前言
说到数据库这个词,我只能用爱恨交加这个词来形容它。两年前在自己还单纯懵懂的时候进了数据库的课堂,听完数据库的课,觉得这是一门再简单不过的课程,任何一门编程语言都比SQL要晦涩难懂,任何一门理论课程都比数据库关系要复杂得多。直到从被面试官按在地上摩擦,到工作中那一条条令人发指的慢查询SQL,这就已经完全颠覆了我对数据库的看法。在有各种数据库工具的今天,我们是看不到那简单到不能再简单的一张表的背后,隐藏着多少数据结构的支撑,也看不到我们随手敲的一条SELECT,背后会有多少算法和数据结构在给我们做优化,作为一个有技术热情的coder,应该需要对我们每日在用的数据库做一次深入了解。
数据库架构
-
如何设计一个关系型数据库
这个问题很宽泛,需要我们对于整体有一个掌控,对我们平时所用的数据库要有足够的了解,对整个数据库做模块划分是这道题的关键,这就更需要我们足够了解数据库,对数据库做一个合理的模块设计。
-
设计
从开始,首先要明白,数据库的最最根本的作用是什么——存储数据,所以我们需要一个存储模块来存储我们的数据,它可以是一个文件系统(机械硬盘?SSD固态硬盘?)。但光有存储模块是不够的,我们还需要一个程序实例,来组织或者获取这些数据,在程序实例中我们需要提供获取和组织这些数据的方式,所以我们需要在程序实例中实现存储管理模块。我们还可以在存储管理模块中做一些提升效能的工作,例如同时读取多行、分块分页存储等。数据库作为一款对性能要求极高的软件,我们应该加入缓存机制,来提高其速度,当查询到缓存中已存在的数据,我们应该直接将其从缓存中读取,这样可以减少硬盘IO次数,提高效能。到这里为止,我们已经完成了对数据库的存储方面的功能设计,但是作为数据库,应该需要提供给用户对数据进行增删改查的接口,即平时所写的SQL,所以我们应该提供一个SQL解析模块,来对日常用户所写的SQL语句进行解析,转换成机器可识别的指令,我们也可以直接将编译过的SQL加入缓存,下次再有同样的SQL就直接从缓存中读取,同样可以提高效能。作为一款成熟的数据库,需要应对各种复杂的环境,要时刻记录数据库的状态,所以我们还需要一个日志管理模块,对操作和错误信息进行记录。数据库中需要支持多用户操作,但每个用户都能操作所有的数据,这是不现实的,所以还需要权限划分模块对数据库用户进行权限管理。当然数据库说到底也只是一款软件,是软件就会有bug,就会出故障,故障不可怕,可怕的是在数据库这种敏感软件下对故障没有特殊的处理方式,导致数据丢失,毕竟数据是无价的,所以数据库应该引入容灾机制,在数据库挂了的时候,对数据进行恢复。还有作为数据库最重要的两个模块,也是现今任何一个数据库都需要考虑的问题——并发和查找效率,所以还需引入索引和锁这两个模块,这就是实现一个最基础的数据库所必需的几大模块。
-
归纳
综上对数据库设计模块做一个汇总:
1.存储模块
2.程序实例
2.1存储管理模块
2.2缓存机制
2.3SQL解析模块
2.4日志管理模块
2.5权限划分模块
2.6容灾机制
2.7索引模块
2.8锁模块
索引
-
为什么要使用索引
要考虑这个问题,首先要从最基础的查找表中数据的过程开始说起。通常我们在查找一个序列中的某一个元素时,用到的最简单的方式就是遍历,数据库也是一样,在一张表中查找某一行数据时,如果不考虑索引的状况下,也会采用一个逐行扫描的方式,只不过数据库通常以块或者页为单位,所以它通常将整个块或者页加载进内存,然后逐块轮询查找到结果并返回。如果数据库中只有少量数据,那么进行全表扫描,速度还是会很快,但是如果在数据量很大的表中,这种方法就不再适用了,在数据量很大的表中,由于逐行扫描代价变大,通常需要避免采用这种逐行扫描的方式进行数据查找,数据库为了使查询变得高效,所以引入了索引这种方式对数据进行查找。
-
什么样的信息能成为索引
1.主键、唯一键、普通键
-
索引的数据结构
-
二叉查找树
众所周知,二叉查找树是每个节点最多由两个子树的树结构,而其还有一个特点是,在任意一颗树中,根节点的左孩子永远小于根节点,根节点的右孩子永远大于根节点,用二叉查找树作为索引,确实可以提高查找效率,其可以使用二分查找将时间复杂度控制在O(lgn),但是二叉查找树有一个显而易见的缺陷,当某种特殊情况(按照某个特定顺序插入树)发生时,二叉查找树将变为下图右侧(线性二叉树)的状况:
-
B-Tree
B-Tree,平衡多路查找树,如果每个节点,最多有N个孩子,那么这样的树就叫N阶B-Tree, 每个节点中主要包含关键字和指向孩子的指针,最多能有几个孩子,取决于节点的容量和数据库的相关配置,通常情况下这个N是很大的。
B-Tree作为一种数据结构,有如下特征:
1.根节点至少包含两个孩子
2.树中每个节点至多含有N个孩子(N>=2)
3.除根节点和叶节点外,其它每个节点至少有ceil(N/2)个孩子。(ceil表示取上限,例如1.2的上限为2,1.1的上限也为2,非四舍五入)
4.所有叶子节点都位于同一层,即叶子节点的高度都是一样的。
5.假设每个非终端节点包含n个关键字信息(P0,P1...Pn,k1...kn)( a )ki(i=1..n)为关键字,且关键字按顺序升序排序k(i-1)<ki。
( b )关键字的个数必须满足:[ceil(m/2)-1]<=n<=m-1]。
( c )非叶子节点的指针:P[1],P[2]...P[M];其中P[1]指向关键字小于K[1]的子树,P[N]指向关键字大于K[N-1]的子树,其它P[i]指向关键字属于(K[i-1],K[i])的子树。
如果这里是二叉查找树,会出现极端情况,使得查找时间复杂度为O(n),而如果是B-Tree,由于上述五个约束,可以让节点通过合并、分裂、上移、下移等操作,使得树高度较二叉查找树小,查找效率显然更高。 -
B+ -Tree(MySQL)
B+ -Tree是B-Tree的一个变体,其定义基本与B树相同,除了:
1.非叶子节点的子树指针与关键字个数相同,其表明B+树能存储更多的关键字
2.非叶子节点的子树指针P[i],指向关键字值[K[i],K[i+1])的子树。
3.非叶子节点仅用来做索引,数据到保存在叶子节点中。(B+树的所有检索都是从根部开始,直到搜索到叶子节点结束。)
4.所有叶子节点均有一个链指针,指向下一个叶子节点。(方便直接在叶子节点直接做范围统计)
1.B+树的磁盘读写代价更低。
2.B+树的查询效率更加稳定。
3.B+树更有利于对数据库的扫描。
-
Hash
Hash索引是根据Hash结构的定义,只需要一次运算便可以找到数据所在位置,不像B+树或者B树需要从根结点出发寻找数据,所以Hash索引的查询效率理论上要高于B+树索引,但是MySQL中并没有采用这一种索引,这是由于这种索引除查询效率之外的缺陷是十分明显的。
1.仅仅只能满足"=","IN",不能使用范围查询。由于其是由Hash运算获取的数据存放位置,每次Hash运算获取的是一个确定的值,且这个值并不与数据本身的大小有关系,所以其并不能满足范围查询。
2.无法被用来避免数据的排序操作。和1的意思差不多,Hash的索引值是由Hash运算获取的,其索引值与数据本身的大小并无明显关系。
3.不能利用部分索引键查询。
4.不能避免表扫描。由于Hash索引会产生Hash冲突,存在Hash冲突的数据会被连接到同一个链表上,当大量数据被连接到相同链表上时,查询某条数据就变成了扫描该链表,时间复杂度并不能保证在O(1)。
5.遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。 -
BitMap索引
位图索引,当表中的某个字段只有几种值的时候,例如:性别,此时用位图索引是一个最佳的选择。目前使用位图索引的比较主流的数据库有Oracle数据库。
-
-
密集索引和稀疏索引的区别
1.密集索引文件中的每个搜索码都对应一个索引值,稀疏索引文件只为索引码的某些值建立索引项。
2.密集索引将数据存储与索引放到了一块,找到索引也就找到了数据,稀疏索引将数据和索引分开存储,索引结构的叶子节点指向数据的对应行。- 关于MySQL的MyISAM和InnoDB
MyISAM不论是主键索引、唯一键索引、还是普通索引,都采用的是稀疏索引,而InnoDB必须有且仅有一个密集索引。
InnoDB密集索引规则:
1.若一个主键被定义,该主键则作为密集索引。
2.若没有主键被定义,该表的第一个唯一非空索引则作为密集索引。
3.若不满足以上条件,InnoDB内部会生成一个隐藏主键(密集索引)。
4.非主键索引存储相关键位和其对应的主键值,包含两次查找。
注:InnoDB如果查询条件为主键索引,则只需查询一次,但是辅助索引需要查询两次,先通过辅助索引查询到主键索引,再查询到数据。
- 关于MySQL的MyISAM和InnoDB
-
如何定位并优化慢查询SQL
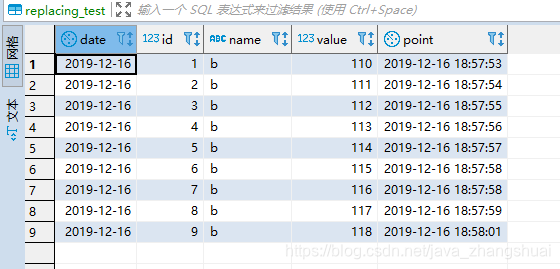
首先先建立一张表
CREATE DATABASE sqltest; use sqltest; create table tb_test(test_id int primary key auto_increment,test_name varchar(1024),test_date datetime,test_desc varchar(1024) );
![[go]---从java到go(01)---基础与入门上手](https://img-blog.csdnimg.cn/20191024113116263.png)
![[数据库] --- clickhouse](https://img-blog.csdnimg.cn/20191119103251762.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2phdmFfemhhbmdzaHVhaQ==,size_16,color_FFFFFF,t_70)
![[错误记录] --- rocketmq批量消费设置参数的问题](https://img-blog.csdnimg.cn/20191127184638246.png)

![[记录] ---阿里云java.io.IOException: Connection reset by peer的问题](https://img-blog.csdnimg.cn/20191225145858140.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2phdmFfemhhbmdzaHVhaQ==,size_16,color_FFFFFF,t_70)