本文转载自公众号:知识工场。
第一部分 概述
关系抽取简介
关系抽取是从自由文本中获取实体间所具有的语义关系。这种语义关系常以三元组 <E1,R,E2> 的形式表达,其中,E1 和E2 表示实体,R 表示实体间所具有的语义关系。如图1所示。关系抽取既是文本处理任务的基础,又是构建知识图谱的核心任务。抽取实例不仅能提升文本分析的层面,还可为诸如问答系统、聊天机器人及语义搜索等下游任务提供背景知识。
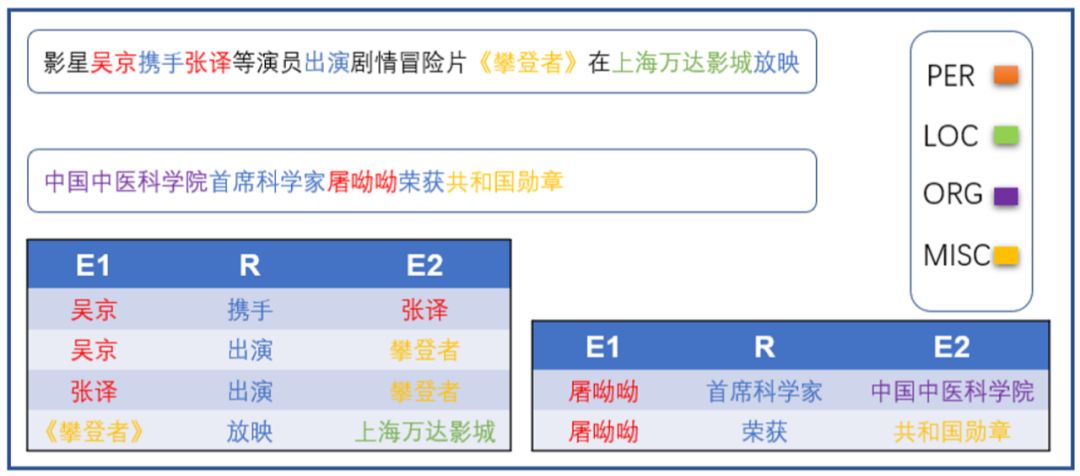
图1 关系抽取案例
关系抽取中的难点问题
1.同一关系可由不同的词语表达。
2.同一短语或词具有歧义性,不能很好的表征同一关系。
3.实体对间可能具有多种关系。
4.跨句多元关系不能很好解决。
5.隐含关系不能很好解决。
6.对nlp处理工具依赖较大。
关系抽取方法分类
关系抽取方法的概括图如图2所示,简述其中部分方法。

图2 关系抽取方法概括图
特定领域关系抽取是指从特定领域的语料中抽取实体间所具有的语义关系,这种语义关系通常是预定义的。基于模式的关系抽取方法通过人工设计或从文本中学到的语言模式与文本进行匹配,以抽取关系实例。该类方法需要依靠nlp处理工具包,如,首先通过分句对文本进行句子分割,然后利用pos对词语进行词性标注、ner识别句子中实体,最后构建基于字符、语法和语义的关系抽取模式。该方法的抽取精度高但泛化能力弱,适用于结构性的文本。基于机器学习的关系抽取方法克服了上述方法的弊端。依据标注数据,可分为监督的关系抽取、弱监督关系抽取及无监督关系抽取。有监督的关系抽取旨在从大规模标注语料中获取表达实体间语义关系的有效特征。主要方法有基于特征工程的关系抽取方法、基于核函数的方法及深度模型的方法。基于特征工程的关系抽取方法通过nlp工具包对语料执行分句、词性标注、依存分析等操作以获取有效特征。基于核函数的关系抽取方法通过构建结构树,计算关系距离以抽取关系实例,该方法缓解了特性稀疏性问题。虽然上述方法在关系抽取上取得了不错的性能,但扩展性较差。基于深度模型的方法克服了模型扩展性的问题,通过从标注语料中自动构建特征,并抽取关系实例。近年来,对该方法的研究层出不迭,该方法常规过程是通过词向量技术对词、字、位置进行向量化表示,或通过pre-trained embedding初始化向量表示。拼接向量以构成句子的表示。通过深度模型抽取词汇级别特征和句子级别特征,最终依据任务类型选用相应的输出函数以获取预测结果。迁移学习的思想是从相关领域迁移标注数据或知识已完成特定领域的任务。
远程监督简介
远程监督的基本假设:如果实体对间存在关系,则任何含有该实体对的句子都表达了该实体对间的关系。远程监督的假设过于绝对,会引入大量噪声。针对引入噪声这一问题,现有方法主要有:
利用先验知识约束数据集的构建;
利用关系图模型对样本打分,过滤信任分数较低的句子;
利用多实例对句子集打标签;
利用注意力机制对句子赋权;
远程监督虽能缓解数据标注问题,但对知识库的质量和覆盖率要求较大。
第二部分 论文介绍
首先举例说明什么是跨句多元关系。
“The deletionmutation on exon-19 of EGFR gene was present in 16 patients, while the L858E point mutation on exon-21was noted in 10. All patients were treated with gefitinib and showed a partial response.”.
上面的两个句子表达了这样一个事实,即三个实体之间存在着一个关系三元组,但这在任一单独的句子中都没有体现。此类现象在中文语料中也是屡见不鲜。
《DistantSupervision for Relation Extraction beyond the Sentence Boundary》- EACL 2017
该文章首次利用远程监督实现跨句关系抽取。文章的方法核心是一种图表示,它可以将依存关系和语篇关系结合,从而提供了一种统一的方法来模拟句子内部和句子之间的关系。在面对语言变异和分析错误时,该方法从多条路径中提取特征,提高了特征提取的准确性和鲁棒性。通过远程监督,该方法从大约100万篇PubMed Central 全文中抽取了大约64000个不同的实例,与原来的kb相比,达到了两个数量级的增长。
该文章既是开创性文章,无法与其他方法对比,又是一篇工程性文章。因此,作者阐述了工程中的主要难点及所抽取的结果。详细如下:
Distant Supervision:从知识库中选择具有明确关系的实体对作为正样本。并随机从知识库中选择不具有明确关系的实体对作为负样本。使正样本的数量与负样本的数量相同以保证训练集平衡。
Minimal-SpanCandidates:在跨句三元组抽取中,直接将具有明确关系的实体对划分到正训练样本中会产生很多噪声。针对这一问题,作者定义了共现实体对间最小跨距。作者通过实验证明,这种方式可提高抽取的准确率。
DocumentGraph:引入了一个document graph,其节点表示词,边表示依存关系、邻接关系和语篇关系等句内和句间关系。每个节点都用词本身、论点和词性标记。句间的边由斯坦福句法解析器赋予类别。同时,为了降低解析误差,通过在邻词间加边及多路径融合的方式缓解。
Features:通过在document graph中的路径上定义特征模板来泛化关系抽取的特征,这些特征模板包含各种类型的交错边(依赖关系、词和句子邻接、语篇关系)。
Multiplepaths:大多数以前的工作只研究了两个实体之间的单一最短路径。当作者使用词法和句法结构时,且解析器正确解析时,这种方法工作得很好。然而,真实的数据是相当嘈杂的。于是,作者采用多条可能路径解决误差并保持噪声的鲁棒性。
《Cross-Sentence N-ary Relation Extraction with Graph LSTMs》-ACL2017
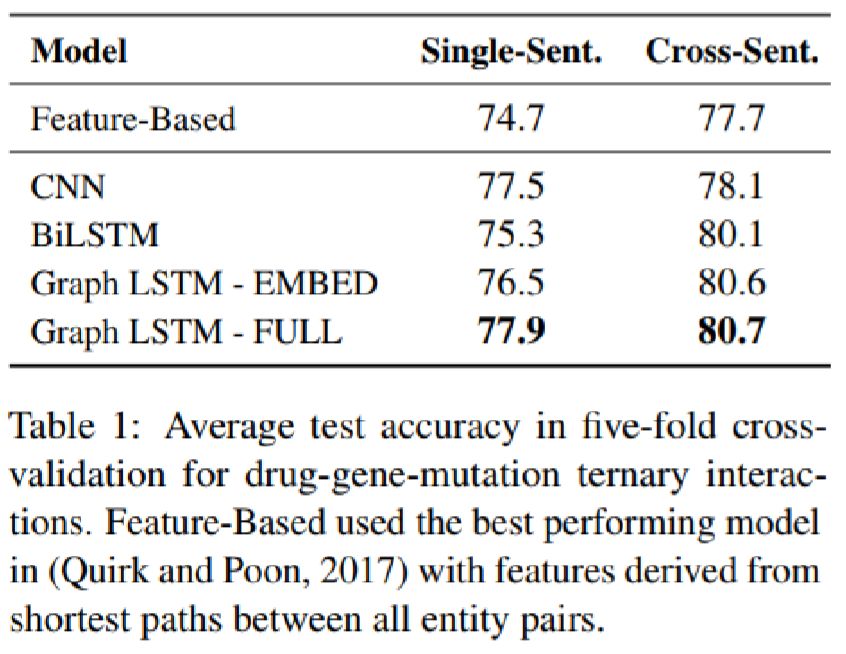
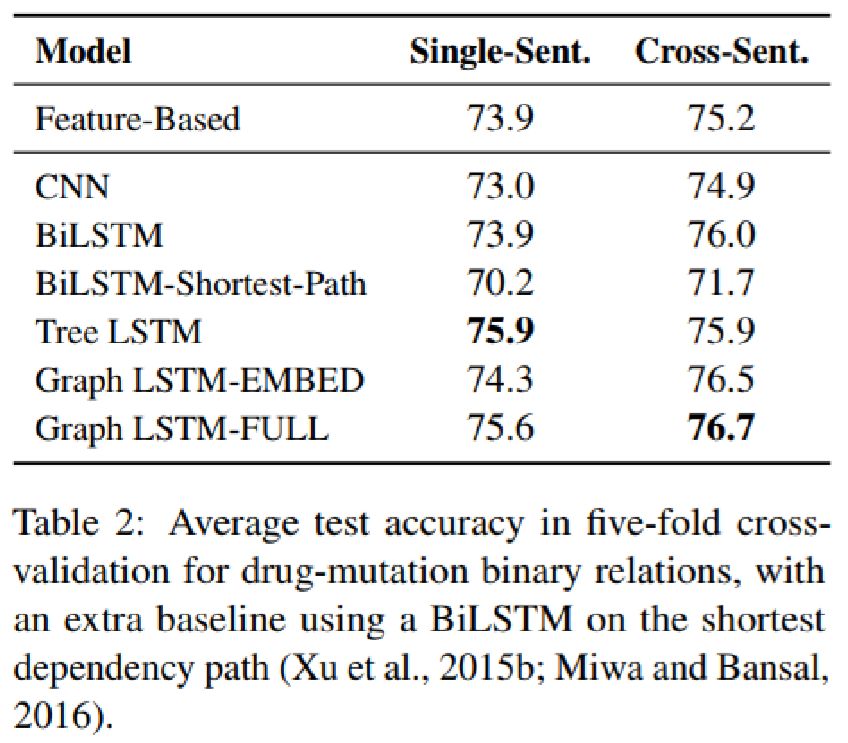
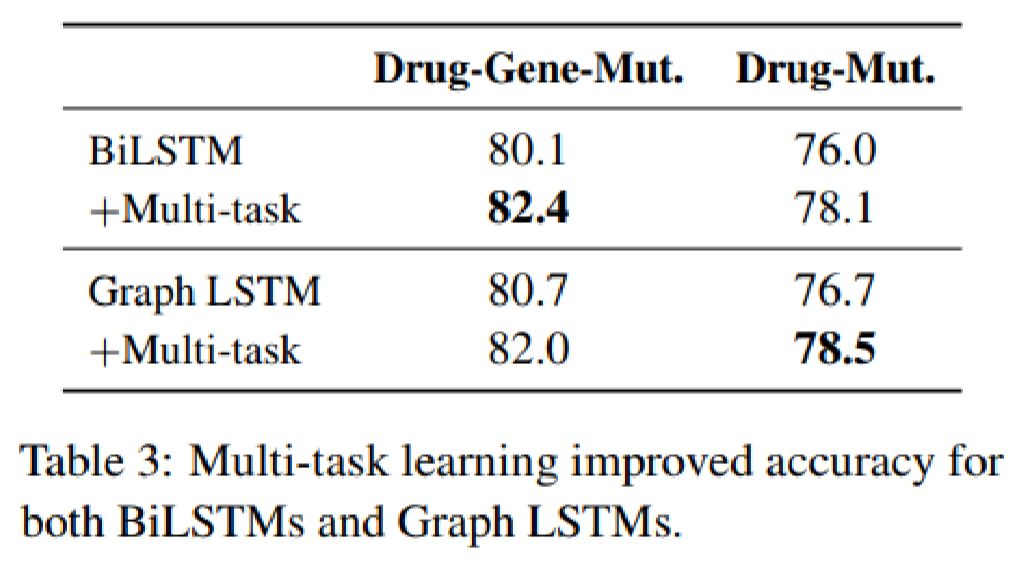
本文针对跨句n元关系抽取这一问题,提出了一种graph long short-term memory networks(graph LSTMs)的框架。图提供了一种探索不同形式LSTM的方法,并可集成句间和句内的各种依赖关系,如序列、句法和语篇关系。它可为实体学习了一个鲁棒的上下文表示,作为关系分类器的输入。它简化了对任意关系的处理,并使与关系相关的多任务学习成为可能.通过在两个重要的精确医学数据集上对该框架进行了评价,证明了该框架在传统监督学习和远程监督下的有效性。跨句抽取产生了更大的知识库。多任务学习显著提高了抽取精度。通过对各种LSTM方法的深入分析,可以发现语言分析对提取精度的影响。
跨句n元关系抽取架构如下图所示。输入层是输入文本的word embedding。Graph LSTM学习每个单词的上下文表示。将文中所提及及的实体与它们的上下文表示连接起来,并成为关系分类器的输入。对于多词实体,利用其词向量的平均值表示。该框架采用反向传播进行训练。文中并未提及分类器的选择。

Graph LSTM的核心是一个document graph,它捕捉输入单词之间的各种依赖关系。通过选择document graph中包含的依存项,Graph LSTMs很自然地过渡到线性链或tree lstms。接下来,简要介绍document graph和如何利用Graph LSTM执行多任务学习。
documentgraph是由表示词的节点和表示各种依存的边组成,如下图所示。如果它只包含邻词的边,则变成线性链表。类似地,其他以前的LSTM方法也可以通过约束边在最短依赖路径或解析树中来获取。

多任务学习可直接由Graph LSTM实现,唯一需要改变是为每个相关的辅助关系添加一个单独的分类器。所有的分类器共享相同的Graph LSTM表示的学习器和词嵌入,并可相互监督。
论文在数据集上评测结果如下:
《N-ary Relation Extraction using Graph State LSTM》-emnlp2018
跨句n元关系抽取是检测句间的n个实体之间的关系。典型的方法将输入描述为document graph,集成了句内和句间的不同依赖关系.目前最先进的方法是将输入图分成两个DAGs,每个都是DAG-structured lstm。尽管能够利用图的边对丰富的语言知识进行建模,但在拆分过程中可能会丢失重要的信息。本文提出了graph-state LSTM模型,它使用一个并行状态对每个字进行建模,通过消息传递递归地更新状态值。与DAGlstms相比,graph-state LSTM保留了原有的图结构,并允许更多的并行化,从而加快了计算速度。在一个标准benchmark,该模型取得了最佳效果。
任务定义
跨句多元关系抽取的输入可表示为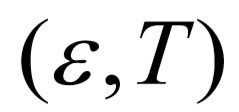 ,其中,
,其中, 表示实体指称集,
表示实体指称集,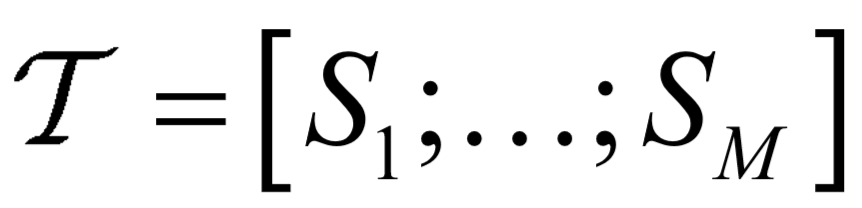 表示由多个句子组成的文本。每一个实体指称
表示由多个句子组成的文本。每一个实体指称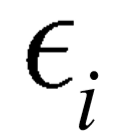 ,属于中的一个句子。预定义关系集
,属于中的一个句子。预定义关系集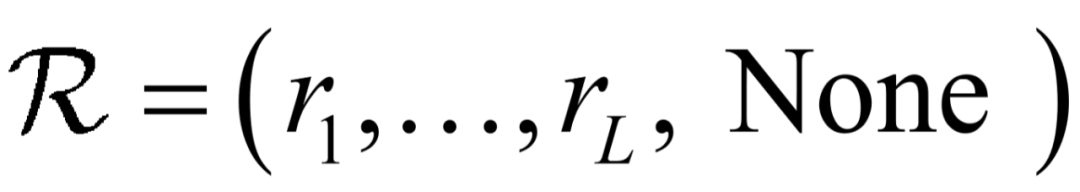 ,其中None表示实体间没有关系。该任务既可表述为确定
,其中None表示实体间没有关系。该任务既可表述为确定 是否共同构成关系的二分类问题,也可表述成用于检测实体对属于哪一种关系的多分类问题。
是否共同构成关系的二分类问题,也可表述成用于检测实体对属于哪一种关系的多分类问题。
Graph State LSTM
给定输入图G=(V,E),为每一个词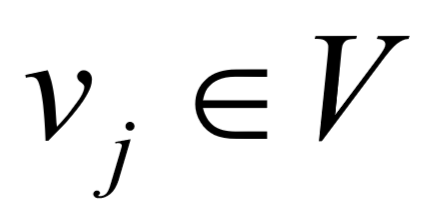 定义一个状态向量
定义一个状态向量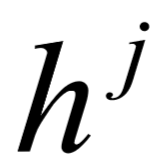 。图的状态是由所有词状态组成,可表示成:
。图的状态是由所有词状态组成,可表示成:
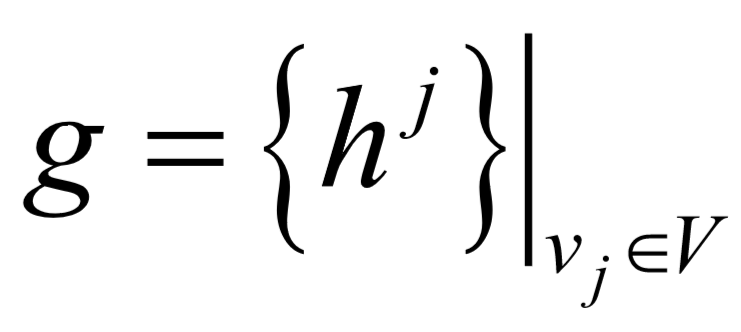
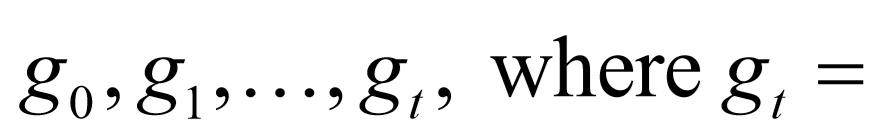
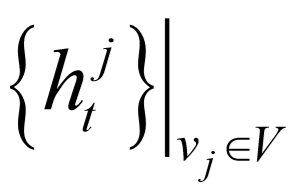 .初始图态
.初始图态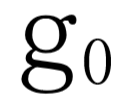 由初始词态
由初始词态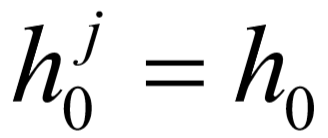 组成.
组成.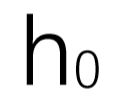 是一个零向量。
是一个零向量。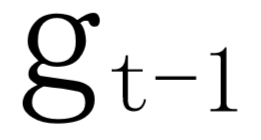 到
到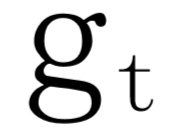 的转移过程。在每个步骤t,都允许词和直接连接到这个词的所有词之间进行信息交换。为避免梯度消失或爆炸,采用gate lstm单元,其中,
的转移过程。在每个步骤t,都允许词和直接连接到这个词的所有词之间进行信息交换。为避免梯度消失或爆炸,采用gate lstm单元,其中, 记录
记录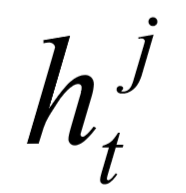 的存储。模型利用输入门
的存储。模型利用输入门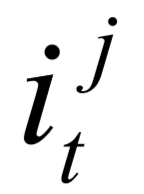 、输出门
、输出门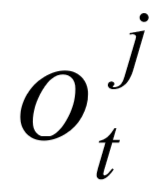 和遗忘门
和遗忘门 来控制输入到的信息流。
来控制输入到的信息流。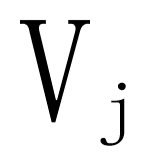 的输入通过输入方与输出方来区分,
的输入通过输入方与输出方来区分,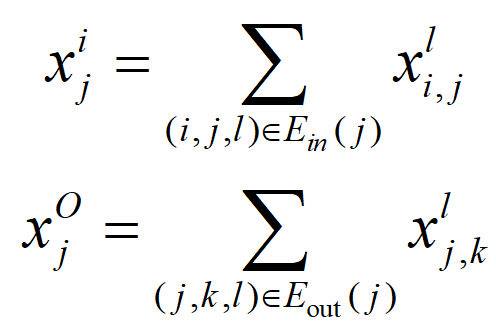
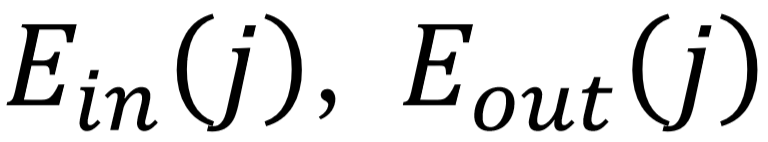 分别表示的输入边集合和输出边集合。
分别表示的输入边集合和输出边集合。除了边缘输入,cell还在状态转换期间接收其输入和输出词的隐藏状态。特别是,对所有输入词和输出词的状态分别进行了累加。
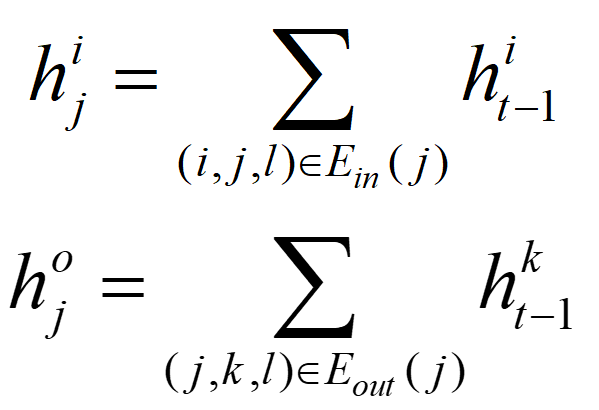
到的循环状态转移可由表示。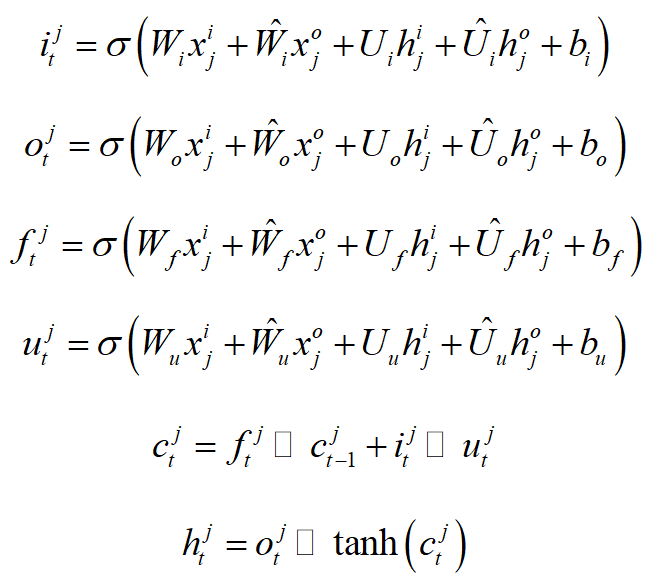
,,分别是输入、输出和遗忘门。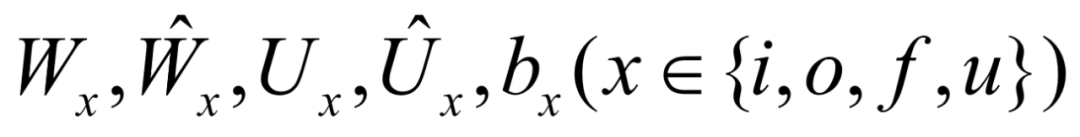 是模型参数。
是模型参数。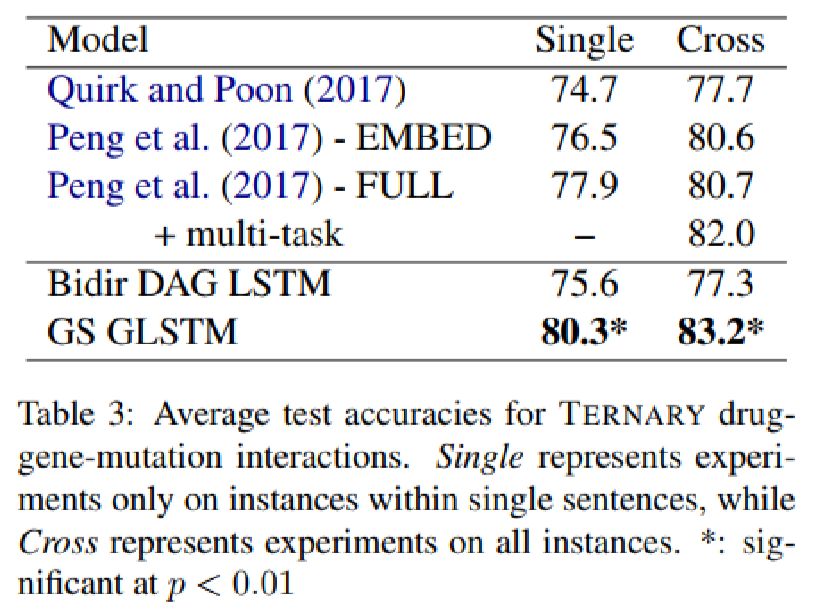
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。