
链接:https://arxiv.org/pdf/1809.05124.pdf
本文主要关注Network embedding问题,以往的network embedding方法只将是网络中的边看作二分类的边(0,1),忽略了边的标签信息,本文提出的方法能够较好的保存网络结构和边的语义信息来进行network embedding的学习。实验结果证明本文的方法在多标签结点分类任务中有着突出表现。
Network embedding的工作就是学习得到低维度的向量来表示网络中的结点,低维度的向量包含了结点之间边的复杂信息。这些学习得到的向量可以用来结点分类,结点与结点之间的关系预测。
Model
本文将总体的损失函数分为两块:Structural Loss和Relational Loss,定义为:
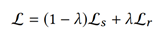
Structural loss:
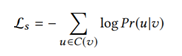
给定中心结点u,模型最大化观察到“上下文”结点v的情况下u的概率,C(v)表示点v的“上下文”结点,“上下文”结点不是直接连接的结点,而是用类似于deepwalk中的random walk方法得到。通过不断在网络中游走,得到多串序列,在序列中结点V的“上下文”结点为以点V为中心的窗口大小内的结点。本文采用skip-gram模型来定义Pr(u|v),Φ(v)是结点作为中心词的向量,Φ‘(v)是结点作为“上下文”的向量。Pr(u|v)的定义为一个softmax函数,同word2vec一样,采用负采样的方法来加快训练。
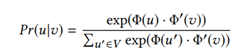
Relational loss:
以前也有方法利用了结点的标签,但是没有利用边的标签信息。本文将边的标签信息利用起来。边e的向量由两端的结点u,v定义得到,定义为:

其中g函数是将结点向量映射为边向量的函数:Rd*Rd->Rd’ ,本文发现简单的连接操作效果最好。
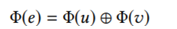
将边的向量信息置入一个前馈神经网络,第k层隐藏层定义为:
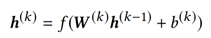
其中,W(k)为第k层的权重矩阵,b(k)为第k层的偏置矩阵,h(0)= Φ(e)。
并且将预测出的边的标签与真实的边的标签计算二元交叉损失函数。真实的边的标签向量为y,神经网络预测的边的标签向量为yˆ。边的损失函数定义为:

本文算法的伪代码如下:

结果分析
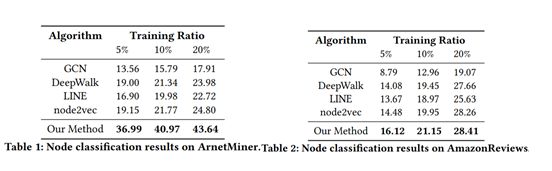
表1和表2展示了五种方法在两个数据集上结点分类的表现。本文使用了5%,10%,20%的含有标签的结点。本文考虑到了在现实中,有标签关系的稀有性,所以本文只使用了10%的标签数据。可以观察到即使是很小比例的标签关系,结果也优于基础方法。在ArnetMiner数据集上表现得比AmazonReviews好的原因是,类似于ArnetMiner数据集的协作网络,关系的标签通常指明了结点的特征了,所以对于结点分类来说,高于AmazonReviewers是正常现象。
总结
本文的方法相比于以往的network embedding方法的优势在于,除了利用了网络的结构信息,同时也利用了网络中的边的标签信息。在真实世界的网络中证实了本文的方法通过捕捉结点之间的不同的关系,在结点分类任务中,网络中的结点表示能获得更好的效果。
论文笔记整理:黄焱晖,东南大学硕士,研究方向为知识图谱,自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。
)






)

链表的实现集合的相关操作)









