
Mohnish Dubey, Debayan Banerjee, Debanjan Chaudhuri, Jens Lehmann: EARL: Joint Entity and Relation Linking for Question Answering over Knowledge Graphs. International Semantic Web Conference (1) 2018: 108-126
链接:https://link.springer.com/content/pdf/10.1007%2F978-3-030-00671-6_7.pdf
研究背景
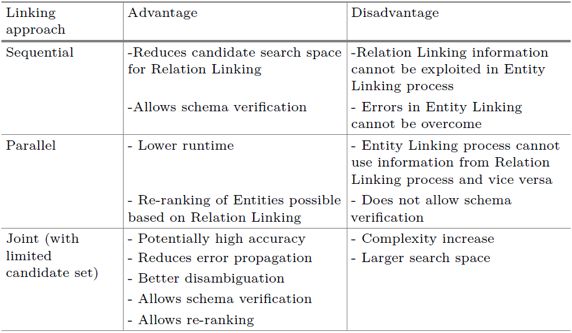
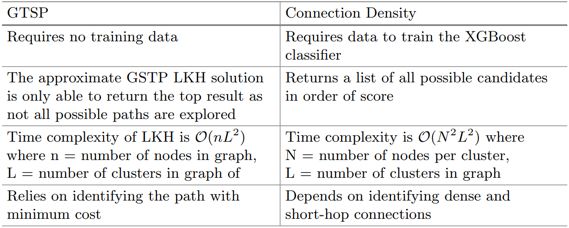
面向知识库的语义问答是指将用户的自然语言问句转换为可以在知识库上执行的形式化查询并获取答案,其面临的挑战主要有以下几点:1)实体的识别和链接;2)关系的识别和链接;3)查询意图识别;4)形式化查询生成。其中实体链接和关系链接是指将自然语言问句中的词汇(或短语)链接到知识库中对应的实体或关系。大多数现有问答系统依次或并行执行实体链接和关系链接步骤,而本工作将这两个步骤合并,提出了1)基于广义旅行商问题的 以及 2)基于连接密度相关特征进行机器学习的 两种联合链接方法。下表展示了不同种类的链接方法的优缺点。
框架及方法
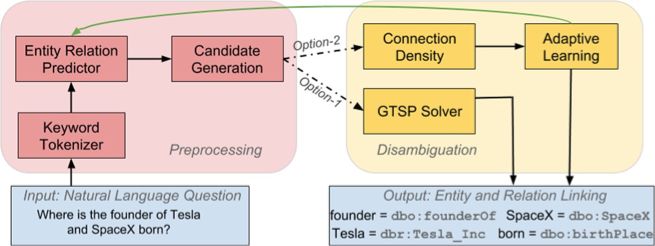
上图展示了本文提出的联合的实体关系链接框架(EARL,Entity and Relation Linking),主要包括如下两个步骤:
1) 预处理步骤(左侧红框内),包括如下三个子过程:
利用SENNA系统从输入的自然语言问句中抽取出若干关键词短语。对于图中输入的问句,这里抽取到的关键词短语是<founder,Tesla, SpaceX, born>。
对于每个关键词,使用基于字符嵌入(character embedding)的LSTM网络判断它是知识库中的关系还是实体。对于上个过程中的关键词短语,这一步将“founder”和“born”识别为关系, 将“Tesla”和“SpaceX”识别为实体。
为每个关键词短语生成候选实体或关系列表。对于问句中的实体名,利用预先收集的URI-label词典,以及Wikidata中的实体别名、sameas关系等进行生成。对于关系词,利用Oxford Dictionary API和fastText扩展知识库上的关系名后进行关联。
2) 联合消歧步骤(右侧黄框内),主要包括本文提出的两个核心方法:
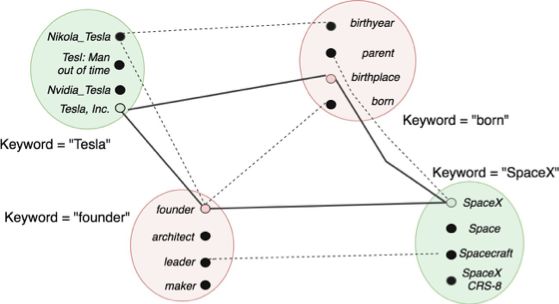
基于广义旅行商问题(GTSP)的消歧方法。如下图所示,该方法将每个关键词的候选URI放入同一个簇。边的权重被设置为两个URI在知识库上的距离(hop数),而联合消歧过程被建模为在该图上寻找一条遍历每个簇的边权总和最小的路(头尾结点可以不同)。对于GTSP问题的求解,本工作先将其转换为TSP问题,后使用Lin-Kernighan-Helsgaun近似算法进行求解。图中加粗的边表示该示例的求解结果。
b. 基于连接密度相关特征进行机器学习的消歧方法。对于每个关键词的所有候选URI,分别抽取特征 R_i (候选列表中的排序位置), C (2步以内可达的其他关键词的候选URI的数量),H (到其他关键词的候选URI的平均步数)三个特征,采用xgboost分类器筛选最合适的候选。
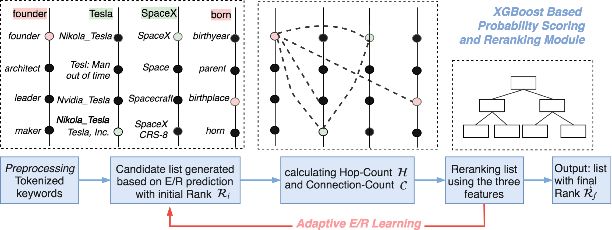
下表总结了上述两个消歧方法的差异:
c. 额外的,本文提出了一种自适应实体/属性预测方法。如果消歧后某个实体/关系和它最终链接到的URI的置信度低于阈值,则可能预处理步骤的第二个子过程(实体/关系预测)有错误。在这种情况下,该工作会更改该关键词的实体/关系标签,重新执行候选生成和消歧步骤,从而获得整体精度的提升。
实验
本文选用了LC-QuAD问答数据集进行实验,包含5000个问句。其标准答案(实体/关系对应的URI)采用人工标注的方法进行生成,可以在https:// figshare.com/projects/EARL/28218下载。除此以外本文还选用了现有的QALD-7问句集(https://project-hobbit.eu/challenges/qald2017/)进行测试。
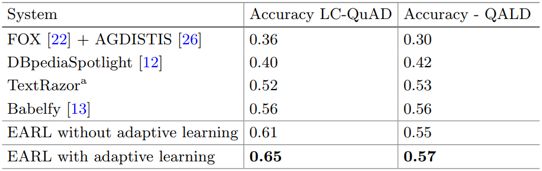
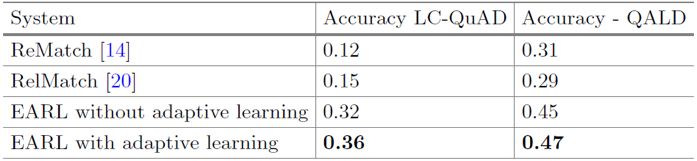
实验结果如下表所示,和对比方法相比,EARL在MRR值上有较大提升。
实体链接结果:
关系链接结果:
论文笔记整理:丁基伟,南京大学博士生,研究方向为知识图谱、知识库问答。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。







终身学习项目-EventKGNELL(学迹))






)




