
来源:混沌巡洋舰
摘要:最近, 深度学习三杰获得了计算机界最重要的图灵奖, 它们的贡献都集中在对深度学习的根据神经网络的理论突破。 今天我们看到的所有和人工智能有关的伟大成就, 从阿法狗到自动驾驶, 从海量人脸识别到对话机器人, 都可以归功于人工神经网络的迅速崛起。那么对于不了解神经网络的同学如何入门? 神经网络的技术为什么伟大, 又是什么让它们这么多年才姗姗走来? 我们一一拆解开来。
一 引入
我们说人工智能经历了若干阶段, 从规则主导的计算模型到统计机器学习。传统统计机器学习不乏极为强大的算法, 从各种高级的线性回归,SVM到决策树随机森林,它们的共同特点是把人类的学习过程直接转化为算法。 但是沿着直接模拟人类学习和思维的路线, 我们是否可以走向人工智能的终极大厦呢?

答案是否定的。 基于统计, 模拟人类思维的机器学习模型, 最典型的是决策树, 而即使决策树, 最多能够提取的无非是一种数据特征之间的树形逻辑关系。 但是显然我们人的功能, 很多并不是基于这种非常形式化的逻辑。 比如你一看到一个人, 就记住了他的面孔。 比如你有情感, 在你愤怒和恐惧的时候击退敌人。 比如你一不小心产生了灵感, 下了一手妙棋或者画出一幅名画。 这些显然都与决策树那种非常机械的逻辑相差甚远。
人类的智慧根据, 是从感知, 到直觉, 到创造力的一系列很难转化为程序的过程。 那我们如何才能真正模拟人类的智能? 我们回到人的组成人的智能本身最重要的材料。 大脑。
如果说统计机器学习的故事是一个模拟人类思维的过程, 那么神经网络的故事就是一个信息加工和处理的故事, 我们的思维将一步步接近造物, 接近 - “信息”, 这个一切认知和智能的本源。 看它该如何流动, 才能产生人的思维。
二 神经元
生物神经元
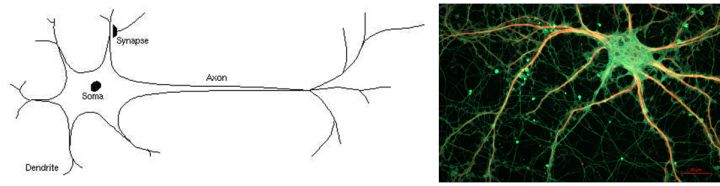
首先, 神经网络的灵感来自生物神经网络。 那么生物神经网络是怎么组成的? 神经元。 神经元的基本结构是树突, 胞体和轴突(如上图)。 这样一个结构, 就像因特网上的一台电脑, 它有一部接受器-树突, 每一个树突的顶端是一个叫突出的结构, 上面布满各种各样的传感器(离子通道), 接受外界物理信号, 或其它“电脑”给它发来的脉冲, 一部发射器,轴突,则以化学递质的形式放出自身的信号。只不过树突和轴突是有形的生物组织, 他们象树枝,根须一般延伸出去,不停的探知外界的情况并调整自己。
神经元模型
我们把生物神经元进行数学抽象, 就得到人工神经元。如何抽取它的灵魂? 简单的说, 每一个神经元扮演的角色就是一个收集+传话者。树突不停的收集外部的信号,大部分是其它细胞传递进来的信号,也有物理信号, 比如光。 然后把各种各样的信号转化成胞体上的电位, 如果胞体电位大于一个阈值, 它就开始向其它细胞传递信号。 这个过程非常像爆发。 要不是沉默, 要不就疯狂的对外喊话。
我们说, 一个神经细胞就是一个最小的认知单元, 何为认知单元, 就是把一定的数据组成起来,对它做出一个判断, 我们可以给它看成一个具有偏好的探测器。 联系机器学习, 就是分类器,不停的对外界数据进行处理。为什么要做分类? 因为正确的分类, 是认知的基础, 也是决策的基础。 因为认识任何概念, 往往都是离散的分类问题, 比如色彩, 物体的形状等等。因此, 神经细胞做的事情, 就像是模数转化, 把连续的信号转化成离散的样子。
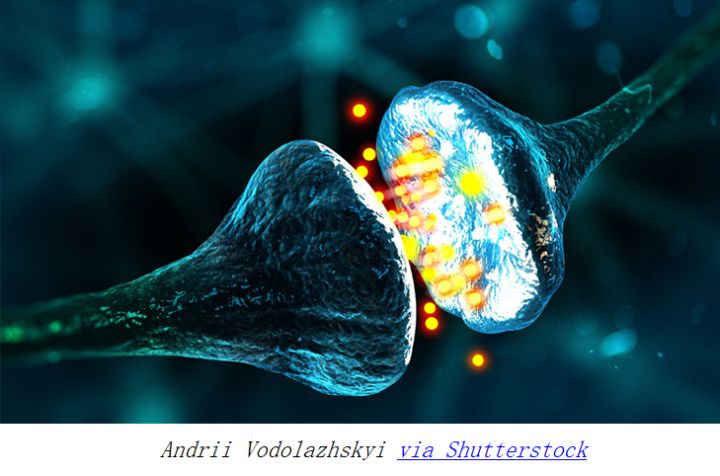
突触:生物神经元对话的媒介, 信号在这里实现转化
如果说把神经元看成这样一个信息转化的函数, 那么生物神经元的这副样子,使它能够极好的调节这个函数。 信号的收集者树突, 可以向外界生长决定探测哪些信号, 然后通过一个叫离子通道的东西收集信号,每个树突上这种通道的数量不一样。 有的多一点, 有的少一点, 而且是可以调控的。 这个调控的东西, 就是对外界信号的敏感度。 这样的结构, 可以说得到了最大的对外界信息的选择性。
什么是外界信号? 这里我们用上次课将的一个东西替代, 特征, 如果把一切看作树, 神经元在不停观测外界, 每个树突都在收集某个特征。而这个离子通道的数量, 就是线性回归里面的那个权重。
它在干什么事情呢? 收集特征, 作为决策证据! 当某些信息积累到一定地步, 它就可以做决策了, 如果把这个功能进一步简化, 我们就可以把这个决策过程描述成以单纯的阈值函数, 要么就干, 否则就不干。 就这么简单的。
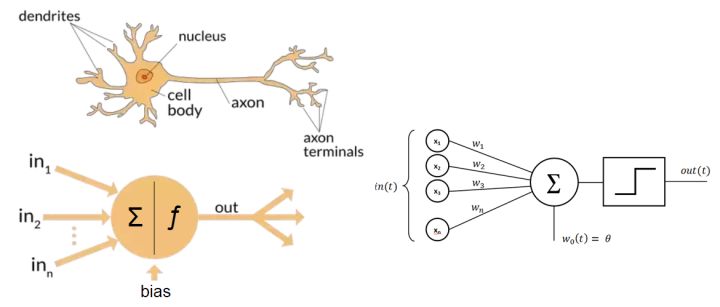
从生物神经元到数学神经元
神经细胞与晶体管和计算机的根本区别在于可塑性。或者更准确的说具有学习能力。从机器学习的角度看, 它实现的是一个可以学习的分类器,就和我们上次课讲的一样, 具有自己调整权重的能力, 也就是调整这个w1和w2.
我们这个简化出来的模型,正是所有人工神经网络的祖母-感知机。 从名字可以看出,人们设计这个模型的最初目的就是像让它像真实的生物神经元一样,做出感知和判断。 并且从数据中学习。
感知机算是最早的把连接主义引入机器学习的尝试。 它直接模拟Warren McCulloch 和 Walter Pitts 在1943 提出而来神经元的模型, 它的创始人 Rosenblatt 事实上制造了一台硬件装置的跟神经元器件装置。
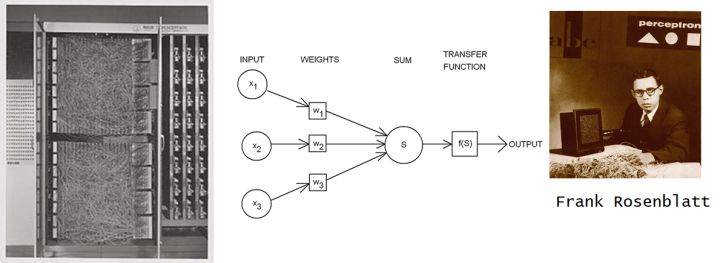
把数学神经元变成机器
你要是想理解这个过程。最好的方法是几何法。你仔细观察, 这个感知机的方程, 如果只有两个特征的时候, 描述的就是一个x1和x2坐标的平面, 中间有一条直线w1x1+w2x2=0,直线的左边是一类, 右边是二类 。感知机的学习过程就是调整这条分类直线的位置,我们测量错分点到这条线的距离之和,调整线的位置, 直到两个类的点乖乖分布到直线两边,我们就实现了分类过程。
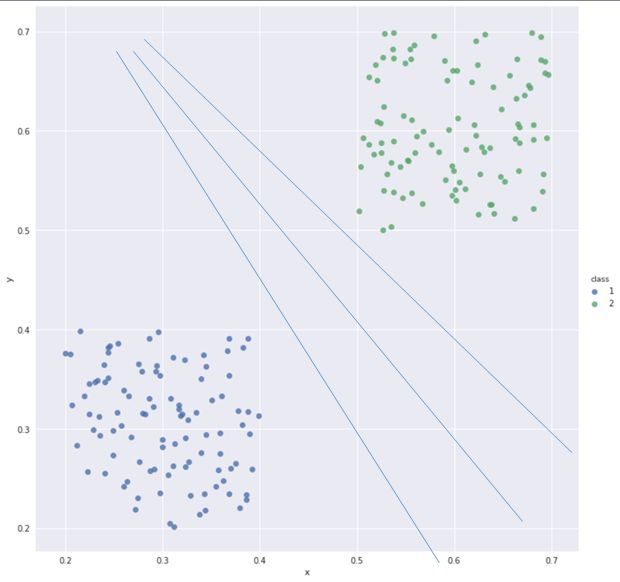
一个神经元相当于一个分类器
这其实就是一个神经元的偏好。 比你让一个神经元帮你确定是否去看电影的例子。它根据今天的温度,一个是电影的长度来判断, 当然一开始它不了解你, 但是它可以先帮你做做决策, 然后根据你每次给他的反馈意见它调整自己,如果你注重温度,它就加大温度的权重,总之找到你看重的东西, 这就是感知机训练的方法白话版, 如果你给他肯定意见,他就不做改变, 你不满意, 他就变一变。
最初的感知机采用阈值函数作为神经元的决策(激活)函数。后来这个函数逐步被调整为sigmoid函数。表现上看, 这个函数把阈值函数进行了软化, 事实上, 它使得我们不是仅仅能够表达非黑即白的逻辑, 而是一个连续变化的概率。 而这个函数的扩展softmax则可以帮助我们实现多个分类的选择。
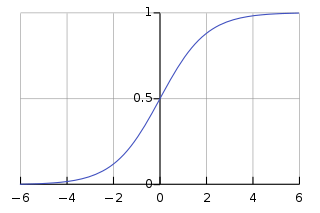
sigmoid 函数
我们说, 这一类模型开始被人们寄托重大希望, 不久却落空。原因在于, 它真是太简单了。 在几何上, 无论怎么变它都只是一个线性的模型。 而事实上, 这个世界却是非线性的。
三 神经网络降伏非线性
什么是非线性, 我们举一个经典的机器学习的房价的例子,首先这是一个经典的线性问题。 我们通常用线性模型描述房价的问题。 把各个影响因子线性的累加起来。比如我们把问题简化为卧室数量, 面积 ,地段, 最后求成交价。 我们用线性模型求解价格。 然而, 着一定不是真实的情况, 这背后的关键假设是,我们的卧室数量,面积, 地段都会独立的影响房价, 这就好像说, 如果你有几个不同的因素, 某个要素变化, 不影响其它要素最终决定房价的方式,我们具体来说, 还是房屋单价只受地段, 距离地铁远近,卧室数量三个要素影响,假定三者的权重是w1,w2, w3. 如果你去改变地段,那么w2,和w3必须是不变的。 就拿海淀和朝阳来说,对这两个区, w2 和w3 是一致的。 事实上呢? 显然这三个要素互相制约,或许海淀的人都做地铁, 朝阳的有车的比较多, 它们对距离地铁远近的敏感就不同, 或者说海淀的单身汉比较多, 朝阳的成家的比较多, 朝阳的就更喜欢卧室多的大户型。 如何表现这种特征之间的相互依赖关系呢? 一个天然的解决方法,就是: 网络模型
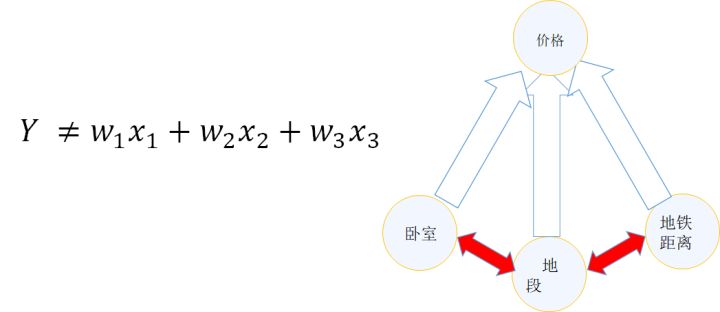
看看人类可能是怎么处理这些信息的, 人对于这种复杂的信息, 往往采用的是陪审团模式, 我们可能有好几个房价专家, 就自己了解的方向去提供意见, 最后我们再根据每个人的情况综合出一个结果。虽然这个时候我们失去了简单的线性, 但是通过对不同意见单元的归纳, 和集中的过程, 就可以模拟更复杂的问题。
再看看怎么把它变成数学处理房价问题。 首先把他表示成公式, 他其实是说的是
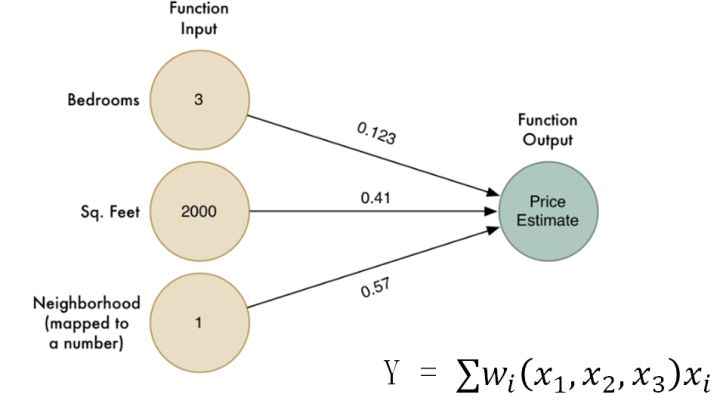
系数变成了和x有关的, 仔细想一下,这不就是增加了一个新的层次吗,我们需要再原始特征x1和x2的基础上, 增加一个新的处理层次, 让不同的特征区域, 享受不同的权重 。 就好比我们有好几位房价评估师,每一位都是针对某种情况下房价的专家,最后有一个人, 根据专家的特长给出最终的综合结果。这与我们的灵感是相符的。
我们把他表示成图示方法。 首先, 每个专家都仿佛是一个小的线性模型, 它们具有唯一的一组权重, 显示它们再所熟悉的区域的权威。
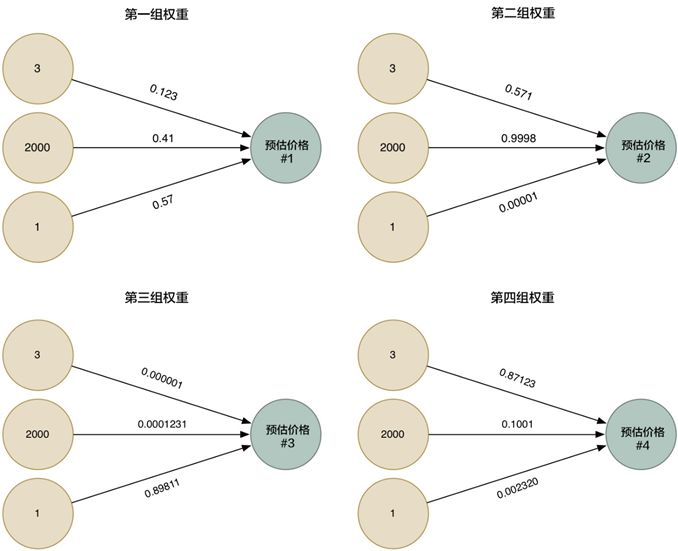
图片改编自网络博文Machine Learning is Fun! by Adam Geitgey
然后,我们把它们汇总起来, 得到下面这个图, 这个图和之前我们讲解线性回归的图是一样的, 但是我们增加了一个中间的层次,这就是刚刚说的陪审团, 哪些中间的位置, 事实上就是表达了特征之间复杂的互相影响。而最终我们把它们的意见综合起来, 就是最终的结果。
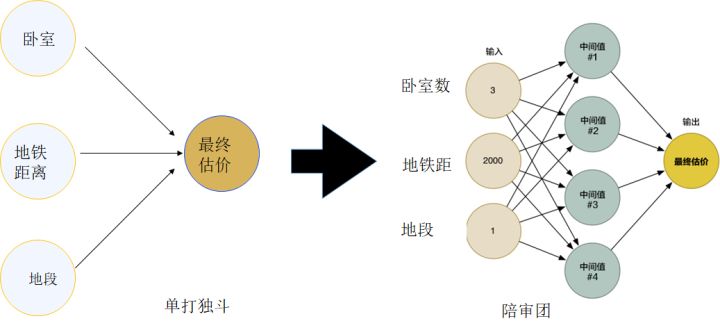
你换个角度思考, 那些中间的绿色圆圈, 也就是说每个专家,不就是神经元吗? 而那个黄色圆圈, 是最终决策的神经元。 这样的一个组织, 而不是单个神经元, 就是神经网络的雏形。
当然, 房价的问题是个回归问题, 而这个世界的大部分机器学习问题是分类, 每个神经元也是一个小小的分类器, 所以我们把每个神经元的角色变成线性分类器,再套用刚刚陪审团的逻辑, 看看我们得到了什么: 每个线性分类器, 刚刚讲过都是一个小的特征检测器, 具有自己的偏好,这个偏好刚好用一个直线表示, 左边是yes,右边是no, 那么多个神经元表达的是什么呢? 很多条这样yes or no的直线! 最终的结果是什么呢? 我们得到一个被一条条直线割的四分五裂的结构, 既混乱又没用! 这就好比每个信息收集者按照自己的偏好得到一个结论。幸好我们有一组头顶的神经元, 它就是最终的大法官, 它把每个人划分的方法, 做一个汇总。 大法官并不需要什么特殊的手段做汇总, 它所做到的,无非是逻辑运算, 所谓的“与”, “或”, “非”, 这个合并方法,可以得到一个非常复杂的判决结果。 你可以把大法官的工作看成是筛选, 我们要再空间里筛选出一个我们最终需要的形状来, 这有点像是小孩子玩的折纸游戏,每一次都这一条直线, 最终会得到一个边界非常复杂的图形。 我们说, 这就是一个一层的神经网络所能干的事情。 它可以做出一个复杂的选择, 每个神经元都代表着对特征的一个组合方法,最后决策神经元把这些重组后的特征已经刻画了不同特征之间的关系, 就可以干掉认识现实世界复杂特性-非线性的能力, 特征之间的关系很复杂, 我也可以学出来。
所谓神经网络的近似定理, 是说一个前馈神经网络如果具有线性输出层和至少一层具有任何一种‘‘挤压’’ 性质的激活函数(例如logistic sigmoid激活函数)的隐藏层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的Borel 可测函数。 这是关于神经网络最经典的理论了,简称万能函数逼近器。
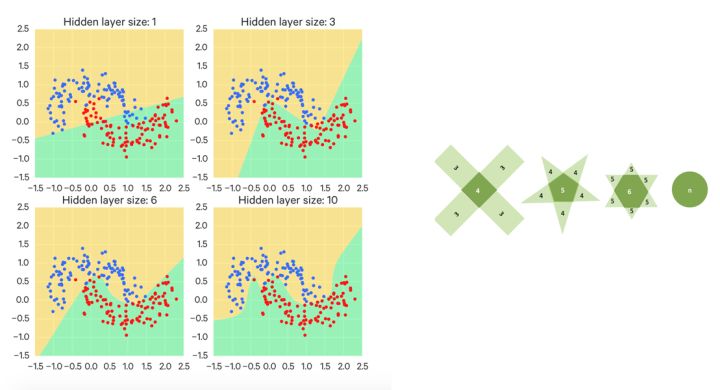
另外的一种理解是,神经网络具有生成非常复杂的规则的能力, 如果你可以让神经网络很好的学习, 他就可以自发的去做那些与或非, 和逻辑运算,不用你自己写程序就解决非线性问题。
四 关于神经网络的学习
是什么阻止了神经网络从出现之后很快的发展, 事实上是它们非常不好学习。
我们说神经网络能够成为一种机器学习的工具关键在于能够学习,那么如何学习的呢? 如果说单个神经元可以学习的它的偏好, 通过调整权重来调整自己的偏好。 那么神经网络所干的事情就是调整每个神经元和神经元之间的联系, 通过调整这个连接, 来学习如何处理复杂的特征。
说的简单, 这在数学上是一个非常难的问题。 我们通常要把一个机器学习问题转化为优化问题求解。 这里, 神经网络既然在解决非线性问题, 事实上和它有关的优化又叫做非线性优化。
先看生物神经网络的学习, 它是通过一种叫做可塑性的性质进行调节的。 这种调控的法则十分简单。说的是神经细胞之间的连接随着它们的活动而变化, 这个变化的方法是, 如果有两个上游的神经元同时给一个共同的下游神经元提供输入, 那么这个共同的输入将导致那个弱的神经元连接的增强, 或者说权重的增强。 这个原理导致的结果是,我们会形成对共同出现的特征的一种相关性提取。 比如一个香蕉的特征是黄色和长形, 一个猴子经常看到香蕉, 那么一个连接到黄色和长形这两种底层特征的细胞就会越来越敏感, 形成一个对香蕉敏感的细胞,我们简称香蕉细胞。 也就是说我们通过底层特征的“共现” 形成了对高级特征的认知。 上述过程被总结hebbain学习的一个过程。
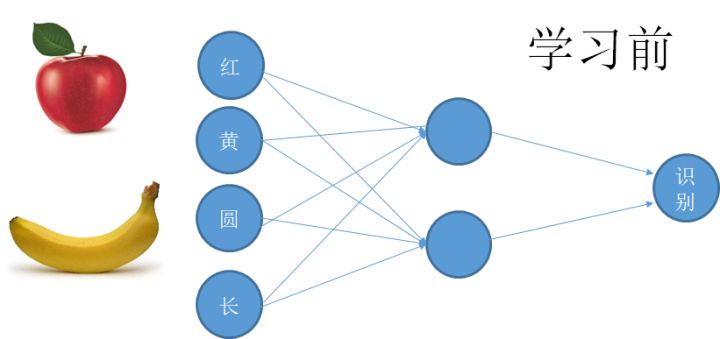
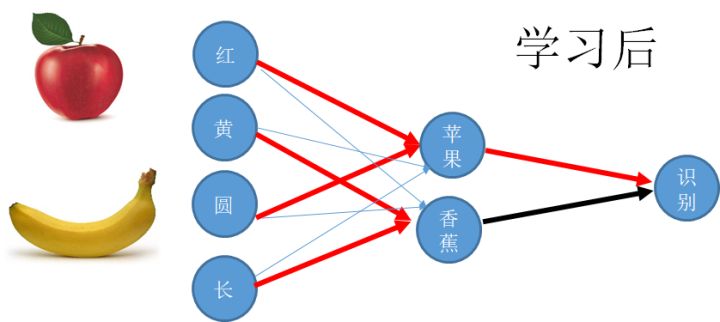
从本质上说, 刚刚说的过程是一种无监督学习,你接受输入引起神经活动, 它慢慢的调整。 如果用这样的方法训练人工神经网络,恐怕需要跑一个世纪。 人工神经网络的训练依赖的是监督学习,一种有效的结果导向的思维,如果我要它判断香蕉和苹果, 我就是要一边给它看图片, 叫它告诉我是什么 ,然后马上告诉它对错, 如果错了,就是寻找那个引起错误的神经连接。 然而这个过程在数学上特别的难以表达, 因为一个复杂网络的判断, 引起错误的原因可能是任何中间环节 ,这就好像调节一大堆互相关联在一起的参数,更加可怕的是, 神经网络往往有很多层, 使得这些参数的相关性更加复杂, 如果你一个个去试探, 那个感觉就是立即疯。
最终, 这个问题被BP算法的提出解决。 BP反向传播算法, 是一种精确的根据最终实现的目标,然后通过比较当下输出和最终目标的差距, 然后一级反推如何微小的改变各级连接权重以减少这种误差的方法。 这其实就是梯度下降结合复合函数求导法则的一个更复杂的形式。 我们通常把一组刚刚到来的数据, 扎成一捆喂给神经网络, 让它计算出一个输出, 这个输出当然会错的很离谱, 然后我们把这个结果和我们真正需求的比较得到一个误差信号, 这个误差信号会一级一级的改变所有的连接权重。 每一捆数据, 被称为一个tensor, 都像一个个子弹一样塑造着整个网络。 对于这个方法的理解, 最好的办法是使用一套由tensorflow提供的可视化工具。
当然这仅仅是一个神经网络的训练的简短小节, 当你在神经网络坚守的Hinton这样的大神,事实上提出过对学习算法的无数改进细节, 才有了它今天的成功。
五 关于多层神经网络,深有什么好处?
刚刚说的方法你可以理解一个一层的神经网络, 那更多层的神经网络呢?深层的神经网络究竟有什么好处?事实上深度学习的深,就是指神经网络之神,可见这是奥妙的门道。
用一句化说,一层的神经网络可以对特征做一次变换,就如同得到了一组新的特征, 这种特征的变换, 用数学家的眼光就是做了一个坐标变换, 兑换到一个新的空间。
我举一个最小的例子让你理解。 你记得高中学过的直角坐标系和极坐标系吧, 这两个坐标系之间存在一个经典的坐标变换公式。 这就可以看作一个坐标变换。 我们举一个例子看,如果要做一个分类器, 把一些居住在圆形中心的点和它的外周分离开来, 那么这个坐标变换就有奇效。
多层网络, 就代表一个多次连续的特征变换,最后会把数据从一种性质变到另一个性质,从一个空间拉到另一个空间。最终总有一个空间, 这些数据呆着最合适。这种行为,简称为表征学习(representative learning)。
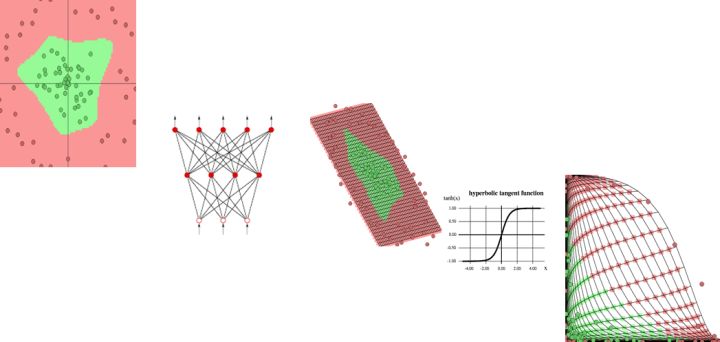
表征学习顾名思义,是要一种特征转化为另外的特征,因为简单的特征一旦发生关系就可以构成复杂的特征,刚刚那个处在领头的大法官和司令再次变成士兵,给上层的决策者提供信息,隐层神经网络所作的事情,我们说其实就是对特征进行重组, 然后得到一组新的特征的坐标变换, 只不过这个变换的形式是可以学习的。 我们说,越限制, 就越自由,为了更好的学习, 我们会限制神经元对信息的处理只由两部分组成, 一个是用一定的权重组合上层的特征, 另一个是通过某个样子的激活函数把这个总和变一变。
多层的神经网络, 通过多次的基变换, 把特征一次次重组,得到越来越复杂的新的特征, 这就是深度神经网络作用的机制。 某种程度上, 它把这种层级特征强加给了它要识别的事物, 但是假定事物本身也是这种按照一层层的方法搭建起来, 那么神经网络就会取得奇效。
哪些事物是有这种层级结构的呢? 我们说,所有的感知信号都是, 从视觉, 到听觉,到语言。 假定你看着一个屏幕, 你真正看到的是每个像素点, 而最终你要组合成为一个可以认知的图象。 假定你听着的是声音, 你最终需要分辨出一个个单词 ,句式,直到语言。
认知科学里说,抽象使得不同的事物可以在更深的层次上被联系起来, 的就是说, 不同层次的函数迭代,产生的新的空间(某种程度也是降维,比如图形处理中),使得原先的距离概念被打破,具体怎样被打破。 这正是人脑处理信息的本质。 实验表明,越靠近感官的神经元处理的信息就具体, 比如颜色,亮度, 而经过多级处理,达到皮层之后, 我们的神经元就可以对比较抽象的实体,如人名,物体的种类敏感。
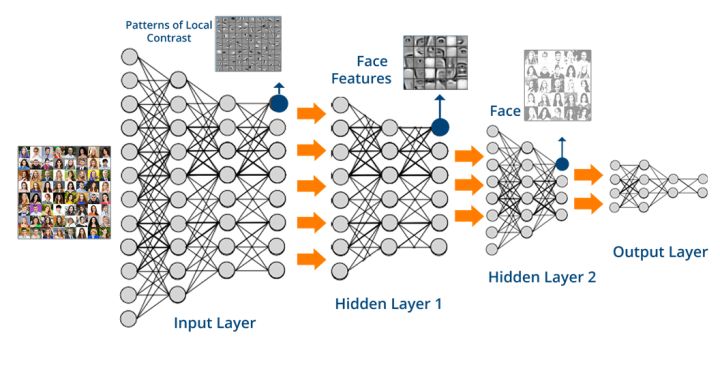
当然,这只是最形象的一个描述,关于增加深度相比增加宽度对神经网络功能的好处,是整个深度学习问题的焦点问题之一。因此引出了几个不同的数学观点, 有机会给大家总结。
训练深度神经网络是困呐的,由于神经网络的训练里有大量的复杂求导运算, 我们是不是函数要写死为止? 其实不是, 我们有一个强大的框架, 就是tensorflow,让你的整个求导过程十分容易。你只需要写出你的目标函数cost function,然后简简单单的调用tensorflow内部的optimisor就可以了。
六 神经网络动物园
神经网络经过这些年的进化,已经是一个大家族。 我们来看几个具体的神经网络
Auto-encoder 自编码器:
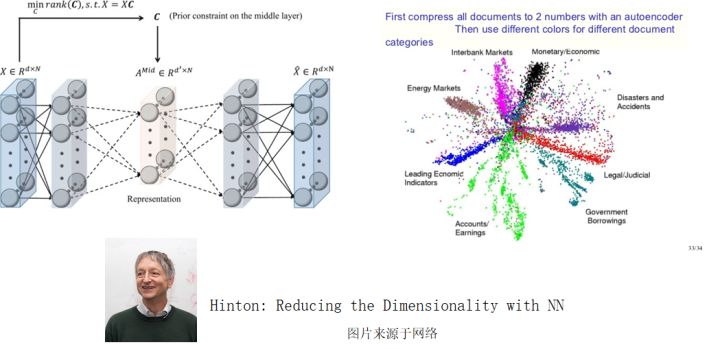
最早成功的一种深度神经网络,自编码器意如其名, 其实做的就是对数据进行编码, 或者压缩。 这种网络通常具有的特点是输出的长度或者说大小远小于输入,但是神奇的是, 这个输出却保留了数据种的大部分信息。 你是不是想到了上节课介绍的PCA了呢? 是的, 这就是一种降维的模型。 这个模型的实质, 也就是一个复杂, 或者说是非线性的降维操作, 比如说你把一张图象压成很简单的编码。 由于这种输入多输出少的性质, 自编码器的形状形如一个下夸上窄的漏斗, 数据从夸的一面进来, 出去的就是压缩的精华。 自编码器之所以在神经网络的进化历史里举足轻重, 是因为它在回答一个很核心的问题, 那就是在变化的信息里那些是不变的, 这些不变的东西往往也就是最重要的东西。比如说人脸, 你把1万张不同的人脸输入到网络里, 这些人类分属于十个人, 那么按说, 很多照片无非是一个人的不同状态,它的不变性就是这个人本身。 这个网络能够把数据最终一步步的集中到十个维度就够了, 这样, 最终可能用一个十位数的数字就可以压缩整个数据集。 而这, 正是神经网络, 甚至是人类理解事物的关键, 那就是找出纷繁变化事物里的不变性, 它对应的正是一个概念。 抓住了概念, 就抓住了从具象到抽象的过程, 抓住了知识,抓住了人认知的关键所在。 深度学习大师Hinton早期的核心工作,正是围绕自编码器。
卷积神经网络:
卷积神经网络就是模拟人类是视觉的一种深度神经网络。这个网络的特点是能够把图象数据,像photoshop 里的滤镜一样, 被过滤成某种特征图,比如纹理图, 这些低级的特征图, 将再次被过滤, 得到一个新的特征图, 这个特征图的特点就是更抽象, 还有更多的刚刚讲过的概念性的特征。 比如一个物体的形状轮廓。 直到最后一层, 得到对某类物体概念的认知。 这就是人类视觉知识形成的过程。 也是我们下次课的重点。
含时间的神经网络:
神经网络不仅能够描述静态的各个特征之间的关系, 而且能够描述特征(这里更好叫因子)之间在时间上的复杂相互作用关系, 一个神经网络的做出的含时间过程, 最好的例子就是含有证据积累的决策过程。 即使是单个神经元, 也可以把不同时间的信息积累起来做个决定, 而动态的神经网络, 就可以更好的把这些证据总体的汇集起来。
总的来说 , 几个神经元组成的网络, 可以像一个信息的蓄水池一样, 通过互相喊话, 把过去的信息在自己人之间流传起来, 从而产生类似于人的记忆的效应, 这些通过特定方法连接在一起的神经元, 就可以形成人的工作记忆或内隐记忆, 而同时, 也可以帮我们设定出处理和时间有关信号的神经网络工具, 这就是RNN – LSTM家族, 以及其它的长时间记忆网络。

在深度时间序列处理种扮演重要核心角色的LSTM,其创始人schmidhuber却无缘此次图灵奖。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


理论篇)















)

