AbstractKnowledgeGraph
AbstractKnowledgeGraph, a systematic knowledge graph that concentrate on abstract thing including abstract entity and action. 抽象知识图谱,目前规模50万,支持名词性实体、状态性描述、事件性动作进行抽象。目标于抽象知识,包括抽象实体,抽象动作,抽象事件。基于该知识图谱,可以进行不同层级的实体抽象和动作抽象,这与人类真实高度概括的认知是一致的。
项目介绍
抽象知识图谱,集中于对知识图谱和事件图谱中的实例事实进行抽象,包括实体抽象、动作抽象以及事件抽象,从而达到对人类真实认知的模拟。本项目目标有三个:
1)论述抽象图谱。对抽象图谱的现实需求进行论述。
2)介绍抽象图谱的相关工作。目前,关于抽象知识图谱的工作已经有一定的积累,如英文中的ConceptNet,MINDNET,verbnet;中文的CN-Probase,Hownet,大词林,百度百科Schema等。
3)提出抽象知识图谱的实施路线并给出抽象接口实践。一个可用的抽象知识图谱构建路线,是对以上两个内容的实践说明。
关于抽象知识图谱
1、抽象知识图谱的现实基础与需求
1)语言的语法特性。定语+主语+状语+谓语+补语+宾语是目前中文成句的重要形式,这种成分的占位与填充为了以词性标注、实体识别、句法分析已经语义角色标注的自然语言处理提供了基础。
2)语言抽象的层级特性。语义三角(包括符号,语义以及语境况三者构成的三角),对人类社会认知进行了很好的刻画。语言形成的过程,是人类对认知(物体,动作,思想)概括和总结的过程。形式化是概括的手段,语言符号及符号体系是概括的结果。层次性是符号体系的一个重要特征,概念之间的上下位,概念之间的总括与构成等,形成构成了语言抽象层级性的物质基础。
3)抽象能力是认知能力的基础。认知的过程,是对现实世界火活动的交互过程,包括内在和外在两个组成部分,内在负责自身知识的总结,抽象,体系的构建过程,即学习过程。外在负责对内在部分形成的知识体系应用的过程,应用包括验证和补充两个部分,验证在于对内在知识形成的证伪,补充在于对新抽象知识的形成与抽象规则的修正两个方面。孩子从出生的一无所知到逐步认知能力的过程,就是对知识不断总结、概括以及应用的过程。
4)抽象数据与抽象规则的获取挑战。让机器能够达到小孩的智力,根本上需要具备抽象能力以及抽象数据基础两个条件。这是解决认知智能的一个方向之一,而目前现有的技术手段,还难以快速满足这两个条件。一方面,健全的抽象数据较难获取,抽象与概括的类型众多,既有对动作的抽象,也有对名词实体的抽象,也有对性状的抽象,抽象的角度以及抽象的粒度很难把握。另一方面,基于这类抽象数据,学习或总结出内在的抽象规则和抽象层级,是难以攻克的一点。
2、抽象知识图谱的构成
1)抽象知识图谱体系架构
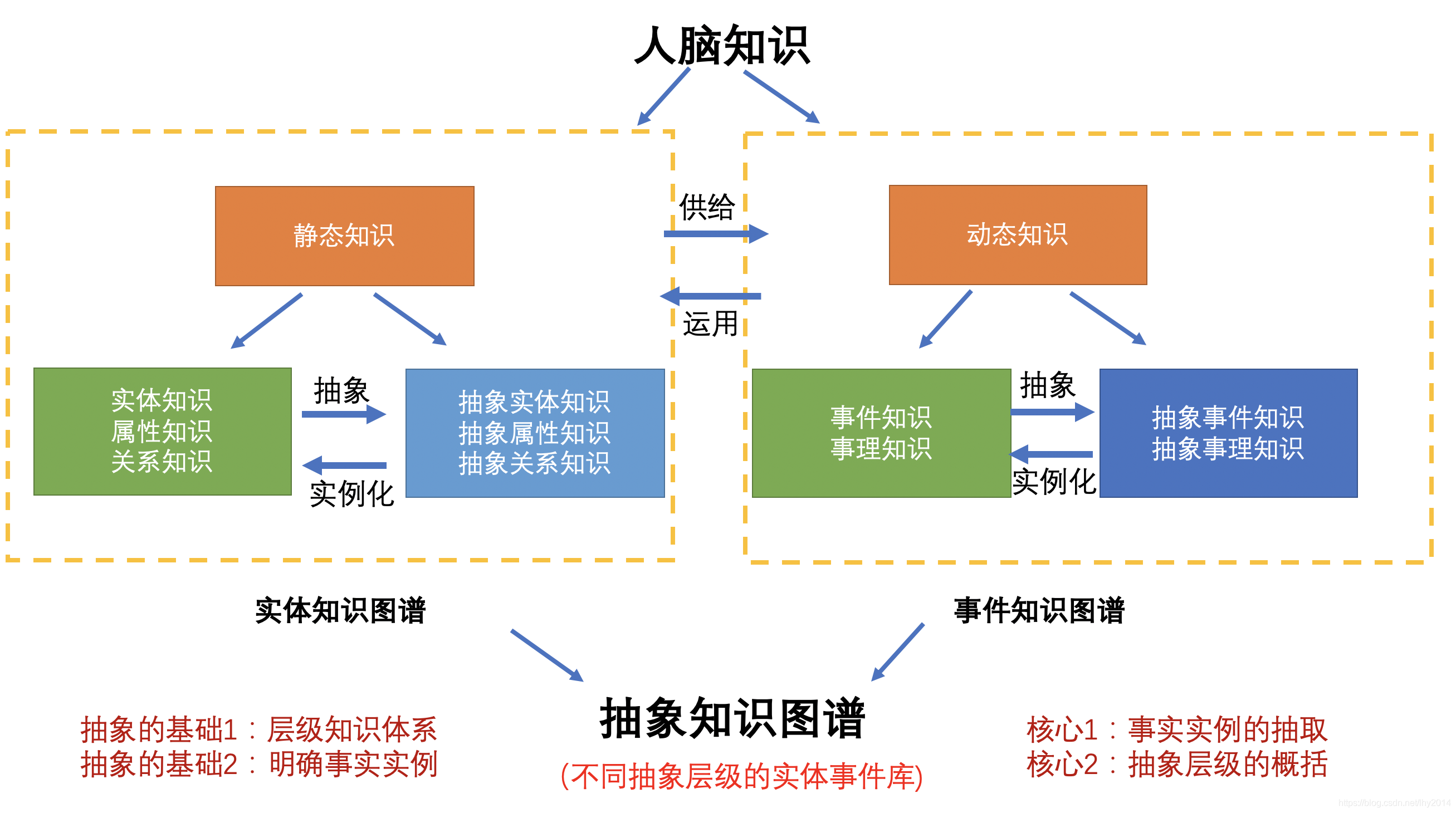
抽象知识图谱包括抽象实体知识图谱和抽象事件图谱两个组成部分,抽象实体知识图谱主要关注静态的实体性知识,抽象事件图谱则关注事件自身的抽象以及事件与事件之间(事理)的知识。抽象事件图谱需要抽象实体图谱作为有效载体,并加以支配;抽象实体图谱以抽象事件图谱作为有效承载,并为其所利用;抽象知识图谱是不同抽象层级的实体事件库,核心在于对事实实例的抽取以及抽象层级的概括两个方面,层级知识体系以及明确的事实实例是抽象的两个重要基础。基于事实实例的抽象是人脑对知识总结概括的过程。
2)抽象知识图谱的抽象角度
a) 名词性实体的抽象
名词性实体的抽象是知识抽象中最为基础也作为宽泛的一种,名词性实体丰富多样,并随着社会的发展以及新事物的产生而增加。苹果是一个公司,也是一种水果,水果又是一种植物,植物又是一种生物,这类层级性的名词性成分能够支持实体聚类、实体泛化等一系列应用。
b) 性状性修饰的抽象
性状性修饰的抽象,指对形容词性状态成分进行抽象,可用于对描述性知识的层级抽象。如美丽一词,属于美好这一层级,美好这一层级又可以归为友好积极的一类;又如悲伤这一词,通过悲伤自身的语义属性,又可以扩展成不同层级的修饰性成分。
c) 动作性事件的抽象
动作性的抽象,是除名词性实体抽象之外语义更为丰富但构建难度更大的一种抽象工作,动作是事件的重要组成部分,动作的层级反映了人类的事件归类和分类的印象。例如,睡觉是一种停止工作的动作,停止这一动作是从动态到静态的状态改变。杀人是犯罪,动刀子是杀人的一个可能步骤,这些动作之间构成的层级性语义网络能够配合名词性和性状性词语的抽象而生成更具有通用性的事件模式,即推动事件演化模式(event logic schema)的构建工作。
中文抽象图谱相关工作
目前中文抽象图谱的工作主要还集中于在实体层级的概念上下位知识库,典型的有CN-Probase, BigCilin,BaikeSchema等四个
-
CN-probase
CN-probase是由复旦大学基于百科知识库构建起来的一个大规模实体型概念知识库,该知识库对百度词条的义项进行挖掘,并基于此进行上下位的挖掘。该项目目前不公开数据集,只提供API的调用。地址:http://kw.fudan.edu.cn/apis/cnprobase -
HowNet
HowNet是董振东与董强两个老师研制出来的一款中文版的wordnet,该知识库构建起了具有层级体系的几百个概念,并基于此对超过6万个汉语词语进行了义项的刻画和组织。以HowNet为体系架构的基本组件,在配合词汇挖掘方法,可以形成一个较大规模的抽象知识库。Hownet与其他几个不同,该知识库还关注动词的抽象层级。该项目目前提供源文件的下载,已开源,关于这个的数据资源,可以参考我之前的一个工作,即句子相似度计算项目,地址:https://github.com/liuhuanyong/SentenceSimilarity -
BigCilin
大词林是由哈工大秦兵老师团队基于搜索引擎结果、百科类知识以及结合同义词词林进行概念上下位挖掘的所形成的一个抽象知识库。该知识库关注实体性的知识,在动词性的知识上还暂未涉及,对于大词林的技术细节以及使用样例,可以搜索大词林,查阅其相关文档。该项目目前仅提供demo展示,无法开源调用。地址:https://www.bigcilin.com
-
BaikeSchema
基于众包方式形成的百科知识库中包含着大量的社会常识知识,这种知识以Taxonomy的方式进行组织。百科类知识库,包括以百度百科、互动百科以及维基百科为首的三大百科,在知识抽象上包括两个方面,一个是百科分类体系树,另一个是百科词条页面中的标签以及义项体系,集成这两个百科的知识体系,可以得到准确率适当的层级效果。不过,在构建过程中,不同的百科中有不同的百科分类体系,往往需要进行对应以及融合。该项目数据分布在百科平台上,需要整理形成使用。关于这方面的工作,可以参考我之前做的一个工作:
1,百科schema收集项目,地址:https://github.com/liuhuanyong/BaikeKnowledgeSchema
2,基于百科知识的上下位概念项目,地址:https://github.com/liuhuanyong/HyponymyExtraction
抽象图谱构建技术路线
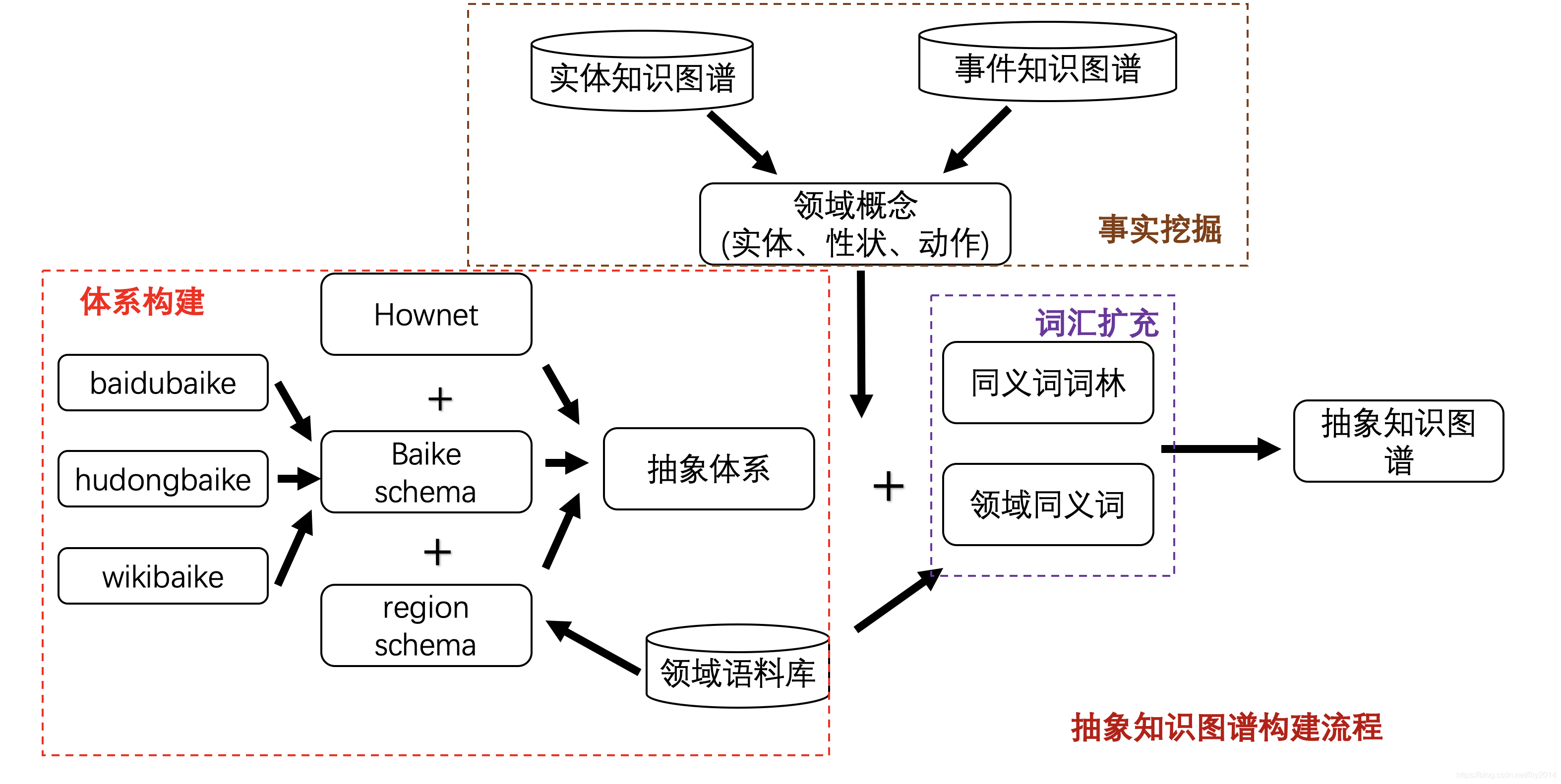
图谱的构建最忌讳从零开始,因此,可以踩在巨人的肩膀上进行处理。利用howet中的概念层级体系为基础,同时对百科类知识体系进行融合,并使用同义词词林等知识库进行拓展和泛化,并在知识更新上,基于百科概念事实以及模式挖掘提升抽象图谱的数量和质量。下图展示了该技术路线图。
目前接口效果
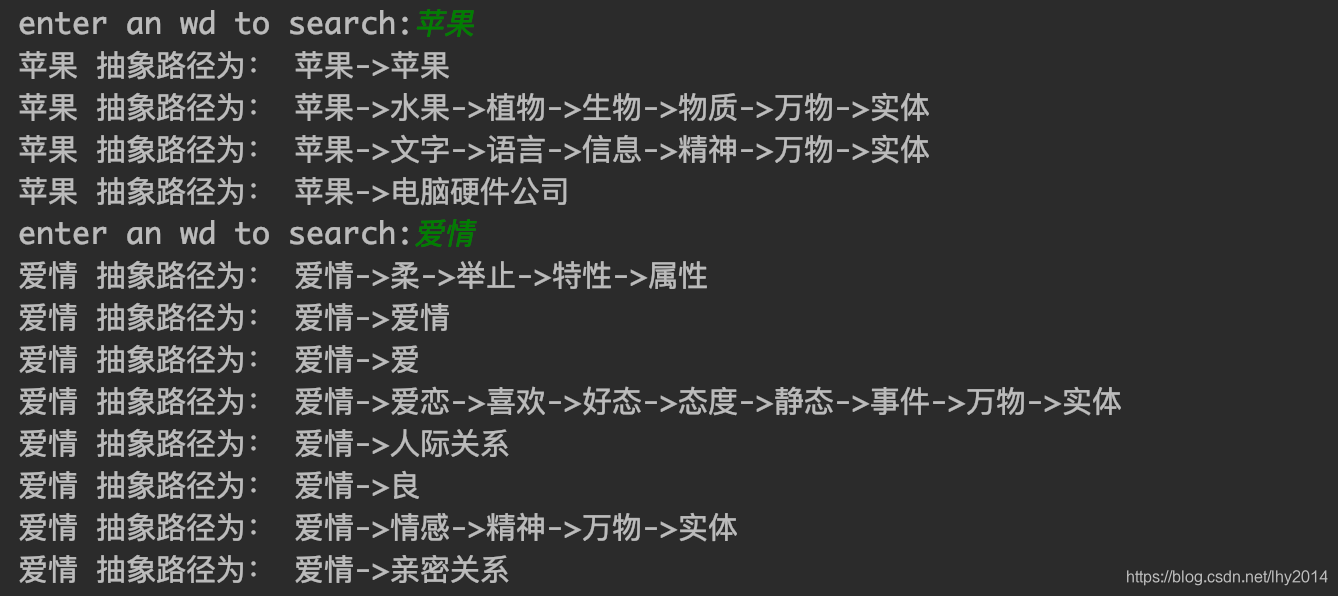
目前知识的抽象,本项目从词性的角度出发(词性与知识的类型比较强相关)进行处理,以下分别展示了名词性、状态性、动作性的抽象路径初步结果,文件说明如下:
1)dict/concept_total.txt,词汇与概念文件,存储词语的概念义项。
2)dict/hiearchy.txt,基础概念体系文件,存储基础概念体系。
3)search_concept.py,概念抽象文件,python3.6环境,直接运行即可。效果如下:
1,名词抽象路径
2,状态词抽象路径

3,动作抽象路径

总结
1,本项目提出了一个抽象知识图谱的项目,目的是对知识抽象与泛化提供一个思路并初步实践。
2,本项目介绍了抽象知识图谱,对抽象图谱的现实需求进行论述。
3,本项目介绍了中文抽象图谱的相关工作。摆阔CN-Probase,Hownet,大词林,百度百科Schema等,并给出了之前关联的项目地址。
4,本项目提出了一个可用的抽象知识图谱构建路线,提出抽象知识图谱的实施路线并给出抽象接口实践。基于hownet,同义词词林,从名词性实体抽象、形容词性性状描述抽象以及事件性动词抽象三个角度出发,形成了一个规模约50万的抽象接口。
5,知识图谱体系的再认识。知识图谱包括知识词汇表的挖掘,知识体系的挖掘,知识事实的挖掘三个部分内容,三个部分内容按照先后顺序排序。知识词汇表挖掘负责对知识中的短语名称、组合名称进行挖掘,形成符号基础。知识体系的挖掘,指知识概念层级的挖掘,更多的集中在抽象层级的挖掘;知识事实的挖掘,是目前的实体抽取与实体关系抽取,这也是目前知识图谱所处的阶段。
6,本项目提出了一个较为理想的目标,但技术实现起来仍然还需要一个体系更为健全、技术更为先进的方法来处理。后续这个项目可以长期维护。
If any question about the project or me ,see https://liuhuanyong.github.io/
如有自然语言处理、[知识图谱、事理图谱]、社会计算、语言资源建设等问题或合作,如果对事件知识库有兴趣的落地或者研究,可联系我:
1、我的github项目介绍:https://liuhuanyong.github.io
2、我的csdn博客:https://blog.csdn.net/lhy2014
3、about me:刘焕勇,中国科学院软件研究所,lhy_in_blcu@126.com
4、懂预言者得天下,得语言者分天下,得知识逻辑者,游得天下。
)





)

:G1收集器+连接池+分布式架构)

)








)