python-dotenv解析env文件
最简单和最常见的用法是在应用程序启动时调用load_dotenv,从当前目录或其父目录中的.env文件或指定的路径加载环境变量,然后调用os.getenv提供的与环境相关的方法
.env 文件内容写法
ADMIN_HOST = https://uat-rm-gwaaa.cn
ADMIN_LOGIN_ROUTE = /api/rm/auth/admin/login
ADMIN_LOGIN_DATA = {"phone":"13922221111","password":"6d614954ed51"}
项目中使用
项目中的环境变量写到.env文件里,以k,v的方式读取作为环境变量
安装
pip install -U python-dotenv
基本用法
确保项目目录下 有 .env 文件
–.env
–.py
在***.py中调用
复制代码
from dotenv import load_dotenv, find_dotenv
from pathlib import Path
# 自动搜索.env文件
load_dotenv(verbose=True)
# 等价与上面写法
load_dotenv(find_dotenv(),verbose=True)
# 指定env文件
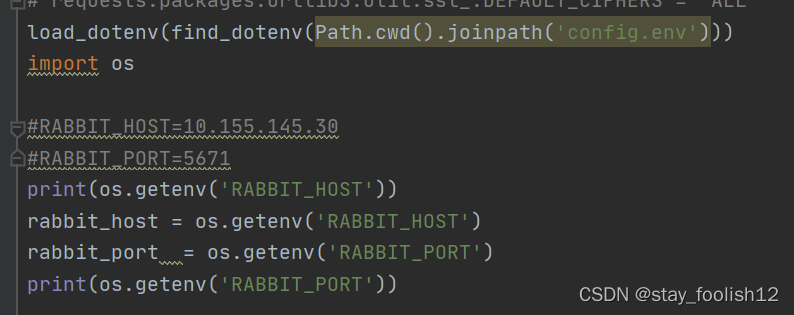
load_dotenv(find_dotenv(Path.cwd().joinpath('test.env')))
复制代码
通过load_dotenv ,就可以访问像访问系统环境变量一样使用.env文件中的变量了,比如通过 os.genenv(key, default=None)
import osprint(os.getenv('ADMIN_HOST'))
实践: