sklearn是利用python进行机器学习中一个非常全面和好用的第三方库,用过的都说好。今天主要记录一下sklearn中关于交叉验证的各种用法,主要是对sklearn官方文档 Cross-validation: evaluating estimator performance进行讲解,英文水平好的建议读官方文档,里面的知识点很详细。
先导入需要的库及数据集
In [1]: import numpy as npIn [2]: from sklearn.model_selection import train_test_splitIn [3]: from sklearn.datasets import load_irisIn [4]: from sklearn import svmIn [5]: iris = load_iris()In [6]: iris.data.shape, iris.target.shape
Out[6]: ((150, 4), (150,))
1.train_test_split
对数据集进行快速打乱(分为训练集和测试集)
这里相当于对数据集进行了shuffle后按照给定的test_size 进行数据集划分。
In [7]: X_train, X_test, y_train, y_test = train_test_split(...: iris.data, iris.target, test_size=.4, random_state=0)#这里是按照6:4对训练集测试集进行划分In [8]: X_train.shape, y_train.shape
Out[8]: ((90, 4), (90,))In [9]: X_test.shape, y_test.shape
Out[9]: ((60, 4), (60,))In [10]: iris.data[:5]
Out[10]:
array([[ 5.1, 3.5, 1.4, 0.2],[ 4.9, 3. , 1.4, 0.2],[ 4.7, 3.2, 1.3, 0.2],[ 4.6, 3.1, 1.5, 0.2],[ 5. , 3.6, 1.4, 0.2]])In [11]: X_train[:5]
Out[11]:
array([[ 6. , 3.4, 4.5, 1.6],[ 4.8, 3.1, 1.6, 0.2],[ 5.8, 2.7, 5.1, 1.9],[ 5.6, 2.7, 4.2, 1.3],[ 5.6, 2.9, 3.6, 1.3]])In [12]: clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train)In [13]: clf.score(X_test, y_test)
Out[13]: 0.96666666666666667
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.cross_val_score
对数据集进行指定次数的交叉验证并为每次验证效果评测
其中,score 默认是以 scoring=’f1_macro’进行评测的,余外针对分类或回归还有:
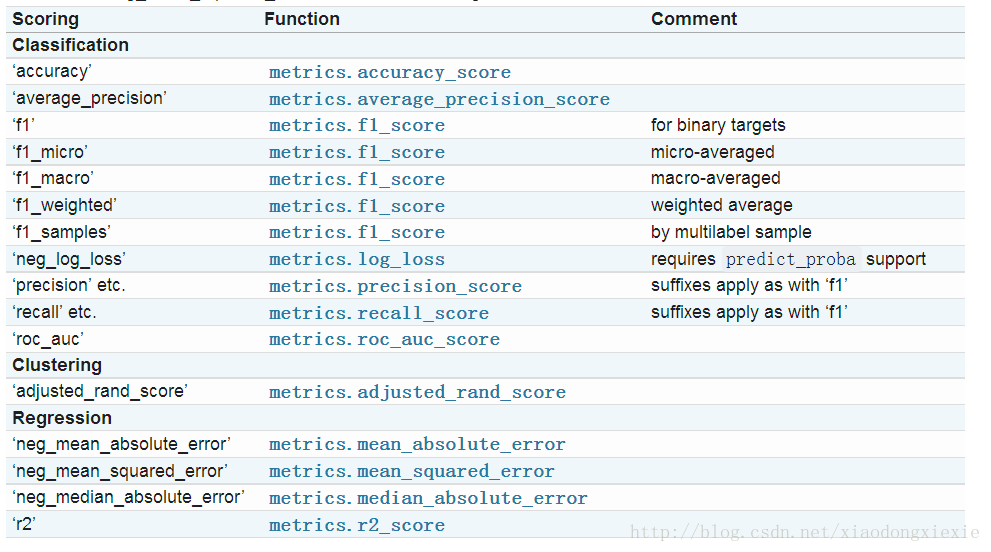
这需要from sklearn import metrics ,通过在cross_val_score 指定参数来设定评测标准;
当cv 指定为int 类型时,默认使用KFold 或StratifiedKFold 进行数据集打乱,下面会对KFold和StratifiedKFold 进行介绍。
In [15]: from sklearn.model_selection import cross_val_scoreIn [16]: clf = svm.SVC(kernel='linear', C=1)In [17]: scores = cross_val_score(clf, iris.data, iris.target, cv=5)In [18]: scores
Out[18]: array([ 0.96666667, 1. , 0.96666667, 0.96666667, 1. ])In [19]: scores.mean()
Out[19]: 0.98000000000000009
除使用默认交叉验证方式外,可以对交叉验证方式进行指定,如验证次数,训练集测试集划分比例等
In [20]: from sklearn.model_selection import ShuffleSplitIn [21]: n_samples = iris.data.shape[0]In [22]: cv = ShuffleSplit(n_splits=3, test_size=.3, random_state=0)In [23]: cross_val_score(clf, iris.data, iris.target, cv=cv)
Out[23]: array([ 0.97777778, 0.97777778, 1. ])
在cross_val_score 中同样可使用pipeline 进行流水线操作
In [24]: from sklearn import preprocessingIn [25]: from sklearn.pipeline import make_pipelineIn [26]: clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(C=1))In [27]: cross_val_score(clf, iris.data, iris.target, cv=cv)
Out[27]: array([ 0.97777778, 0.93333333, 0.95555556])
3.cross_val_predict
cross_val_predict 与cross_val_score 很相像,不过不同于返回的是评测效果,cross_val_predict 返回的是estimator 的分类结果(或回归值),这个对于后期模型的改善很重要,可以通过该预测输出对比实际目标值,准确定位到预测出错的地方,为我们参数优化及问题排查十分的重要。
In [28]: from sklearn.model_selection import cross_val_predictIn [29]: from sklearn import metricsIn [30]: predicted = cross_val_predict(clf, iris.data, iris.target, cv=10)In [31]: predicted
Out[31]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2,2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2,2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])In [32]: metrics.accuracy_score(iris.target, predicted)
Out[32]: 0.96666666666666667
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.KFold
K折交叉验证,这是将数据集分成K份的官方给定方案,所谓K折就是将数据集通过K次分割,使得所有数据既在训练集出现过,又在测试集出现过,当然,每次分割中不会有重叠。相当于无放回抽样。
In [33]: from sklearn.model_selection import KFoldIn [34]: X = ['a','b','c','d']In [35]: kf = KFold(n_splits=2)In [36]: for train, test in kf.split(X):...: print train, test...: print np.array(X)[train], np.array(X)[test]...: print '\n'...:
[2 3] [0 1]
['c' 'd'] ['a' 'b'][0 1] [2 3]
['a' 'b'] ['c' 'd']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
5.LeaveOneOut
LeaveOneOut 其实就是KFold 的一个特例,因为使用次数比较多,因此独立的定义出来,完全可以通过KFold 实现。
In [37]: from sklearn.model_selection import LeaveOneOutIn [38]: X = [1,2,3,4]In [39]: loo = LeaveOneOut()In [41]: for train, test in loo.split(X):...: print train, test...:
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
In [42]: kf = KFold(n_splits=len(X))In [43]: for train, test in kf.split(X):...: print train, test...:
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
6.LeavePOut
这个也是KFold 的一个特例,用KFold 实现起来稍麻烦些,跟LeaveOneOut 也很像。
In [44]: from sklearn.model_selection import LeavePOutIn [45]: X = np.ones(4)In [46]: lpo = LeavePOut(p=2)In [47]: for train, test in lpo.split(X):...: print train, test...:
[2 3] [0 1]
[1 3] [0 2]
[1 2] [0 3]
[0 3] [1 2]
[0 2] [1 3]
[0 1] [2 3]
7.ShuffleSplit
ShuffleSplit 咋一看用法跟LeavePOut 很像,其实两者完全不一样,LeavePOut 是使得数据集经过数次分割后,所有的测试集出现的元素的集合即是完整的数据集,即无放回的抽样,而ShuffleSplit 则是有放回的抽样,只能说经过一个足够大的抽样次数后,保证测试集出现了完成的数据集的倍数。
In [48]: from sklearn.model_selection import ShuffleSplitIn [49]: X = np.arange(5)In [50]: ss = ShuffleSplit(n_splits=3, test_size=.25, random_state=0)In [51]: for train_index, test_index in ss.split(X):...: print train_index, test_index...:
[1 3 4] [2 0]
[1 4 3] [0 2]
[4 0 2] [1 3]
8.StratifiedKFold
这个就比较好玩了,通过指定分组,对测试集进行无放回抽样。
In [52]: from sklearn.model_selection import StratifiedKFoldIn [53]: X = np.ones(10)In [54]: y = [0,0,0,0,1,1,1,1,1,1]In [55]: skf = StratifiedKFold(n_splits=3)In [56]: for train, test in skf.split(X,y):...: print train, test...:
[2 3 6 7 8 9] [0 1 4 5]
[0 1 3 4 5 8 9] [2 6 7]
[0 1 2 4 5 6 7] [3 8 9]
9.GroupKFold
这个跟StratifiedKFold 比较像,不过测试集是按照一定分组进行打乱的,即先分堆,然后把这些堆打乱,每个堆里的顺序还是固定不变的。
In [57]: from sklearn.model_selection import GroupKFoldIn [58]: X = [.1, .2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]In [59]: y = ['a','b','b','b','c','c','c','d','d','d']In [60]: groups = [1,1,1,2,2,2,3,3,3,3]In [61]: gkf = GroupKFold(n_splits=3)In [62]: for train, test in gkf.split(X,y,groups=groups):...: print train, test...:
[0 1 2 3 4 5] [6 7 8 9]
[0 1 2 6 7 8 9] [3 4 5]
[3 4 5 6 7 8 9] [0 1 2]
10.LeaveOneGroupOut
这个是在GroupKFold 上的基础上混乱度又减小了,按照给定的分组方式将测试集分割下来。
In [63]: from sklearn.model_selection import LeaveOneGroupOutIn [64]: X = [1, 5, 10, 50, 60, 70, 80]In [65]: y = [0, 1, 1, 2, 2, 2, 2]In [66]: groups = [1, 1, 2, 2, 3, 3, 3]In [67]: logo = LeaveOneGroupOut()In [68]: for train, test in logo.split(X, y, groups=groups):...: print train, test...:
[2 3 4 5 6] [0 1]
[0 1 4 5 6] [2 3]
[0 1 2 3] [4 5 6]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
11.LeavePGroupsOut
这个没啥可说的,跟上面那个一样,只是一个是单组,一个是多组
from sklearn.model_selection import LeavePGroupsOutX = np.arange(6)y = [1, 1, 1, 2, 2, 2]groups = [1, 1, 2, 2, 3, 3]lpgo = LeavePGroupsOut(n_groups=2)for train, test in lpgo.split(X, y, groups=groups):print train, test[4 5] [0 1 2 3]
[2 3] [0 1 4 5]
[0 1] [2 3 4 5]
12.GroupShuffleSplit
这个是有放回抽样
In [75]: from sklearn.model_selection import GroupShuffleSplitIn [76]: X = [.1, .2, 2.2, 2.4, 2.3, 4.55, 5.8, .001]In [77]: y = ['a', 'b','b', 'b', 'c','c', 'c', 'a']In [78]: groups = [1,1,2,2,3,3,4,4]In [79]: gss = GroupShuffleSplit(n_splits=4, test_size=.5, random_state=0)In [80]: for train, test in gss.split(X, y, groups=groups):...: print train, test...:
[0 1 2 3] [4 5 6 7]
[2 3 6 7] [0 1 4 5]
[2 3 4 5] [0 1 6 7]
[4 5 6 7] [0 1 2 3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
13.TimeSeriesSplit
针对时间序列的处理,防止未来数据的使用,分割时是将数据进行从前到后切割(这个说法其实不太恰当,因为切割是延续性的。。)
In [81]: from sklearn.model_selection import TimeSeriesSplitIn [82]: X = np.array([[1,2],[3,4],[1,2],[3,4],[1,2],[3,4]])In [83]: tscv = TimeSeriesSplit(n_splits=3)In [84]: for train, test in tscv.split(X):...: print train, test...:
[0 1 2] [3]
[0 1 2 3] [4]
[0 1 2 3 4] [5]




 的基础)




})

模型})



})

})

