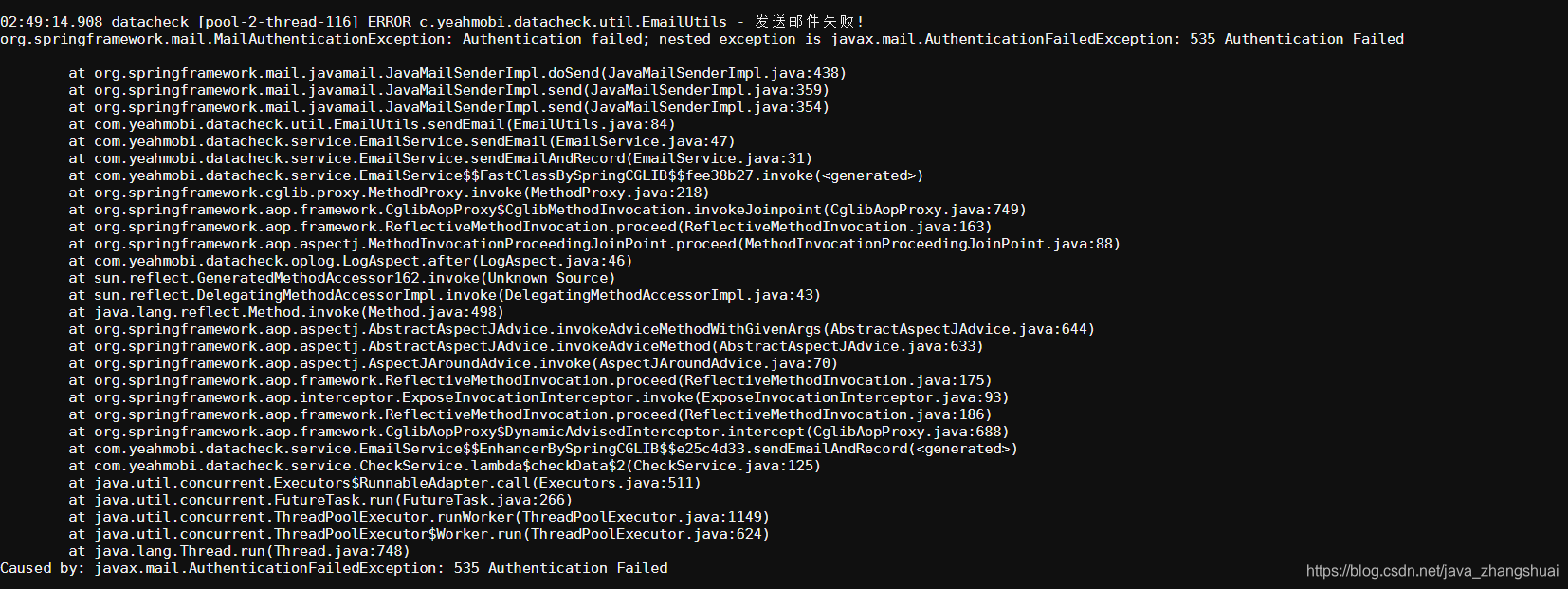
限流算法(漏桶算法、令牌桶算法)
漏桶算法:
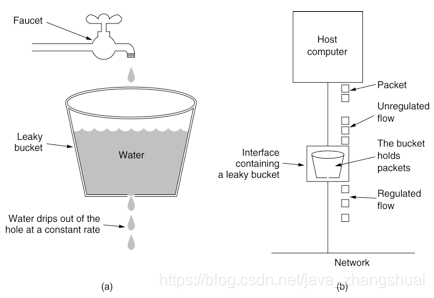
有个桶,比如最大能进2个单位的水(请求),桶底有个洞,每个单位的水都会在桶里待3秒后漏下去。
那么这个桶就可以同时处理2个单位的水。
如果进水太多,同一时间进水多出2个单位的水就溢出来了,也就是拒绝请求或阻塞。
令牌桶算法:
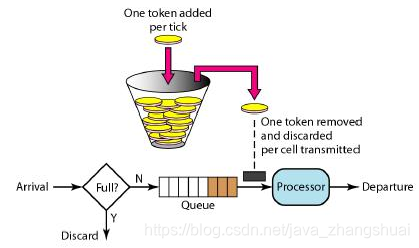
有个桶,每个固定时间会向桶里放令牌,放满就不放了,而每次请求都会从桶里去拿令牌,拿到才能正常请求。
如果拿的速度大于放的速度,那么就会出现拿不到令牌的情况,请求就会被拒绝或阻塞。
基于漏桶算法的典型实现:java.util.concurrent.Semaphore
基于令牌桶算法是典型实现:com.google.common.util.concurrent.RateLimiter
1、Semaphore(漏桶算法)
Semaphore更倾向于限制并发量,比如系统只支持2个并发,那么就设置:
Semaphore semaphore = new Semaphore(2);
每次请求前,执行semaphore.acquire();相当于将水放在水桶里,最多放2个
请求结束前,执行semaphore.release();相当于把水漏掉
那么效果就是系统每秒只能支持两个请求,只有等这某个请求执行完,并且释放掉,才能接收新的请求
2、RateLimiter(令牌桶算法)
RateLimiter更倾向于限制访问速率,比如系统每秒2次请求,那就设置:
RateLimiter limiter = RateLimiter.create(2.0);
每次请求前,执行limiter.acquire();相当于从桶里取令牌
那效果就是每秒只能有两个请求取到令牌,其他请求只能阻塞住,等待下一秒
刚开始看这两种限流算法,有些人会混淆,感觉不到太大的差别,那就试试跑跑下面的例子,感受一下:
public static void main(String[] args) {RateLimiter limiter = RateLimiter.create(2.0); // 这里的2表示每秒允许处理的量为2个for (int i = 1; i <= 10; i++) {limiter.acquire();// 拿令牌,拿不到就阻塞log.info("执行。。。" + i);}}
public static void main(String[] args) {Semaphore semaphore = new Semaphore(2);//这里的2表示并发数是2for(int i=0;i<10;i++) {new Thread(()->{try {semaphore.acquire();//入桶,放不下就阻塞log.info(Thread.currentThread().getName()+"执行");Thread.sleep(3000);//睡3秒} catch (InterruptedException e) {e.printStackTrace();}finally {semaphore.release();//释放}},"线程"+i).start();}}
注意比对结果,看for循环里每个执行的速度,你会发现:
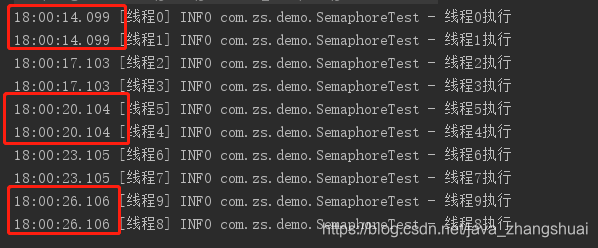
使用Semaphore限流的,设置的并发数是2个,那么就是一下子两个一起执行,完了3秒后都执行完,释放掉,后两个再一起执行。重点是一批一批的。
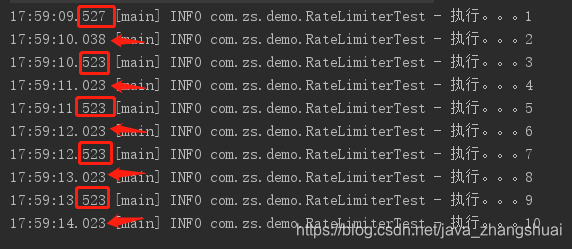
使用RateLimiter限流的,每个执行都是匀速的,设置的每秒2个请求,那就基本上是0.5秒一个,匀速执行。重点是匀速。
具体执行结果可以看下图:
这个是RateLimiter,可以看到是匀速的执行,0.5秒一个。
这个是Semaphore,是两个两个的执行,每3秒2个。
注意
这两种都是单机版的,分布式环境可以使用redis等分布式唯一存储来记录这些值,原理都基本差不多


![[go]---从java到go(01)---基础与入门上手](https://img-blog.csdnimg.cn/20191024113116263.png)
![[数据库] --- clickhouse](https://img-blog.csdnimg.cn/20191119103251762.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2phdmFfemhhbmdzaHVhaQ==,size_16,color_FFFFFF,t_70)
![[错误记录] --- rocketmq批量消费设置参数的问题](https://img-blog.csdnimg.cn/20191127184638246.png)

![[记录] ---阿里云java.io.IOException: Connection reset by peer的问题](https://img-blog.csdnimg.cn/20191225145858140.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2phdmFfemhhbmdzaHVhaQ==,size_16,color_FFFFFF,t_70)