Commonsense for Generative Multi-Hop Question Answering Tasks
链接: https://arxiv.org/abs/1809.06309
背景
机器阅读任务按照答案类型的不同,可以大致分为:
(1) 分类问题: 从所有候选实体选择一个
(2) answer span: 答案是输入文本的一个片段
(3) 生成式问题: 模型生成一句话回答问题
不同的数据集文档的差异也较大。如SQuAD,CNN/DM数据集来源于百科,新闻等文本,问题类型多为事实型,因而回答问题不需要综合全文多处进行综合推理,只需要包含答案的句子即可。而本文实验所用的数据集如NarrativeQA则来源于小说等,回答问题需要综合全文多处不相连片段进行推理,因此难度更大。
本文提出在NarrativeQA等需要多跳推理的文本进行生成式问题回答的模型。人工抽样数据集样本分析发现,许多样本答案的推理单凭文本包含的信息是无法完成推理并回答的,需要引入外部知识库中的常识信息。本文提出在常规的机器阅读模型中引入ConceptNet中的常识信息。
BaseLine模型
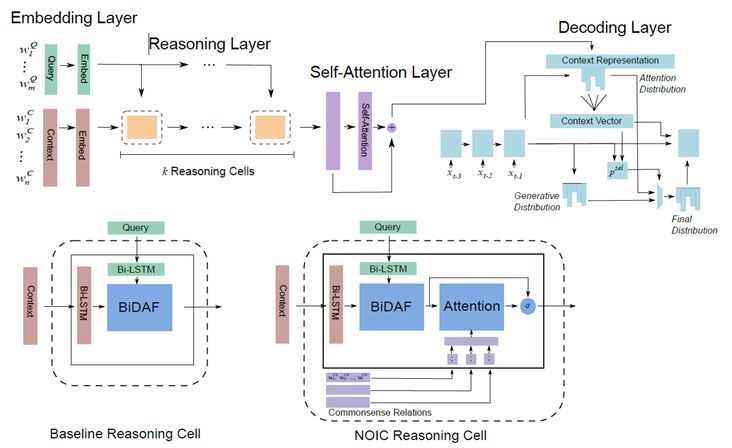
按照机器阅读模型的一般性结构,baseline模型可以分为4层:
(1) Embedding layer: 问题和文档里的每个词用预训练的词向量和ELMo向量表示
(2) Reasoning layer: 重复执行K次推理单元,推理单元的内部结构是BiDAF模型的attention层
(3) Model layer: 最后再对文档的表示做self-attention和Bi-LSTM
(4) Answer layer: pointer-generator decoder, 即RNN的每一步同时对词表和输入计算输出概率,每个词在当前位置被输出的概率为其在词表中被选中的概率和其在输入中被copy的概率之和。
改进模型:引入外部常识
常识挑选
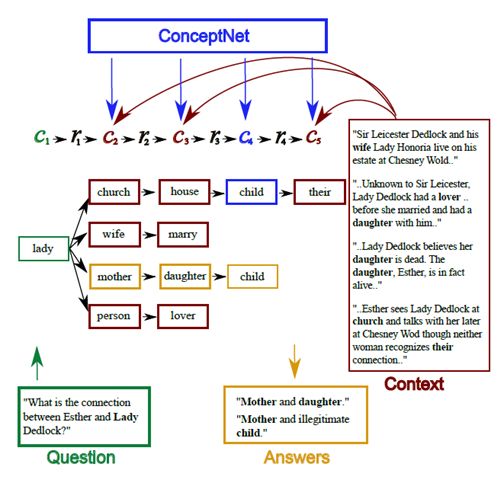
对每一个样本,需要中外部KG中选择与之相关的多跳路径,做法如下:
(1) 在KG中找出多跳路径,其中包含的实体出现在样本的问题或文档中
(2) 对这些路径中的实体节点按照出现次数或PMI打分
(3) 类似beam search, 从所有路径生成的输出中挑选出得分最高的一些路径,这些路径是对该样本可能有帮助的外部常识信息
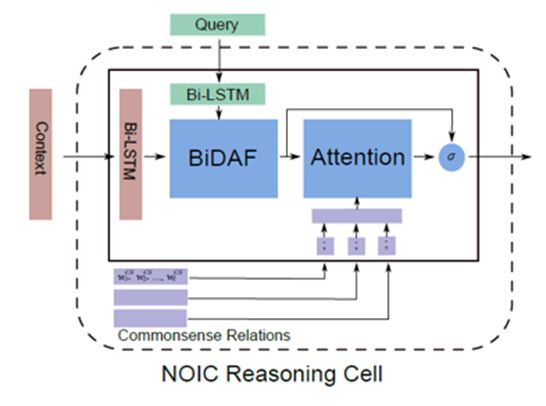
模型引入常识
引入外部常识通过修改Reasoning layer中的基本单元。具体做法是,每条路径的embedding表示为其每个节点的文本embedding的简单拼接,修改后的Reasoning cell在经过BiDAF的attention结构后,再对该样本的所有外部常识三元组路径做attention计算,该attention计算再次更改文档和问题中每个词的表示。
实验结果
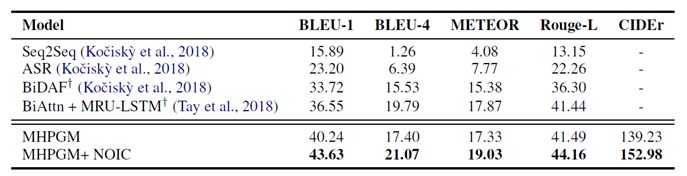
对比baseline模型和引入外部常识的模型可见,引入外部常识能是模型在BLEU和Rouge等指标上取得不错的提升。
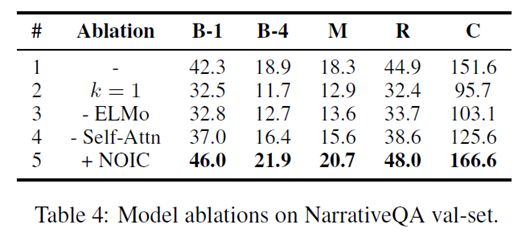
对模型做ablationtest, 可以发现推理层的推理次数如果为1,模型效果下降很多,这表明模型确实在利用多跳的路径信息。另外,ELMo embedding,以及经过Reasoning层后的self-attention,都对模型的效果提升较大。
本文作者: 王梁,浙江大学硕士,研究方向为知识图谱,自然语言处理.
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。







)






)

链表的实现集合的相关操作)


