面试官很喜欢让求职者写一些常用库函数的实现,有很多是和字符串相关的,有一些是关于内存拷贝的。一般,常会让写的函数有以下几个:
strcpy , strncpy, memcpy。
memset一般不会让去写,但这个函数也很有特点,有很多容易用错的地方。一并总结吧。
1. strcpy
strcpy函数的原型是:
char * strcpy(char* dest, const char* src)
strcpy的实现经常要注意的细节是:
(1)判断地址是否为空,个人感觉可以使用断言
(2)参数只有两个地址,没有拷贝的长度。拷贝到'\0‘时就会终止,要保证最终dest末尾是'\0'。
(3)要保证目标字串的长度足够,能够容纳原串的长度。
(4)因为拷贝是dest会移动,而最终要返回的是拷贝后字符串的起始地址,因此要先保存dest的地址,便于最终返回。
在实现这一点时,有两种方法。 char* temp=dest; 拷贝时移动dest返回temp,或者拷贝时移动temp返回dest,不知道哪个是对的。感觉两个都是没有问题的
其中一种实现方式:
- char* mystrcpy(char* dest,const char* src)
- {
- assert(dest!=NULL && src!=NULL);
- char* temp=dest;
- while((*temp++ = *src++ )!='\0')
- {}
- return dest;
- }
2. strncpy
strncpy的功能和strcpy相似,只是它复制时多了一个终止条件。即是未遇到原串的'\0’,如果已经复制了n个字符(n为提供的参数长度),复制同样会终止。
strcpy的实现要注意的细节也基本适用于strncpy的实现。
实现方式:
- char* mystrncpy(char* dest, const char* src, int len)
- {
- assert(dest!=NULL && src!=NULL);
- char* temp=dest;
- int i=0;
- while(i++ < len && (*temp++ = *src++)!='\0')
- {}
- if(*(temp)!='\0')
- *temp='\0';
- return dest;
- }
3. memcpy
memcpy和strncpy有些类似,但也有本质的不同。
(1)strncpy只能复制字符串,但memcpy对类型没有要求。
(2)strncpy有两个终止条件,memcpy只有一个终止条件,那就是复制n个字节。(n是memcpy的第三个参数)
(3)要特别注意目的地址和源地址重合的问题,拷贝前要加以判断。
(4)实现这个函数时一般要把原来的指针类型转换成char*,这样每次移动都是一个字节。
实现方式:(考虑了两个地址空间是否会有重叠)
- void* mymemcpy(void* dest, void* src, int len)
- {
- int i=0;
- char* tempdest=(char*)dest;
- char* tempsrc=(char*)src;
- if(tempdest<tempsrc || tempdest>(tempsrc+len-1))
- {
- while(i<len)
- {
- *tempdest++ = *tempsrc++;
- i++;
- }
- }
- else
- {
- tempdest+=len;
- tempsrc+=len;
- i=len;
- while(i>0)
- {
- *tempdest-- = *tempsrc--;
- i--;
- }
- }
- return dest;
- }
注意,memcpy是对内存的拷贝,对其他安全性不做考虑。用户在使用这个函数时要小心,比如用它来拷贝字符串(当然如果是字符串拷贝肯定是用strncpy)就要注意末尾的\0字符之类的。
4. memset
memset函数的原型是:
void *memset(void *s, int ch,size_t n)
作用是把s所指向的地址开始的n个字节的内容全部置位ch所指定的ASCII值。
一般经常用memset对某段内存空间置零。
经常会出现的一个问题:在C++中,为什么不提倡在构造函数中使用:memset(this,0,sizeof(*this))
原因: 在C++中,如果类中都是基本类型的数据成员并且没有虚函数和虚继承的话,使用memset这样用到没有太多影响。
如果有虚函数,memset会把虚表指针等全部置零,对类会产生破坏。
三个函数的原型如下:
- void* memset(void *des, int val, size_t size)
- void * memcpy(void *des, const void* src, size_t size)
- void * memmove(void *des, const void *src, size_t size)
实现如下:
- void* memset(void *des, int val, size_t size) {
- void *start = des;
- while (size--) {
- *(char*) des = (char) val;
- des = (char *) des + 1;
- // (char*) des++;
- // des = (char* )des + 1;
- }
- return start;
- }
- void * memcpy(void *des, const void* src, size_t size) {
- void *ret = des;
- while (size--) {
- *(char *) des = *(char *) src;
- des = (char *)des + 1;
- src = (char *)src + 1;
- // (char *) des++;
- // (char *) src++;
- }
- return ret;
- }
- void * memmove(void *des, const void *src, size_t size) {
- void *ret = des;
- if (des < src || (char *) des > (char *) src + size - 1) {
- while (size--) {
- *(char *) des = *(char *) src;
- des = (char *) des + 1;
- src = (char *)src + 1;
- // (char *) src++;
- // (chr *) des ++;
- }
- }else{
- des = (char *)des + size - 1;
- src = (char *)src + size - 1;
- while (size -- > 0){
- *(char *) des = *(char *) src;
- // (char *) des--;
- // (char *) src--;
- des = (char *)des - 1;
- src = (char *)src - 1;
- }
- }
- return ret;
- }
不采用//中的写法是因为包报出警告:warning: value computed is not used
看起来不爽。
注意事项:
(1)使用memset的时候,要把最后一位或者最后一位的下一位置为‘\0’;
- char buffer[20] = "hello";
- memset(buffer, '1', sizeof(char)*20);
- printf("%s\n",buffer);
- 运行结果:111111111111111111110@
- char buffer[20] = "hello";
- memset(buffer, '1', sizeof(char)*20);
- buffer[20] = '\0';
- printf("%s\n",buffer);
- 运行结果:11111111111111111111
因为在prinf一个字符串的时候,printf函数是遇见‘\0就停止。想第一个例子中的,buffer[20]都是‘1’,结束没有‘\0’,所以打印出来的结果就不确定。当然,也有可能是对的,那只是运气好而已。
(2)memcpy和strcpy的区别:
实际上区别只有一个,strcpy的操作对象只能是char *,而memcpy操作的对象是void *。(什么类型的都可以)。实际上,在memcpy的实现上,都是将(void *)装换成为了(char *)来做的,其实跟strcpy一样。
(3)memmove和memcpy的区别:
区别就是memmove要考虑内存区间重叠的情况,而memcpy不会。
关于这个问题,可以用下面的图片来解释:
内存区间重叠的情况如下和不会出现内存区间重叠的情况:

假设des为src + 2,如果按照memcpy处理,从头开始拷贝,就要出现下面的悲剧:
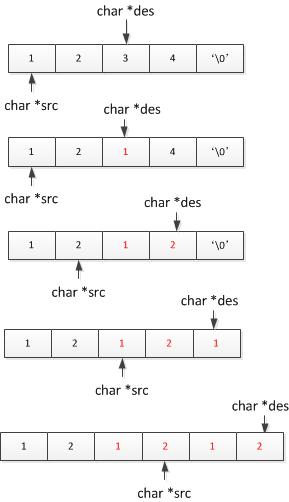
src的内存都被污染了,而且如果这时候打印*des开头的内存,仍然会出现未定义的情况:因为'\0'被覆盖了。
- char buffer5[10] = "1234";
- memcpy(buffer5 + 2, buffer5, sizeof(buffer5));
- printf("%s\n", buffer5);
- char buffer6[10] = "1234";
- memmove(buffer6 + 2, buffer6, sizeof(buffer6));
- printf("%s\n",buffer6 + 2);
121212121212????"
1234