本文转载自公众号:知识工场。
罗康琦,上海交通大学计算机系2019届博士,研究方向为自然语义理解和知识图谱。2012年获得华中科技大学软件工程学士学位,现就职于京东数据科学实验室(Data Science Lab)。他曾在AAAI,IJCAI,EMNLP等国际顶级会议上发表多篇论文。
本章的研究为基于知识库的自动问答任务。用户提出的问句可能具有复杂语义,其中包含了未知答案与相关实体的多种关系,因此复杂问句的回答过程充满了挑战。我们提出了面向复杂语义的知识库问答模型,主要特点在于,我们利用神经网络学习复杂语义结构的整体连续特征表示,从而捕捉不同语义成分之间的信息交互。
5.1 概述
基于知识库的自动问答( KBQA )是自然语言处理中的经典应用场景。该任务以自然语言问句作为输入,并根据已有结构化知识库提供的信息,寻找到问句的一个或多个答案。以 Freebase,YAGO,DBPedia 为代表的结构化知识库主要以维基百科为骨架构建而成,它们包含真实世界的广域知识,因此常用于自动问答任务中。
在自动问答任务中,我们关注的问题称为 “事实类问题” ,其特点在于它们询问的是与句子中实体相关的客观事实,因此答案为知识库中存在的实体、数值或时间。以一个较简单的问题为例,“ What’s the capital of the United States? ” ,为了准确回答这个问题, 一个较为直接的方式是,首先识别句子中的相关实体并链接到知识库,再将该实体与目标答案之间的自然语言关系映射为知识库中的一个谓词(或为词序列),那么原问题即可转换为具有(实体,谓词,目标答案)三元组形式的查询语句,例如 ( united_states, capital,? ),通过在知识库上运行查询语句,生成最终的结果。将已有的<问题,答案> 对作为训练数据,我们可以通过远距离监督( Distant Supervision )的形式学习问句和查询语句之间的映射关系。
对于只包含简单语义的问题,我们可以通过上述方法将其转为知识库上的一个基本三元组查询,但这样的方法并不适用于其它具有更复杂语义的问题。例如图5–1所示,为了准确回答问题 “ What is the second longest river in United States? ” ,我们实际上需要对其进行推理,得出以下三条语义线索:1)答案实体位于美国内部;2)答案实体的类型是河流;3)在满足前两个条件的所有实体中,根据长度属性进行降序排列,目标答案排在第二位。具体分析,第一条语义类似于简单问题,描述相关实体和答案间的关联,第二条语义则描述了知识库中的特定类型与答案的包含关系,第三条语义和序数相关,它甚至不能简单地对应到知识库中已有的事实三元组。由此可见,我们需要挖掘出多条不同的关系,才能准确地定位目标答案。对于这类无法通过单个三元组查询来精确描述语义的问题,我们将它称为“复杂问题”,也是这个章节研究的重点。
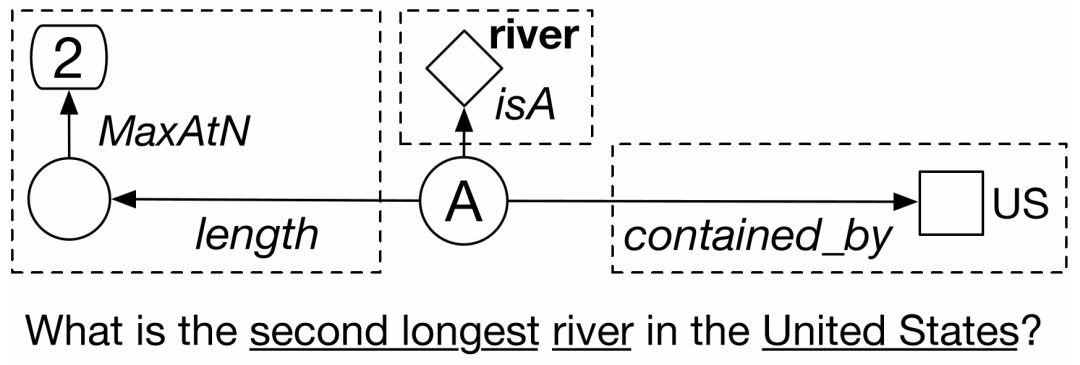
图5–1 一个具有复杂语义的问句示例。
回答复杂问题的核心,在于问答系统是否能准确理解问句中多部分语义之间的组合关系,而不仅仅是通过搜索的方式得到答案。这条思路对应了解决自动问答的语义解析技术( Semantic Parsing ) [39,40]。对于一个问句,基于语义解析的模型会将其转换成一棵语义解析树,这样的解析树等价于知识库中的查询图( Query Graph ),与关系理解中的模式图类似,是包含未知实体知识库子结构。本章中,“语义解析树” ,“查询结构” 和 “查询图”表示同一概念。图5–1为问题“ What is the second longest river in United States? ” 的查询图,具有树形结构。代表未知答案的节点 A 为解析树的根节点,三个叶节点US, river,2则由问句的字面描述中抽取出来,并已链接到知识库中的实体、类型、时间或是数值上。这些叶节点通过知识库中的谓词(序列)与答案节点连接,从而对未知答案进行限制,因此本节中也称叶节点为问句的 “相关节点” 。此外,近年来神经网络模型在提高自动问答系统的性能方面显示出了巨大的前景,在多个不同的自动问答数据集上,通过神经网络改善语义解析的方法成为了目前最先进的技术[42,43,139]。基于以上论述,本章所讨论的工作围绕语义解析技术结合神经网络模型的思路,并将其扩展至复杂问题场景。
语义解析模型可以分为两个部分:生成候选查询图,以及预测最佳查询图。候选查询图的生成可以采用自底向上的方式构建[40,41],或是分阶段形式,由简到繁逐步生成所有候选[42,43]。预测最佳查询图,主要是基于计算问题和查询图之间的语义相似度,挑选出最佳查询图。对于回答简单问题,目前已有的神经网络模型主要遵循“编码-比较”框架,即首先利用卷积神经网络( CNN )或循环神经网络( RNN ),将原始问题以及候选的谓词序列分别进行编码,形成在同一个向量空间中的两个不同的语义向量,两者之间的语义相似度则可以定义为向量空间中的距离度量。
当输入的问题具有复杂语义时,候选的查询图无法简化为线性的谓词序列,如何对复杂的查询图进行编码,成为了语义相似度模型的关键问题。一个较为直观的做法,是将整个查询图看做由答案节点到不同叶节点的路径集合,例如图5–1中的虚线框将查询图分成三个语义成分,分别对应指向不同相关实体的谓词序列。这使得针对简单问题的神经网络模型可以被直接应用,即分别计算问句与不同语义成分的相似度分值,并将其聚合(平均或相加),用来代表问句与查询图整体的语义相似度。
这种基于查询图拆分的方式具有其合理性,每个语义成分仅对应一个相关实体,类似人类对问句推理得到的平行语义线索。然而,基于此法套用简单问题的神经网络模型,依然存在两个缺陷。第一个缺陷是,将独立的语义成分与问句直接比较会带来风险。 对于简单问题,唯一的谓词路径代表了整个问句的语义,问句和查询对应的语义向量越相近,代表它们匹配度也越高。然而复杂问题的查询图中,每一个独立的路径仅包含问句部分语义,即便是正确的谓词路径,与问句整体依然存在语义差距。若整体相似度由各部分相似度相加产生,则可能导致训练陷入局部极值,即问句经编码后的语义向量倾向于查询图中的某条特定谓词路径,而难以和其余正确的语义成分产生匹配。第二个缺陷是,分别计算相似度再简单相加的形式会丢失信息。将查询图的多个谓词序列分别进行编码,计算相似度再合并,这样的做法视作互相独立的多个部分。因此这样的模型无法理解不同语义成分之间存在的重叠、互补等语义交互。模型没有学习整个查询图的语义向量,因此无法从一个全局的角度描绘复杂查询图所包含的语义组合。
已有的文献 [42, 139] 尝试规避上述两个缺陷,它们的共同点在于从查询结构中仅挑选一条主路径,与问句计算语义相似度,对于查询结构中的其它限制,则依赖于人工定义的规则特征,或引入外部非结构化文本进行额外过滤。问答模型效果得以提升,但并没有直接应对这样的不足。
在本章中,我们着手于利用神经网络模型改善问句与复杂查询图之间语义相似度计算的效果,并尝试解决之前论述的两个缺陷。该模型整体基于对问句和谓词序列的编码,将其表示为同一个语义空间下的语义向量。我们的模型和之前方法主要区别,在于模型对各个语义成分编码后的向量进行结合,形成对于查询图整体的语义向量表示。同时,为了弥补问句和语义成分之间的信息不对等,在对问句进行编码的过程中,我们利用依存语法分析( Dependency Parsing )寻找问句中和特定谓词序列相关的局部信号,以此作为对问句字面信息的补充,使模型能更好地将问句和不同的语义成分对齐。
本章的贡献可以总结为以下四个部分:
1. 提出了一个轻量化和有效的神经网络模型来解决具有复杂语义的自动问答任务。 据我们所知,这是第一次尝试在模型中对复杂查询图的完整语义进行明确编码;
2. 通过融入依存语法分析信息来丰富模型中问句的语义表示,并进行模型分析以验证其有效性;
3. 通过一种集成的方法,对已有的实体链接工具进行改良,丰富从问句中获得的候选实体,并进一步提升任务的整体效果;
4. 在多个自动问答数据集上进行实验,在由复杂问题组成的 ComplexQuestions 数据集中,模型的效果超过了已有的方法,在主要有简单问题组成的 WebQuestions 和 SimpleQuestions 数据集中,模型依然具有很强的竞争力。
5.2 相关工作
基于知识库的自动问答是最近几年的热门研究。最主要的用于解决自动问答的方法可以分为两类:基于信息抽取( Information Extraction )和基于语义解析( Semantic Parsing )。
基于信息抽取的问答模型首先通过实体链接寻找句子中的相关实体,将它们在知识库上邻近的实体抽取出作为候选答案。对于候选答案的排序,则依赖以候选答案为中心的知识库子图与问句之间的关联特征。早期的文献 [35] 利用特征工程进行训练,而后一系列深度学习模型[37,95,96]则通过神经网络学习答案在类型、谓词、上下文等多个不同维度与问句的语义关联程度,并取得了明显的效果提升。基于语义解析的系统则会先生成带有复杂结构的候选查询图,将查询图翻译为能在运行在知识库上的结构化查询语句,得到最终的答案。早期的语义解析系统[38,39]根据 PCCG 文法生成和具体知识库无关的中间表达形式,通常以 λ 算子的形式呈现,再将 λ 算子中的谓词和常量,映射到知识库中的具体谓词和实体。Liang 提出的 λ-DCS [89]是对 PCCG 的简化,语义解析树依然为自底向上的方式,但 λ 表达式由简单的相交、合并等规则生成,大大降低了解析树生成的复杂程度。最近的研究中,分阶段候选差选图的生成[42,43]已证明了其有效性, 它利用深度搜索,通过由简到繁逐步扩展查询图,不需要定义操作,也摆脱了自底向上生成过程中,组合顺序与单词顺序相关的限制。
随着深度学习的发展,神经网络模型被广泛使用于知识库上的自动问答任务,并且展示出了优秀的结果。这些方式的基本思路是利用神经网络的对特征表示的学习能力,将问句转换为连续空间上的向量表示,同时再将查询结构(或答案实体)映射到同一语义空间,并定义问句和答案的语义相似度,根据<问题,答案>对进行学习,预测正确的查询。处理简单语义的神经网络问答模型具有较多的变种,例如文献[48,92]使用了字符级别的循环神经网络以及注意力机制,对谓词序列和相关实体均进行相似度计算, 对于未在训练数据中观察到的单词,模型依然具有鲁棒性;Bordes 等人[46]利用知识库向量学习,关注候选答案的在知识库中的类型、相连谓词、相邻实体等信息,学习它们在知识库上的向量表示,并以此对候选答案进行编码;Yu 等人[49]引入了多层循环神经网络,并通过残差连接的方式,同时捕捉问句在词级别和整体级别与特定谓词序列的语义匹配;Qu 等人[93]提出了 AR-SMCNN 模型,除了利用循环神经网络捕捉问句和谓词序列在语义上的相关性,还利用了类似与卷积神经网络处理二维图像的方式,在词级别相似度矩阵中寻找纹理,学习问句和谓词序列的另一种相似度量。
对于利用神经网络回答复杂语义的问题,已有的工作进行了不少尝试,但并没有尝试学习查询图整体的语义表示。例如文献[42, 139]侧重于用神经网络计算问句和查询图中主路径的匹配关系,相当于退化至简单语义场景。对于查询图中,除去主路径的其余语义成分,Yih 等人[42]利用人工定义特征捕捉少数特殊语义,但基于特征工程的方法不具有较好的扩展性;Xu 等人[139]则挖掘非结构化文本中的上下文信息,对满足主路径的候选答案进行过滤,这种方式被视为模型计算之后的处理,而并没有从本质上解决问题。Bao 等人[43]利用每个相关实体在问句中的上下文窗口表示局部语义,并和查询图中的对应的谓词路径进行相似度匹配计算,但谓词路径之间仍缺少关联。
此外,依存语法分析可以描述一个句子中,词汇间的远距离依赖关系,考虑到它与查询图的结构较为相似,因此候选查询结构的生成可以基于依存分析树进行转换,语义匹配过程也更多利用了结构上的相似关系,例如文献[90, 91]。我们的模型同样使用了依存语法分析,但将其视为语义特征的信息来源,而并非直接决定候选查询图的形状,因此我们可以生成更灵活的查询图。
5.3 我们的方法
本节将具体阐述复杂语义下的自动问答模型。主要包括四个部分:1.基于分阶段的方式生成所有候选查询图; 2. 通过神经网络定义问句和查询图整体之间的语义相似度; 3.基于集成的方式对已有的实体链接结果进行扩充;4.具体的训练以及测试流程。
5.3.1 分阶段查询图生成
本节中主要阐述分阶段候选查询图的生成过程。与已有的工作比较,例如文献[43],我们对候选生成的策略进行了优化,主要利用了查询图中对答案类型的隐含限制,以及知识库中用来维护和时间段事实相关的特殊设计。本文中,我们主要考虑四种不同的语义限制,分别是实体、类型、时间、顺序限制。例如在问句中,实体限制描述了答案与某已知实体的联系,顺序限制描述了答案按某种方式排序所具有的序号。以图5–2为例,我们通过问句 “ who is the youngest president of the united states after 2002? ” 阐述候选图的具体生成过程,该问句同时包含了上述四种语义限制。为了方便描述,本节假设 Freebase 为问答系统所使用的知识库。
阶段一:相关节点链接。该步骤寻找问句中代表相关实体、类型、时间、顺序的词汇或短语,并链接到知识库上。相关节点作为候选查询图的叶节点,是不同类别语义限制的起点。图5–2(a) 列出了可能的 < 短语,叶节点 > 对,同一个短语可以对应到多个候选叶节点。不同语义限制类别(实体、类型、时间、顺序)的叶节点有着各自的链接方式。对于实体链接,我们使用了已有的链接工具 S-MART [54],在多个已有的自动问答研究均被使用。S-MART 对所有可能的 < 短语,实体 > 进行打分,并保留了至多前十组结果。对于类型链接,考虑到知识库中不同的类型数量有限,我们枚举问句中所有长度不超过 3 的短语,并根据预训练的词向量,计算不同短语和类型之间的余弦相似度,同样保留至多前十组结果。对于时间链接,我们通过正则表达式识别句中出现的所有年份。对于顺序链接,我们利用预先定义的形容词最高级词汇列表(例如 largest,highest, latest 等描述客观事实的最高级词汇),并在问句中匹配最高级词汇,或 “序数词 + 最高级”的词组,如“ second longest ”。对应的叶节点表示顺序值,若匹配到序数词,则顺序值为序数词对应的数字,否则为 1。如图5–2(a)所示,<“ youngest ”, 1> 为生成的唯一顺序链接。
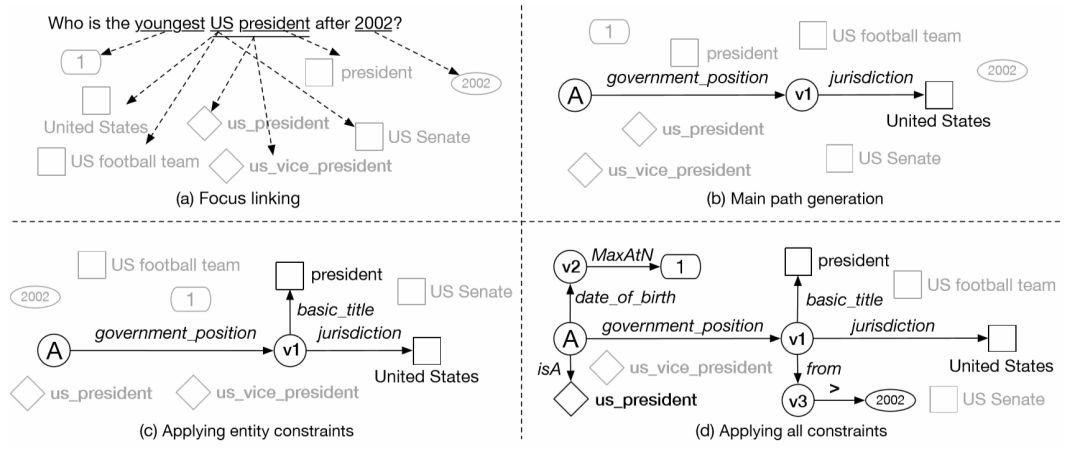
图5–2 分阶段候选图生成的具体例子。
阶段二:生成主路径。主路径是一个查询图的基础,代表着问句最主要的语义。考虑到几乎所有的事实类问题都和问句中至少一个实体相关,因此它被定义为从答案出发,通过谓词序列连接至某个实体节点的路径,等同于一个简单问题的查询图。我们枚举所有被链接的实体,以及它们在知识库中相连的合法谓词序列,即可生成一系列候选主路径。谓词序列的长度为1或2,后者实质是描述了多元关系中某两个实体的关联。图5–2(b) 显示出了某一个主路径,其中答案节点 A 以及中间节点 v1 都是变量节点。对于后续更复杂的语义限制,在图中均表示为由主路径上某变量节点出发,指向特定的叶节点的谓词序列。
阶段三:添加额外实体语义限制。这个步骤的目的是在主路径之上扩充与实体相关的语义限制。受到4.2.4.1节中复杂模式图生成的启发,我们同样采用深度优先搜索的方式,由简到繁进行查询图生成。对搜索空间中的每一个查询图,我们尝试单个谓词连接不同的变量节点与实体节点,构建出具有不同复杂程度的查询图。如图5–2(c)所示,在主路径上添加的实体语义限制为( 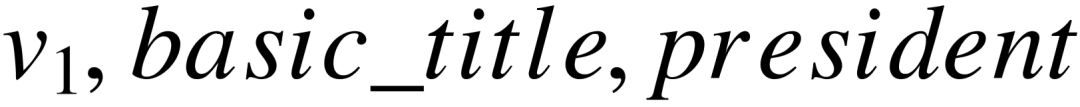 )。基于深度优先搜索的优势在于查询图中的实体数量不受限,和基于模板的候选生成方法相比,具有更高的覆盖率, 同时搜索过程中可以通过剪枝策略排除无法生成答案的查询图,提高候选生成速度。
)。基于深度优先搜索的优势在于查询图中的实体数量不受限,和基于模板的候选生成方法相比,具有更高的覆盖率, 同时搜索过程中可以通过剪枝策略排除无法生成答案的查询图,提高候选生成速度。
阶段四:添加类型限制。类型限制只能和答案节点关联,利用知识库中的 IsA 谓词连接某个具体的相关类型节点。在该步骤中,我们对已有方法进行了改进:通过答案节点直接连接的谓词,推测出其具有的隐含类型,以此对类型限制进行过滤。如图5–2(c)所示,与答案直接相连的谓词为 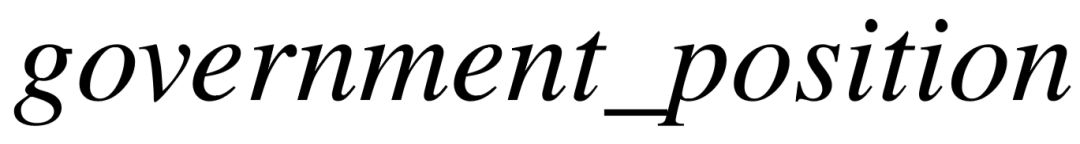 ,根据知识库对谓词的定义,其主语类型为
,根据知识库对谓词的定义,其主语类型为  ,因此成为答案的隐含类型。因此,我们可以过滤与隐含类型无关联的相关类型节点,从而防止语义偏离,并提升候选差选图的生成速度。具体而言,为了定义两个类型是否相关,我们采用了4.1.2.3节中通过松弛类型包含构建的 Freebase 类型层次关系。若某相关类型不包含任意一个隐含类型,或不被任意一个隐含类型包含,我们则将其视为无关类型,不用于候选生成。
,因此成为答案的隐含类型。因此,我们可以过滤与隐含类型无关联的相关类型节点,从而防止语义偏离,并提升候选差选图的生成速度。具体而言,为了定义两个类型是否相关,我们采用了4.1.2.3节中通过松弛类型包含构建的 Freebase 类型层次关系。若某相关类型不包含任意一个隐含类型,或不被任意一个隐含类型包含,我们则将其视为无关类型,不用于候选生成。
阶段五:生成时间、顺序限制。 完成类型限制的添加后,主路径上所有变量节点的类型(显式类型限制以及隐含类型)都已确定,因此我们可以枚举隶属于这些类型的特定谓词,完成时间和顺序限制的添加。如图5–2(d)所示,时间限制通过长度为2的谓词序列表示,例如序列 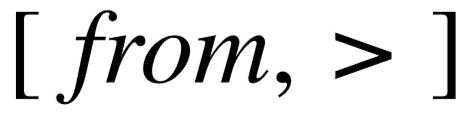 ,其中前一个谓词在知识库中指向时间,后一个谓词为虚拟谓词,指明了和特定时间比较的方向,由问句中位于时间前的介词进行确定,例 如“ before ”,“ after ”以及“ in ”。类似地,顺序限制同样由长度为2的谓词序列表示,例如序列
,其中前一个谓词在知识库中指向时间,后一个谓词为虚拟谓词,指明了和特定时间比较的方向,由问句中位于时间前的介词进行确定,例 如“ before ”,“ after ”以及“ in ”。类似地,顺序限制同样由长度为2的谓词序列表示,例如序列  ,前者在知识库中指向整数、浮点数或时间,后一个谓词表示降序排列。我们并不能从问句中获取直接的信号确定排序方向,因此生成具体的排序限制时,两种方向都进行枚举。值得注意的是,对于时间限制,我们的方法进行了针对性优化。已有的文献 [42,43]仅考虑使用一条谓词与时间相连,我们的改进在于使用了知识库中存在的成对时间谓词,来描述更加准确的时间限制。Freebase 中,成对时间谓词用来描述和时间段相关的事实,例如图5–2(d) 中的 from 谓词,存在谓词 to 与之对应,两者分别为起始时间谓词和终止时间谓词。我们通过简单的名称匹配方式,收集了知识库中356组成对谓词,对于时间比较为 “ in ” 的形式,例如句中出现 “ in 2002 ” ,我们在图中使用起始时间谓词进行连接,但生成 SPARQL 查询语句时,起始和终止谓词均会被使用,从而确保问句中的相关时间能够限制在一个时间段内,而不是仅仅等同于起始或终止时间点。
,前者在知识库中指向整数、浮点数或时间,后一个谓词表示降序排列。我们并不能从问句中获取直接的信号确定排序方向,因此生成具体的排序限制时,两种方向都进行枚举。值得注意的是,对于时间限制,我们的方法进行了针对性优化。已有的文献 [42,43]仅考虑使用一条谓词与时间相连,我们的改进在于使用了知识库中存在的成对时间谓词,来描述更加准确的时间限制。Freebase 中,成对时间谓词用来描述和时间段相关的事实,例如图5–2(d) 中的 from 谓词,存在谓词 to 与之对应,两者分别为起始时间谓词和终止时间谓词。我们通过简单的名称匹配方式,收集了知识库中356组成对谓词,对于时间比较为 “ in ” 的形式,例如句中出现 “ in 2002 ” ,我们在图中使用起始时间谓词进行连接,但生成 SPARQL 查询语句时,起始和终止谓词均会被使用,从而确保问句中的相关时间能够限制在一个时间段内,而不是仅仅等同于起始或终止时间点。
所有阶段结束后,我们将所有生成查询图转换为 SPARQL 查询语句,并在Freebase 中查询最终答案。图5–2(d)中的查询图对应的完整 SPARQL 查询语句对应如下:

代码5–1 SPARQL 查询语句示例
最后,我们舍弃掉没有结果的查询图,以及使用的相关实体对应词组出现重叠的查询图。和已有系统相比,本节的候选图生成使用了更少的人工规则,并在类型限制和时间限制上进行了改进,加快生成速度的同时,描述更加准确的语义限制。
5.3.2 基于神经网络的语义匹配模型
本节介绍的语义匹配模型如图5–3所示。作为预处理部分,查询图中使用的实体(或时间)节点对应于问句中的短语被替换为单词⟨ E ⟩(或⟨ 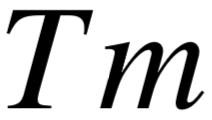 ⟩),这样问句的语义将不会被具体的实体或年份所干扰。为了对查询图整体进行编码,我们首先将其分拆为从答案节点出发,指向不同叶节点的谓词路径,也称为语义成分。同样为了去除具体的实体、时间、顺序值对语义的干扰,谓词序列不包括叶节点的信息,类型限制是一个特例,作为模型输入的谓词序列为[ IsA, river ],类型节点的信息被包含在内。接下来将逐个介绍对问句和谓词序列的编码,基于查询图整体语义表示计算相似度的方式。
⟩),这样问句的语义将不会被具体的实体或年份所干扰。为了对查询图整体进行编码,我们首先将其分拆为从答案节点出发,指向不同叶节点的谓词路径,也称为语义成分。同样为了去除具体的实体、时间、顺序值对语义的干扰,谓词序列不包括叶节点的信息,类型限制是一个特例,作为模型输入的谓词序列为[ IsA, river ],类型节点的信息被包含在内。接下来将逐个介绍对问句和谓词序列的编码,基于查询图整体语义表示计算相似度的方式。
5.3.2.1 语义成分编码
为了对语义成分 p 进行编码,模型对主要利用谓词序列的名字信息,以及每个谓词在知识库中的编号信息。以图5–3为例,查询图的第一个语义成分仅由一个谓词构成,对应的编号序列为 [ contained_by ]。将序列中的每个谓词在知识库中显示的名字相连,即可的到谓词名字序列,即[“ contained ”,“ by ”].
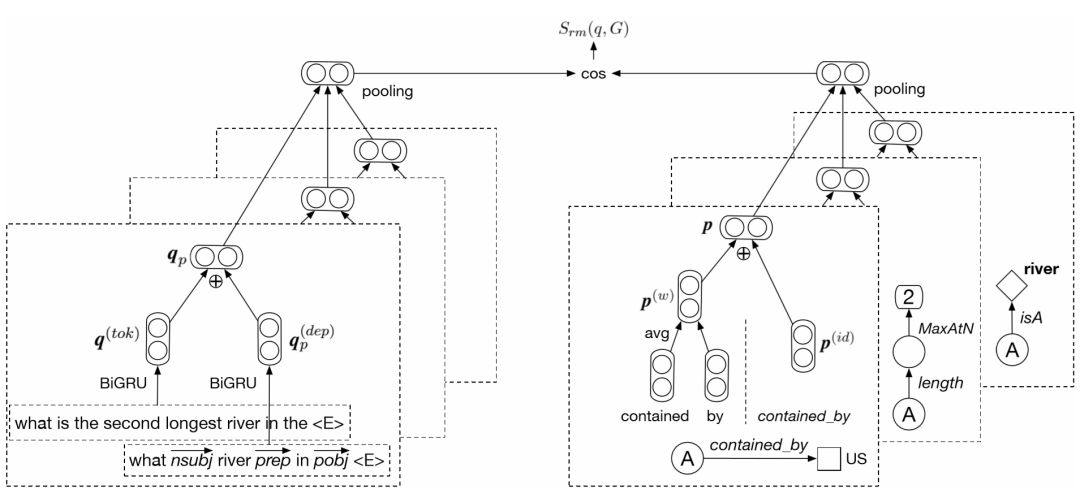
图5–3 语义匹配模型的整体结构
对于语义成分的谓词名字序列  ,我们首先通过词向量矩阵
,我们首先通过词向量矩阵 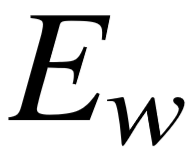 ∈
∈ 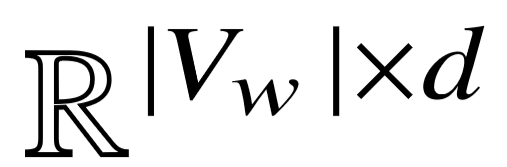 将原始序列变为词向量 , 其中 |
将原始序列变为词向量 , 其中 | 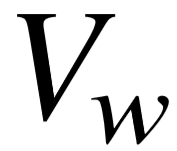 | 表示自然语言词汇数量, d 表示词向量维度。接着我们采用词平均的方式计算整个名字序列的语义向量,即
| 表示自然语言词汇数量, d 表示词向量维度。接着我们采用词平均的方式计算整个名字序列的语义向量,即 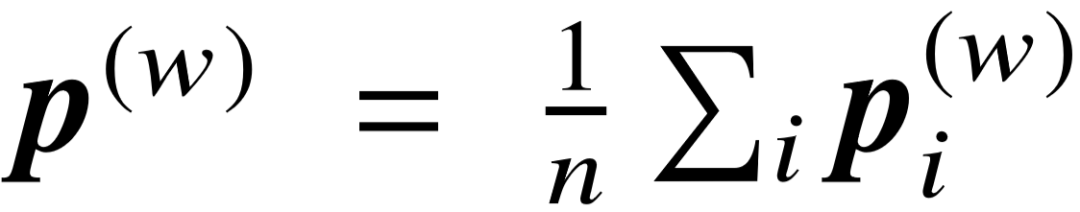 . 对于谓词编号序列
. 对于谓词编号序列  ,我们将整个序列视为整体,并根据序列级别的向量矩阵
,我们将整个序列视为整体,并根据序列级别的向量矩阵 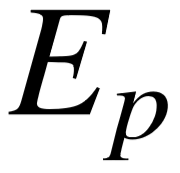 ∈
∈ 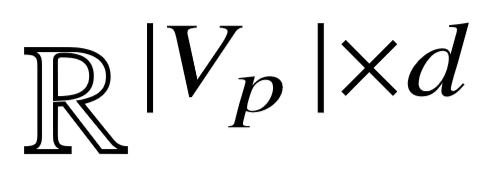 ,直接转换为语义向量表示,其中
,直接转换为语义向量表示,其中 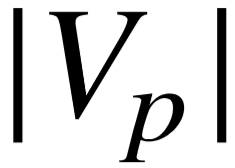 代表训练数据中不同的编号序列数量。之所以将编号序列看做整体,而不使用编号的向量平均或循环神经层表示语义,主要原因有以下三点:1)根据候选图生成方式,每个语义成分的谓词编号序列长度不超过3;2)通常情况下,对单个谓词序列进行打乱重排操作,新的序列是非法的,不会出现在其它查询图中;3)不同的谓词序列数量约等于知识库中不同的谓词数量,不带来成倍增长。将名字序列和编号序列的向量进行按位置相加,我们得到了单个谓词序列的向量表示,
代表训练数据中不同的编号序列数量。之所以将编号序列看做整体,而不使用编号的向量平均或循环神经层表示语义,主要原因有以下三点:1)根据候选图生成方式,每个语义成分的谓词编号序列长度不超过3;2)通常情况下,对单个谓词序列进行打乱重排操作,新的序列是非法的,不会出现在其它查询图中;3)不同的谓词序列数量约等于知识库中不同的谓词数量,不带来成倍增长。将名字序列和编号序列的向量进行按位置相加,我们得到了单个谓词序列的向量表示,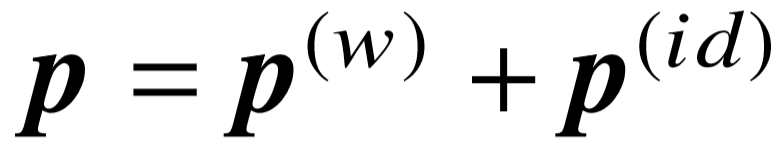 .
.
5.3.2.2 问句编码
对问句的编码需要考虑全局和局部两个层次,其目的是捕捉问句中与某特定语义成分 p 相关的语义信息。对问句全局语义的编码,输入信息为问句词序列。我们利用同一 个词向量矩阵 将词序列向量化,得到  。将该输入通过双向 GRU 层[140],并将前向序列和后向序列的最后一个隐藏状态进行拼接,作为整个词序列的语义向量:
。将该输入通过双向 GRU 层[140],并将前向序列和后向序列的最后一个隐藏状态进行拼接,作为整个词序列的语义向量: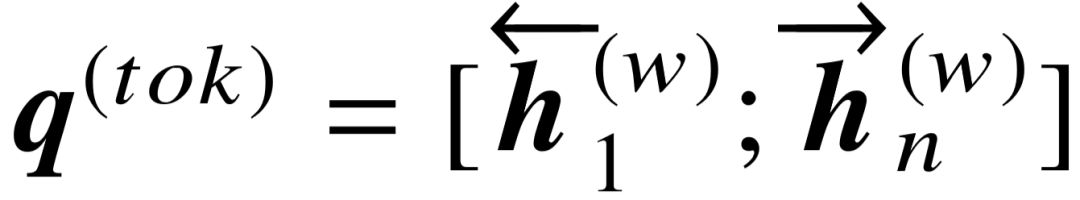 .
.
为了对表示问句的局部语义,核心在于提取与特定语义成分对应的信息。我们在模型中利用依存语法分析,寻找答案与语义成分中的实体之间的依赖关系。由于在问句中,wh- 词用于指示答案,因此我们抽取依存语法树中,连接 wh- 词和实体所对应短语的路径,该路径有且仅有一条。与[139]类似,在依存语法树上的一条路径包含了词,以及词之间带有方向的依存弧。例如图5–3中的句子,答案 “ what ” 与实体 “ United States ” 之 间的依存路径为 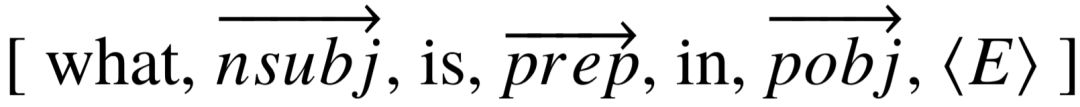 。我们使用另一个具有不同参数的双向 GRU 层,对依存路径进行编码,生成向量表示
。我们使用另一个具有不同参数的双向 GRU 层,对依存路径进行编码,生成向量表示 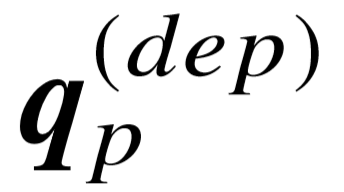 ,其中包含了语法层面的以及与语义成分 p 直接相关的特征。最后,我们同样将句子在两种粒度上的向量进行按位置相加,得到整个问句对应特定语义成分的向量表示,
,其中包含了语法层面的以及与语义成分 p 直接相关的特征。最后,我们同样将句子在两种粒度上的向量进行按位置相加,得到整个问句对应特定语义成分的向量表示,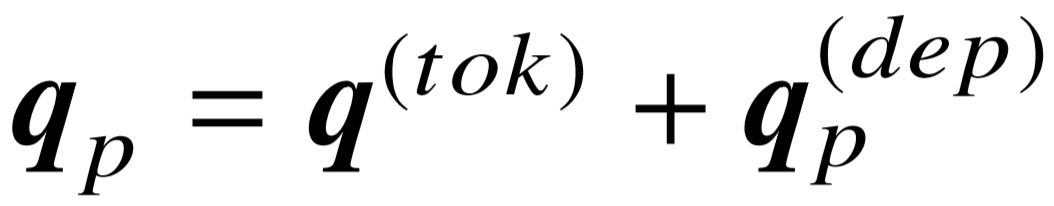 .
.
5.3.2.3 语义合并
给定具有 N 个语义成分的查询图 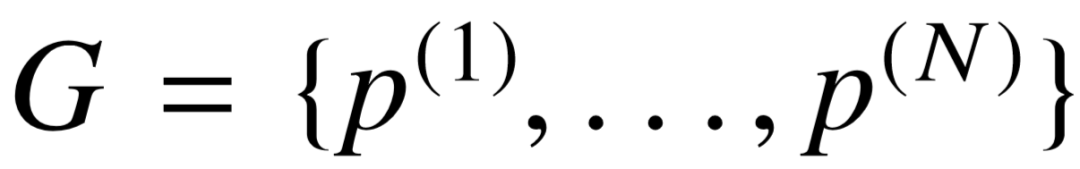 , 每个语义成分已经被投影至同一个连续语义空间上的不同向量,体现了不同方面的隐藏特征。受卷积神经网络应用于二维图像处理所启发,图像整体的特征表示取决于是否存在某些局部区域,其样式与对应隐藏特征相吻合,而忽略这些局部区域的相对位置。考虑到复杂查询图内部的多个语义成分是并列的,互相之间并无次序之分,因此,模型对语义成分的向量表示进行最大池化( Max Pooling ),获得整个查询图的组合语义表示。相应地,针对每个语义成分所对应的问句语义表示,我们同样进行最大池化操作,将多个语义向量合并为问句的整体表示。最后,我们利用余弦相似度计算问句和整个查询图之间的语义相似程度:
, 每个语义成分已经被投影至同一个连续语义空间上的不同向量,体现了不同方面的隐藏特征。受卷积神经网络应用于二维图像处理所启发,图像整体的特征表示取决于是否存在某些局部区域,其样式与对应隐藏特征相吻合,而忽略这些局部区域的相对位置。考虑到复杂查询图内部的多个语义成分是并列的,互相之间并无次序之分,因此,模型对语义成分的向量表示进行最大池化( Max Pooling ),获得整个查询图的组合语义表示。相应地,针对每个语义成分所对应的问句语义表示,我们同样进行最大池化操作,将多个语义向量合并为问句的整体表示。最后,我们利用余弦相似度计算问句和整个查询图之间的语义相似程度:
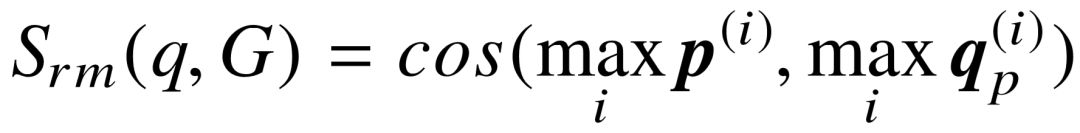
(5-1)
基于以上框架,本节提出的的语义相似度模型能尽可能使问句与单个语义成分具有可比性,同时捕获查询图不同部分之间的互补语义特征。
5.3.3 实体链接扩充
S-MART 实体链接器[54]在本模型中类似于一个黑箱,不具有操控性,并且生成的结果倾向于高准确率,而牺牲了一定召回率。为了在实体链接步骤寻找一个更好的准确率与召回率间的平衡,我们提出了一个基于集成的方式对实体链接结果进行扩充。首先,我们通过维基百科建立一个大的 < 词组,实体 > 对应表,每个实体和如下词组相对应:1) 实体页面的标题;2) 实体所在的重定向、消歧义页面标题;3) 实体在其它实体页面提及的链接文字,即锚文本( Anchor Text )。之后,每一对 < 词组,实体 > 都关联上一组统计特征,包括实体的链接概率、词级别的 Jaccard 相似度、三连字符级别的 Jaccard 相似度、实体在维基百科中的热门度、实体在知识库中的热门度。最终,我们使用一个双层全连接的线性回归模型,将所有出现在 S-MART 链接结果中的词组实体对作为模型训练数据,用来拟合每一对的 S-MART 链接分值。模型训练完毕后,词组实体对应表中的每一对条目都将计算出一个虚拟的链接分值。对于每个问题,我们挑选出不在 S-MART 已有结果中,且分数排在前 K 位的条目,作为实体链接结果的扩充,阈值 K 为模型超参数。
5.3.4 问答系统整体训练及预测
为了从一系列候选中预测最佳查询图,我们用 S( q, G ) 表示问句 q 和查询图 G 之间的整体关联分值。前一小节的语义匹配模型关注谓词路径层面的相似性,而整体关联分值还涉及到更多维度的特征,例如实体链接的置信度,以及查询图本身的结构特征。所以 S( q, G ) 为一系列实体链接、语义匹配、查询结构层面上的特征进行加权求和而得。表5–1为完整的特征列表,实体链接特征为链接分数之和,以及每个链接的来源( S-MART 或链接扩展);语义匹配特征即神经网络的输出 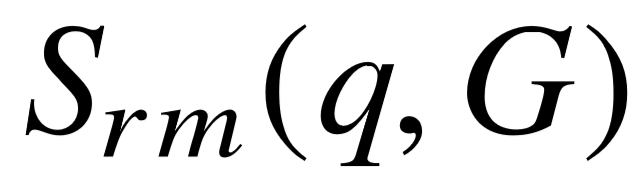 ;查询图结构特征为不同类别限制的数量、主路径长度以及输出的最终答案个数。我们利用最大间隔损失函数进行模型训练,尽可能较好查询图
;查询图结构特征为不同类别限制的数量、主路径长度以及输出的最终答案个数。我们利用最大间隔损失函数进行模型训练,尽可能较好查询图 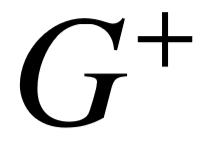 和较差查询图
和较差查询图 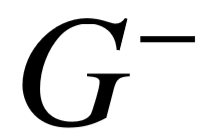 之间的分数差距:
之间的分数差距:
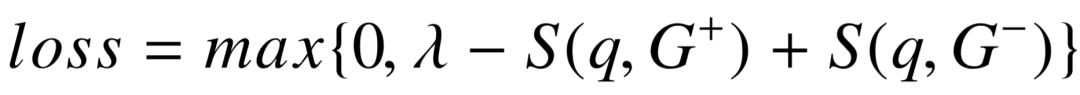
(5-2)
由于问答数据集通常只包含正确答案,而不标注查询图,我们依据查询图生成的答案对应的  分数区分正负样本。对于每一个 分数高于一定阈值(设定为 0.1)的查询图, 我们将其视为正样本 ,并从候选集中随机选择最多 20 个具有更低 的查询图作为 ,组成不同的样本对。
分数区分正负样本。对于每一个 分数高于一定阈值(设定为 0.1)的查询图, 我们将其视为正样本 ,并从候选集中随机选择最多 20 个具有更低 的查询图作为 ,组成不同的样本对。
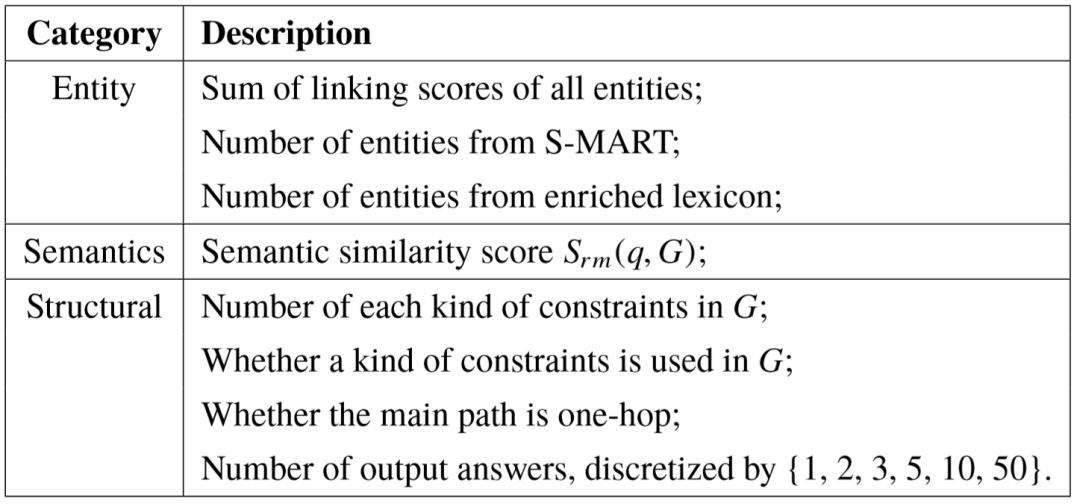
表5–1 预测最佳查询图所使用的特征。
5.4 实验
本节主要介绍我们所使用的自动问答数据集,以及用于比较的已有问答模型。具体实验包括在多个数据集上的端到端测试,以及一系列切除测试,用来分析方法中不同模块的重要性。
5.4.1 实验设置
自动问答数据集:我们在实验中使用了三个开放领域的数据集,分别为 ComplexQuestions [43], WebQuestions [40] 以及SimpleQuestions [47],对应缩写为 CompQ ,WebQ 和 SimpQ 。CompQ 数据集来源于 Bing 搜索引擎日志,一共包含 2,100个具有复杂语义的问题,以及人工标注的答案,前1,300个问句为训练集,后800为测试集。WebQ 数据集收集了 5,810 个通过 Google Suggest API 抓取的问题,以及对应的人工标注答案,约有 15% 的问句为复杂语义,同样数据集被分为 3,778 句训练集,以及 2,032 句测试集。 SimpQ 一共包含 108,442 个具有简单语义的问句以及标注的答案,答案形式为<相关实体,谓词>对,我们主要利用该数据集进行补充实验,验证回答复杂问题的模型在简单语义场景中的性能。对于其它自动问答的数据集,例如 QALD,由于测试集数量过小, 我们没有在这之上进行实验。
知识库:对于在 CompQ 和 WebQ 上进行的实验,我们跟随文献 [40, 139]的实验设置,使用完整版本的 Freebase 作为知识库,共包含约 46,000,000 个不同实体,以及 5,323 种不同谓词。同时通过开源图数据库Virtuoso 对 Freebase 进行访问与查询。对于 SimpQ 上进行的实验,我们使用数据集中提供的 FB2M 知识库,它是 Freebase 的一个 子集,包含大约 2,000,000 个实体和 10,000,000 个事实三元组。
模型实现及调参细节: 对本节中的所有实验,我们使用基于 GloVe[59] 预训练的词向量作为模型词向量矩阵的初始化。词向量维度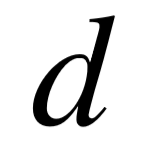 ,以及双向 GRU 层的隐藏状态维度均设为300。损失函数中的 λ 的调参范围为{ 0.1,0.2,0.5 },实体链接优化的集成阈值 K 范围为{ 1,2,3,5,10,+INF },训练批量大小 B 范围为{ 16,32,64 }.
,以及双向 GRU 层的隐藏状态维度均设为300。损失函数中的 λ 的调参范围为{ 0.1,0.2,0.5 },实体链接优化的集成阈值 K 范围为{ 1,2,3,5,10,+INF },训练批量大小 B 范围为{ 16,32,64 }.
5.4.2 端对端实验比较
我们首先对 WebQ 和 CompQ 数据集进行端到端测试。实验所使用的评价指标为所有测试问题的平均 分数。Berant 等人[40]提供的官方评测代码通过预测答案和标准答案的完全字面匹配计算每个问题的 分数,对于 CompQ 数据集,其中标注的实体名称和 Freebase 内实体名称存在大小写不一致的情况,因此我们参照 Bao 等人[43]的做法,计算 分数时忽略大小写。通过对验证集进行调参,WebQ 数据集的实验参数为 λ=0.5,B=32,K=3,CompQ 数据集的参数为 λ=0.5,B=32,K=5。
表5–2列出了在两个数据集上的具体实验结果。Yih 等人[42]在 CompQ 上的实验结果基于 Bao 等人[43]对其模型的实现。在 CompQ 数据集上,我们提出的神经网络模型超过了其它已有方法,将平均 分数提升了1.9,而在 WebQ 数据集上,与大量已有工作进行对比,我们的模型排在第二位,文献[141]基于记忆网络模型,成为分数最高的系统,其方法并不基于语义解析,无法直观解释一个答案是基于怎样的语义而生成,并且问答过程涉及的隐含语义与单一谓词路径相似,难以应对类型、时间、顺序等语义限制。需要指出的是,Xu 等人[139]利用维基百科的非结构化文本进行候选答案的验证,过滤掉满足主路径语义,但不匹配剩余语义的答案。由于此方法引入了大量由人工社区提供的额外知识,它达到了一个略高于我们方法的分数(53.3),但将此步骤去掉之后,模型分数跌落至47.0。此外,文献[42, 43]额外使用了 ClueWeb 数据集[142]学习谓词与自然语言词组之间的语义匹配关系。根据 Yih 等人公布的比较结果,把这一部分信息移除之后,WebQ 数据集上的 分数将下降了约0.9。此外,结果显示,扩充实体链接可以进一步提升问答系统的整体性能,在两个数据集上都获得了大约0.8的提升,是对语义匹配模型的一个良好补充。我们认为,和其它使用了 S-MART 链接工具的问答系统相比,我们的结果可以与之直接比较,这是因为 S-MART 的算法同样基于维基百科的半结构化信息进行学习,例如重定向链接、消歧义页面、锚文本等信息,实体链接扩充的步骤没有并没有引入额外的知识,因此可以直接比较。
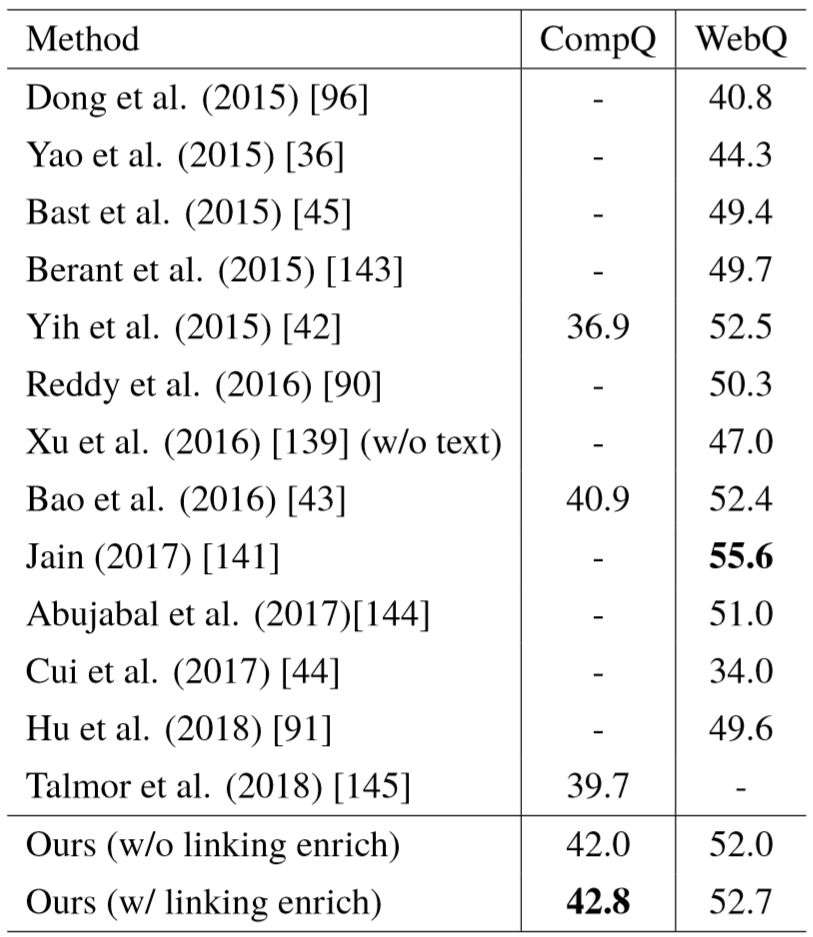
表5–2 CompQ 和 WebQ 数据集上的实验结果,评价指标为平均 分数
针对语义匹配本身,我们在 SimpQ 数据集上进行了测试。由于 SimpQ 提供了标注的相关实体,我们可以消除实体链接步骤带来的差错,单独衡量语义匹配的性能。我们根据相关实体的名字,倒推出它在问句中对应的短语,将其替换为< E >之后,预测问句所表达的知识库谓词,使用准确率作为评价指标。表5–3列出了具体的实验结果。相关文献主要针对简单问题,尝试了许多模型变种,例如文献[93]的准确率最高,该模型利用循环神经网络对问句语义进行建模,同时利用卷积神经网络,从问句和谓词名称的词级别二维相似度矩阵中学习隐藏匹配样式。文献[49]使用了双层双向 LSTM 网络对问句进行编码,并在两层中使用残差连接方式捕捉不同粒度的语义。我们的语义匹配准确率略低一些,考虑到重点在于多个语义成分的组合,而不是回答简单问题,我们的模型更加轻量,同时93.1%的准确率也确保了模型的有效性。
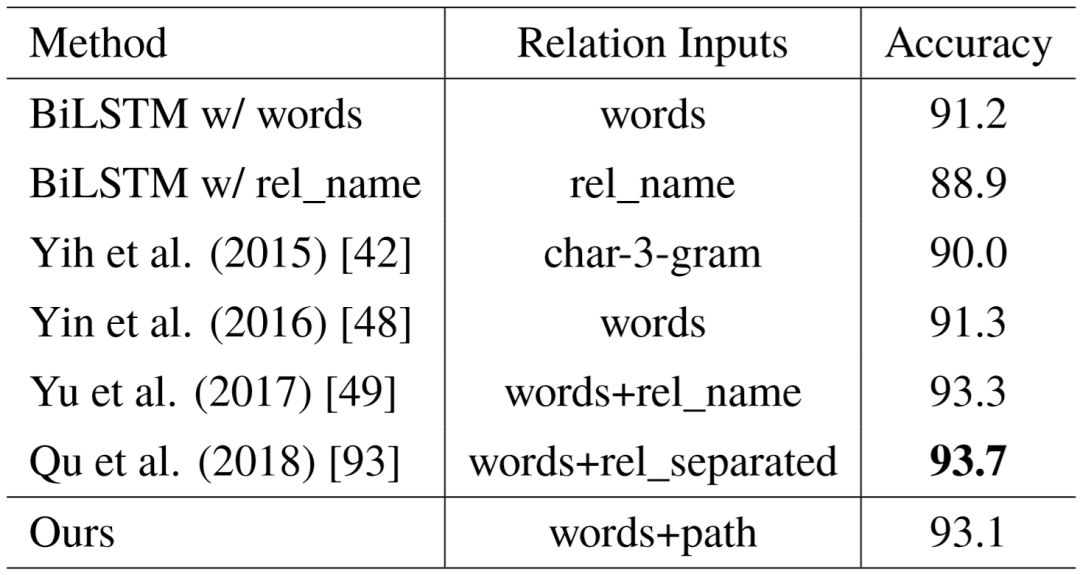
表5–3 SimpQ 数据集上的语义匹配测试结果
5.4.3 模型分析
本节主要对模型的各个主要进行分析测试,并讨论模型回答错误的一些例子。
5.4.3.1 谓词路径表示
我们改变模型对谓词路径的编码方式,并在 CompQ 和 WebQ 上进行分析测试。首先对于谓词名字序列,我们尝试使用双向 GRU 层(和问句编码部分结构一致,但不共享参数)拼接隐藏状态的方式替代词向量平均。对于谓词编号序列,我们将对路径整体编码方式改为谓词向量的平均。
实验结果如表5–4所示。观察发现,前三行的基线方法移除了名字序列或编号序列, 在两个数据集上的 分数明显低于后三行的方法。这说明了谓词的名字序列和编号序列所提供的语义可以互相补充。另一方面,对比最后两行实验,在 CompQ 数据集上,对名字序列使用词向量平均要优于使用双向 GRU,而在 WebQ 上,这个差距变得更小,我们认为原因主要来自于训练数据量的区别,WebQ 的训练集大小约为 CompQ 的三倍, 因此可以支持更复杂的模型。
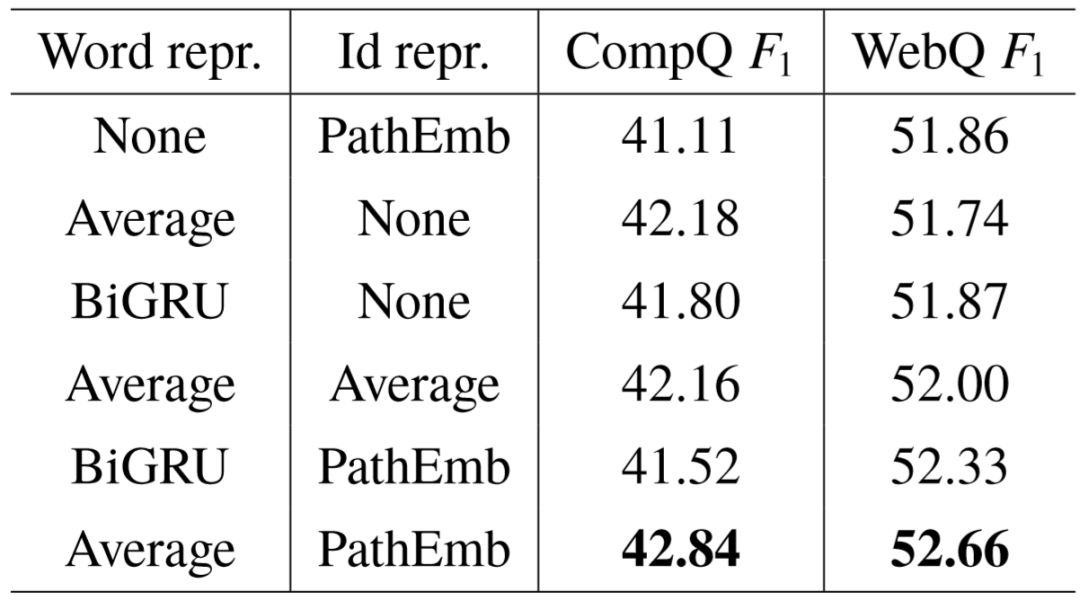
表5–4 对谓词表示的分析结果。
5.4.3.2 问句表示及语义组合
为了说明语义组合的有效性,我们建立一个基线模型:不使用公式5–2对应的最大池化操作,替代方式是分别计算每个问句表示和每个语义成分之间的相似度,并将各部分相似度分值相加,作为查询图与问句的整体相似度: 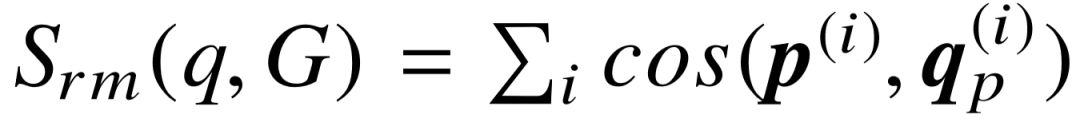 。对于问句的编码方式,我们进行一系列比对实验,观察不使用字面序列或依存语法路径对整体性能带来的影响。
。对于问句的编码方式,我们进行一系列比对实验,观察不使用字面序列或依存语法路径对整体性能带来的影响。
表5–5显示了在 CompQ 和 WebQ 上的具体比较结果。相比仅使用问句字面信息的模型,当依存语法分析提供的路径信息被使用后,问答系统整体性能平均提升了0.42。 在隐藏语义的角度,答案和相关实体之间的依存语法路径主要包含了词之间的语法依赖,以及每个词的功能化特征,是对整个问句序列信息的良好补充。然而,如果对问句编码只使用依存语法信息, 分数会大幅度下降约2.17。对于具有特殊语法结构的问题,如果仅关注疑问词和实体短语间的路径,会使得模型丢失句中表达语义的关键词, 例如以下两例:“ who did draco malloy end up marrying ”以及“who did the philippines gain independence from ” ,其中相关实体用斜体标出,代表语义的关键词为粗体。经过观察发现,WebQ 中大约有 5% 的问句具有类似的结构,在丢失关键语义信息后很难预测出正确的查询图。
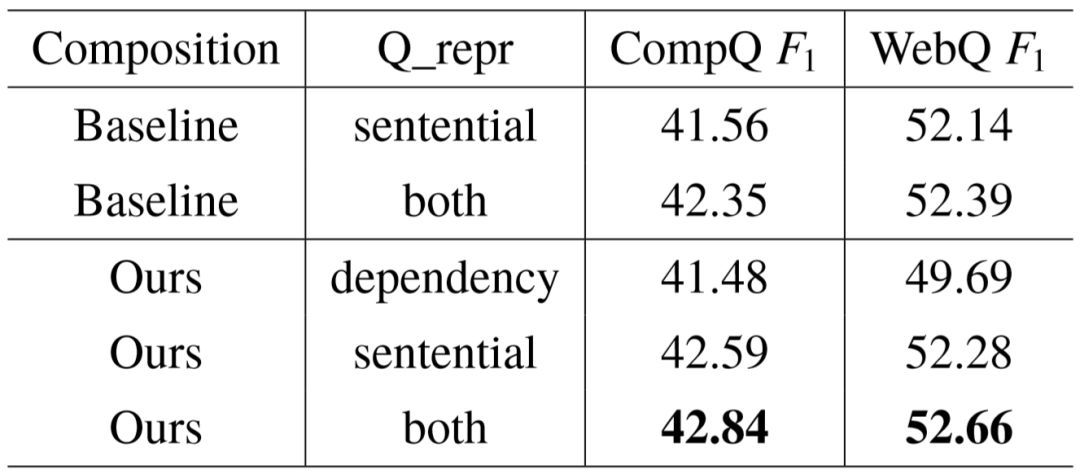
表5–5 问句表示和语义组合的分析测试。
语义组合的比较结果显示,模型中使用的最大池化操作要一致优于对应的基线方法。在 WebQ 上的提升要低于 CompQ ,主要原因是 WebQ 中约85%的问句依然是简单语义形式,无法体现语义组合的区别。移除依存语法信息和池化操作的模型可以视为一个基础的利用深度学习改善语义解析的问答模型。在复杂语义场景中,局部信息和语义组合的引入,两者结合使得 CompQ 数据集上效果提升1.28。
我们通过以下例子,进一步阐述模型中语义组合带来的优势。给定问句 “ who is gimli’s father in the hobbit ”,由于“ gimli ”的实体链接结果中既存在自然人,也存在名字一样的虚拟角色,我们主要关注下面两个可能代表真实语义的查询图:
1. 
2.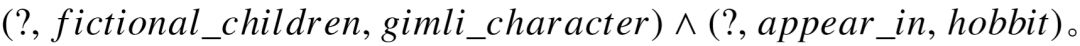
两个查询图涉及到三个不同的语义成分,如果独立观察其中每一个语义成分,谓词 children 与问句整体的匹配程度最高,因为 “ father ” 一词包含了很强的语义信息,训练数据中也包含较多 “ ’s father” 和 children 的关联,因此它们的关联特征容易被学习。 相比之下,fictional_children 过于生僻,而 appear_in 与“ father ”无关联,这两个语义成分的相似度远不如 children,因此基线模型认为第一个查询图更加正确。而我们的模型中,不同语义成分的隐藏特征通过池化方式汇集起来,分别将各自突出的隐藏语义传递出去,构成查询图整体的语义向量。与单独的 children 语义向量相比,查询图整体语义能兼顾与“ ’s father ”以及“ in the hobbit ”匹配,因此模型能正确预测第二个查询图为答案。
5.4.3.3 错误分析
我们从 CompQ 数据集中完全回答错误的问题中随机挑选100个例子进行分析,并归纳出下列几类错误原因。
主路径错误(10%):模型完全没有理解问句语义,哪怕最主要的语义也没有预测出来。这类错误对应的问题通常较难回答,例如“ What native american sports heroes earning two gold medals in the 1912 Olympics ”。
语义限制错误(42%):模型预测的查询图中包含正确的主路径,但其余语义限制存在偏差。比较典型的一类限制是隐含时间限制,例如问句 “ Who was US president when Traicho Kostov was teenager ” 无法准确回答,因为 “ when Traicho Kostov was teenager ” 暗示了时间限制,受限于候选生成方法,这类限制无法被识别。
实体链接错误(16%):这类错误的主要原因是问句中的一些实体词组具有高度歧义。例如问句 “ What character did Robert Pattinson play in Harry Potter ” ,而 “ Harry Potter ” 可以对应7部不同的电影,因此很难猜测问句中指的是哪一部。
杂项 (32%):包含了一些较明显的答案标注错误,以及问题本身语义不明确或不合逻辑。例如问句 “ Where is Byron Nelson 2012 ” ,根据标注答案可以帮助确定问句中 “ Byron Nelson ”的具体所指,然而此人已于2006年去世,因此该问题的真实意图难以捉摸,或许提问者想问的是他的逝世地点,或葬于何处。
5.5 小结
本章讨论了面向复杂语义的知识库自动问答任务,其难点在于复杂问句中包含多个关系,并不能转换为知识库上的简单三元组查询。我们沿用关系理解中的模式图思路,提出了基于复杂查询图的语义解析模型,以解决复杂问句的语义结构表示和语义匹配计算。据我们所知,我们的工作是首次通过神经网络模型学习查询图整体的连续语义表示,相对于已有工作,整体语义表示通过池化操作,聚合查询图中不同语义成分的特征,以捕捉其中的语义相近、互补等交互。与此同时,我们研究了提升问答效果的多种 不同的方法,主要包括候选查询图生成的时间、类型限制优化,引入依存语法信息捕捉与特定语义成分的局部匹配,以及利用集成方法扩充实体链接结果,提高候选查询图的召回率。我们在三个广泛使用的问答数据集上进行了测试,在全部由复杂问题组成的 ComplexQuestions 中,我们提出的模型取得了目前最好的效果,并且显著优于已有模型; 在主要由简单问题构成的 WebQuestions ,以及全部为简单问题的 SimpleQuetions 中,基于复杂查询图的模型依然拥有竞争力,领先于绝大部分已有模型,同时语义匹配模型具有轻量级、参数少等优势,证明了其有效性。
后续的研究主要包括了对更多种语义限制的挖掘,例如隐含时间限制,即问句中不出现具体的时间,而是以从句形式描述与该时间相关的事件。一些研究工作对问句进行从句提取的方式,先回答从句部分,再将时间答案代回主句进行第二次回答。为了减少对问句进行特殊处理的步骤,我们会研究如何将隐含时间限制的挖掘纳入现有的查询图框架中,进一步提升问答模型效果和适用性。
6.1 论文工作总结与主要贡献
自然语言理解是人工智能的重要分支。如何让机器理解人类语言的含义,是一系列任务的研究重点,尤其是对于问答系统、阅读理解、多轮对话等下游任务,它们都依赖于机器对语义的充分认知。伴随着互联网中海量结构化信息积累,知识库的诞生和相关技术的发展给自然语言理解提供了一种有效的解决方案,即以知识库中的实体、类型和谓词为载体,描述自然语言中的实体、实体间的关系,甚至蕴含多个关系的复杂句子。 在此背景下,本文对基于知识库的自然语言理解分为三个递进的层面,即实体理解、关系理解和问句理解。针对这三个层面理解问题,本文展开了一系列研究,并提出了具有针对性的语义匹配模型。
实体理解的目标,是将自然语言文本中表示实体的短语映射至知识库的对应实体,是一种直接匹配的过程。本文进行了中文到英文的跨语言场景中,对表格文本进行链接的研究。表格链接过程中,同行列的实体具有明显的相关性,这是传统实体链接任务所不具备的特性,也是链接模型的关注重点。而知识库和链接文本不在同一个语言中,使得模型无法利用任何字面上的相似信息,这给链接任务带来了更多挑战。本文是学术界首次研究跨语言的表格链接任务,本文提出了基于跨语言词向量和深度神经网络的链接模型,目标在于克服翻译步骤带来的错误传播,以及自动学习不同粒度的语义匹配特征。具体而言,本文提出的方法贡献如下:
1. 候选实体生成中,利用多种翻译工具进行过渡,并保留足量候选,将黑盒翻译工具出错的影响尽可能降低;
2. 训练跨语言词向量,使得中英文单词、实体的特征表示在连续语义空间中互通, 保证在不依赖字面相似特征和共现统计特征的情况下,实现高质量的链接;
3. 定义了三种语义匹配特征,即单个单元格到实体的指示特征,单元格行列信息到实体的上下文特征,及同列实体之间的一致性特征,通过神经网络对三类特征进行表示学习,并提出了逐位方差进行一致性特征计算的方式;
4. 模型遵循联合训练框架,以整张表格级别的匹配程度作为目标函数,并利用基于成对排序损失的 RankNet 进行训练,充分利用负样本表格生成产生的偏序关系;
5. 实验表明,本文提出的模型在跨语言表格链接任务中明显优于其它基线模型,同时模型对一致性特征的建模以及联合训练框架均带来实质性的帮助。
关系理解的目标,是将自然语言中的二元关系通过知识库中的谓词进行表示。相对于实体理解的直接匹配过程,关系理解较难做到二元关系和谓词的一一对应,一方面在 于关系的多义性,更重要原因在于知识库和自然语言之间存在语义间隔,使得一些语法简单的关系,在知识库中却对应复杂的语义。基于这两个不同的挑战,本文对二元关系进行了两种不同粒度的研究。
粗粒度的关系语义研究中,本文旨在分析关系在大跨度上的多义性,挖掘关系的主语和宾语所具有的不同类型搭配。本文提出了挖掘关系具有代表性类型搭配的方法,其思路在于尽可能使用具体的类型匹配更多的已知关系三元组,主要贡献列举如下:
1. 提出了一种主宾语联合进行实体链接的方式,利用关系名称和主宾语间谓词路径存在的关联特征,提升整体链接准确率;
2. 去除关系名称中不影响类型搭配的成分,并利用语法变换将相似语义关系归为一组,使长尾关系能够被有效利用;
3. 利用松弛类型包含构建更丰富的知识库类型层次关系,并可用于其它任务中;
4. 人工测评实验表明,本文提出的方法可以改善互信息模型对热门类型搭配的惩罚情况,同时推理出的代表性的类型搭配也具有不错的质量。
细粒度的关系语义研究中,本文旨在深入挖掘关系语义的精确表达,定义了具有树形结构的模式图,它是知识库中满足特定语义的子图的抽象表达,同时具有良好的可解释性。本文提出了基于复杂模式图的规则推导模型,由已知关系三元组出发,挖掘语义相近的候选模式图,并学习它们的概率分布,从而以结构匹配的形式描述关系语义,并运用于知识库补全任务中。本文提出的方法贡献如下:
1. 定义了具有 “路径 + 分支” 结构的模式图,它是对传统规则推导模型中,基于谓词路径形式的规则扩展,对复杂语义关系具有更强的表示能力;
2. 利用深度优先搜索采集不同的模式图,并通过优先队列实现搜索过程的高效剪枝,在获取和关系语义较为接近的模式图同时,维持不同模式图间的多样性;
3. 将二元关系语义表示为候选模式图上的概率分布,可以更好地应对关系的多义性,同时任何一个查询图自身都具有独立的描述能力,使人类易于理解;
4. 模式图概率通过生成模型学习,实现了宽泛和具体模式图之间的平衡;
5. 多个自然语言关系的模式图实例表明,基于模式图的结构有能力准确描述复杂关系语义,并且质量显著好于其它基于路径的规则推导模型;
6. 本文提出的模型能有效运用于知识库补全任务中,在主宾语预测和三元组分类两个子任务上,效果优于其它规则推导模型,以及新兴的知识库向量模型。
问句理解的目标,是学习问句和答案之间的推理匹配。本文关注于通过知识库回答客观事实类问题,由于单个问句可能包含未知答案和其它实体的多个关系,和语义仅对应单个谓词的问句相比,复杂问句的回答更具有挑战性,体现在如何对复杂问句进行语义描述,以及如何度量和问句的语义匹配程度。针对以上挑战,本文提出了面向复杂语义问句的问答模型。对于问句的语义表示,本文沿用关系理解中的模式图思路,由问句出发生成可解释性高的查询图,以表示答案实体与问句中多个相关实体、类型、时间等信息的关联。同时,模型通过神经网络训练问句与查询图的匹配程度,为复杂查询图整体学习连续空间中的特征表示,捕捉不同成分间的语义交互。具体贡献如下:
1. 沿用模式图思路,利用多阶段生成方式构建问句的候选查询图,并在前人基础上对类型语义限制和时间语义限制进行改进;
2. 提出了一个轻量级的神经网络模型,以计算问句和查询图的语义匹配程度,据我们所知,这是知识库问答研究中首次尝试学习复杂查询图整体的连续语义表示;
3. 对问句的表示学习引入依存语法路径,作为问句字面序列信息的补充,以体现问句与特定语义成分的关联;
4. 通过集成方法,对已有实体链接工具的结果进行扩充,在链接准确率不受较大影响的前提下,提升候选查询图的召回;
5. 本文提出的模型在复杂问题数据集上取得了最优的效果,在简单问题数据集上依然保持竞争力,更多对比实验显示,学习查询图整体的连续特征表示有助于提升问答系统的效果。
6.2 未来工作展望
由于时间关系,本文的工作中还存在一些没有得到解决的问题,列举如下:
1. 表格链接,以及关系三元组的实体链接中,都存在着无法链接到具体实体的短语。除了较容易识别的数字、时间以外,考虑到知识库并不完整,部分实体(尤其是人名)不存在于知识库中,此时模型需要识别出这样的短语,而不是强行链接。我们对表格链接的任务定义绕开了此问题,而对三元组的实体链接则忽略了这种情况,这是一个需要改进的方向。
2. 关系三元组的链接方式较为粗糙,采用了主谓宾各自匹配度连乘的方式,并没有使用模型训练各部分权重。4.1.2节提到的集成链接方案并不是最优的解决办法,未来将利用神经网络表示三元组各自成分的链接特征,从而提升这一步骤的准确率。
3. 知识库问答研究中,我们尝试使用注意力层[63]取代依存语法序列,让语义匹配模型自动学习和特定谓词最相关的问句短语,但实验显示注意力层对问答指标几乎没有改进。一个可能的解释是,输入的问句长度大多在10左右,而不是类似一段话的形式,因此注意力模型效果不明显。在今后的研究中,会在这个问题上继续调研。
此外,在未来的研究工作中,我们以问句理解为核心,关注以下两个主要研究问题。
关系理解和问句理解具有很高的相关性。给定问句中的二元关系,若已知其主宾语类型搭配,那么对于候选查询图而言,答案类型与类型搭配的查询图更有可能表示了正确的语义。类似地,二元关系所对应的模式图也可指引问句查询图的排序,提供额外的匹配特征。我们在过去的工作中,对主宾语类型搭配与自动问答的结合进行了一定的尝试,但效果提升有限,除了类型搭配本身出现偏差,将问句与特定二元关系的对应是另一个瓶颈。基于语法转换的方式进行映射过于确定,由于用户提问可能不具有严谨的语法,可能需要使用更加灵活的方式实现这一对应。在未来的研究中,我们将尝试由陈述句出发生成疑问句,并引入一定的非严谨语法形式,以此构建训练数据,学习更加准确 的问句到二元关系的映射。
在现有的问答模型中,候选结构的生成过程是一次性的,对于测试问句,必须先生成所有查询图,再从中挑选最匹配的结构。为了保证候选生成速度,搜索规模需要受限,例如主路径长度限制为2,对于某些特殊问句,则无法生成出正确的查询图。因此,一种可能的改进方式,是将查询结构的生成看做序列,通过使用序列到序列模型,以问句为输入,输出查询图的生成序列。Golub 等人[92]使用了这样的模型用于回答简单问句, 而 Jain [141]使用记忆网络模型在 WebQuestions 上取得了最佳的效果,其模型的多层设计暗含了谓词的多步跳转。对于复杂问句,虽结构复杂,但多阶段生成过程很容易转换成序列形式,如何将复杂语义结构与序列到序列模型结合,是未来的一个研究方向。
参考文献:
(文中提及的部分参考文献在01#02#03#)

—END—
了解更多信息请点击知识工场网站主页:http://kw.fudan.edu.cn/
合作意向、反馈建议请联系:
info.knowledgeworks@gmail.com
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




)

)



)
评测任务发布)







