文章目录
- abstract
- 1.introduction
- 2. our approach
- 2.2 微调fine tuning
- 3.Model
- 3.1QA Model
- 3.2QG model
abstract
本文研究了基于知识库的问答系统的性能改进问题生成技术。问题生成(question generation,
QG)的任务是根据输入的答案生成相应的自然语言问题,而问答(question answer,
QA)则是针对给定的问题寻找合适答案的逆向任务。对于KBQA任务,可以将答案视为包含一个谓词和知识库中的两个实体的事实。培训一个有效的KBQA系统需要大量的标记数据,这些数据很难获取。而经过训练的KBQA系统在回答训练过程中不可见谓词对应的问题时仍然表现不佳。为了解决这些问题,我们提出了一个统一的框架,在知识库和文本语料库的帮助下,将QG和QA结合起来。首先在金数据集上对质量保证(QA)和质量保证(QG)模型进行联合训练,然后利用由质量保证(QG)模型构建的补充数据集,借助文本证据对质量保证(QA)模型进行微调。我们使用Freebase知识库对两个数据集SimpleQuestions和WebQSP进行了实验。实证结果显示,我们的架构改善了KBQA的绩效,并与最先进的架构相媲美,甚至更好。
任务:使用问题生成和QA系统训练,达到半监督训练QA的目的
1.introduction
- KBQA:
- 自然语言提问
- 翻译成–>(subj实体,rel关系,obj答案)
- 将关系和实体链接到知识库中
- 挑战
- 开放领域下许多问题没见过
- 需要许多训练数据
- 关系检测更难
- 实体链接难
- 问题生成:由答案A生成相应q
- 受启发
- 利用问题生成(QG)来帮助阅读理解[16]和
- 回答选择句子[14]任务
在这项工作中,我们提出了一个统一的框架来结合QA和QG通过两个组件,包括双重学习和微调。与[14]类似,我们首先利用QA和QG之间的概率相关性来联合训练它们的模型。由于答案a在[14]中是一个句子,而在我们的KBQA任务中是一个三元组,所以我们设计了不同的方法来计算概率公式中相应的项。为了解决不可见谓词和短语的挑战,我们提出了一个微调组件。利用复制操作[10]和来自Wikipedia的文本证据,我们训练了一个序列到序列的模型,该模型可以根据从知识库中提取的三元组生成不可见谓词的问题。此外,可以通过提供生成的问题和从知识库中提取的三元组来优化QA模型
- 方法总述:
- 统一的框架来结合QA和QG通过两个组件,包括双重学习和微调
- 首先利用QA和QG之间的概率相关性来联合训练它们的模型
- 微调组件(解决不可见谓词和短语的挑战)
- 利用复制操作[10]和来自Wikipedia的文本证据,我们训练了一个序列到序列的模型,该模型可以根据从知识库中提取的三元组生成不可见谓词的问题
- 可以通过提供生成的问题和从知识库中提取的三元组来优化QA模型
- 本文贡献
- 首先,与以往的阅读理解和句子选择任务不同,我们研究了如何利用factoid QG来帮助KBQA任务。
- 其次,我们框架中的微调组件可以解决KBQA任务中不可见谓词和短语的挑战。
- 第三,实证结果表明,我们的框架改进后的KBQA系统与目前的水平相当,甚至更好
2. our approach
-
这项工作包括两个任务,
-
包括问题回答(QA)和
- 在自然语言处理社区中,QA任务可以分为基于知识的和基于文本的。
- KBQA中的答案是知识库中的一个事实,–本文关注这个–转化为评分fqa(q,a)f_{qa}(q,a)fqa(q,a)和排名问题
- 而文本QA中的答案是给定文档中的一个句子
- 在自然语言处理社区中,QA任务可以分为基于知识的和基于文本的。
-
问题生成(QG)。
-
fqa(q,a)f_{qa}(q,a)fqa(q,a):q和a的关联性
-
QA–简化为关系检测任务
- 假设实体已经检测到了,再找到关系,就可以确定答案a
- 输入
- 问题q
- 候选关系R={r1,r2,…,rn}
- 输出
- 最有可能的候选关系ri
-
QG
- 输入:以一个句子或一个事实a作为输入,
- 输出:一个问题q,
- 这个问题q可以由a来回答。
- 在这项工作中,我们把QG看作一个生成问题,并开发了一个序列到序列的模型来解决它。我们的QG模型简称为Pqg(q|a),其中输出的是产生问题q的概率。
-
通常,我们的框架由两个组件组成。
- 第一个是双学习组件,利用QA和QG之间的概率相关性,尝试将QA/QG模型的参数在训练过程中引导到更合适的方向。
- 第二个是微调组件,旨在通过使用文本语料库和知识库三元组涉及QG模型,增强QA模型处理不可见谓词和短语的能力。
- 我们的框架是灵活的,不依赖于特定的QA或QG模型。
- 最近的工作[14]提出了一个双重学习框架,通过利用QA和QG之间的概率相关性作为正则化项来联合考虑问题回答(QA)和问题生成(QG),从而改进这两个任务的训练过程。我们的直觉是,特定于qa的信号可以增强QG模型,不仅生成字面上类似的问题字符串,而且生成可以由答案回答的问题。反过来,QG可以通过提供额外的信号来改进QA,这些信号代表给出答案后产生问题的概率。训练的目标是共同学习QA模型参数θqa和QG模型参数θqg,通过减少他们的受到以下限制的损失函数。
- 约束
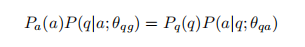
- 正则化项
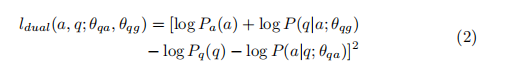
- 使用上述公式的问题
- KBQA任务中的答案a是一个事实,而不是一个句子。直接利用语言模型计算Pa(a)是不可能的。为了解决这个问题,我们提出了三种方法。
- 谓词频率:来表示Pa(a)
- 翻译模板
- [14]使用语言模型来计算问题q和答案a的相对可能性,因为它们都是自然语言。因此,获得Pa(a)的另一种解决方案是将三元组a翻译成自然语言句子sa,然后利用预先训练好的语言模型计算sa的概率
- 翻译:使用模板
- 我们首先尝试一个基于模板的方法。
由于大多数知识库谓词用它们的单词表示来表示等价的意思,所以我们可以将谓词rel分解成单词序列,并根据预定义的模板利用它来构造句子sa。
- 我们首先尝试一个基于模板的方法。
- 用NAG模型翻译[9]
- 为了多样性
- 使用与训练好的Natrural Answer Generation model来从a->sa

- KBQA任务中的答案a是一个事实,而不是一个句子。直接利用语言模型计算Pa(a)是不可能的。为了解决这个问题,我们提出了三种方法。
2.2 微调fine tuning
- 使用整个训练集来训练QA,QG
- 对每个三元组ai,我们从wiki文档中收集了一组文本证据来帮助QG模型的训练和推理
- 收集文本证据Collecting Textual Evidence:
- 在关系提取[11]的远程监控设置之后,我们
- 首先从实体subj的Wikipedia文章中选择包含subject subj和object obj的句子。
- 然后通过保留出现在subj和obj之间依赖路径上的单词,将这些句子简化为关系意译。我们通过查询知识库来收集subj和obj的实体类型列表。如果一个实体有多个类型,我们选择在所选的句子s或谓词rel中出现的类型。
- 最后,我们用它们的类型替换subj和obj mention,以学习在语法级别上更一般的关系表示。
- 在文本证据的帮助下,QG模型能够为不可见的谓词生成问题
- 在关系提取[11]的远程监控设置之后,我们
- 我们可以将生成的问题和采样的三元组作为补充训练集,剩下的问题是如何从知识库中采样三元组。
- 直观地说,我们从知识库中抽取的三元组越多,QA模型的能力就越强。但是,知识库中的三元组总数太大,有必要研究如何对适当的三元组进行抽样
- 简单的策略是随机选择三元组。
- 我们首先获得包含最高k个频率的谓词的候选谓词集R。
- 然后我们从r中选择谓词m次。对于每个选择的谓词reli,我们查询知识库,随机找到对应的subject subji和obji对,然后我们得到一个三元组
- 最后,当它有m个三元组时,补集T被完全构建,其中m是一个超参数。
- 为了避免调优参数m,我们提出一个方法来样品一套无偏三相同的原始数据集的分布。
- 作为一个前提,我们假设测试集具有相同的分布与知识库,同时有一个小训练集的区别。为了补充训练集,我们通过随机选择创建一个谓词集R。当原始训练集中的每个谓词reli都在r中发生时,选择过程就终止了。之后,我们丢弃所有这些冗余谓词,将剩余的谓词作为补充谓词集。
- 不重复地包含所有
- 简单的策略是随机选择三元组。
- 直观地说,我们从知识库中抽取的三元组越多,QA模型的能力就越强。但是,知识库中的三元组总数太大,有必要研究如何对适当的三元组进行抽样
3.Model
3.1QA Model
我们将在本节中详细描述问答(QA)模型。一般来说,QA模型制定作为fqa
(q)函数估计的正确性给定问题问每个候选人回答。为了方便,我们减少了QA模型关系分类模型和使用谓词rel取代回答一个候选人。相比与其他子任务如KBQA实体连接,关系提取在影响中扮演更重要的角色最终结果[21]。在现有的KBQA方法中,实体链接的准确性相对较高,但是由于不可见的谓词或转述,关系提取的性能不够好
QA->关系分类模型,并且用候选关系rel替代答案a
- 基于递归神经网络的关系提取模型(RNN)
- 为了更好地支持不可见的关系,我们将关系名称分解为单词序列,并将关系提取表示为一个序列匹配和排序任务。
- 输入关系:r={r1,r2,…,rm}–关系名
- 转化为与训练好的word embedding
- 输入bilstm–》得到一个隐层表示
- max pooling:利用最大汇聚层提取最显著的局部特征,形成固定长度的全局特征向量,得到最终的关系表示hr
- 同样的nn得到hq,计算余弦相似度cos(hr,hq)
- 为了语法上更一般的表示,实体替换为
- 丢失了实体信息,会混淆模型
- 将类型表示与问题表示连接起来
- 可提高性能
- 使用排名训练方法对上述模型进行训练,使得对问题q,正确的关系r+得分高,错误的关系r-,得分低(在候选关系中),损失函数如下
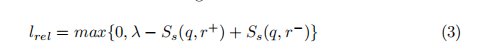
3.2QG model
- q={w1,w2,…,wn},a={s,p,o}
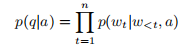
- 我们将QG问题作为一种翻译任务来处理,并采用了编解码器结构来解决它
- encoder:a->编码为embedding,使用transE–>hf=[hs;hp;ho]h_f=[h_s;h_p;h_o]hf=[hs;hp;ho]
- decoder:hf=[hs;hp;ho]h_f=[h_s;h_p;h_o]hf=[hs;hp;ho]->生成问题q
- QG模型应该能够生成具有不可见谓词的三元组的问题
- 在[6]之后,我们将介绍一个文本编码器。对于每个事实a,我们收集n个文本证据D = {d1, d2,…, dn}来自wiki文档。使用一组具有共享参数的n个门控递归神经网络(GRU)对每个文本证据进行编码。第j个文本证据中第i个词的隐藏状态计算为
- encoder:GRU
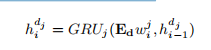
- EdE_dEd:预训练好的词嵌入矩阵
- wijw_i^jwij是dj的one-hot
- EdwijE_dw_i^jEdwij:是dj的向量表示
- 隐层状态表示:、
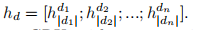
- decoder:带attention的GRU
- 给定一组编码的输入向量I = {h1, h2,…, hk}和
- 解码器先前的隐藏状态st−1,
- attention的
- 其中va、Wa、Ua为注意力模块的可训练权重矩阵。然后我们计算所有文本证据中所有标记的总体注意
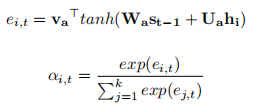
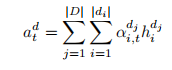
最近在NMT上的工作使用复制动作[10]来处理罕见/未知的单词问题。它将具有特定位置的单词从源文本复制到输出文本。我们利用这个机制来解决不可见谓词的问题。
我们采用了[6]的一个变体,它使用相同的POS标签复制单词,而不是使用特定的位置。这可以提高我们的QG模型的泛化能力。在每个时间步骤中,解码器选择从词汇表中输出一个单词,或从文本证据中输出一个表示复制操作的特殊令牌。这些特殊的标记在输出之前用它们原来的单词替换
















)

)
