本文转载自公众号:恒生技术之眼。
21世纪以来,人类社会信息资源的开发范围持续扩大,经济、社会信息随着经济活动加剧得到空前的开发,信息资源总量呈爆炸式增长,我们从最初的“信息匮乏”一步踏入到“信息过量”时代。
个人如此,行业亦然:随着大数据应用的不断发展,金融机构的经营决策、营销服务越来越依赖于诸如新闻舆情、企业信用、热点概念等企业外部数据,而这些数据的应用场景也愈加需要与金融机构内部的数据打通,形成数据融合计算。再加上人工智能的异军突起,大量非结构化数据正在被人工智能结构化掉,隐藏在文档中的信息价值正在不断的被“机器”发现并加以大规模的使用,大数据、人工智能让金融机构的数据治理工作又重新回到了“混乱”的起点。面向人工智能的大数据治理,已经成为金融IT向金融DT转型所必须面对的一个严峻课题。
人工智能的应用现状
在笔者看来,人工智能就是一种数据服务能力,智能金融本质上就是金融DT服务,发展人工智能就等于发展数据技术,人工智能系统智能化程度的高与低,与数据处理能力正相关。为了方便说明这一论点,我们先来看看金融机构在人工智能领域所做的各种探索和尝试。
人脸识别作为最早的人工智能技术在金融机构各种需要身份验证的应用场景中得到广泛的应用,早在3年前远程开户、网上营业厅等业务就已经在金融机构中逐步展开,这是人工智能进入金融领域比较早的案例。现如今智能客服也已成了一个极佳的人工智能的切入点:首先通过智能语音技术将客户的语音转化为文字,然后用自然语言处理NLP技术进行解析,识别用户意图,最后用用智能问答形式给与相关的解答和服务。
智能客服在大幅降低人工客服的服务压力的同时,还能有效提升服务品质和服务效率,这对那些面临大量客服工作的大型金融机构来说还是非常有吸引力的。还有一部分金融机构以产业链知识图谱为其人工智能的着眼点,构建上市公司及其产品服务的上下游关系,再通过追踪监控新闻、事件、舆情在产业链中的传导效应,形成具体的投研策略。产业链技术延伸出去就会形成智能投研、智能资管、智能风控等智能金融业务,这类人工智能技术更加贴合金融机构的金融业务的用户场景。也有金融机构,索性把人工智能当作自己的贴身秘书来使用,各类新闻、公告、年报的解读全部交给了人工智能,通过自然语言处理技术,提取公告中的财务数字,做自动摘要,形成正负面相关性的分析。这类数据通过人工智能技术预处理后,大量信息被提炼出来,结合部分人工审核和校对,基本上也可以上生产了。
数据智能服务:从感知到认知
有人把人工智能的发展分为三个阶段:计算智能、感知智能、认知智能,对应的DT服务的发展就是数据从信息向知识演化并最终生长为数据智能的演变过程。当前大部分金融机构的人工智能还停留在感知智能向认知智能转化这个阶段,而主要工作场景还是在感知这一领域,所谓感知智能就是就是能听能说,具备一定的表达能力。很显然,人脸识别是图像视频这类非结构化数据的特征结构化的结果,这是让机器看懂人的图像;智能客服仰仗的是NLP的分词和意图识别能力,支撑问答系统的是强大的知识库和知识图谱技术,这是让机器理解人的语言;产业链知识图谱主要是传统三方资讯关系型数据转变为RDF三元组的一种数据存储形态的改变;各类新闻公告年报等的报告信息提取与加工,代表着非结构化数据结构化的一个过程,这是让机器替代人脑去读懂文档。
发展人工智能,光有感知能力显然是不够的,最终要能够具备认知推理的能力,从学术界看这个问题,有两条路可以走,一个是机器学习,一个是符号推理。机器学习大家都比较理解了,尤其是深度学习技术已经让语音识别、视频影响处理的能力超越了人类大脑的能力。符号推理,走的是另外一条路,最早指的就是专家系统,大量的知识被存储管理起来,用于检索,现如今,符号推理,是借助语义网络知识管理进行图分析挖掘的一种能力。符号推理在当前工业界落地的就是指知识图谱,基于RDF三元组存储的知识图谱,可以存储管理人类已有的各类知识,而这些知识又因为是一种实体关系属性的图表达,所以基于图的分析挖掘,表现出来的就是知识发现和推理的一种能力。
在我国金融行业,因为大数据本身的积累不够,做过标注的金融数据语料更加匮乏,所以造成一个结果,就是在金融行业,面向具体金融业务场景的机器学习的数据是不够的,更加谈不上深度学习了,结果就是基于机器学习的认知智能的发展必然受限。这里最直接的表现就是我们发现所有金融应用场景里,适合机器学习和深度学习的场景,是比较少的。很多机器学习不得不为NLP、知识图谱这种细节场景服务,或者机器学习和金融工程整合在一起,而主体还是金融工程,机器学习目前只是一种辅助工具,充其量就是多因子的一个加工手段而已。究其原因是金融行业业务相关的大数据的体系还没有完全构造出来。应用场景的数据还没有得到有效沉淀。
而符号推理在金融行业会有所不同,我们知道金融服务本质上就是一种信息服务,而金融对上市公司的公告、年报、新闻等等的资讯数据是天然敏感的,大多数玩金融的人,都是从处理这些信息开始的。很多行业研究员为了能够建立自己的竞争力,领先市场一步,每天加班加点的就是在阅读分析处理这类资讯数据。这类资讯数据基本上是一种非结构化形式存在的,三方资讯数据厂商通过人工采编的方式能够结构化掉其中一部分,而大多数数据还是需要人脑加工的。这就给了人工智能应用一个空间,通过自然语言理解NLU,再进行自然语言处理NLP,最后通过自然语言生成NLG,有了这几项技术,再结合知识图谱和机器学习的能力,将可以将这类非结构化数据的加工结果进行有效反馈。如果我们将NLP加工获取的金融词林,进一步挖掘获取的实体、关系、属性、概念、事件等信息,加以整理,建立他们之间的各类关系,那么一个基本的金融知识图谱就构造出来了。所以,我们会看到NLP技术在当前的人工智能领域的应用已经成为了热点,而KG是紧随其后的一项技术,大量的非结构化数据的提取达到一定的准确度后,机器就可以代替人,来完成大规模知识发现,最终形成知识计算所需要的“大知识“的数据储备,目前NLP的准确率还只能到60%上下,具体场景针对性优化后才可能到90%以上的水准。
在足够窄的应用领域,NLP技术通过了实战的考验。但面对海量大数据,基于文档互联的互联网体系想要转化为以实体关系为主体的语义网络,还有相当长的一段路要走。但我们还是有理由相信以广义NLP(新视频文字)技术为核心的人工智能将会统治相当长一段时间,直到非结构化数据的处理不再是问题以及非结构化数据和结构化数据能够相互融合,那么届时行业知识图谱、企业知识图谱的数据准备也已由点及面的建立起来,基于知识图谱的人工智能应用将大放异彩,金融领域的人工智能也就从感知智能正式过渡到认知智能阶段。
数据的价值演化
人工智能的发展本质上是数据价值的一个演化过程。计算智能对应的就是我们看到的多源异构大数据,我们将这些数据进行采集、清洗、转化加载到大数据中心后,数据变成各类有用的信息。如果我们将信息进一步提炼,通过知识构建与管理的一系列手段,便可以将信息转化为知识,存储起来。如果我们按照W3C的知识管理规范,对知识做RDF三元组的存储和管理,我们就能构造出来一系列的知识图谱。有了这个知识图谱,我们就具备了知识计算的能力,那么对于一个具体的金融场景来说,如果我们将金融业务场景的业务模型结合知识计算的能力,以及对大数据平台的数据进行机器学习的能力,就可以形成我们的金融大脑。
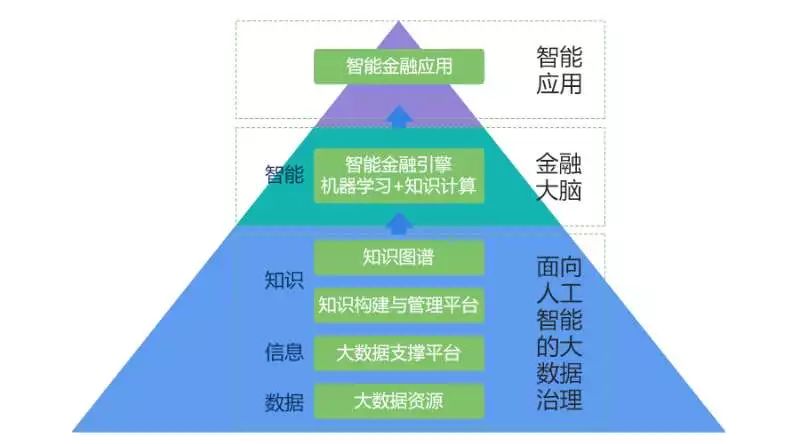
金融大脑=金融业务场景的业务模型
+知识计算+机器学习
我们将这类金融大脑,也就是大大小小的智能化场景,开放出去,就形成我们对传统金融的一个智能化变革。
面向人工智能的大数据治理
从以上的分析中,我们可以明确感觉到人工智能正在迅速改变金融机构,金融机构的数据计算的关注点,正在从企业信息系统内部的计算,转变为关注来自互联网和三方的外部数据的计算和处理上。
多元异构数据的整合,是未来金融机构将要长期面临的一个局面。数据难以融合,也就难以做到统一消费,从非结构化数据提取的实体关系、属性等信息,当他们不能融合到企业内部经营数据中去,就会再次形成信息孤岛,随着多元异构数据的量级不断攀升,这个信息孤岛将会呈现越来越严重的局面。在人工智能迅猛发展的今天,如何解决上述问题,是未来企业竞争中体现出来的核心竞争力之一。
以上所述的问题与挑战,就是我们今天所谈到的面型人工智能的大数据治理有待解决的问题。那么我们该如何行动呢?
第一步:多源异构数据源的统一管理。首先,我们要对多源异构数据源进行统一管理。这里既包括金融机构内部的经营数据,也包括来自三方资讯数据厂商的外部数据,以及来自互联网的各种大数据。
为了达到未来的智能化能力,我们需要将金融内部的结构严谨的业务系统数据图谱化,将具有明显关系特征的数据提取出来,再用这些数据对企业内部数据通过实体链接、数据标引等技术进行再组织;同时我们将三方数据中非结构化的那部分PDF、WORD等进行知识抽取,也提炼出实体关系属性等数据。最后对那些跟金融机构相关的互联网大数据,通过爬虫技术不断的抓取,并对这些网页半结构化数据进行结构化处理,同样提取其中的实体关系和事件信息。
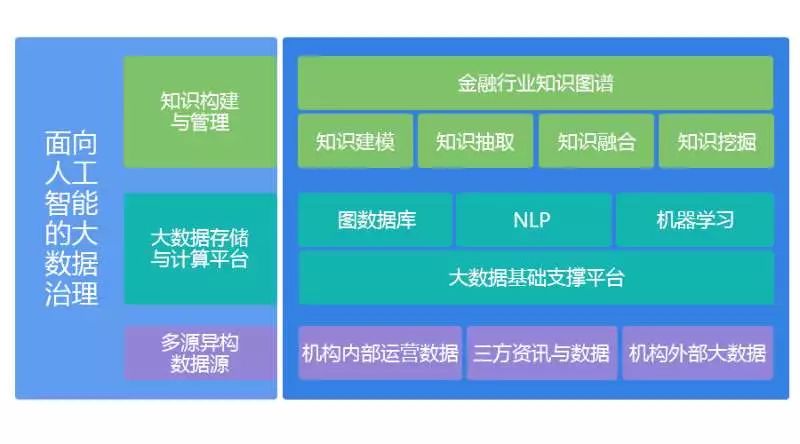 第二步:大数据存储与计算。对于金融机构而言,无论是采用商业化的软件还是开源软件,都需要一个大数据平台将来自多源异构数据源的数据进行统一管理,可以把这理解为一个大数据中心的建立,只不过这个数据中心的主要构建技术是人工智能的三驾马车:知识图谱、NLP、机器学习。我们在大数据中心除了保留原始异构数据源的一份拷贝之外,还要对这些数据进行面向人工智能的数据处理,包括通过NLP进行实体挖掘、关系抽取、属性提炼;通过知识图谱保存NLP提炼出来的具有关系特征的各种数据以及用机器学习来加速这一进程的处理效率提升准确度等。
第二步:大数据存储与计算。对于金融机构而言,无论是采用商业化的软件还是开源软件,都需要一个大数据平台将来自多源异构数据源的数据进行统一管理,可以把这理解为一个大数据中心的建立,只不过这个数据中心的主要构建技术是人工智能的三驾马车:知识图谱、NLP、机器学习。我们在大数据中心除了保留原始异构数据源的一份拷贝之外,还要对这些数据进行面向人工智能的数据处理,包括通过NLP进行实体挖掘、关系抽取、属性提炼;通过知识图谱保存NLP提炼出来的具有关系特征的各种数据以及用机器学习来加速这一进程的处理效率提升准确度等。
第三步:构造知识图谱。最后我们需要构造金融行业的一个知识图谱,可以是行业知识图谱,也可以是企业图谱。KG的建设是有一个完整的生命周期的,包括知识建模、知识获取、知识融合、知识计算以及知识应用的全过程。知识建模依赖与金融机构内部数据和来自三方的结构化数据,将ER关系转化为KG的Schema是这一个工作的重点。构造好Schema后,就可以进行知识获取工作了:首先导入关系型数据库的各类实体关系属性数据,然后通过知识抽取技术将各类非结构化数据结构化掉后,将散落在互联网大数据和三方非结构化数据中的知识进行整理合并到现有KG中去;接着通过实体消岐、指代消解等知识融合技术对KG的质量进行管理与维护;KG初步建立后,就可以通过图计算进行知识发现知识推理和挖掘等工作了。
至此,一个完整的面向人工智能的数据治理工作关于基础信息系统层面的建设就告一段落了。之后如果我们据此再逐步建立大数据大知识(KG)的管理规范,不断积累其中的业务应用模型,那么一个成熟可拓展的面向人工智能的大数据治理成果就会逐步呈现出来。届时,面向人工智能的大数据治理,势必能有效支撑智能金融从感知智能向认知智能的变革。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




)




与答案生成(QA)的结合)







)

:Encoder-Decoder模型和Attention模型)