本文转载自公众号:挖地兔,本文的作者刘志明先生也是 Tushare 的作者。
Tushare 是一个基于 Python 语言的免费、开源的财经数据接口包,可以为金融量化分析人员提供快速、整洁和多样的结构化数据,帮助量化投资人员节省数据采集和清洗时间,使他们有更多的精力集中在策略的研发上,极大提高投研效率。作为国内最早一个服务于量化投资的 Python 开源项目,目前用户超过 10 万,机构 300 家,已经成为量化投资领域比较常用或者借鉴的数据工具。

前言
早在2010年的时候,我作为Oracle中国公司的实施方的项目负责人,给江苏省国税局做了一个项目——江苏国税智能问答系统。这个系统借助 Oracle OPA 产品,实现了税务方面的智能问答。通过税务局预设的相关问题,用户根据企业自身实际情况选择或输入数据,实现互动式精准问答。比如说,用户想知道自己公司是否可以享受福利企业税收优惠政策,企业根据自身的情况,输入相关数据,系统依据用户反馈的数据经过条件判断和计算给出不同的路径,最终引导用户得到需要的答案。
虽然这个系统当时只是通过预先设定的流程反馈结果,但当时我理解这是一个税务知识以及税务政策法规的总结和知识的交互呈现,通过XML技术,把税务知识结构化、语义化,让机器能快速对用户的问题作出反馈。在当时人工智能、NLP没有多少人提及的时候,我们姑且把这种模式当做是一种“智能系统”,放到今天来看,我个人把这种系统归纳为“知识图谱”的一种应用。
由此,引出了一个概念——“知识图谱”。到底什么是知识图谱?可能很多朋友都不太清楚,这也是写作本文的目的,给大家科普一下知识图谱的概念,希望能给需要了解或有兴趣了解的朋友带来一些帮助。
什么是知识图谱?
直接了当的说,知识图谱是人工智能技术的重要组成部分,它是具有语义处理与信息互联互通能力的知识库。通常在智能搜索、机器人聊天、智能问答以及智能推荐方面有着广泛的应用。
今天我们学习和探讨的知识图谱,实际是Google公司在2012年提出的为了提高搜索引擎能力,增强用户的搜索效率效果以及搜索体验的一种技术实践。
而在10年前,就已经提出了语义网的概念,呼吁业界推广并完善利用本体(Ontology)模型来形式化表达数据中的隐含语义,便于知识的高效呈现和利用。知识图谱技术的出现正是基于以上相关研究,是对语义网相关技术和标准的提升。
知识图谱中的一些概念要素:
实体:是指具有可区别性且独立存在的某种事物(有点像面向对象编程里的Object)。如某一种动物、某一个城市、某一种水果、某一类商品等等。世界万物有具体事物组成,此指实体。实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。
语义类(概念):概念主要指集合、类别、对象类型、事物的种类,例如人物、地理等。
属性:主要指对象可能具有的属性、特征、特性、特点以及参数,例如国籍、生日等。
属性值:主要指对象指定属性的值,例如国籍对应的“中国”、生日对应1988-09-08等。每个属性-属性值对可用来刻画实体的内在特性。
关系:用来连接两个实体,刻画它们之间的关联。形式化为一个函数,它把kk个点映射到一个布尔值。在知识图谱上,关系则是一个把kk个图节点(实体、语义类、属性值)映射到布尔值的函数。
知识图谱中一般用三元组的方式来表达,三元组的基本形式主要包括(实体1-关系-实体2)和(实体-属性-属性值)等。每个实体可用一个全局唯一确定的ID来标识,每个属性-属性值对可用来刻画实体的内在特性。
下图是一个以上概念和关系形象展示,帮助理解知识图谱的内容。
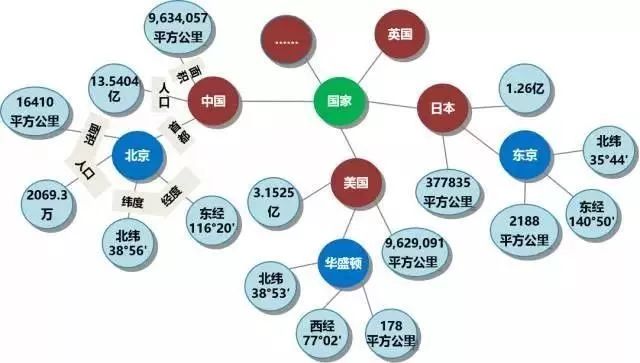
知识图谱在金融数据中的体现
从智能金融或者智能投研的角度来看,米哥认为,最常见是从上市公司、高管、产业、行业的角度将知识关联化和结构化,让每一类数据不再仅仅是数据(数字),而是具有可联系、可追溯、可扩展的图谱,将背后隐藏的逻辑关系快速呈现出来。
企业知识图谱
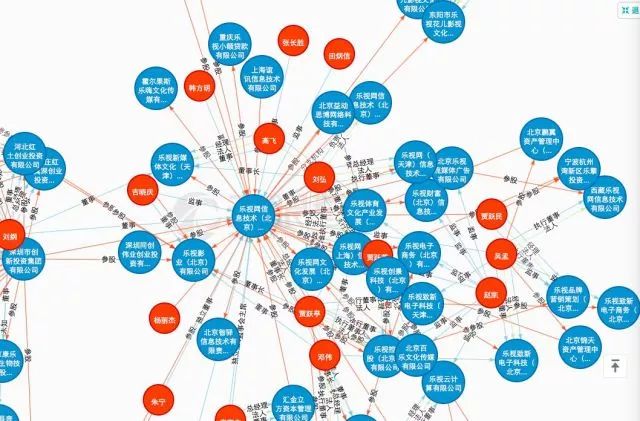
我们看一家公司的时候,尤其是针对一家上市公司,总会希望了解这家公司的股权关系,股东结构,希望通过了解该公司的控股股东及其背后的投资关系,了解该企业及法人对外投资的情况,获得该公司的风险要素。
也希望通过了解该公司的主营业务构成、产品生产和销售情况,了解该公司未来的发展潜力;同时,也会关注公司获得了那些专利技术、参与了哪些招投标项目,涉及了那些司法诉讼等等。这些基本要素就构成了一家公司或者一个集团的简单知识图谱,通过图形化的方法,利用酷炫的可视化效果呈现出来,达到快速了解和分析某一公司的目的。
我从网上搜索了一些可视化效果,给予大家直观的感受。
除了企业的图谱,其他类型的数据也可以被知识结构化和图谱化,同样也是从网上找了一个例子,有人将《星球大战》的人物和场景做了一个知识图谱,包含了“星战”7部电影里的87名角色、21颗星球、37艘飞船、39架战车、37个种族,并且通过各个节点链接,展现228个实体之间的1112种关系。
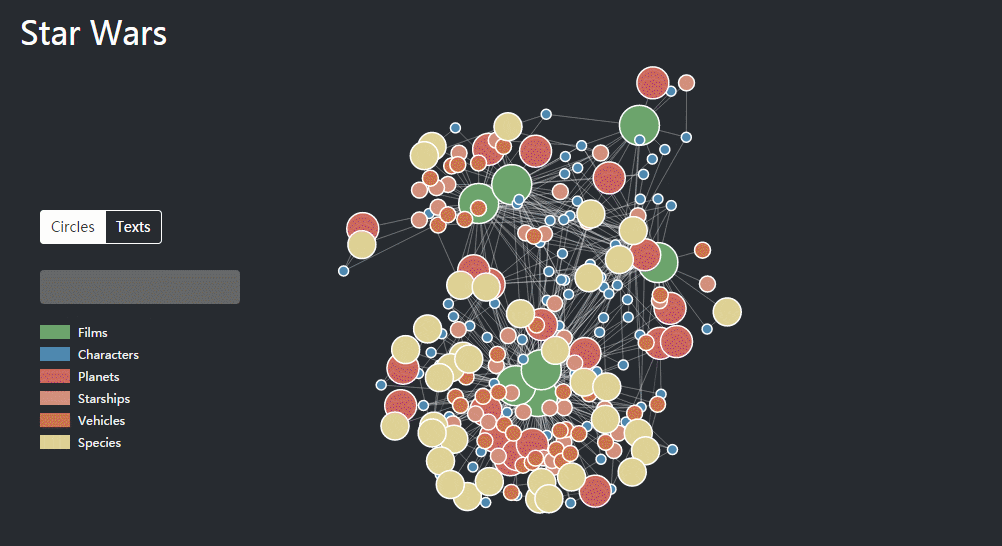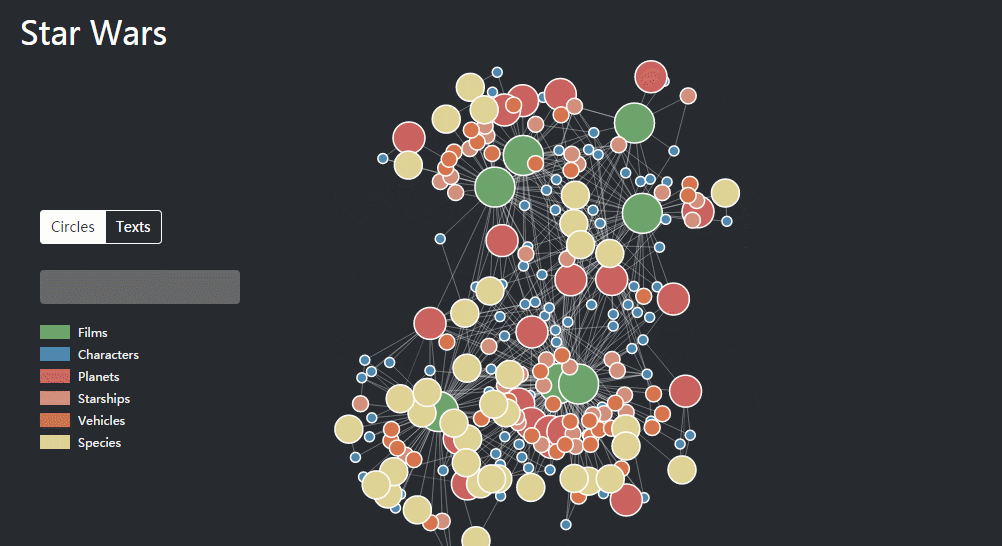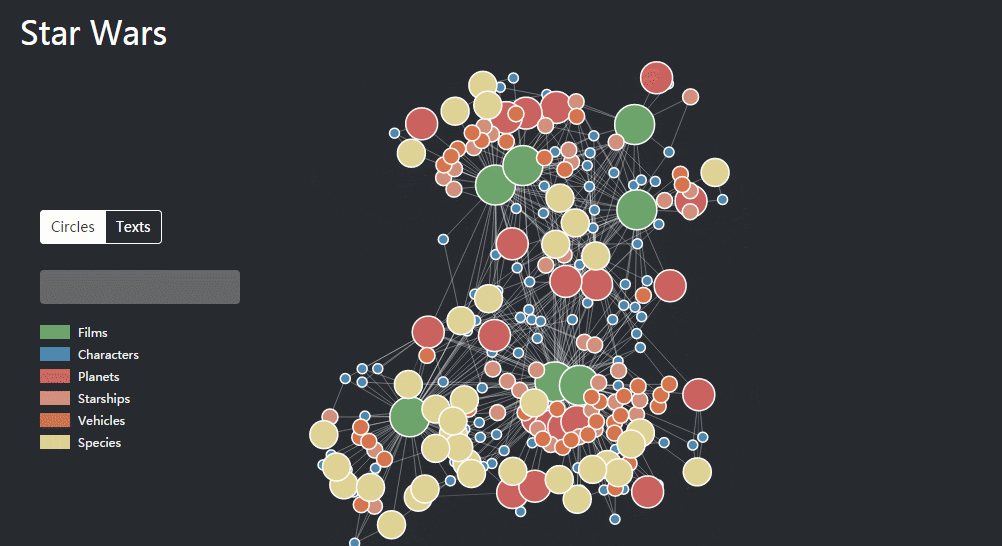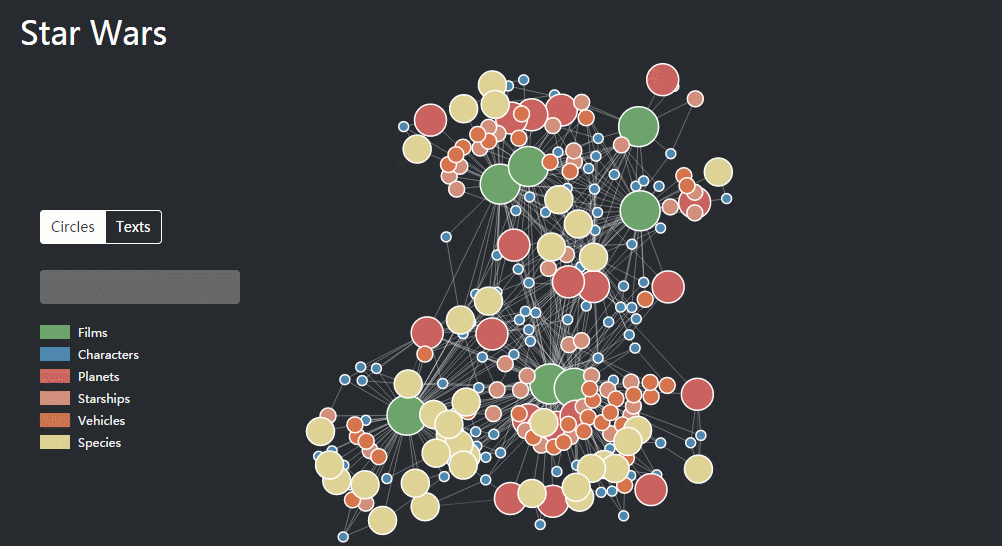
02
行业知识图谱
我个人认为,行业知识图谱最重要的体现可能在行业中的产业链图谱,当然也是最难实现的。有些行业上下游非常复杂,往往有较高的业务壁垒,而对行业和产业的理解、梳理清楚直接决定了是否可以驾驭这一领域。
在金融研究传统的行业分析方面,行业研究员掌握了大量信息,但基本都存在各自的大脑里作为其看家本领,一旦分析师离职,将直接影响这个行业分析的延续,甚至拖垮该公司在这个领域的研究体系。
如果建立在基于知识图谱的基础上,通过数据化、可视化的手段,相信一定可以实现将某一行业的产业知识、逻辑关系、上下游传导机制描绘出一个完整的、清晰的架构。即使有新人、新手来接续研究,也能很快上手。
下图是简单的例子,其实还算不上一个完整的知识图谱,只能算是产业知识总结,但一定程度上诠释了产业知识结构。
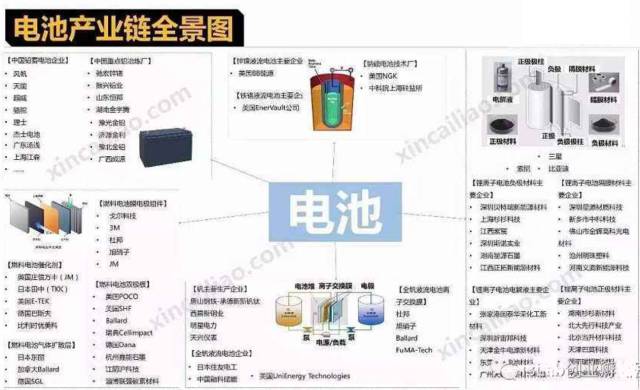
市场信息图谱
利用市场信息的整合分析来辅助投资决策是现今做金融投资比较常用的方法,利用多渠道来源的信息、多种碎片化的数据,互相补充,协同作用,得出一幅信息全景图,非常方便用于分析资本市场的动向。
这种信息处理的技术主要被用在情报分析领域,但资本市场也有比较多的需求。比如,对并购重组意向等影响公司未来的重大事件的早期预警,对上市公司业绩疑点的多方求证,对未披露的实际控制人身份的锁定等等。
这实际也是所谓大数据干的事情,但如果是利用知识图谱技术,绘制出一幅信息图谱,当出现某一个事件的时候,如何传导或导致什么样的结果,判断起来似乎就容易的多了。
知识图谱的难点
知识图谱的构建涉及知识表示、知识抽取、实体链接、实体融合、链接预测、推理补全、语义嵌入、知识存储等多方面的技术。这些技术看似纷繁复杂,但实际上瓶颈在于数据。
数据的严重缺失、数据质量差强人意等问题直接影响了图谱的效果。尤其是针对互联网数据、即各类非结构化的数据的处理上,尽管我们有NLP,尽管NLP抽取的准确率在提升,但我们很难指望 NLP 和机器学习能自动构建你真正所需要的知识图谱。
我们看到了构建一个高质量、高覆盖的知识图谱的难度以及高昂的成本,但一旦拥有,将自动建立起竞争壁垒,提到同行竞争门槛。米哥始终认为,不管是知识图谱也好,人工智能也好,未来取胜的关键仍然在于数据。
国内知识图谱组织
这里只介绍米哥熟悉的一个组织——OpenKG。
OpenKG是由国内资深的产业界和学术界的KG专家共同发起成立的一个NGO组织。这里面有我比较熟悉的文因互联CEO鲍捷博士、浙江大学的陈华钧教授,东南大学的漆桂林教授等等。
这个组织做了不少的尝试,从数据的收集整理到线下活动交流,推动了知识图谱理念和技术的落地。为学界、工业界提供了一个不错的资源共享和交流的平台。
虽然曾经受到过 OpenKG的 邀请,但自知半斤八两,寄希望于通过自己的努力,有朝一日可以加入OpenKG,利用Tushare数据平台,为KG领域贡献部分数据资源。
文献参考:
1、《知识图谱技术综述》徐增林等
2、白硕 : 知识图谱,就是场景的骨架和灵魂
更多精彩内容,请关注公众号:

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



)















