+n6H2Tpq7NMtE/uwoP/HRVqobfH2aLHTYMflU1dx81LcKKKKACiiigAooooAKKKKACiiigAooooAKKKKACiiigAprZ2nHXFOqOWRYonkdgqKpZiewFAHxvq5Y6ncl87jKxP1yaopu3NgDHvV3VpFm1K5kU5V5GYH2JNVoY3kB2KW+grzz6imm4qxAxOe1Nw3qPyqw1rODzBJ/3zTPJkHWN/8AvmncpxZHg+o/KnKo7/yp3lt/cf8AKlEbA/cb8qLi5RpHoSPxppB/vGpSh/un8qYVI7H8qAsR/N/eNPQuDwR+VJjHr+VOU8+9AWNOS7WXw9DbNE4lt7p234+Xa6rxn1yhqlb/AOv4pftEqwPb/wDLKRldh7jIH8zTYOJR7UCcbRZ9m2OfsFtnr5S5/IVZNU9LbdpVm3rAh/8AHRVw13o+Ye4UUUUCCiiigAooooAKKKKACiiigAooooAKKKKACiiigAFVb6PzbC4j2B98TLtPfIPFWhVTUiV0y6KyeWwich8Z28HmhjW58cXSlJnVuCrEEVb0nB3jvnNU7o5kPOSSSTU2mnE2PavOlsfXYTdHQKBil25pE5FPNc56RGyVE4qcnimMMigaGYpdvsKdigZpiG7R6A/hUckMZHMan8KnAqKVsChByoxb+KOMDYqqc9qrQ8yfhVi/fLiq9ty4z0zzW8djzcVZNpH2RpH/ACBrH/r3j/8AQRV41S0tVXSrNVLMogQAsMEjaOtXTXoI+Re4UUUUxBRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQAlYPjFpk8Iap9n/wBY0DID6buCfyNb1MkRZEZHUMjDBUjIIpNXVhxdmmfMl74FiTS4r1b93Z3RXVUGAGIGevvWTq+g/wDCP6xHbLOZ0eMOrlcfhXrOraWlpeanoxG1SwntgD2zkAfjxXB+PhDDrenxI2WEG5h6ZNcMlZWPpMBVcqi13MyIfLUhFRxdBUtcp7jGECmsvFOOaG6UAJim4p1JnmgYY4qvOMA5NWCcCs+5l600CMe7OZiOtNtwyvnBx9K67wIsba3dTvGJPLhwARnGT1/Su10ywFzoEVvBarLNeTOEVkHOWPP0xXSloeLjK1ps9k0idbnRrGdSCJLeNgR3yoq7VHR7E6Zo9nZEhjBCsZI6cCr1dy2PmHuLRRRTEFFFFABRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQB8+/FTxBc6X8R28slo0towUzjsTkeh5rPM+n+LbF5miQ36ofLlUhXyBnaw7iqvxc/f/EW/wDRVjX8kFcrbWsce1xneOQQcVw1JK7PqcLhm6cJRdnZGzAf3a561KTUMX3QKmxXIz2Bcimt0oNNY0AKaTikLUm6gY2U/KaybpiMgd61JDkVUErW11HcJGkjxMHVH6Ej1q4ibsjp/CWmT6AlzfapNDaw3MW3a7DeB1zjtXcfDfxHY6x4smsrVd0VrZnyXYdMMAcfga8M1XUL7UbhpLtyTnhBwo+gruPgnN5Hj+NScCa3kT9M/wBK64fEjwMXSlKE5S3sfTFFFFdZ86FFFFABRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQAUUUHpQB8x/ENhP441V+uJyv5AD+lc5FwQK2PF0nm+KNTkznN1J/6Eaxojk8GvMk7tn3WGjy0oryX5GhGal3YFQxdKmK8c1izcTcD3pjNSkYqNulAx55pPpSDmnUANfhapSMMmrr4281QkO5jiqQFeSNXHzDmuo+GpFn470pxxum2fmCP61zLVteF5TD4k0yUHBW6jP/AI8K1i7NHLiYc1KS8n+R9WUUDpRXpHw4UUUUAFFFFABRRRQAUUUUAf/Z我们已准备好测试用的中英文数据,通过下列示例中的shell脚本即可自动下载。
CLIP文图检索微调与测试示例
我们提供了CLIP使用示例,位于EasyNLP/examples/clip_retrieval
中文示例
# 中文训练,执行如下脚本时所需的数据文件会自动下载
sh run_clip_local.sh 0 train_cn #其中0代表所要使用的显卡编号
# 我们提供两种中文权重
# alibaba-pai/clip_chinese_roberta_base_vit_base
# alibaba-pai/clip_chinese_roberta_base_vit_large
# 对应的命令如下,源码细节请查看run_clip_local.sh文件
# easynlp \
# --mode train \
# --worker_gpu=1 \
# --tables=./MUGE_MR_train_base64_part.tsv,./MUGE_MR_valid_base64_part.tsv \
# --input_schema=text:str:1,image:str:1 \
# --first_sequence=text \
# --second_sequence=image \
# --checkpoint_dir=./clip_cn_model/ \
# --learning_rate=1e-6 \
# --epoch_num=1 \
# --random_seed=42 \
# --logging_steps=100 \
# --save_checkpoint_steps 200 \
# --sequence_length=32 \
# --micro_batch_size=32 \
# --app_name=clip \
# --save_all_checkpoints \
# --user_defined_parameters='pretrain_model_name_or_path=alibaba-pai/clip_chinese_roberta_base_vit_base' # 中文测试
sh run_clip_local.sh 0 evaluate_cn# 生成离线文图特征示例
sh run_clip_local.sh 0 predict_cn_text
sh run_clip_local.sh 0 predict_cn_image英文数据
# 英文训练
# 英文同样提供两种尺寸的权重
# alibaba-pai/pai-clip-commercial-base-en
# alibaba-pai/pai-clip-commercial-large-en
sh run_clip_local.sh 0 train_en
# easynlp \
# --mode train \
# --worker_gpu=1 \
# --tables=./fashiongen_1to1_train.tsv,./fashiongen_1to1_test.tsv \
# --input_schema=text:str:1,image:str:1 \
# --first_sequence=text \
# --second_sequence=image \
# --checkpoint_dir=./clip_en_model/ \
# --learning_rate=1e-6 \
# --epoch_num=1 \
# --random_seed=42 \
# --logging_steps=100 \
# --save_checkpoint_steps 200 \
# --sequence_length=32 \
# --micro_batch_size=32 \
# --app_name=clip \
# --save_all_checkpoints \
# --user_defined_parameters='pretrain_model_name_or_path=alibaba-pai/pai-clip-commercial-base-en' # 英文测试
sh run_clip_local.sh 0 evaluate_en未来展望
在未来,我们计划在EasyNLP框架中集成更多NLP的多模态的知识模型,覆盖各个常见领域和任务,敬请期待。我们也将在EasyNLP框架中集成更多SOTA模型(特别是中⽂模型),来⽀持各种NLP和多模态任务。此外, 阿⾥云机器学习PAI团队也在持续推进多模态模型的⾃研⼯作,欢迎⽤户持续关注我们,也欢迎加⼊ 我们的开源社区,共建NLP和多模态算法库!
Github地址:https://github.com/alibaba/EasyNLP
Reference
- Wang C, Qiu M, Zhang T, et al. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. arXiv, 2021.
- Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision. PMLR, 2021.
- Rostamzadeh N, Hosseini S, Boquet T, et al. Fashion-gen: The generative fashion dataset and challenge. arXiv, 2018.
- Gao D, Jin L, Chen B, et al. Fashionbert: Text and image matching with adaptive loss for cross-modal retrieval. ACM SIGIR, 2020: 2251-2260.
- Zhuge M, Gao D, Fan D P, et al. Kaleido-bert: Vision-language pre-training on fashion domain. CVPR, 2021: 12647-12657.
- Yu L, Chen J, Sinha A, et al. Commercemm: Large-scale commerce multimodal representation learning with omni retrieval. ACM SIGKDD, 2022: 4433-4442.
- Ma H, Zhao H, Lin Z, et al. EI-CLIP: Entity-Aware Interventional Contrastive Learning for E-Commerce Cross-Modal Retrieval. CVPR, 2022: 18051-18061.
- Li Y, Liang F, Zhao L, et al. Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. ICLR 2022.
作者:熊兮、欢夏、章捷、临在
原文链接
本文为阿里云原创内容,未经允许不得转载

)



)

)

)

)
)

)
)


)
