
来源:微软研究院AI头条
概要:1月17日,院友袁进辉博士回到微软亚洲研究院做了题为《打造最强深度学习引擎》的报告,分享了深度学习框架方面的技术进展。
1月17日,院友袁进辉博士回到微软亚洲研究院做了题为《打造最强深度学习引擎》的报告,分享了深度学习框架方面的技术进展。报告中主要讲解了何为最强的计算引擎?专用硬件为什么快?大规模专用硬件面临着什么问题?软件构架又应该解决哪些问题?
首先,我们一起来开一个脑洞:想象一个最理想的深度学习引擎应该是什么样子的,或者说深度学习引擎的终极形态是什么?看看这会给深度学习框架和AI专用芯片研发带来什么启发。
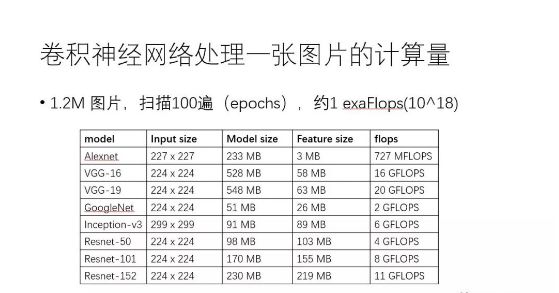
以大家耳熟能详的卷积神经网络CNN 为例,可以感觉一下目前训练深度学习模型需要多少计算力。下方这张表列出了常见CNN模型处理一张图片需要的内存容量和浮点计算次数,譬如VGG-16网络处理一张图片就需要16Gflops。值得注意的是,基于ImageNet数据集训练CNN,数据集一共大约120万张图片,训练算法需要对这个数据集扫描100遍(epoch),这意味着10^18次浮点计算,即1exaFlops。简单演算一下可发现,基于一个主频为2.0GHz的CPU core来训练这样的模型需要好几年的时间。
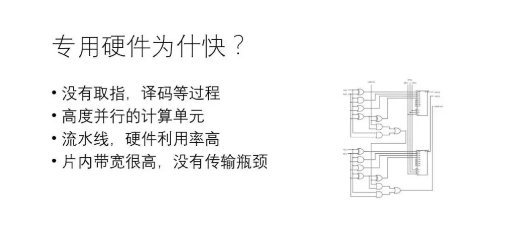
专用硬件比通用硬件(如CPU、GPU)快,有多种原因,主要包括:(1)通用芯片一般经历“取指-译码-执行”(甚至包括“取数据”)的步骤才能完成一次运算,专用硬件大大减小了“取指-译码”等开销,数据到达即执行;(2)专用硬件控制电路复杂度低,可以在相同的面积下集成更多对运算有用的器件,可以在一个时钟周期内完成通用硬件需要数千上万个时钟周期才能完成的操作;(3)专用硬件和通用硬件内都支持流水线并行,硬件利用率高;(4)专用硬件片内带宽高,大部分数据在片内传输。显然,如果不考虑物理现实,不管什么神经网络,不管问题的规模有多大,都实现一套专用硬件是效率最高的做法。问题是,这行得通吗?
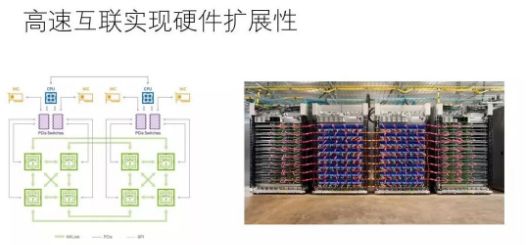
现实中,不管是通用硬件(如GPU)还是专用硬件(如TPU) 都可以通过高速互联技术连接在一起,通过软件协调多个设备来完成大规模计算。使用最先进的互联技术,设备和设备之间传输带宽可以达到100Gbps或者更多,这比设备内部带宽低上一两个数量级,不过幸好,如果软件“调配得当”,在这个带宽条件下也可能使得硬件计算饱和。当然,“调配得当”技术挑战极大,事实上,单个设备速度越快,越难把多个设备“调配得当”。
当前深度学习普遍采用随机梯度下降算法(SGD),一般一个GPU处理一小块儿数据只需要100毫秒的时间,那么问题的关键就成了,“调配”算法能否在100毫秒的时间内为GPU处理下一块数据做好准备,如果可以的话,那么GPU就会一直保持在运算状态,如果不可以,那么GPU就要间歇性的停顿,意味着设备利用率降低。理论上是可以的,有个叫运算强度(Arithmetic intensity)的概念,即flops per byte,表示一个字节的数据上发生的运算量,只要这个运算量足够大,意味着传输一个字节可以消耗足够多的计算量,那么即使设备间传输带宽低于设备内部带宽,也有可能使得设备处于满负荷状态。进一步,如果采用比GPU更快的设备,那么处理一块儿数据的时间就比100毫秒更低,譬如10毫秒,在给定的带宽条件下,“调配”算法能用10毫秒的时间为下一次计算做好准备吗?事实上,即使是使用不那么快(相对于TPU 等专用芯片)的GPU,当前主流的深度学习框架在某些场景(譬如模型并行)已经力不从心了。
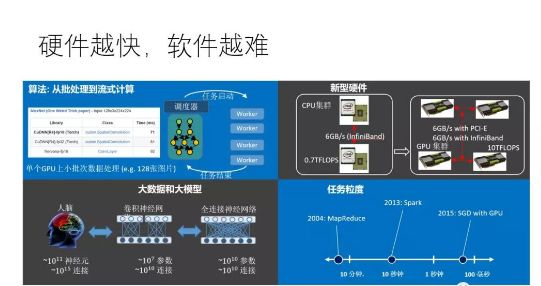
一个通用的深度学习软件框架要能对任何给定的神经网络和可用资源都能最高效的“调配”硬件,这需要解决三个核心问题:(1)资源分配,包括计算核心,内存,传输带宽三种资源的分配,需要综合考虑局部性和负载均衡的问题;(2)生成正确的数据路由(相当于前文想象的专用硬件之间的连线问题);(3)高效的运行机制,完美协调数据搬运和计算,硬件利用率最高。
事实上,这三个问题都很挑战,本文暂不讨论其解法,假设我们能够解决这些问题的话,会有什么好处呢?
假设我们能解决前述的三个软件上的难题,那就能“鱼与熊掌兼得”:软件发挥灵活性,硬件发挥高效率,任给一个深度学习任务,用户不需要重新连线,就能享受那种“无限大专用硬件”的性能,何其美好。更令人激动的是,当这种软件得以实现时,专用硬件可以比现在所有AI芯片都更简单更高效。读者可以先想象一下怎么实现这种美好的前景。

让我们重申一下几个观点:(1)软件真的非常关键;(2)我们对宏观层次(设备和设备之间)的优化更感兴趣;(3)深度学习框架存在一个理想的实现,正如柏拉图心中那个最圆的圆,当然现有的深度学习框架还相距甚远;(4)各行各业的公司,只要有数据驱动的业务,最终都需要一个自己的“大脑”,这种“大脑”不应该只被少数巨头公司独享。

未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”








@树袋飘零...)


 - 蓝月网络...)





)


