场景:
在spark分析数据时,创建hive表失败。
提示异常 :
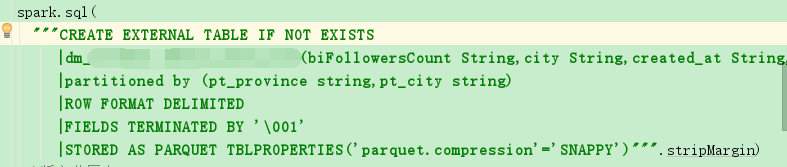
19/10/09 10:59:18 INFO execution.SparkSqlParser: Parsing command: CREATE EXTERNAL TABLE IF NOT EXISTS
dm_xxx.user_area(biFollowersCount String,city String,created_at String,description String,experience String,followers_count String,friends_count String,name String,profileImageUrl String,province String,statuses_count String,uid String,url String,verified String,verified_reason String,verified_type String,verified_type_ext String)
partitioned by (pt_province string,pt_city string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY')
Exception in thread "main" org.apache.spark.sql.catalyst.parser.ParseException:
Operation not allowed: ROW FORMAT DELIMITED is only compatible with 'textfile', not 'parquet'(line 1, pos 0)== SQL ==
CREATE EXTERNAL TABLE IF NOT EXISTS
^^^
dm_xxx.user_area(biFollowersCount String,city String,created_at String,description String,experience String,followers_count String,friends_count String,name String,profileImageUrl String,province String,statuses_count String,uid String,url String,verified String,verified_reason String,verified_type String,verified_type_ext String)
partitioned by (pt_province string,pt_city string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY')at org.apache.spark.sql.catalyst.parser.ParserUtils$.operationNotAllowed(ParserUtils.scala:39)at org.apache.spark.sql.execution.SparkSqlAstBuilder.org$apache$spark$sql$execution$SparkSqlAstBuilder$$validateRowFormatFileFormat(SparkSqlParser.scala:1320)at org.apache.spark.sql.execution.SparkSqlAstBuilder$$anonfun$visitCreateHiveTable$1.apply(SparkSqlParser.scala:1089)at org.apache.spark.sql.execution.SparkSqlAstBuilder$$anonfun$visitCreateHiveTable$1.apply(SparkSqlParser.scala:1064)at org.apache.spark.sql.catalyst.parser.ParserUtils$.withOrigin(ParserUtils.scala:99)at org.apache.spark.sql.execution.SparkSqlAstBuilder.visitCreateHiveTable(SparkSqlParser.scala:1064)at org.apache.spark.sql.execution.SparkSqlAstBuilder.visitCreateHiveTable(SparkSqlParser.scala:55)at org.apache.spark.sql.catalyst.parser.SqlBaseParser$CreateHiveTableContext.accept(SqlBaseParser.java:1121)at org.antlr.v4.runtime.tree.AbstractParseTreeVisitor.visit(AbstractParseTreeVisitor.java:42)at org.apache.spark.sql.catalyst.parser.AstBuilder$$anonfun$visitSingleStatement$1.apply(AstBuilder.scala:71)at org.apache.spark.sql.catalyst.parser.AstBuilder$$anonfun$visitSingleStatement$1.apply(AstBuilder.scala:71)at org.apache.spark.sql.catalyst.parser.ParserUtils$.withOrigin(ParserUtils.scala:99)at org.apache.spark.sql.catalyst.parser.AstBuilder.visitSingleStatement(AstBuilder.scala:70)at org.apache.spark.sql.catalyst.parser.AbstractSqlParser$$anonfun$parsePlan$1.apply(ParseDriver.scala:69)at org.apache.spark.sql.catalyst.parser.AbstractSqlParser$$anonfun$parsePlan$1.apply(ParseDriver.scala:68)at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:97)at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48)at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:68)at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:632)at com.izhonghong.data.filter.weibo.WeiBoAccountArea$.main(WeiBoAccountArea.scala:93)at com.izhonghong.data.filter.weibo.WeiBoAccountArea.main(WeiBoAccountArea.scala)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:775)at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:119)at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
原因:
spark 不为 parquet文件提供DELIMITERS。
参考:
https://issues.apache.org/jira/browse/SPARK-15279