文章目录
- Abstract
- 1.Introduction
- 2.相关工作
- 3 Adversarial Learning for Distant Supervision
- 3.1 Pre-Training Strategy
- 3.2 Generative Adversarial Training for Distant Supervision Relation Extraction
- 3.3 Cleaning Noisy Dataset with Generator
- 4.实验
- 4.2 Training Process of DSGAN
- 4.3 Quality of Generator
- 4.4 Performance on Distant Supervision Relation Extraction
- 5.结论
Qin, P., et al. (2018). DSGAN: Generative Adversarial Training for Distant Supervision Relation Extraction. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
Abstract
远程监督可以有效地标记关系提取的数据,但是受到噪声标记问题的困扰。最近的作品主要执行软袋级降噪策略,以找到句子包中相对较好的样本,与在句子级别做出假阳性样本的硬判决相比,这是次优的。在本文中,我们介绍了一个名为DSGAN的对抗性学习框架,用于学习一个句子级的真正生成器。受Generative Adversarial Networks的启发,我们将生成器生成的正样本视为负样本来训练鉴别器。获得最佳发生器,直到鉴别器的辨别能力下降最大。我们采用生成器来过滤远程监督训练数据集,并将误报实例重新分配到负集中,从而为关系分类提供清洁的数据集。实验结果表明,与现有技术系统相比,该策略显着提高了远程监督关系提取的性能。
- 关系抽取
- 已知文本中实体,对句子中存在的实体对的关系进行预测
- 远程监督
- 使用句子包
- (h,r,t)三元组的句子分在一个包中
- 远程监督存在噪音
- 以GAN来去除噪音,获得噪音低的包
- 生成器:找到句子中好的样本
- 判别器:将生成器产生的样本视作负样本来训练

1.Introduction
由于现实世界中存在大量事实,因此非常昂贵,并且人类注释器几乎不可能对训练数据集进行注释以满足各行各业的需求。这个问题越来越受到关注。 Fewshot学习和零镜头学习(Xian et al。,2017)尝试用很少的标记数据预测看不见的类,甚至没有标记数据。不同的是,远程监督(Mintz et al。,2009; Hoffmann et al。,2011; Surdeanu et al。,2012)是为了与远程监督(DS)之间看不见的关系,从纯文本中有效地生成关系数据。然而,它自然会带来一些缺陷:由此产生的远程监督训练样本通常非常嘈杂(如图1所示),这是阻碍性能的主要问题(Roth等,2013)。大多数当前最先进的方法(Zeng et al。,2015; Lin et al。,2016)在实体对的句子包中进行去噪操作,并将此过程整合到远程监管关系中。 。实际上,这些方法可以过滤大量的噪声样本;然而,他们忽略了一个实体对的所有句子都是假阳性的情况,这也是远程监管数据集中的常见现象。在这种考虑下,一个独立而准确的句子级降噪策略是更好的选择。
在本文中,我们设计了一个对抗性学习过程(Goodfellow等,2014; Radford等,2015),以获得一个句子级生成器,它可以识别来自嘈杂的远程监督数据集的真实阳性样本,而无需任何监督信息。在图1中,假阳性样本的存在使得DS决策边界不是最理想的,因此阻碍了关系提取的性能。然而,就数量而言,真阳性样本仍占据大部分比例;这是我们方法的先决条件。给定具有DS数据集决策边界的鉴别器(图1中的棕色决策边界),生成器尝试从DS正数据集生成真正的正样本;然后,我们为生成的样本分配负标签,其余样本分配正标签以挑战鉴别器。在这种对抗性设置下,如果生成的样本集包含更多真实的阳性样本,并且剩余集合中剩余更多的假阳性样本,则鉴别器的分类能力将下降得更快。根据经验,我们证明了我们的方法在各种基于深度神经网络的模型中带来了一致的性能提升,在广泛使用的纽约时报数据集上实现了强大的性能(Riedel等,2010)。我们的贡献是三方面的:
- 标注困难
- few-shot:通过少量标注来预测不可见的类
- zero-shot:无标注来预测不可见的类
- 远程监督:
- 噪声大
- 去噪
- 以前:在实体对的句子包中去噪
- 忽略了实体对的所有句子均是假阳性FP的可能
- 假阳性:预测为真,实际为假
- 在远程监督中很常见
- 忽略了实体对的所有句子均是假阳性FP的可能
- 解决:独立而准确的句子级去噪
- 噪声大
2.相关工作
为了解决上述数据稀疏性问题,Mintz等人。 (2009)首先通过远程监督将未标记的文本语料库与Freebase对齐。然而,远程监督不可避免地受到错误的标签问题的困扰。早期的工作不是明确地去除噪声实例,而是打算抑制噪声。Riedel等。 (2010)在关系抽取中采用多实例单标签学习;霍夫曼等人。 (2011年)和Surdeanu等人。 (2012)模型远程监督关系提取作为多实例多标签问题。
最近,已经提出了一些基于深度学习的模型(Zeng等人,2014; Shen和Huang,2016)来解决关系提取问题。当然,有些作品试图通过深度学习技术来缓解错误的标注问题,并将它们的去噪过程集成到关系提取中。曾等人。 (2015)选择一个最合理的句子来表示实体对之间的关系,这不可避免地错过了一些有价值的信息。林等人。 (2016)计算一个实体对的所有句子的一系列软注意权重,不正确的句子可以减权;基于同样的想法,Ji等人。 (2017)将有用的实体信息带入注意力量的计算中。然而,与这些软注意权重分配策略相比,在关系提取之前识别来自远程监督数据集的真实阳性样本是更好的选择。Takamatsu等。 (2012)基于从许多NLP工具中提取的语言特征构建噪声滤波策略,包括NER和依赖树,这不可避免地会遇到错误传播问题;而我们只是利用字嵌入作为输入信息。在这项工作中,我们学习了一个真正的识别器(生成器),它独立于实体对的关系预测,因此它可以直接应用于任何现有的关系提取分类器之上。然后,我们将假阳性样本重新分配到负集中,以便充分利用远程标记的资源。
- 远程监督
- Mintz et al. (2009) 提出:对齐
- 噪音
- 早期:抑制噪音
- Riedel et al. (2010) :多实例单标签学习
- Hoffmann et al. (2011) and Surdeanu et al. (2012) :多实例多标签
- 深度学习:将深度学习去噪集成到关系抽取中
- Zeng et al. (2015) :句子包里挑一个
- 错过了有价值的信息
- Lin et al. (2016):soft attention
- 给包中的句子加权
- Ji et al. (2017):attention中包含了实体信息
- Zeng et al. (2015) :句子包里挑一个
- 在关系抽取之前,分辨出真假样本:
- Takamatsu et al. (2012) :噪声滤波器
- 使用NER和依赖树的语言特征
- 难以避免错误传递
- 本文:仅使用word embedding
- Takamatsu et al. (2012) :噪声滤波器
- 早期:抑制噪音
3 Adversarial Learning for Distant Supervision
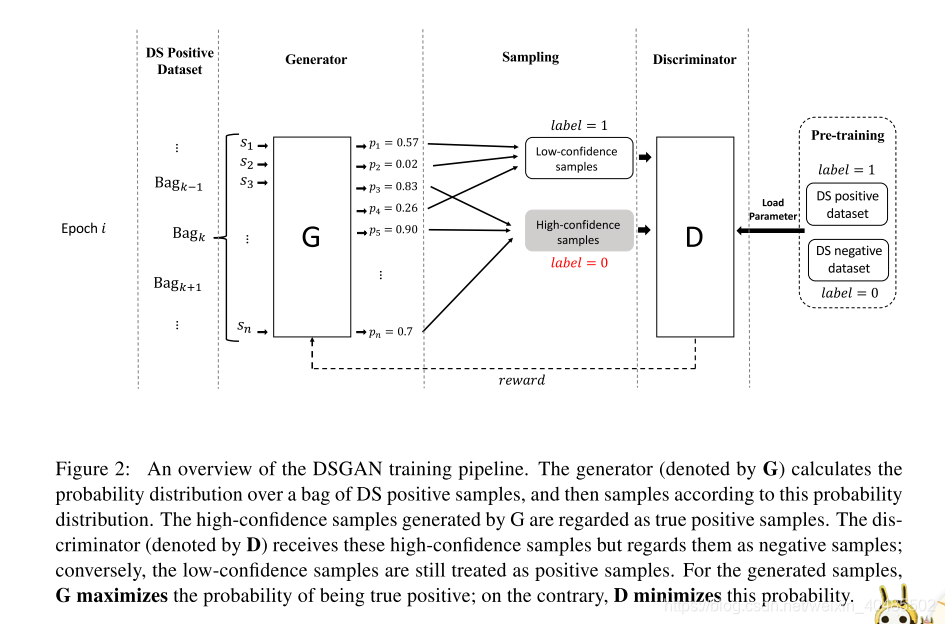
在本节中,我们将介绍一种对抗性学习流程,以获得一个强大的生成器,该生成器可以在没有任何监督信息的情况下从嘈杂的远程监督数据集中自动发现真正的正样本。我们的对抗性学习过程概述如图2所示。给定一组远程标记的句子,生成器试图从中生成真正的正样本;但是,这些生成的样本被视为负样本以训练鉴别器。因此,当完成扫描DS阳性数据集一次时,生成器发现的真实阳性样本越多,鉴别器获得的性能就越明显。在对抗训练之后,我们希望获得一个强大的发生器,它能够迫使鉴别器最大程度地丧失其分类能力。
在下一节中,我们描述了发生器和鉴别器之间的对抗性训练管道,包括训练前策略,目标函数和梯度计算。由于生成器涉及离散采样步骤,因此我们引入了一种策略梯度方法来计算发电机的梯度。
- DSGAN
- 目标:区分句子是不是好样本
- 只对标注为T的样本做区分,将FP重新归于负类
- 假设:标注为真的样本,多数为TP
- 生成器:区分句子是TP还是FP,无需监督
- 策略梯度:因为涉及离散采样
- 输入:word-embedding
- 判别器:
- 将生成器生成的样本标注为F
- 原来的样本,标注为T
- 训练判别器
- 如果生成集合中,TP多,而剩余集合中FP多,则鉴别器分类能力下降的很快
- 贡献
- 我们是第一个考虑对抗性学习去噪远程监督关系提取数据集的人。
- 我们的方法是句子级和模式诊断,因此它可以用作任何关系提取器(即插即用技术)。
- 我们证明我们的方法可以在没有任何监督信息下生成一个干净的数据集,从而提高最近提出的神经关系提取器的性能。
- 目标:区分句子是不是好样本
3.1 Pre-Training Strategy
- GANs:
- 预训练:生成器和判别器
- 必须
- 目标:得到更好的初始化参数,容易收敛
- 判别器:远程监督数据集的positive set P和negtive set NDN^DND
- 生成器:
- 预训练到精度达到90%
- 使用P和另一个negtive set NGN^GNG
- 让生成器对P过拟合
- 目标:让生成器在训练过程开始时错误地给出所有有噪声的DS的阳性样本高概率
- 之后会通过对抗学习降低FP的这个概率
- 目标:让生成器在训练过程开始时错误地给出所有有噪声的DS的阳性样本高概率
- 预训练:生成器和判别器
3.2 Generative Adversarial Training for Distant Supervision Relation Extraction
DSGAN的生成器和鉴别器都由简单的CNN建模,因为CNN在理解句子方面表现良好(Zeng et al。,2014),并且它具有比基于RNN的网络更少的参数。对于关系提取,输入信息由句子和实体对组成;因此,作为共同背景(Zeng et al。,2014; Nguyen and Grishman,2015),我们使用字嵌入和位置嵌入将输入实例转换为连续的实值向量。
- 网络
- CNN:
- 参数比RNN少
- 语言理解能力强
- 输入:句子+实体对
- 使用:word embedding + position embedding
- CNN:
- 生成器
- 与计算机视觉的区别
- 不用生成全新的句子(图),只需要从集合中判别出TP即可
- 是“从概率分布中抽样 ”的离散的GANs
- 与计算机视觉的区别
- 句子sjs_jsj是TP的概率
- 生成器:PG(sj)P_G(s_j)PG(sj)
- 判别器:PD(sj)P_D(s_j)PD(sj)
- 1个epoch扫描一次P
- 更有效的训练+更多反馈
- P–>划分成N个batch
- 处理完一个batch,更新一次参数θG,θD\theta_G,\theta_DθG,θD
- 目标函数
- 生成器
- 对一个batchBiB_iBi,生成器得到他的概率分布{PG(sj)}j=1,...,∣Bi∣\{P_G(s_j)\}_{j=1,...,|B_i|}{PG(sj)}j=1,...,∣Bi∣
- 依据这个概率分布采样,得到集合T
- T={sj},sjPG(sj),j=1,2,...,∣Bi∣T=\{s_j\},s_j~P_G(s_j),j=1,2,...,|B_i|T={sj},sj PG(sj),j=1,2,...,∣Bi∣–对G而言是正样本
- PG(sj)P_G(s_j)PG(sj)大的,是生成器视为正例的句子,但对判别器而言是负例
- 为了挑战判别器,损失函数(最大化):LG=Σsj∈TlogpD(sj)L_G=\Sigma_{s_j\in T}logp_D(s_j)LG=Σsj∈TlogpD(sj)
- LG=Σsj∈TlogpG(sj)L_G=\Sigma_{s_j\in T}logp_G(s_j)LG=Σsj∈TlogpG(sj)–感觉应该是G,原文是D
- 判别器:
- 样本:
- T:对D而言是负样本
- F=Bi−TF=B_i-TF=Bi−T:正样本
- 损失:
- 与二分类相同
- LD=−(Σsj∈(Bi−T)logpD(sj)+Σsj∈Tlog(1−pD(sj)))L_D=-(\Sigma_{s_j\in(B_i-T)}log p_D(s_j)+\Sigma_{s_j\in T}log(1-p_D(s_j)))LD=−(Σsj∈(Bi−T)logpD(sj)+Σsj∈Tlog(1−pD(sj)))(最小化)
- 可以用任何梯度的方法优化
- epoch:
- 与先前工作中的鉴别器的常见设置不同,
- 我们的鉴别器在每个epoch开始时加载相同的预训练参数集
- 原因1:想要的是强大的生成器而不是判别器
- 原因2:生成器只采样,不生成全新的数据
- 所以,判别器相对容易崩溃
- 假设:一个判别器在一个epoch内具有最大的性能下降时,就会产生最稳定的生成器
- 样本:
- 为保证前提条件相同,每个epoch的B相同(batch划分相同)
- 生成器

- 优化
- 生成器:
- 目标:从参数化概率分布中最大化样本的给定函数的期望。(类似一步强化学习)
- 训练:策略梯度策略
- 类比到强化学习中
- sjs_jsj:状态
- PG(sj)P_G(s_j)PG(sj):策略
- 奖励:(两个角度来定义)
- 从对抗训练角度,希望判别器判别生成器生成的为1(但对判别器来说,标注为0)
- r1=1∣T∣Σsj∈TpD(sj)−b1r_1=\frac{1}{|T|}\Sigma_{s_j\in T}p_D(s_j)-b_1r1=∣T∣1Σsj∈TpD(sj)−b1,b1:可以减小方差
- 来自NDN^DND的预测概率的平均值
- p~=1∣ND∣Σsj∈NDpD(sj)\tilde{p}=\frac{1}{|N^D|}\Sigma_{s_j\in N^D}p_D(s_j)p~=∣ND∣1Σsj∈NDpD(sj)
- NDN^DND:参与判别器的预训练过程,但不参与对抗训练过程
- 当判别器的分类能力降低,NDN^DND判别为0的准确率逐渐下降–>p~\tilde{p}p~增加了–>生成器更好
- r2=η(p~ik−b2),b2=maxp~im,m=1,...,k−1r_2=\eta(\tilde{p}_i^k-b_2),b_2=max{\tilde{p}_i^m},m=1,...,k-1r2=η(p~ik−b2),b2=maxp~im,m=1,...,k−1
- 从对抗训练角度,希望判别器判别生成器生成的为1(但对判别器来说,标注为0)
- 梯度:∇θDLG=Σsj∈BiEsj−pG(sj)r∇θGlogpG(sj)=1∣T∣Σsj∈Tr∇θGlogpG(sj)\nabla_{\theta_D}L_G\\=\Sigma_{s_j\in B_i}E_{s_j-p_G(s_j)}r\nabla_{\theta_G}log p_G(s_j)\\=\frac{1}{|T|}\Sigma_{s_j\in T}r\nabla_{\theta_G}log p_G(s_j)∇θDLG=Σsj∈BiEsj−pG(sj)r∇θGlogpG(sj)=∣T∣1Σsj∈Tr∇θGlogpG(sj)
- 类比到强化学习中
- 生成器:
3.3 Cleaning Noisy Dataset with Generator
- 上面训练得到的生成器–当做二分类器
- 过滤噪声样本
- 为了达到数据的最大利用率:
- 实体对的句子包中所有句子均被认定为FP,则该实体对将被分配到负集中
- 这样,远程监督训练集的规模不变
- (??负集啥意思,认为他俩没关系?)
在我们的对抗学习过程之后,我们获得一个关系类型的生成器;这些生成器具有为相应的关系类型生成真阳性样本的能力。因此,我们可以采用发生器来过滤来自远程监控数据集的噪声样本。简单而明确地,我们将发电机用作二元分类器。为了达到数据的最大利用率,我们制定了一个策略:对于具有一组带注释的句子的实体对,如果所有这些句子被我们的生成器确定为假阴性,则该实体对将被重新分配到负集中。在这一战略下,远程监督训练集的规模保持不变。
4.实验
本文提出了一种对抗性学习策略,用于从嘈杂的远程监督数据集中检测真实的阳性样本。由于缺乏有监督的信息,我们定义了一个发生器,通过与鉴别器竞争来启发式学习识别真正的阳性样本。因此,我们的实验旨在证明我们的DSGAN方法具有此功能。为此,我们首先简要介绍数据集和评估指标。从经验上讲,对抗性学习过程在某种程度上具有不稳定性;因此,我们接下来说明我们的对抗训练过程的趋同。最后,我们从两个角度证明了我们的发电机的效率:生成的样本的质量和广泛使用的远程监督关系提取任务的性能。
- 实验目标:
- 证明我们的DSGAN方法具有此功能(区分FP和TP)
- 证明我们的对抗训练收敛了
- 效率好
- 生成样本的质量
- 对远程监督关系提取任务性能的提升
- 数据集
- Reidel dataset(Riedel et al。,2010)
- Freebase的三元组+NYT的句子
- 测试:held-out evaluation
- 它构建了一个测试集,其中实体对也从Freebase中提取。
- 同样,从测试文章中发现的关系事实会自动与Freebase中的关联事实进行比较
- Reidel dataset(Riedel et al。,2010)
- word embedding:word embedding matrix by Lin et al. (2016)
- position embedding:最大距离-30和30
- CNN:简单的cnn
- 超参数

由于缺少相应的标记数据集,因此没有地面实况测试数据集来评估远程监督关系提取系统的性能。在这种情况下,以前的工作采用保持评估来评估他们的系统,这可以提供精确的近似测量,而不需要昂贵的人工评估。它构建了一个测试集,其中实体对也从Freebase中提取。同样,从测试文章中发现的关系事实会自动与Freebase中的关联事实进行比较。
4.2 Training Process of DSGAN

由于对抗性学习被广泛认为是一种有效但不稳定的技术,因此我们在这里说明了培训过程中的一些属性变化,以此表明我们提出的方法的学习趋势。我们使用3种关系类型作为例子:/ business / person / company,/ people / person / place living和/ location / neighborhood / neighborhood of。因为它们来自Reidel数据集的三个主要类别(商务,人员,位置),并且它们都具有足够的远程监督实例。图3中的第一行显示了训练期间鉴别器的分类能力变化。
- 本文对抗训练的收敛性
- 对抗训练过程中判别器在NDN^DND上精度下降(不用NDN^DND进行对抗训练了)
- 每个epoch从同一起点开始

精度由负set4NDN^DND 计算得出。在对抗性学习开始时,鉴别器在NDN^DND上表现良好;此外,在对抗训练期间不使用NDN^DND。因此,NDN^DND的准确度是反映鉴别器性能的标准。在早期时期,来自发生器的生成样本提高了准确性,因为它没有挑战鉴别器的能力;然而,随着训练时期的增加,这种准确性逐渐降低,这意味着鉴别器变得更弱。这是因为发电机逐渐学会在每个袋子中产生更准确的真阳性样品。在提议的对抗性学习过程之后,发生器足够强大以使鉴别器崩溃。图4给出了更准确的趋势显示趋势。请注意,每个呈现的关系类型都存在准确性下降的临界点。这是因为我们给发生器挑战鉴别器的机会只是一次扫描噪声数据集;当发电机已经足够稳健时,就会产生这个临界点。因此,当模型达到临界点时,我们会停止训练过程。总之,我们的发电机的能力可以稳步增加,这表明DSGAN是一种强大的对抗性学习策略。
4.3 Quality of Generator
- 图三可见:
- 训练得快,容易收敛,拟合度高–>则数据质量好
- 随机选择的正集<用预训练的生成器选择的<DSGAN选择的正集
- 与训练的生成器无法提供FP和TP之间的界限
由于缺乏监督信息,我们从另一个角度验证发电机的质量。结合图1,对于一种关系类型,真阳性样本必须具有明显更高的相关性(紫色圆圈簇)。因此,具有更多真阳性样本的阳性集更容易训练;换句话说,收敛速度更快,训练集的拟合度更高。基于此,我们在图3的第二行中给出了比较测试。我们从嘈杂的远程监督数据集P构建三个正数据集:随机选择的正集,正集基于预训练的发生器,正集基于DSGAN发生器。对于预训练的发生器,根据从高到低为正的概率选择正组。这三组具有相同的尺寸并伴有相同的负集。显然,DSGAN发生器的正设置产生了最佳性能,这表明我们的对抗性学习过程能够产生强大的真正正发生器。此外,预训练的发电机也具有良好的性能;然而,与DSGAN发生器相比,它不能提供误报和真阳性之间的界限。
4.4 Performance on Distant Supervision Relation Extraction
基于所提出的对抗性学习过程,我们获得了一个能够识别来自嘈杂的远程监督数据集的真实阳性样本的生成器。当然,远程监督关系提取的改进可以为我们的发电机提供直观的评估。我们采用3.3节中提到的策略来重新定位数据集。获得此重新分配的数据集后,我们将其应用于培训最新的最先进模型,并观察它是否为这些系统带来了进一步的改进。曾等人。 (2015年)和林等人。 (2016)是解决远程监管关系提取错误标注问题的有力模型。根据图5和图6中显示的比较,所有四个模型(CNN + ONE,CNN + ATT,PCNN + ONE和PCNN + ATT)实现了进一步的改进。
- 使用DSGAN可以提升远程监督关系抽取的效果比基本模型好



即使曾等人。 (2015年)和林等人。 (2016)旨在减轻假阳性样本的影响,它们都只关注实体对的句子包中的噪声过滤。曾等人。 (2015)将至少一个多实例学习与深度神经网络相结合,仅提取一个活动句子来表示目标实体对;林等人。 (2016)将软注意权重分配给一个实体对的所有句子的表示,然后使用这些表示的加权和来预测目标实体对之间的关系。然而,根据我们对Riedel数据集的人工检查(Riedel et al。,2010),我们发现另一个假阳性案例,即特定实体对的所有句子都是错误的;但是上述方法忽略了这种情况,而所提出的方法可以解决这个问题。我们的DSGAN流水线与实体对的关系预测无关,因此我们可以采用我们的生成器作为真正的指标,在关系提取之前过滤嘈杂的远程监管数据集,这解释了图5和图6中这些进一步改进的起源。 。为了给出更直观的比较,在表2中,我们给出了每条PR曲线的AUC值,它反映了这些曲线下的面积大小。较大的AUC值反映出更好的性能。而且,从t检验评估的结果可以看出,所有p值都小于5e-02,因此改进是显而易见的。
5.结论
远程监督已成为关系提取的标准方法。然而,虽然它带来了便利,但它也在远程标记的句子中引入了噪音。在这项工作中,我们提出了第一个生成对抗性训练方法,用于鲁棒的远程监督关系提取。更具体地说,我们的框架有两个组成部分:一个产生真阳性的生成器,一个试图对正负数据样本进行分类的鉴别器。通过对抗训练,我们的目标是逐渐降低鉴别器的性能,而发生器在达到平衡时提高预测真阳性的性能。我们的方法是模型不可知的,因此可以应用于任何远程监督模型。根据经验,我们证明了我们的方法可以显着提高广泛使用的纽约时间数据集上许多竞争基线的性能。



















,考虑长距离的实体标签之间的关)