编辑 | 萝卜皮

由于功率、处理和内存的限制,高级机器学习模型目前无法在智能传感器和无人机等边缘设备上运行。
麻省理工学院的研究人员介绍了一种基于跨网络的离域模拟处理的机器学习推理方法。在这种被称为 Netcast 的方法中,基于云的「智能收发器」将重量数据流式传输到边缘设备,从而实现超高效的光子推理。
该团队以 98.8%(93%)的分类准确度展示了图像识别在 40 焦耳/倍(<1 个光子/倍)的超低光能下。研究人员在波士顿地区的现场试验中重现了这一性能,该试验超过 86 公里已部署的光纤,波长多路复用超过 3 太赫兹的光带宽。Netcast 允许具有最少内存和处理能力的毫瓦级边缘设备以保留给高功率(>100 瓦)云计算机的 teraFLOPS 速率进行计算。
该研究以「Delocalized photonic deep learning on the internet’s edge」为题,于 2022 年 10 月 20 日发布在《Science》。

深度神经网络(DNN)的进步正在改变科学技术。然而,最强大的 DNN 日益增长的计算需求限制了在智能手机和传感器等低功耗设备上的部署,而同时向物联网(IoT)设备的发展加速了这一趋势。许多努力正在降低功耗,但由于矩阵代数中的能量消耗,一个基本的瓶颈仍然存在,即使对于包括神经形态、模拟存储器和光子网格在内的模拟方法也是如此。
在所有这些方法中,内存访问和乘法累加(MAC)函数仍然是每个 MAC 接近 1 pJ 的顽固瓶颈。边缘设备通常使用芯片级传感器,占用毫米级尺寸,并消耗毫瓦级功率。它们的小尺寸和低功耗预算意味着性能受到设备上集成的计算系统的尺寸、重量和功率(SWaP)的限制
为了使高级 DNN 在低功耗设备上完全可行,业界已将计算量大的 DNN 推理卸载到云服务器上。例如,智能家居设备可以将语音查询作为向量 U 发送到云服务器,云服务器将推理结果 V 返回给客户端(图 1)。这种卸载架构为语音命令增加了约 200 毫秒的延迟,这使得自动驾驶等服务变得不可能。此外,卸载在边缘和云中都带来了安全风险:客户端数据通信(向量 U)的黑客攻击导致了私有数据的安全漏洞。
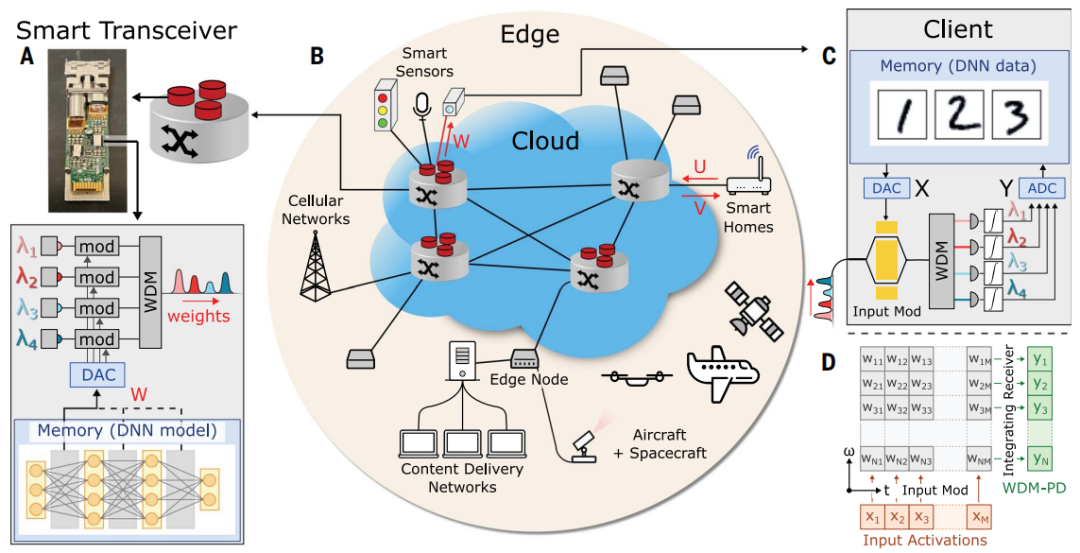
图 1:Netcast 概念。(来源:论文)
为了解决这些问题,麻省理工学院的研究团队引入了一种名为 Netcast 的光子边缘计算架构,以最大限度地减少大型线性代数运算(例如,通用矩阵向量乘法 [GEMV])的能量和延迟。
在 Netcast 架构中,云服务器以模拟格式将 DNN 权重数据(W)流式传输到边缘设备,以实现超高效的光学 GEMV,从而消除了所有本地权重内存访问。
包含「智能收发器」的服务器会定期将常用 DNN 的权重(W)广播到边缘设备,使用波分复用(WDM)来利用本地接入层可用的大频谱。
具体来说,一个 DNN 层的(M,N)大小的权重矩阵可以通过幅度调制场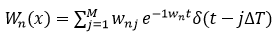 在时频基础上进行编码,其中,频率 Wn 和时间步长 j 处的光幅度 wnj 表示权重矩阵的第 n 行,δ 是脉冲响应函数。
在时频基础上进行编码,其中,频率 Wn 和时间步长 j 处的光幅度 wnj 表示权重矩阵的第 n 行,δ 是脉冲响应函数。
现在假设图 1 中的相机需要对图像 X 进行推断。为此,它等待服务器传输「图像识别」 DNN 权重,它使用宽带光学调制器与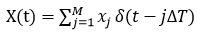 进行调制,随后将波长分离到 N 个时间积分检测器以产生矢量-矢量点积
进行调制,随后将波长分离到 N 个时间积分检测器以产生矢量-矢量点积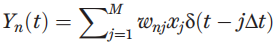 。这种架构最大限度地减少了客户端的有源组件,只需要一个光调制器、数模转换器 (DAC) 和模数转换器(ADC)。
。这种架构最大限度地减少了客户端的有源组件,只需要一个光调制器、数模转换器 (DAC) 和模数转换器(ADC)。
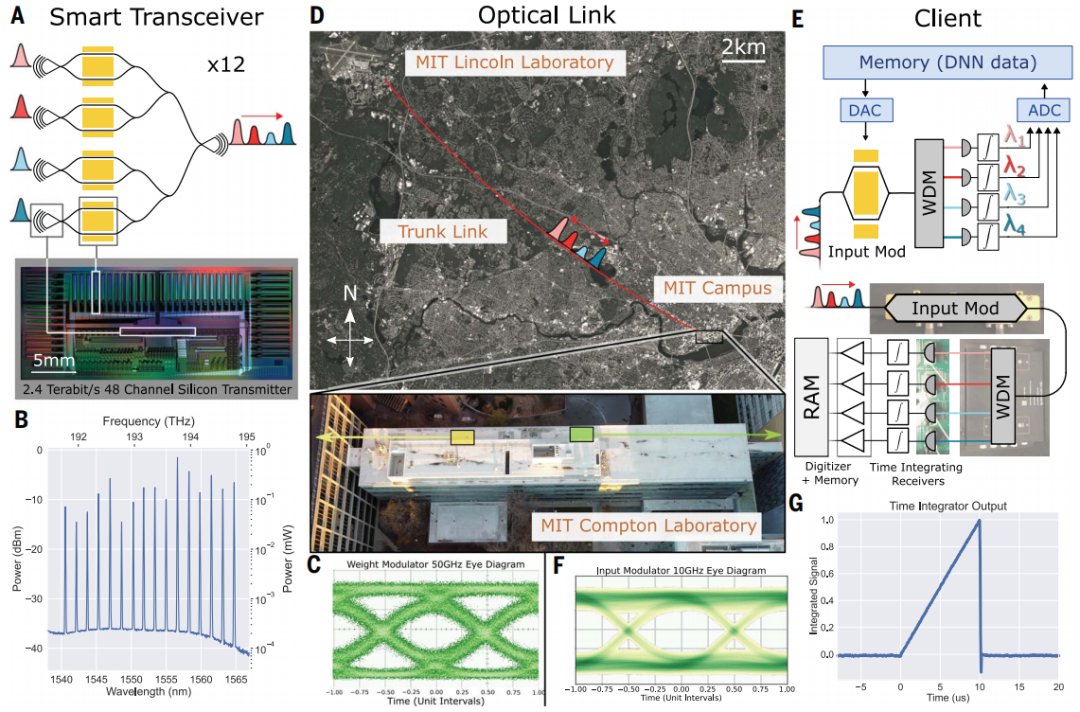
图 2:Netcast 系统的实验演示。(来源:论文)
此处显示的系统级演示是 Netcast 实现的一个示例。基于云的智能收发器可以驻留在现有的网络硬件中,例如网络交换机、服务器或边缘节点。研究人员的想法是,可以扩展到用户数据通过带有智能收发器的可编程网络交换机流式传输的情况,从而实现网络内光学推理。
现代网络交换机,例如英特尔的 Tofino 交换机,是商业开发 Netcast 的理想平台,由于它们是可编程的,因此能够以线速(100 Gbps)部署多个权重流,并且可以支持 64 GB 的内存,达到现代神经网络的存储要求。
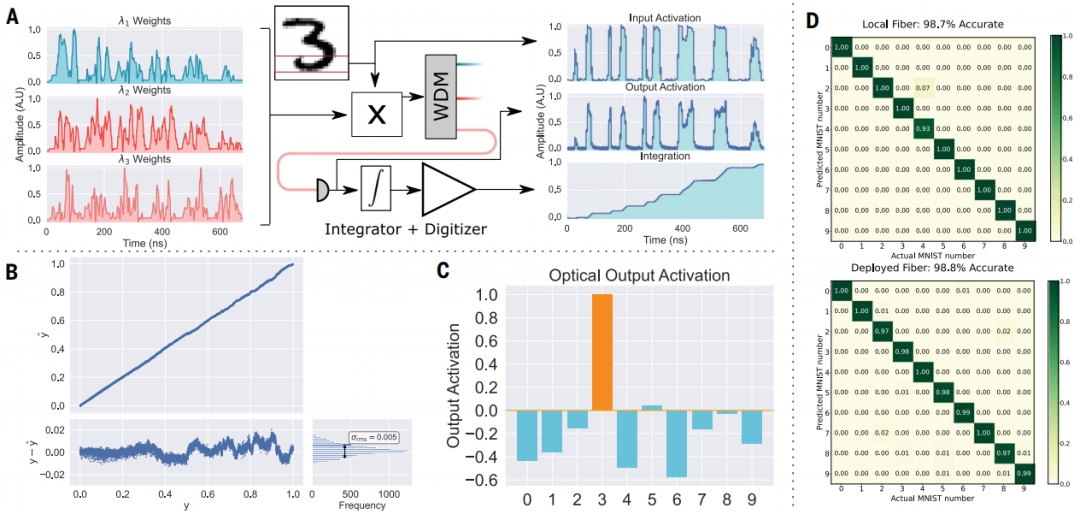
图 3:Netcast 系统的计算精度。(来源:论文)
先前的工作已经证明了使用可编程开关通过智能收发器执行逐层推理的可行性。这些网络交换机的大数据存储使得可以存储和查询多个模型。客户端设备可以使用其宽带调制器允许反射模式通信返回到服务器,客户端调制接收到的光并沿光纤链路将其发送回进行通信。这种查询通信可能很慢且有损,因为请求发送新模型只需要几个位。
新兴的光子技术,例如低功率静态移相器和高速移相器,可以将接收器电能消耗降低到每 MAC 约 10 aJ。通过使用无接收器检测器、光子 DAC 和光子 ADC 等技术,晶体管和光子在硅中的紧密集成可以进一步降低这种能量。诸如雪崩探测器之类的探测器可以与时间积分器结合,以提高接收器的光学灵敏度,但代价是增加了电能消耗。通过使用相干检测可以进一步提高光学灵敏度,该检测使用强大的本地振荡器增强接收到的信号。
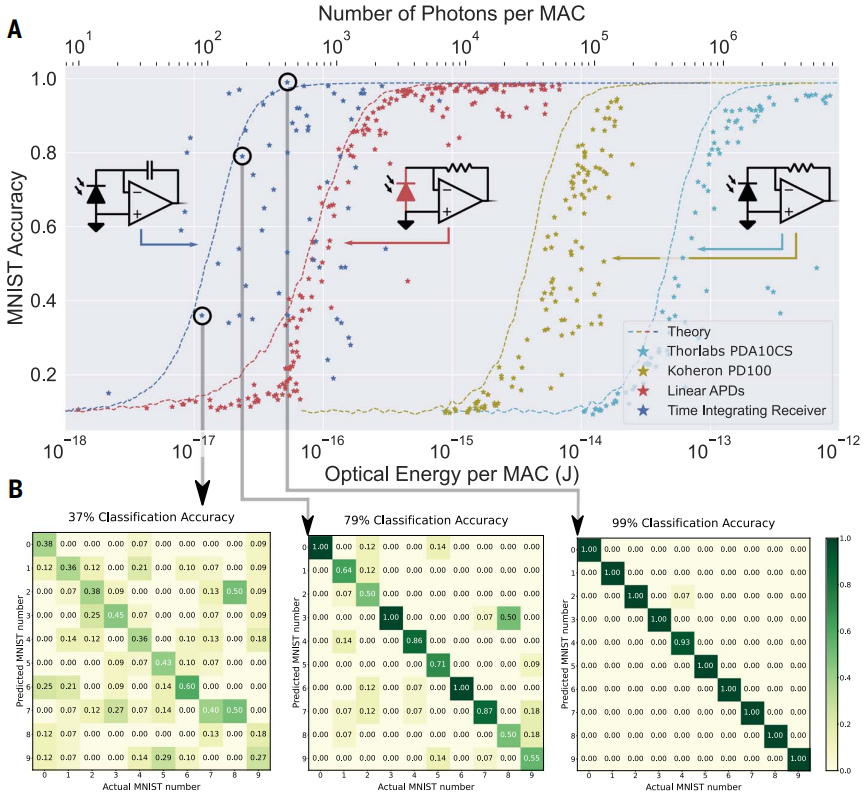
图 4:热噪声限制了 Netcast 系统的光学灵敏度。(来源:论文)
许多公司设计了具有减少 SWaP 的定制边缘计算专用集成电路(ASIC),但这些 ASIC 受到与较大 CMOS 处理器相同的能量和带宽限制的阻碍。与电子同类产品相比,忆阻交叉阵列和光子干涉仪网格等模拟加速器有望降低神经网络的功耗,但现有的商业演示仍然消耗瓦特的功率。
在传统光通信系统中缩放带宽的一个障碍是光纤中的色散。对于单个智能收发器和客户端,波长相关延迟等技术可以补偿智能收发器的色散。但是,在将权重从一个具有不同光纤长度的智能收发器部署到多个客户端的系统中,不能使用这种技术。研究人员在论文中讨论了色散的影响,并表明可以利用光学 O 波段在超过 10 公里的光纤上以每波长 10 GHz 的时钟速率实现太赫兹带宽。
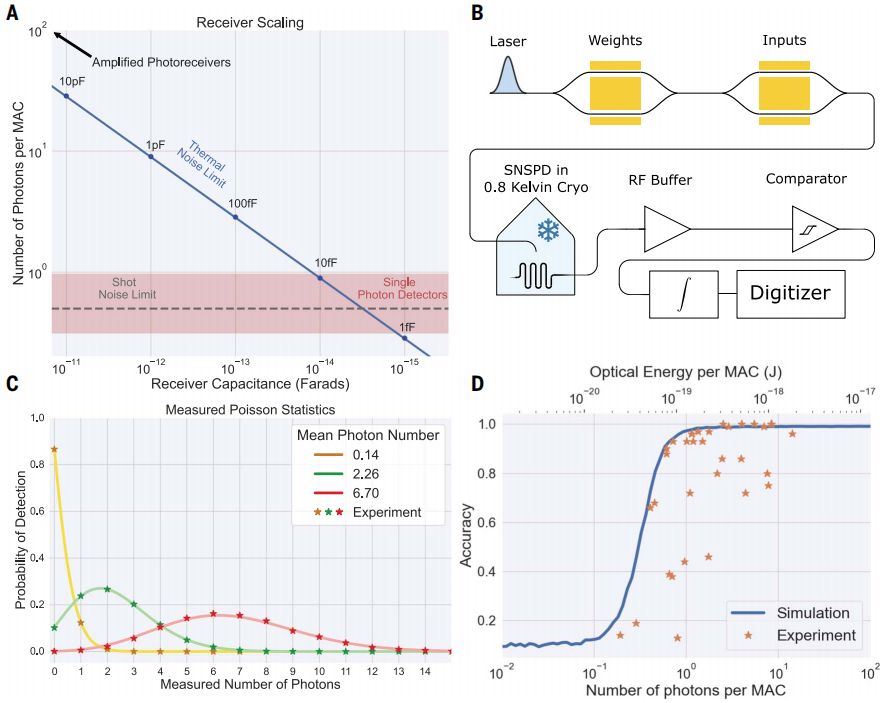
图 5:Netcast 的前瞻性表现。(来源:论文)
这种边缘计算架构利用光子学和电子学的优势,在能效和光学灵敏度方面比现有数字电子学提高了几个数量级。研究人员展示了使用 WDM 的可扩展光子边缘计算、时间积分接收器、可扩展至毫瓦级功耗、<1 photon-per-MAC 接收器灵敏度,以及使用 3 THz 带宽在已部署光纤上进行计算。在图像分类任务中,他们展示了 98.8% 的准确图像分类。
论文中展示的硬件很容易在现有的 CMOS 代工厂大规模生产,从而可以对日常生活产生短期影响。同时,该方法消除了边缘计算的基本瓶颈,在部署的传感器和无人机上实现高速计算。
论文链接:https://www.science.org/doi/10.1126/science.abq8271
相关报道:https://techxplore.com/news/2022-10-deep-components-machine-encoded.html
人工智能 × [ 生物 神经科学 数学 物理 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。



















