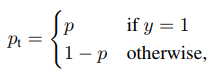本文是100天区块链学习计划的第二篇学习笔记,其实就是按照阮一峰的网络日志-区块链入门教程的讲解进行的简单梳理。也是时间有点紧张的原因,相比于上一篇SHA256算法原理详解,个人感觉质量和原创程度明显下降。待对区块链有了更深的理解后,我会回来完善,并加入更多自己的理解的。
区块链的本质
区块链是什么?一句话,它是一种特殊的分布式数据库。
首先,区块链的主要作用是存储信息。任何需要保存的信息,都可以写入区块链,也可以从里面读取,所以它是数据库。
其次,任何人都可以架设服务器,加入区块链网络,成为一个节点。区块链的世界里面,没有中心节点,每个结点都是平等的,都保存着整个数据库。你可以向任何一个节点,写入/读取数据,因为所有节点最后都会同步,保证区块链一致。
区块链的诞生是为了满足什么需求?还是解决什么问题?
溯源区块链,我们发现区块链诞生于比特币,是从比特币的技术中衍生出的。
在2008年全球金融危机中,美国政府因为有记账权,所以可以无限增发货币,一位自称中本聪的人觉得这样很不靠谱,于是他想创建一种新型支付体系,大家都有权记账,货币不能超发,整个账本完全公开透明十分公平。
2008年11月1日中本聪在网络上发表了一篇《比特币——一种点对点的电子现金系统》的论文,文中描述了一个全新的电子现金系统 比特币。比特币是一种去中心化的电子现金系统,它解决了在没有中心机构的情况下,总量恒定的数字资产的发行和流通问题,通过比特币系统转账,信息公开透明,可以放心的把比特币转给另一个人,每一笔转账信息都会被全网记录。白皮书的问世,标志着比特币的底层技术区块链的诞生。(这里要着重区分一下Bitcoin和bitcoin,大写的B是代表点对点的电子现金系统,小写的b是指比特币。)
注意:区块链是比特币得以实现的技术,比特币是区块链技术的第一个应用。
比特币的存在是为了避免中心机构作恶超发货币,解决去中心化网络和价值传递两个问题。而区块链就是解决这两个问题的核心技术,使得电子现金可以点对点的直接从一方支付给另一方,中间不经过任何金融机构。
区块链的最大特点
分布式数据库并非新发明,市场上早有此类产品。但是,区块链有一个革命性特点。
区块链没有管理员,它是彻底无中心的。其他的数据库都有管理员,但是区块链没有。如果有人想对区块链添加审核,也实现不了,因为它的设计目标就是防止出现居于中心地位的管理当局。
正是因为无法管理,区块链才能做到无法被控制。否则一旦大公司大集团控制了管理权,他们就会控制整个平台,其他使用者就都必须听命于他们了。
但是,没有了管理员,人人都可以往里面写入数据,怎么才能保证数据是可信的呢?被坏人改了怎么办?
区块
区块链由一个个区块(Block)组成。
每个区块包含两个部分。
- 区块头(Head):记录当前区块的特征值
- 区块体(Body):实际数据
区块头包含了当前区块的多项特征值。
- Height 525216 (Main chain)
- Hash 00000000000000000016897fbee5d409cf831236d12f760f8453b0cb9e5150b9
- Previous Block 000000000000000000280a08df7f13f48bb30c1470216b81c98c2396c3c9aaca
- Next Blocks 0000000000000000003a29065af4314d8ea2299c091c61bf3045f9f7da24d85e
- Time 2018-05-31 02:49:19
- Difficulty 4,306,949,573,981.51
- Bits 390158921
- Version 0x20000000
- Merkle Root d76de1a9c0f4b583c51815b08377d788286e2213ba71ab24114d635dbf7207ac
- Nonce 2427928693
- Block Reward 12.5 BTC
- …
所谓“哈希”就是计算机可以对任意内容,计算出一个长度相同的特征值。区块链的哈希长度是256位,这就是说,不管原始内容是什么,最后都会计算出一个256位的二进制数字。而且可以保证,只要原始内容不同,对应的哈希一定是不同的。
因此,就有两个重要的推论。
- 推论1:每个区块的哈希都是不一样的,可以通过哈希标识区块。
- 推论2:如果区块的内容变了,它的哈希一定会改变。
Hash的不可修改性
区块与哈希是一一对应的,每个区块的哈希都是针对“区块头”计算的。也就是说,把区块头的各项特征值,按照顺序连接在一起,组成一个很长的字符串,再对这个字符串计算哈希。
Hash = SHA256 ( 区块头 )
上面就是区块哈希的计算公式,AHA256 是区块链的哈希算法。注意,这个公式里面只包含区块头,不包含区块体,也就是说,哈希由区块头唯一决定。
前面说过,区块头包含很多内容,其中有当前区块体的哈希,还有上一个区块的哈希。这意味着,如果当前区块体的内容变了,或者上一个区块的哈希变了,一定会引起当前区块的哈希改变。
这一点对区块链有重大意义。如果有人修改了一个区块,该区块的哈希就变了。为了让后面的区块能连接到它(因为下一个区块包含上一个区块的哈希),该人必须依次修改后面所有的区块,否则被改掉的区块就脱离区块链了。由于后面要提到的原因,哈希的计算很耗时,短时间内修改多个区块几乎不可能发生,除非有人掌握了全网51%以上的计算能力。
正是通过这种联动机制,区块链保证了自身的可靠性,数据一旦写入,就无法被篡改。这就像历史一样,发生了就是发生了,从此再无法改变。
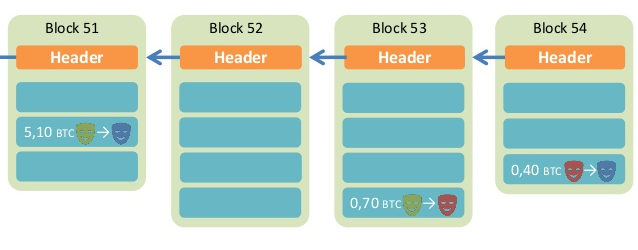
每个区块都连着上一个区块,这也是“区块链”这个名字的由来。
采矿
由于必须保证节点之间的同步,所以新区快的添加速度不能太快。试想一下,你刚刚同步了一个区块,准备基于它生成下一个区块,但这时别的节点又有新区块生成,你不得不放弃做了一半的计算,再次去同步。因为每个区块后面,只能跟着一个区块,你永远只能在最新区块的后面,生成下一个区块。所以,你别无选择,一听到信号,就必须立刻同步。
所以,区块链的发明者 中本聪 故意让添加新区块,变得很困难。他的设计是,平均每10分钟,全网才能生成一个新区块,一小时也就六个。
这种产出速度不是通过命令达成的,而是故意设置了海量的计算。也就是说,只有通过及其大量的计算,才能得到当前区块的有效哈希,从而把新区块添加到区块链。由于计算量太大,所以快不起来。
这个过程就叫采矿(mining),因为计算有效哈希的难度,好比在全世界的沙子里面,找到一粒符合条件的沙子。计算哈希的机器叫做矿机,操作矿机的人就叫矿工。
难度系数
不是任何一个哈希都可以,只有满足条件的哈希才会被区块链接受。这个条件特别苛刻,使得绝大部分哈希都不满足要求,必须重算。
原来,区块头包含一个难度系数(difficulty),这个值决定了计算哈希的难度。区块链协议规定,使用一个常量除以难度系数,可以得到目标值(target)。显然,难度系数越大,目标值就越小。
target = targetmax / difficulty哈希的有效性跟目标值密切相关,只有小于目标值的哈希才是有效的,否则哈希无效,必须重算。由于目标值非常小,哈希小于该值的机会极其渺茫,这就是采矿如此之慢的根本原因。
前面说过,当前区块的哈希由区块头唯一决定。如果要对同一个区块反复计算哈希,就意味着,区块头必须不停地变化,否则不可能算出不一样的哈希。区块头里面所有的特征值都是固定的,为了让区块头产生变化,中本聪故意增加了一个随机项,叫做Nonce。
Nonce是一个随机值,矿工的作用其实就是猜出 Nonce 的值,使得区块头的哈希可以小于目标值,从而能够写入区块链。Nonce 是非常难猜的,目前只能通过穷举法一个个试错。根据协议,Nonce 是一个32位的二进制值,即最大可以到21.47亿。第100000个区块的 Nonce 值是 274148111,可以理解成,矿工从0开始,一直计算了2.74亿次,才得到一个有效的 Nonce 值,使得算出的哈希能够满足条件。
运气好的话,也许一会就找到了 Nonce。运气不好的话,可能算完了21.47亿次,都没有发现 Nonce,即当前区块体不可能算出满足条件的哈希。这时,协议允许矿工改变区块体,开始新的计算。
难度系数的动态调节
采矿具有随机性,没法保证正好十分钟产出一个区块,有时一分钟就算出来了,有时几个小时可能也没结果。总体来看,随着硬件设备的提升,以及矿机的数量增长,计算速度一定会越来越快。
为了将产出速率恒定在十分钟,中本聪还设计了难度系数的动态调节机制。他规定,难度系数每两周(2016个区块)调整一次。如果这两周里面,区块的平均生成速度是9分钟,就意味着比法定速度快了10%,因此接下来的难度系数就要调高10%;如果平均生成速度是11分钟,就意味着比法定速度慢了10%,因此接下来的难度系数就要调低10%。
难度系数越调越高(目标值越来越小),导致了采矿越来越难。
区块链的分叉
即使区块链是可靠的,现在还有一个问题没有解决:如果两个人同时向区块链写入数据,也就是说,同时有两个区块加入,因为它们都连着前一个区块,就形成了分叉。这时应该采纳哪一个区块呢?
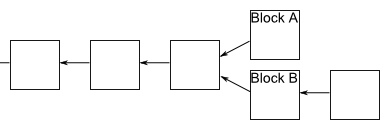
现在的规则是,新节点总是采用最长的那条区块链。如果区块链有分叉,将看哪个分支在分叉后面,先达到6个新区块(称为“六次确认”)。按照10分钟一个区块计算,一小时就可以确认。

由于新区块的生成速度由计算能力决定,所以这条规则就是说,拥有大多数计算能力的那条分支,就是正宗的区块链。
总结
区块链作为无人管理的分布式数据库,从2009年开始已经运行了8年,没有出现大的问题。这证明它是可行的。
但是,为了保证数据的可靠性,区块链也有自己的代价。
- 一是效率,数据写入区块链,最少要等待十分钟,所有节点都同步数据,则需要更多的时间;
- 二是能耗,区块的生成需要矿工进行无数无意义的计算,这是非常耗费能源的。
因此,区块链的适用场景,其实非常有限。
1. 不存在所有成员都信任的管理当局。
2. 写入的数据不要求实时使用。
3. 挖矿的收益能够弥补本身的成本。
如果无法满足上述的条件,那么传统的数据库是更好的解决方案。
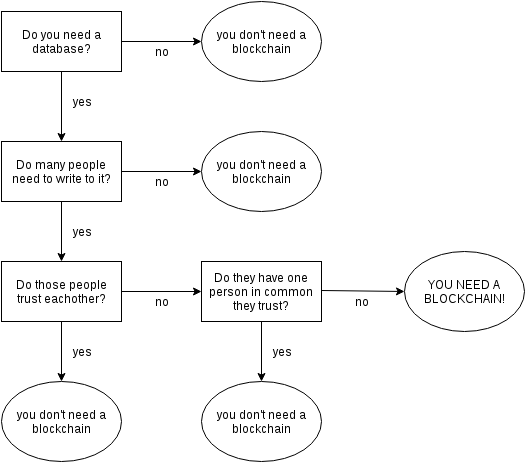
目前,区块链最大的应用场景(可能也是唯一的应用场景),就是以比特币为代表的加密货币。
参考连接
https://blockchain.info/
http://www.ruanyifeng.com/blog/2017/12/blockchain-tutorial.html