🍅 作者:不吃西红柿
🍅 简介:CSDN博客专家🏆、信息技术智库公号作者✌。简历模板、职场PPT模板、技术难题交流、面试套路尽管【关注】私聊我。
🍅 欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
一、解析PDF(简历内推)
应用场景:简历内推(解析内容:包括不限于姓名、邮箱、电话号码、学历等信息)
输入:要解析的文件路径
输出:需要解析的内容(点我主页,详见历史文章)
环境准备:python 3.6 、mac(下文中doc转docx是mac写法,windows更简单,导入win32的包即可)
依赖包:
# encoding: utf-8
import os, sys
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator
def pdf_reader(file):fp = open(file, "rb")# 创建一个与文档相关联的解释器parser = PDFParser(fp)# PDF文档对象doc = PDFDocument(parser)# 链接解释器和文档对象parser.set_document(doc)# doc.set_paeser(parser)# 初始化文档# doc.initialize("")# 创建PDF资源管理器resource = PDFResourceManager()# 参数分析器laparam = LAParams()# 创建一个聚合器device = PDFPageAggregator(resource, laparams=laparam)# 创建PDF页面解释器interpreter = PDFPageInterpreter(resource, device)# 使用文档对象得到页面集合res = ''for page in PDFPage.create_pages(doc):# 使用页面解释器来读取interpreter.process_page(page)# 使用聚合器来获取内容layout = device.get_result()for out in layout:if hasattr(out, "get_text"):res = res + '' + out.get_text()return res二、发送邮件
有几个模块用于访问互联网以及处理网络通信协议。其中最简单的两个是用于处理从 urls 接收的数据的 urllib.request 以及用于发送电子邮件的 smtplib:
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )参数说明:
- host: SMTP 服务器主机。 你可以指定主机的ip地址或者域名如: runoob.com,这个是可选参数。
- port: 如果你提供了 host 参数, 你需要指定 SMTP 服务使用的端口号,一般情况下 SMTP 端口号为25。
- local_hostname: 如果 SMTP 在你的本机上,你只需要指定服务器地址为 localhost 即可。
Python SMTP 对象使用 sendmail 方法发送邮件,语法如下:
SMTP.sendmail(from_addr, to_addrs, msg[, mail_options, rcpt_options])参数说明:
- from_addr: 邮件发送者地址。
- to_addrs: 字符串列表,邮件发送地址。
- msg: 发送消息
案例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-import smtplib
from email.mime.text import MIMEText
from email.header import Headersender = 'from@runoob.com'# 西红柿微:ZPYDWXY
receivers = ['1221121@qq.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱# 三个参数:第一个为文本内容,第二个 plain 设置文本格式,第三个 utf-8 设置编码
message = MIMEText('Python 邮件发送测试...', 'plain', 'utf-8')
message['From'] = Header("不吃西红柿", 'utf-8') # 发送者
message['To'] = Header("测试", 'utf-8') # 接收者subject = 'Python SMTP 邮件测试'
message['Subject'] = Header(subject, 'utf-8')try:smtpObj = smtplib.SMTP('localhost')smtpObj.sendmail(sender, receivers, message.as_string())print "邮件发送成功"
except smtplib.SMTPException:print "Error: 无法发送邮件"
三、操作execl
1. 关联公式:Vlookup
vlookup是excel几乎最常用的公式,一般用于两个表的关联查询等。所以我先把这张表分为两个表。
#查看订单明细号是否重复,结果是没。
df1["订单明细号"].duplicated().value_counts()
df2["订单明细号"].duplicated().value_counts()df_c=pd.merge(df1,df2,on="订单明细号",how="left")2. 数据透视表
需求:想知道每个地区的业务员分别赚取的利润总和与利润平均数。
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])3. 对比两列差异
需求:比较订单明细号与订单明细号2的差异并显示出来。
sale["订单明细号2"]=sale["订单明细号"]#在订单明细号2里前10个都+1.
sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1#差异输出
result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]4. 去除重复值
需求:去除业务员编码的重复值
sale.drop_duplicates("业务员编码",inplace=True)5. 缺失值处理
#用0填充缺失值
sale["客户名称"]=sale["客户名称"].fillna(0)
#删除有客户编码缺失值的行
sale.dropna(subset=["客户编码"])6. 多条件筛选
需求:想知道业务员张爱,在北京区域卖的商品订单金额大于6000的信息。
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]7. 模糊筛选数据
需求:筛选存货名称含有"三星"或则含有"索尼"的信息。
sale.loc[sale["存货名称"].str.contains("三星|索尼")]8. 分类汇总
需求: 北京区域各业务员的利润总额。
sale.groupby(["地区名称","业务员名称"])["利润"].sum()9. 条件计算
需求:存货名称含“三星字眼”并且税费高于1000的订单有几个?这些订单的利润总和和平均利润是多少?(或者最小值,最大值,四分位数,标注差)
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()10. 删除数据间的空格
需求:删除存货名称两边的空格。
sale["存货名称"].map(lambda s :s.strip(""))四、画图分析
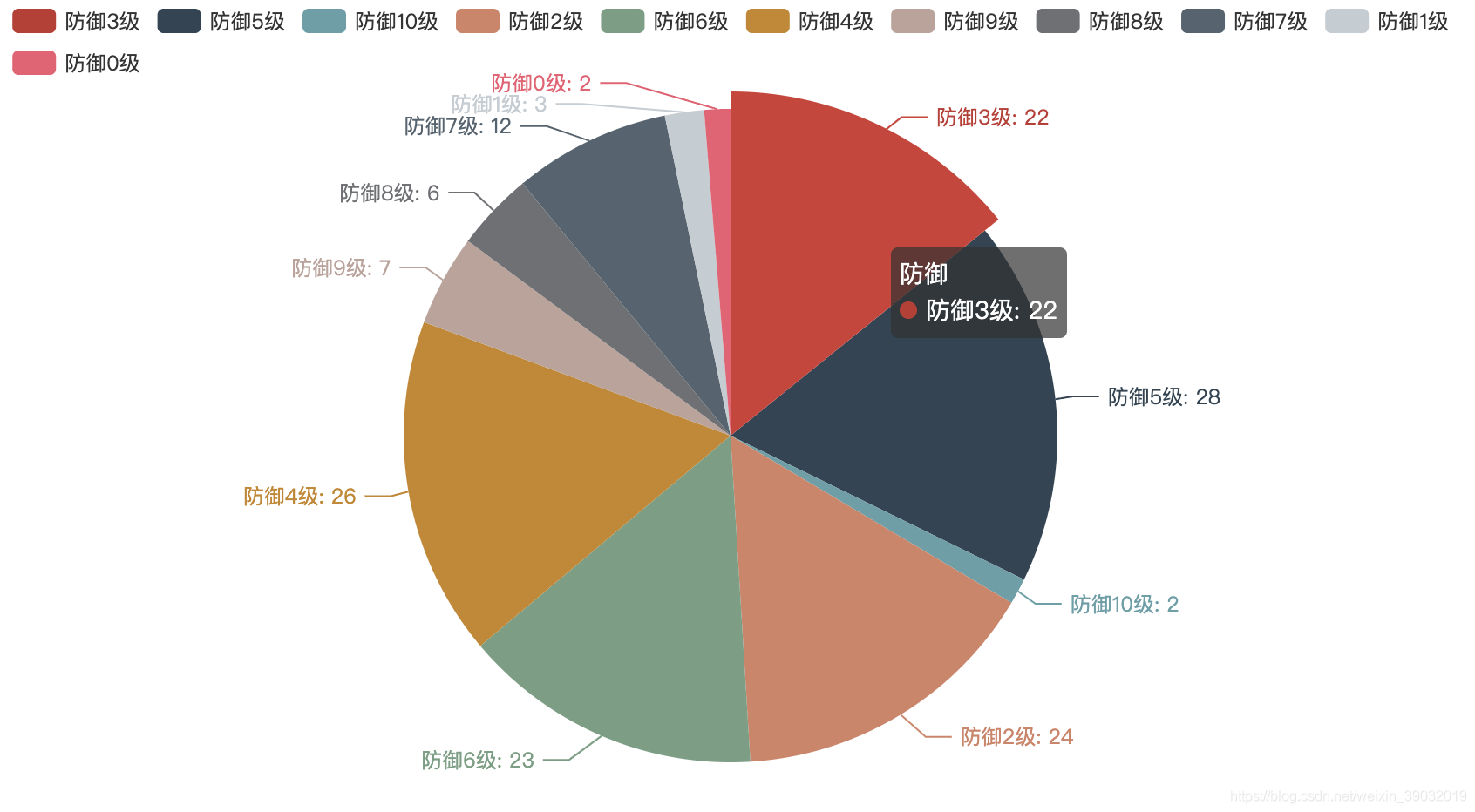
英雄联盟防御力:
防御能力最低的英雄(1级): 暗夜猎手,魔法猫咪,万花通灵
防御能力最高的英雄(10级): 正义巨像,披甲龙龟
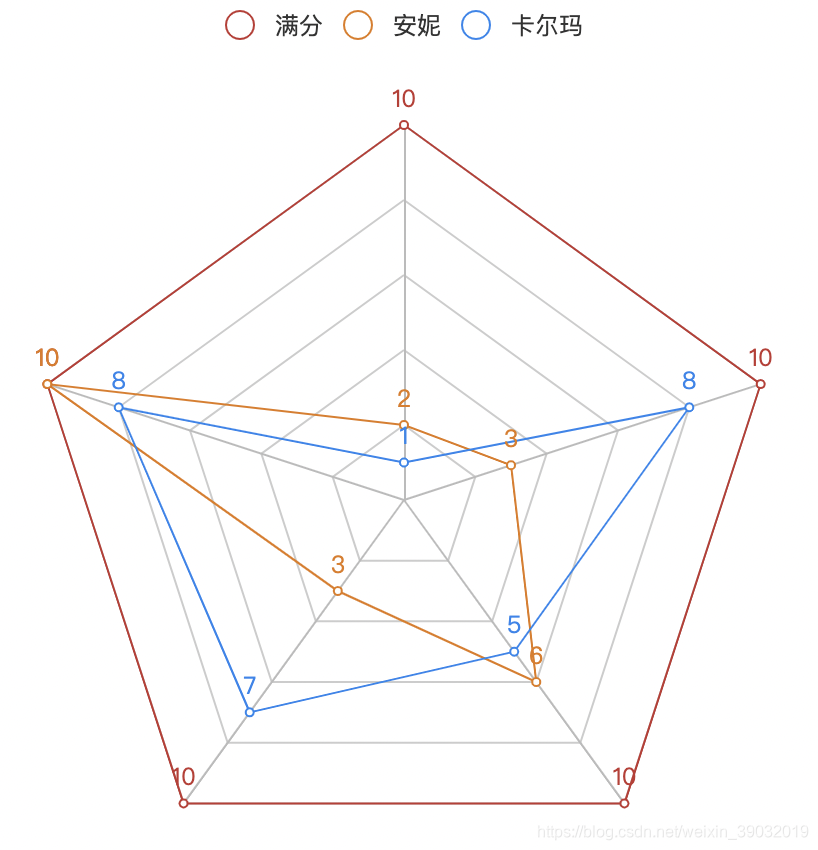
安妮、卡尔玛能力矩阵:
代码示例:
# encoding: utf-8
import json
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.charts import Radardef draw_Radar():from pyecharts.charts import Radarradar = Radar()# //由于雷达图传入的数据得为多维数据,所以这里需要做一下处理radar_data = [[10, 10, 10, 10, 10]]radar_data1 = [[2, 10, 3, 6, 3]]radar_data2 = [[1, 8, 7, 5, 8]]# //设置column的最大值,为了雷达图更为直观,这里的月份最大值设置有所不同schema = [("物理", 100), ("魔法", 10), ("防御", 10),("难度", 10),("喜好", 10)]# //传入坐标radar.add_schema(schema)radar.add("满分", radar_data)# //一般默认为同一种颜色,这里为了便于区分,需要设置item的颜色radar.add("安妮", radar_data1, color="#E37911")radar.add("卡尔玛", radar_data2, color="#1C86EE")radar.render()if __name__ == '__main__':draw_Radar()五、解析word(docx、doc)
依赖包:
# encoding: utf-8
import os, sys
import docxdef word_reader(file):try:# docx 直接读if 'docx' in file:res = ''f = docx.Document(file)for para in f.paragraphs:res = res + '\n' +para.textelse:# 先转格式doc>docxos.system("textutil -convert docx '%s'"%file)word_reader(file+'x')res = ''f = docx.Document(file+'x')for para in f.paragraphs:res = res + '\n' +para.textreturn resexcept:# print(file, 'read failed')return ''六、计算器
math模块为浮点运算提供了对底层函数库的访问:
>>> import math
>>> math.cos(math.pi / 4)
0.70710678118654757
>>> math.log(1024, 2)
10.0热门专栏推荐:
🥇 大数据集锦专栏:大数据-硬核学习资料 & 面试真题集锦
🥈 数据仓库专栏:数仓发展史、建设方法论、实战经验、面试真题
🥉 Python专栏:Python相关黑科技:爬虫、算法、小工具
(优质好文持续更新中……)✍






)












