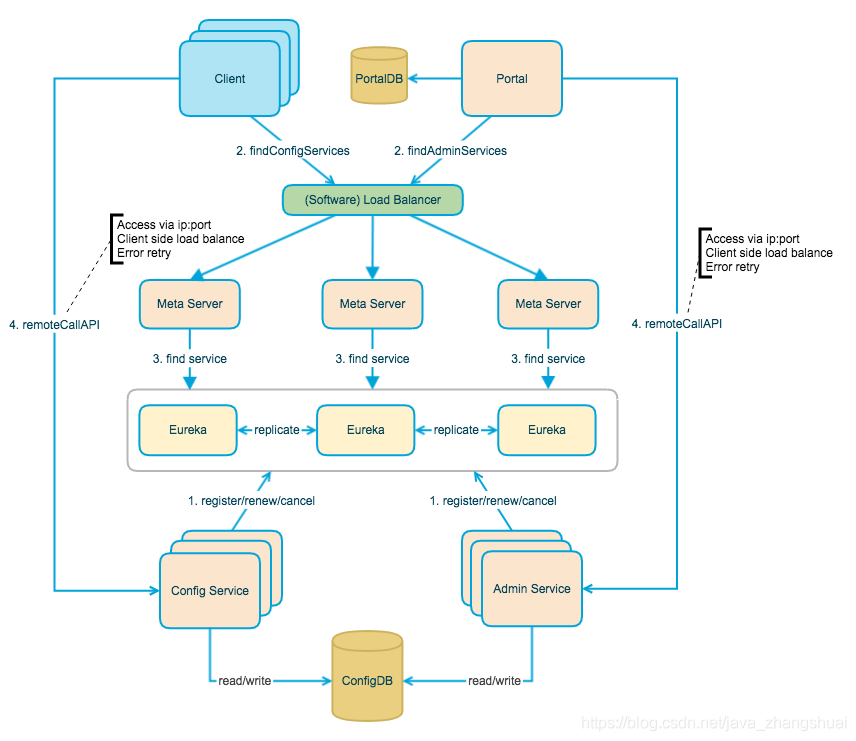
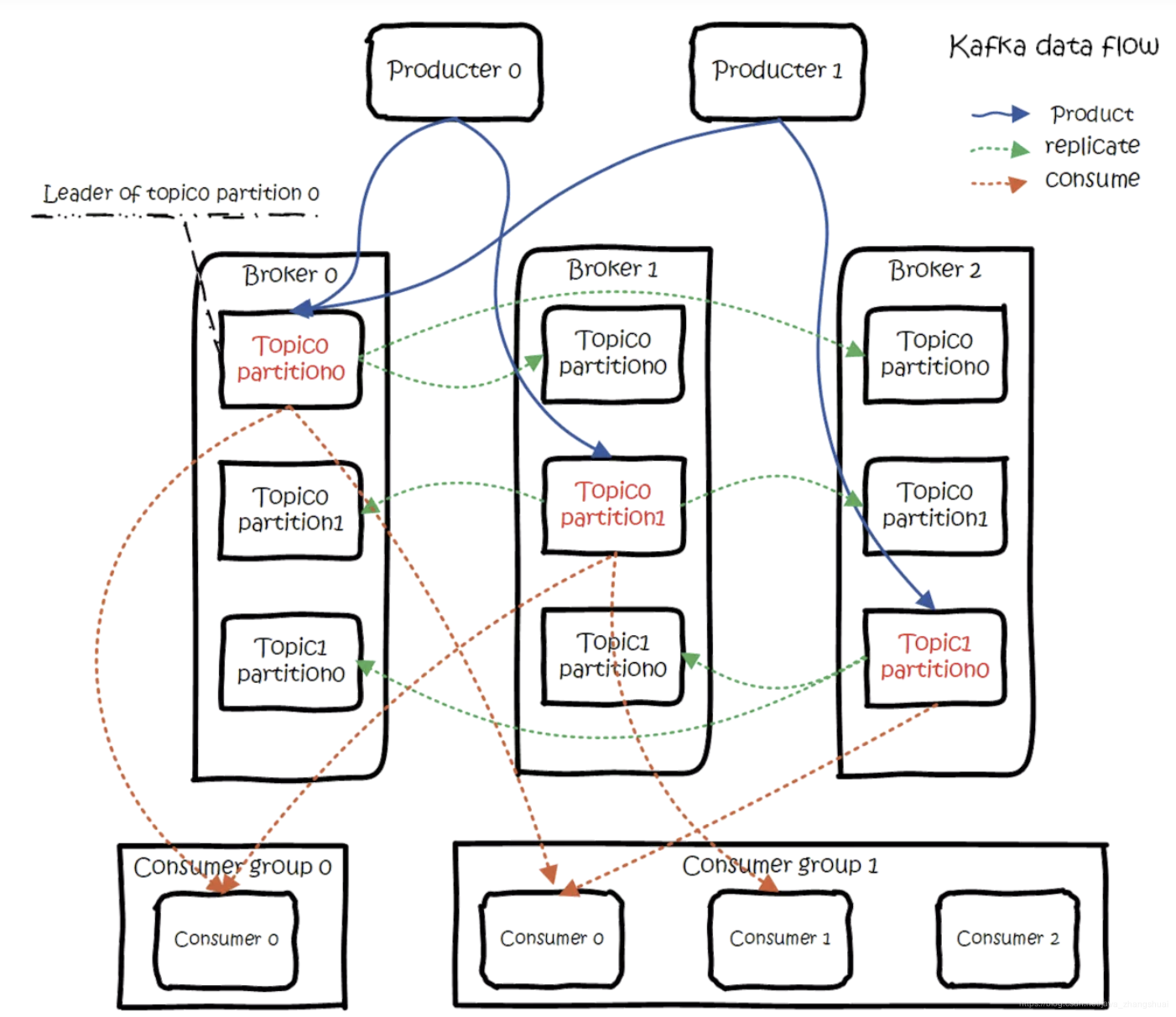
转自:http://www.cocoachina.com/cms/wap.php?action=article&id=22240。
一、概述:
1.工作量证明(Proof of Work):
通过所有节点的工作量竞争来达成一致。竞争的是运算力。
2.权益证明(Proof of Stake):
通过节点拥有代币数量的多少和时间,确定下一区块的创造者。竞争的是拥有代币的数量和时间。
3.委任权益证明(DPOS):
通过一定算法选取固定数量的代表投票来达成一致。如果某代表不能履行投票职责,会被除名,重新选择代表加入。
4.实用拜占庭容错共识(PBFT):
PBFT是一种基于严格数学证明的算法,需要经过三个阶段的信息交互和局部共识来达成最终的一致输出。
二、工作量证明(Proof of Work)
区块链共识算法中最常见的是比特币的工作量证明机制,它主要有两个功能:一是保证区块链的下一区块是唯一正确的块,二是防止强大的敌手干扰区块链系统从而导致区块链分叉。
工作量证明中,矿工通过竞争解决密码学难题来完成下一个块的增加和区块链的扩展,如图1所示为比特币工作量证明的简图;参与挖矿的矿工竞争将前一区块的hash与一个随机的比特串一起来计算出一个hash值,若输出的hash值满足前若干比特为0,即为解出了该难题。第一个解出难题的人获得扩展一个块的机会,并且能够获得一定量新挖出的比特币以及一小笔交易费作为其工作量的奖励。
尽管比特币的工作量证明机制是个非常杰出的共识设计,但并不是完美的。最常见的对工作量证明的质疑有两点:一是消耗算力巨大,不适合大规模系统,并且交易的确认时间需要10-16分钟,不能满足实时性需求;二是大多数挖矿活动集中在电力成本较低的区域,形成了局部中心化的趋势。
比特币的创造者Satoshi Nakamoto让人们初步认识到区块链改变未来世界的巨大潜力,但落实到具体应用,仍需要进一步探索更快速的、更加去中心化以及资源效率更高的共识算法。为此,许多互联网、计算机科学、金融、工业等行业的学者和业界人士进行了不断的探索,并提出了若干代替性的区块链共识方案,其中最有影响力的是权益证明(Proof of Stake)共识算法。

三、权益证明(Proof of Stake)
权益证明共识是代替工作量证明的共识机制中最完善和受到最多关注的,其共识的达成不需要参与者投入昂贵的计算机设备来参与挖矿竞争。相对于以比特币为代表的工作量证明共识系统中的矿工而言,基于权益证明共识的区块链系统中,参与者的角色是验证者Validator,他们只需要投资系统的代币并在特定时间内验证自己是否为下一区块创造者,即可完成下一区块的创建。如图2所示为权益证明的简要示意图。下一区块创造者是以某种确定的方式来选择,被选中的验证者将合适的交易打包成块并发布到区块链上。验证者被选中为下一区块创造者的概率与其所拥有的系统中代币的数量成正比例,简单来说即拥有300个代币的验证者被选中为下一区块创造者的概率是即拥有100个代币验证者的3倍。
由于权益证明中创造区块不需要算力资源等高成本,区块创造者不会获得区块奖励,但可以获得一定数额的交易打包费用。用权益证明共识产生区块和扩展区块链的方式也比比特币中用工作量证明的共识效率提高上千倍,并且大大节约了资源。
权益证明共识中一旦验证者创建了一个块,该块也需要提交到区块链上。不同的权益证明系统对提交过程的处理方式不同。
一个典型的例子是Tendermint,其系统中的每个节点都必须在每一个块上签名(在此过程中的角色称为“签名者”),直至达成了大多数节点对区块验证和记录到链上的共识;在其他一些系统中,选择一组随机的节点进行签名即可达成共识。
权益证明有效率高、节约资源的优点,但同时也面临着一些潜在的现实风险,业内研究者通常将其表述为nothing-at-stake问题,意即区块创造者和区块验证者完成各自的工作所投入的成本都极低,因而违背系统协议作恶的损失也很小。基于理性人的自利假设,参与者难免会出现做恶的情况,例如区块创造者同时创造2个块并收取两笔交易费,或者签名者同时签名2个块以获得2笔工作报酬。这些都与系统协议中同一时间段只能产生一个合法的区块且签名者不可对不合法的区块签名的规范相违背。
在新兴的“加密经济学”领域,区块链工程师们正在探索解决这些问题的方法。其中一个解决方案是要求验证者将其拥有的系统代币锁定在一种虚拟保险库中。如果验证者试图对系统进行双重签名或同时产生多个块进行分叉,那么这些代币就会被全部或部分罚没。类似的改进机制也在不同的采用权益证明的区块链系统被提出并进行了许多实践。
Peercoin是第一个将权益证明实现的代币,其次是blackcoin和NXT。此外,以太坊最早依赖于工作量证明共识,但正计划在2018年初迁移到权益证明,提出Casper试图解决工作量证明和权益证明中的问题。Decred采用的是工作量证明和权益证明的混合共识方案。

四、委任权益证明DPOS
DPOS是权益共识的一种改进版本,共识过程不再需要所有参与节点的大多数通过,而是委托部分代表来进行,这样可以进一步提高共识效率,也能较好地处理系统节点不在线的问题。在比特股(Bitshare)系统中采用的DPOS共识的原理是让每一个持有比特股的人进行投票,由此产生101位代表, 他们彼此的权利完全平等,可以将其理解为101个超级节点或者矿池。
从某种角度来看,DPOS与议会制度或人民代表大会制度有相似之处。如果代表不能履行他们的职责,例如当轮到他们产生区块时没能按时生成,他们会被除名,继而网络会选出新的超级节点来将其取代。采用DPOS共识的系统通常都会采用经济方面的奖励和惩罚机制来达成更稳定的共识。
五、实用拜占庭容错共识PBFT
PBFT是一种基于严格数学证明的算法,需要经过三个阶段的信息交互和局部共识来达成最终的一致输出。可以证明,系统中只要有三分之二以上比例的正常节点,就能保证最终一定可以输出一致的共识结果,尽管达成共识的时间不确定。
实用拜占庭容错协议的缺点在于不适用于大规模的节点共识,因为随着节点规模的增大,达成共识需要的时间大大增加,不符合效率需求。许多相关研究人员在探讨改进拜占庭协议,以解决不同应用场景下的效率问题。
六、总结
共识算法的性能直接影响着分布式系统的性能,例如安全性、鲁棒性、共识成本和效率等。如何在兼顾安全性和鲁棒性的基础上提高效率是一个需要持续讨论和研究的重点。目前关于区块链共识的各种研究也在根据具体应用场景做出多方面的改进,除了技术方案的改进之外,还需要结合经济和社会等因素寻找更加有针对性、更加完善的解决方案。
总的来说,对于区块链共识方案的研究为分布式系统中的一致性问题提供了较好的解决方案,目前已经有一些算法能较好地解决分布式系统中的共识等问题,在EUROCRYPT,ACM, Cryptology ePrint Archive等高水平会议、刊物上也有高质量的文章发表,对于上述问题进行了更深刻和前瞻性的探讨,但该领域仍然由许多问题有待解决,仍有很大的研究价值和发展空间。



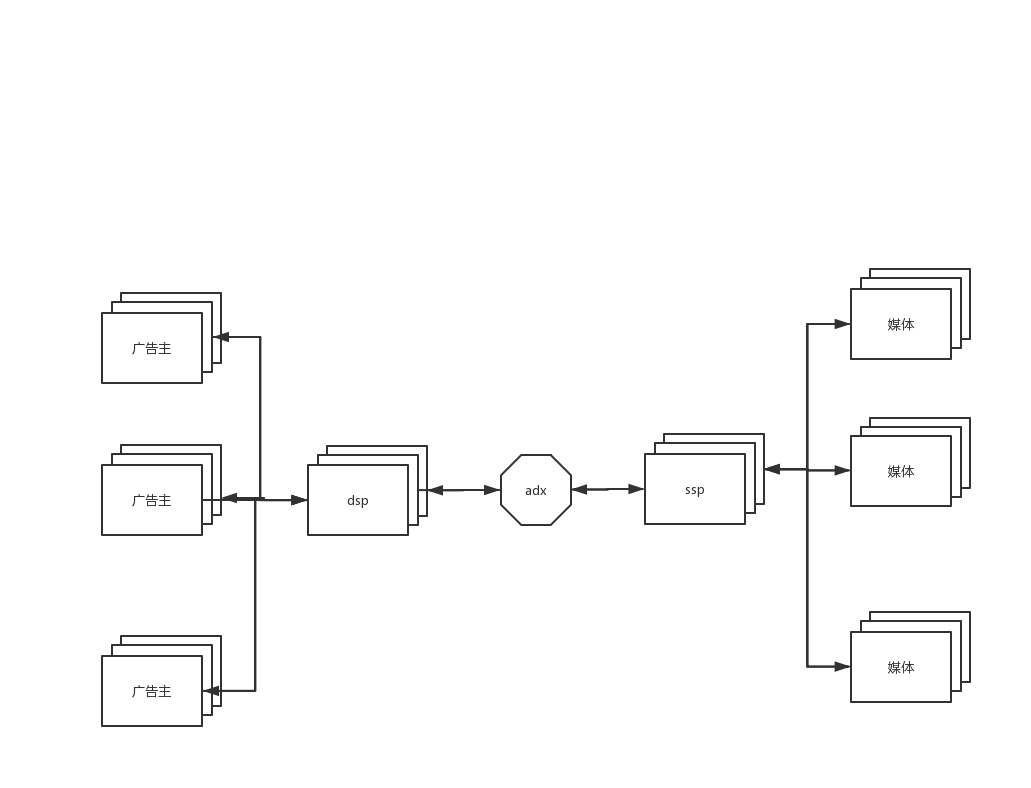
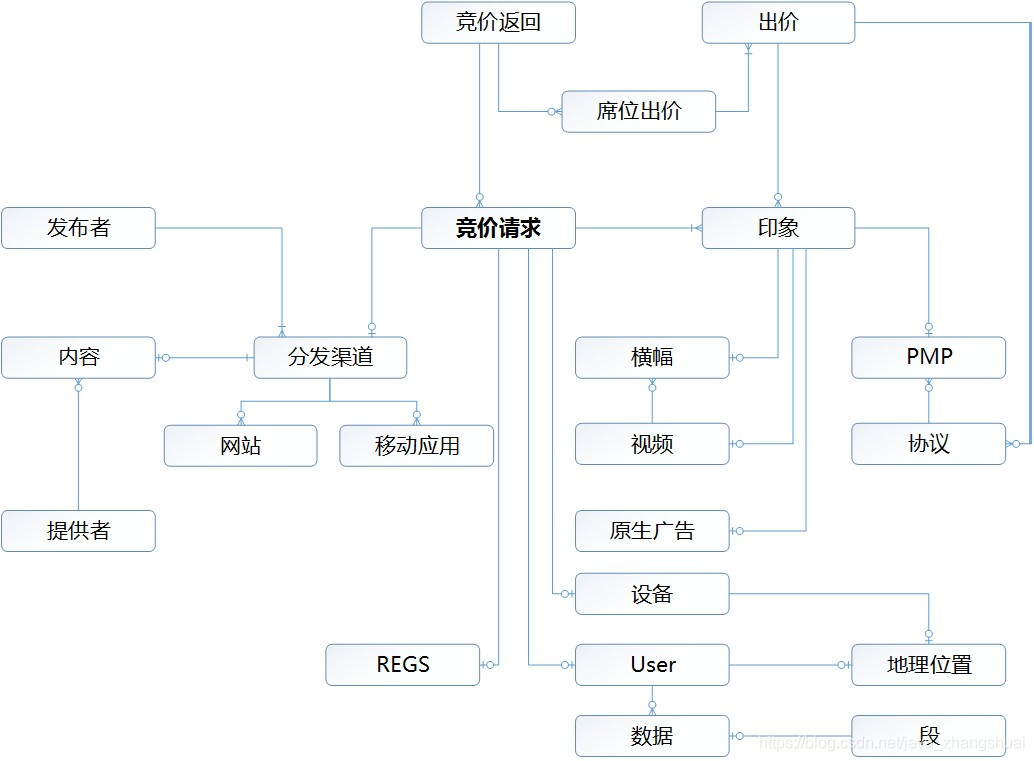
![[go]---从java到go(01)---基础与入门上手](https://img-blog.csdnimg.cn/20191024113116263.png)
![[数据库] --- clickhouse](https://img-blog.csdnimg.cn/20191119103251762.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2phdmFfemhhbmdzaHVhaQ==,size_16,color_FFFFFF,t_70)
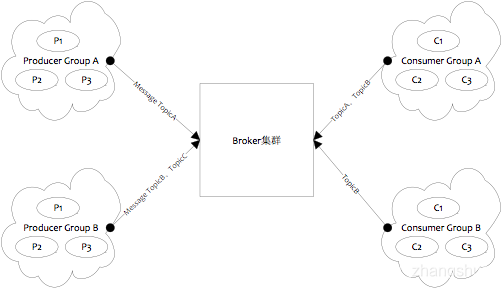
![[错误记录] --- rocketmq批量消费设置参数的问题](https://img-blog.csdnimg.cn/20191127184638246.png)