基于Grad-CAM与KL损失的SSD目标检测算法
人工智能技术与咨询
来源:《电子学报》,作者侯庆山等

摘 要: 鉴于Single Shot Multibox Detector (SSD)算法对中小目标检测时会出现漏检甚至错检的情况,提出一种改进的SSD目标检测算法,以提高中小目标检测的准确性.运用Gradient-weighted Class Activation Mapping (Grad-CAM)技术对检测过程中的细节作可视化处理,并以类激活图的形式呈现各检测层细节,分析各检测层的类激活图发现SSD算法中待检测目标的错检以及中小目标的漏检现象与回归损失函数相关.据此,采用Kullback-Leibler (KL)边框回归损失策略,利用Non Maximum Suppression (NMS)算法输出最终预测框.实验结果表明,改进算法相较于已有检测算法具有更高的准确率以及稳定性.
关键词: 目标检测;可视化;类激活图;Grad-CAM;SSD;KL损失
1 引言
目标检测技术的不断完善和发展,引起智能化交通系统[1]、智能监控系统[2]、军事目标检测[3]及医学导航手术中手术器械定位[4]等领域的广泛关注,是计算机视觉领域的核心技术之一.在国内外相关研究机构的努力下,高效的目标检测算法如雨后春笋般层出不穷,如基于单阶段过程的You Only Look Once (YOLO)算法[5]、SSD算法[6]、基于双阶段过程的Region with CNN features (R-CNN)算法[7]等.
针对SSD算法在中小目标检测中漏检甚至错检的问题,Wen,Zhan[8]等人改进原SSD算法的激活函数,并引入Atrous滤波器.Wu[9]等人在传统的SSD检测算法中加入转置卷积结构,将低分辨率、高语义与高分辨率、低语义的输出特征图进行融合.针对图像中某些待检测目标被遮挡的情况,Xing[10]等人根据检测目标的分布规律调整了输出特征层的缩放系数,一定程度上解决了漏检问题.Tang[11]等人提出了多视窗的方法,但由于该方法存在目标被拆分检测等问题,使得其准确性及稳定性受到影响.针对SSD模型的低特征层,Chen[12]等人采用区域放大提取的方法提升了算法的中小目标检测能力.Fu[13]等人提出Deconvolutional Single Shot Detector (DSSD)模型,但其网络结构也随之变得更复杂,导致模型的检测实时性下降.Jeong [14]等人提出的Rainbow Single Shot Multibox Detector (RSSD)模型改进了特征融合的方式,对各输出层特征更加充分的利用,提升算法对中小目标的检测效果.Li[15]等人通过特征融合与下采样的方法获取更多输出特征层细节信息,从而提出Feature fusion Single Shot multibox Detector (FSSD)目标检测模型.
为了方便对SSD算法在中小目标检测方面性能的提高,本文引入可视化技术[16]对原算法的检测过程进行分析,优化了原算法的损失函数.改进后的检测算法对中小目标的检测能力更强,总体检测效果更好,并且目标漏检、错检问题也得到相应改善.
2 相关研究
2.1 SSD模型
SSD算法使用多尺度特征层进行目标检测,是一种直接预测目标类别和边界框的多目标检测算法.与双阶段过程的目标检测算法相比SSD算法将所有计算在单阶段过程中进行,没有候选框区域的生成和后续特征重采样阶段的过程,提升了SSD算法的检测速度.该算法以Visual Geometry Group 16 (VGG-16)[17]为基础网络,中上部分采用采样金字塔结构[18],将最后两个全连接层替换为卷积层,并在其后增加四个卷积层.
2.2 KL损失函数
现有的目标检测算法在大规模数据集上进行某些边界框标定时存在歧义.KL损失[19]针对边界框的移动与位置间的方差进行学习,在同等计算量下提升不同结构定位的准确率.KL边界框回归损失可以获取到数据集中的模糊,从而降低预测边界框的回归损失.
基于对Faster R-CNN[20],Mask R-CNN[21]检测网络的认知,KL损失将原本的回归框参数由(x,y,w,h)替换为(x1,y1,x2,y2),这样便于在每个维度上单独优化,预测边界框与真实边界框的偏差可由式(1)表达.

(1)
(x1,y1,x2,y2)表示预测边界框左上角和右下角的坐标,

表示真实边界框左上角以及右下角的坐标.(x1a,x2a,y1a,y2a,wa,ha)是由真实边界框聚类产生的锚框.
KL损失重点评估位置的置信度,在预测位置的同时给出置信度.假设坐标间互相独立并使用单变量高斯模型,将边界框坐标表示为x,单独对每个坐标进行独立优化,可由式(2)表达.
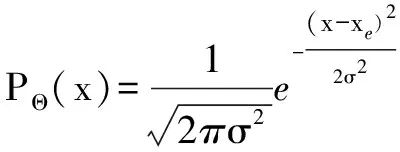
(2)
式(2)中Θ表示一组要学习的参数,xe表示预测边界框的位置,xe∈(x1,y1,x2,y2),σ表示位置估计的置信度.
真实边界框也可以表示为σ→0的高斯分布,如式(3)所示.式(3)中的xg表示真实边界框的位置.
PD(x)=δ(x-xg)
(3)
选取N个样本,将这些样本的预测边界框分布PΘ(x)和真实边界框分布PD(x)之间的误差最小化,进而对

进行评估,获取位置定位的目标,可由式(4)表达.

(4)
基于KL损失的检测算法中,边界框回归的损失函数采用KL损失,对于单个样本的边界框回归损失由式(5)定义.
Lreg=DKL(PD(x)‖PΘ(x))
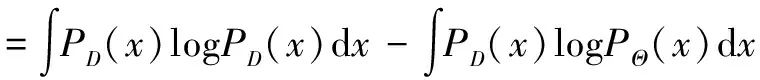

(5)
xe表示预测边界框的位置,当预测边界框的坐标位置不准确时,网络通过预测更大的方差σ2,使回归损失降低,由于式(5)中的后两部分与参数Θ无关,得式(6).
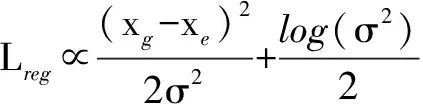
(6)
当σ=1时,损失变为欧氏距离,如式(7).

(7)
对式(6)中预测边界框的位置估计和定位标准偏差σ分别求偏导,如式(8)、(9)所示.
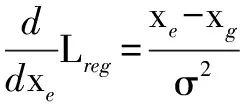
(8)

(9)
为了防止在训练开始时发生梯度爆炸,令α=log(σ2),在进行测试时,将α重新变回为σ,变换后的损失可由式(10)表达.

(10)
用随机高斯分布对全连接层初始化,KL损失在开始训练时类似于smooth L1损失,当│xg-xe│>1时,损失可定义为式(11).

(11)
2.3 类激活图
为解决卷积神经网络模型中的不可见问题,通过Grad-CAM技术[22]可将网络模型对输入图像中感兴趣的区域表示出来,将网络模型可视化,直观的表达了算法得出分类结果的原因.在Grad-CAM技术中,利用类别输出结果对卷积层的输出特征图求导获取特征激活图,由式(12)计算得到权重值
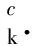
将与特征图累加得到可视化结果,权重说明了类别c对特征映射的重要度.
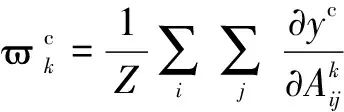
(12)
通过ReLU函数除去特征图上负值对分类结果的影响,最终的分类任务由式(13)、(14)表达.

(13)

(14)
3 改进框架设计
3.1 SSD检测算法的可视化
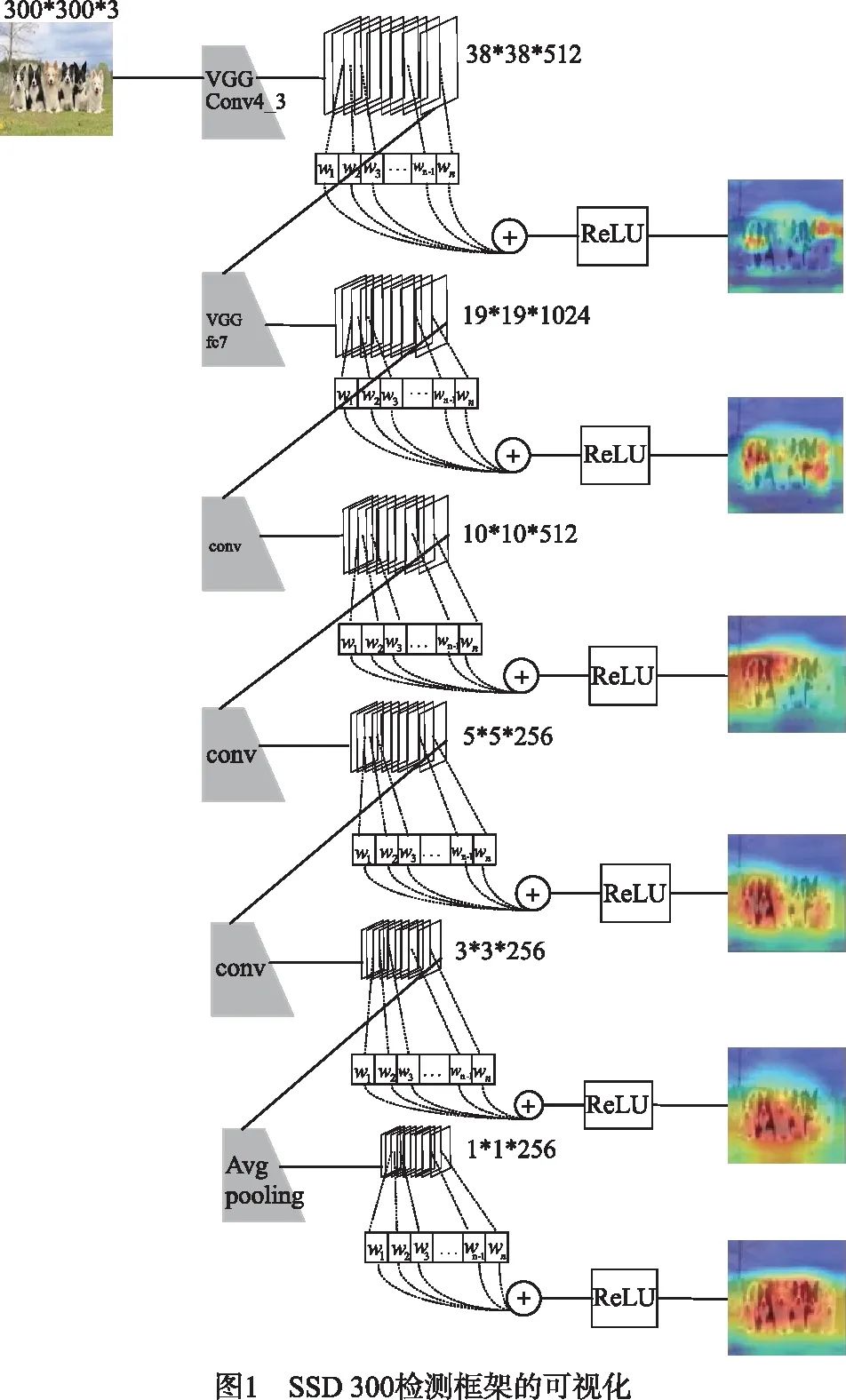
Grad_CAM技术根据输入图像中各目标的类别标签判别目标区域.将该技术运用到SSD检测算法,使该算法的执行过程可视化,针对用于目标检测的各卷积层,对这些层的特征输出层进行分析,构建各检测层的类激活图.
SSD检测算法的可视化,能够更好的理解网络的目标检测过程,通过分析类激活图,得出中小目标检测不准确或漏检的原因,针对该原因做出相应的改进策略,提高检测效率.SSD 300目标检测算法的可视化过程如图1所示.
3.2 基于KL损失的SSD算法
3.2.1 默认框设定
检测算法沿用了原SSD算法中默认框的设定方法,针对多个目标检测层的输出特征图进行设定,对于特征图中的每个像素点生成大小不同的两个正方形及多个长方形默认框.比例值ar的数目决定了特征输出图中某一像素点下默认框的数目,默认框的大小取决于Sk值的设定,默认框的长和宽可由式(15)、(16)进行表达.

(15)
其中m为特征图的个数,Smin=0.2 ,Smax=0.9.

(16)
其中默认框长宽比ar∈(1,2,3,1/2,1/3),另外设置一个
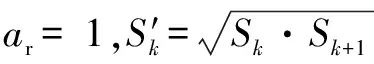
的默认框.默认框中心点的位置可由式(17)计算.
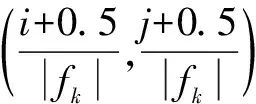
(17)
其中│fk│为第k个特征图的大小,i,j∈[0,│fk│].
3.2.2 正负样本标定
利用检测算法对输入图像中的目标进行检测时,需要对默认边界框进行类别标定.通过IoU值进行匹配,IoU值由式(18)定义.对于每一个待检测目标的真实边界框,对应默认边界框的匹配规则如下:设定IoU的阈值为0.5,当默认边界框与真实边界框的IoU值大于0.5时,将此默认边界框标定为正例样本,否则标定为负例样本.
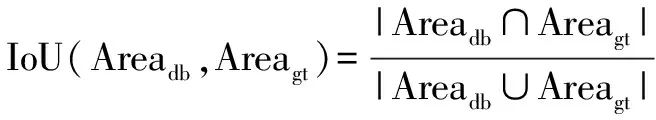
(18)
其中Areadb,Areagt分别表示默认边界框与真实边界框的面积.
3.2.3 损失策略
改进的SSD目标检测算法的训练损失由目标分类损失和预测边界框的回归损失两部分组成,改进算法训练损失可由式(19)表达.

(19)
式中N为正例样本数,α表示用于控制分类损失和回归损失的比重.
目标分类损失采用交叉熵损失[23],损失由式(20)表达.
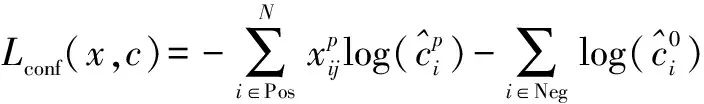
(20)

表示的是第i个默认边界框与第j个真实边界框关于目标类别p是否匹配,当时不匹配,时匹配.
预测边界框的回归损失采用KL损失,回归损失由式(21)定义.
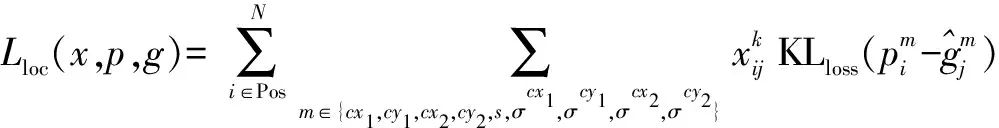
(21)
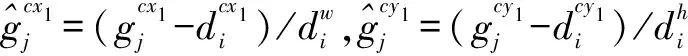


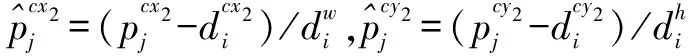
式中p,g分别表示预测边界框和真实边界框与默认边界框之间的偏移量,在边界框的回归损失中,通常期望p和g差距较小.
对经过NMS算法处理后所选中的边界框位置投票,选择最大得分边界框M{x1,y1,x2,y2,s,σx1,σy1,σx2,σy2},根据自身和相邻边界框的参数更新坐标位置,邻近边界框权重值Pi和新坐标的计算式由式(22)定义.
pi=e-(1-IoU(bi,b))2/σt

(22)
式中σt表示变量投票表决时的可调参数.
4 图像数据预处理
为增强检测算法的通用性和稳定性,采取数据增广的方法对数据预处理.通常将图像目标区域分割掩码中像素数量小于1024的目标定义为小目标,大于1024且小于9216的目标定义为中等目标.为此,针对改进的SSD算法制定如下数据增广规则:
(a)对原始的输入图像进行随机位置的采样,采样图像与原始图像的比例取1/64、1/32、1/16、1/8、1/4、1/2、1.
(b)对采样图像以一定的概率作翻转和裁剪处理.
(c)对采样图像以一定的概率添加色彩变换.
与原SSD算法的采样比例相比,更小的采样比例可以使得由随机采样得到的小目标经过图像尺寸恢复后被更明显的表示出来.
5 实验设计
5.1 实验数据集说明
以PASCAL VOC和MS COCO 2017三种数据集为基础,设计相关实验数据集,数据集的说明如下:
选取MS COCO数据集中的30类目标作为检测类别.分别从MS COCO和PASCAL VOC数据集的训练集中选取3000张和2000张带有检测类别的图像,将选取的5000张图像作为训练集;从MS COCO数据集的验证集中选取1000张图像作为验证集,用于调控模型的超参数,监测过拟合现象;分别从MS COCO和PASCAL VOC数据集的测试集中选取800张图像作为检测算法的测试集.
5.2 实验相关过程描述
基于设计好的实验数据集,对改进的SSD目标检测算法进行训练测试.改进的SSD目标检测算法采用了随机梯度下降的方法,对改进算法的初始学习率、动量、权重大小、批量等参数进行设定.检测算法在训练数据时将初始学习率设定为0.001,对训练集中的图像进行30000次的迭代训练;进一步将学习率设定为0.0001,对训练集中的图像进行10000次的迭代训练;最后将学习率下降至0.00005,对训练集中的图像进行10000次的迭代训练.此外,设置IoU阈值为0.5,利用验证集对超参数进行调节,监测过拟合现象.
利用测试集对训练好的改进目标检测算法进行测试,与原算法的mPA及fps值作对比,体现改进检测算法的优势,验证算法改进的合理性和有效性.
5.3 实验结果分析
5.3.1 各检测层结果对比
检测算法的低检测层对小目标特征进行提取,对原SSD目标检测算法中各检测层的检测效果进行测试,与原检测算法相比,改进算法对小目标检测的准确度明显提升,检测精度提升约12%.计算原算法和改进算法各检测层的mPA值和fps值,如表1所示.
表1 目标检测算法各检测层mPA值和fps值对比
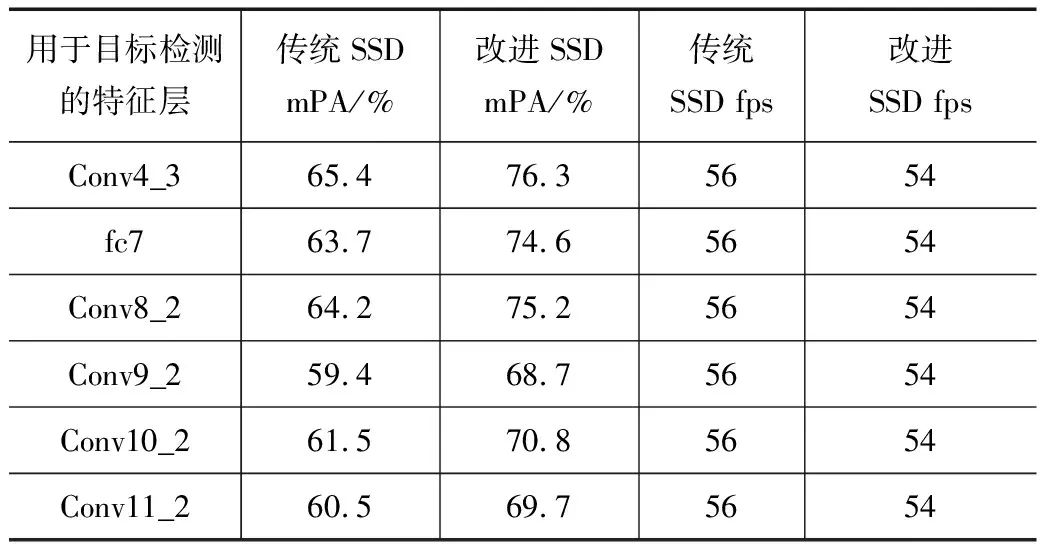
由表1数据可知,改进后的低特征层对小目标的检测效果提升明显,能够收集到更丰富的语义信息.通过fps值的对比,改进后的SSD目标检测算法保持了良好的检测实时性,SSD算法得到明显改进.
5.3.2 SSD相关改进算法对比
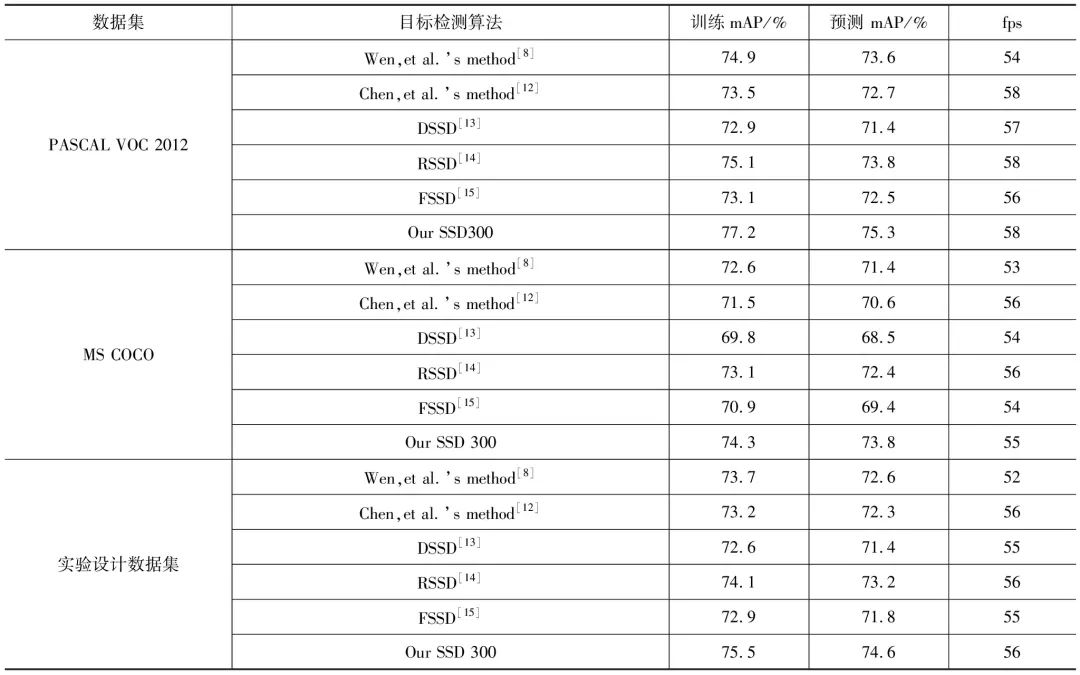
对现有的一些SSD改进算法在相关数据集上训练和预测, 将训练和预测结果与改进的SSD 300目标检测算法做对比,对比结果如表2所示。
分析表2可知,与选取的SSD改进算法相比,本文提出的改进算法检测精度有较明显的提高,算法的检测实时性得到较好保持.
表2 SSD相关改进算法mPA和fps对比
5.3.3 常见目标检测算法框架对比
对现有的一些目标检测算法在实验设计数据集上训练和预测,将训练和预测结果与改进的SSD目标检测算法做对比,对比结果如表3所示.
将改进算法训练过程的mPA值与YOLO、YOLOv2算法训练过程的mPA值对比,对比结果如图2所示.另外选取基于两阶段过程的Fast R-CNN、Faster R-CNN算法,训练过程的mPA值对比结果如图3所示.


对比改进算法与原SSD算法训练过程的mPA值,对比结果如图4所示.

与现有的目标检测算法对比,改进后的SSD目标检测算法检测精度有较明显的提高,算法的检测实时性较好.一方面,对原SSD目标检测算法的损失策略进行改进,进一步缩小了检测算法训练时的损失;另一方面,针对图像中的中小目标做出相应的图像增广策略,
表3 目标检测算法mPA和fps对比

使得检测算法对中小目标特征的收集更加全面,提高了对输入图像上中小目标的检测精度.
5.3.4 效果图对比
将改进算法的检测效果图与原算法的检测效果图进行对比,对比效果图如图5、6所示.改进后的SSD目标检测算法对输入图像中的中小目标能够更加精准的检测和分类,对由于遮挡现象造成的目标漏检问题有良好改善.在复杂场景中,与原SSD检测算法相比,改进的SSD目标检测算法能够检测到更多的目标;在简单场景中,改进算法对待检测目标类型的判别更加精确,目标的正确分类得分更高。此外,在处理模糊场景及小目标场景时,改进算法能够检测到更多的模糊目标与小目标。


6 结束语
改进的SSD目标检测算法提高了原SSD目标检测算法的稳定性和准确率,改善了在遮挡情况下造成的目标错检现象,对中小目标的检测效果有明显的提升.改进算法的贡献主要体现在以下方面:
(1)对SSD目标检测算法进行可视化,分析SSD目标检测算法的检测过程.
(2)针对原算法的不足,改进了输入图像的增广策略.
(3)基于对可视化结果的分析,优化了传统SSD目标检测算法的边界框回归损失.
(4)利用改进的NMS算法输出目标的预测边界框.

我们的服务类型
公开课程
人工智能、大数据、嵌入式
内训课程
普通内训、定制内训
项目咨询
技术路线设计、算法设计与实现(图像处理、自然语言处理、语音识别)





















