前言
《HDFS NameNode内存全景》中,我们从NameNode内部数据结构的视角,对它的内存全景及几个关键数据结构进行了简单解读,并结合实际场景介绍了NameNode可能遇到的问题,还有业界进行横向扩展方面的多种可借鉴解决方案。
事实上,对NameNode实施横向扩展前,会面临常驻内存随数据规模持续增长的情况,为此需要经历不断调整NameNode内存的堆空间大小的过程,期间会遇到几个问题:
- 当前内存空间预期能够支撑多长时间。
- 何时调整堆空间以应对数据规模增长。
- 增加多大堆空间。
另一方面NameNode堆空间又不能无止境增加,到达阈值后(与机型、JVM版本、GC策略等相关)同样会存在潜在问题:
- 重启时间变长。
- 潜在的FGC风险。
由此可见,对NameNode内存使用情况的细粒度掌控,可以为优化内存使用或调整内存大小提供更好的决策支持。
本文在前篇《HDFS NameNode内存全景》文章的基础上,针对前面的几个问题,进一步对NameNode核心数据结构的内存使用情况进行详细定量分析,并给出可供参考的内存预估模型。根据分析结果可有针对的优化集群存储资源使用模式,同时利用内存预估模型,可以提前对内存资源进行合理规划,为HDFS的发展提供数据参考依据。
内存分析
NetworkTopology
NameNode通过NetworkTopology维护整个集群的树状拓扑结构,当集群启动过程中,通过机架感知(通常都是外部脚本计算)逐渐建立起整个集群的机架拓扑结构,一般在NameNode的生命周期内不会发生大变化。拓扑结构的叶子节点DatanodeDescriptor是标识DataNode的关键结构,该类继承关系如图1所示。
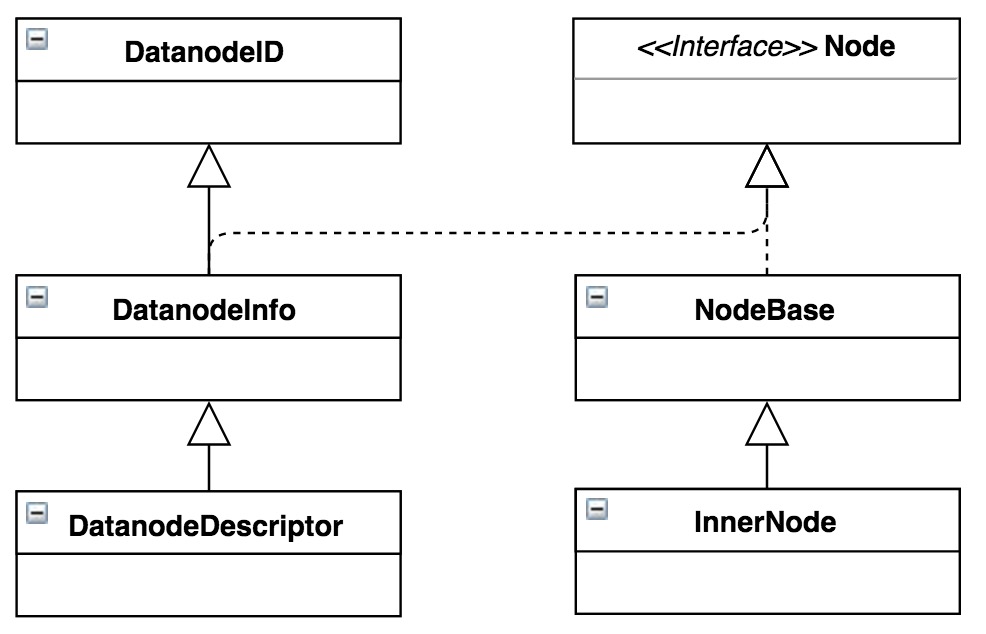
图1 DatanodeDescriptor继承关系
在64位JVM中,DatanodeDescriptor内存使用情况如图2所示(除特殊说明外,后续对其它数据结构的内存使用情况分析均基于64位JVM)。
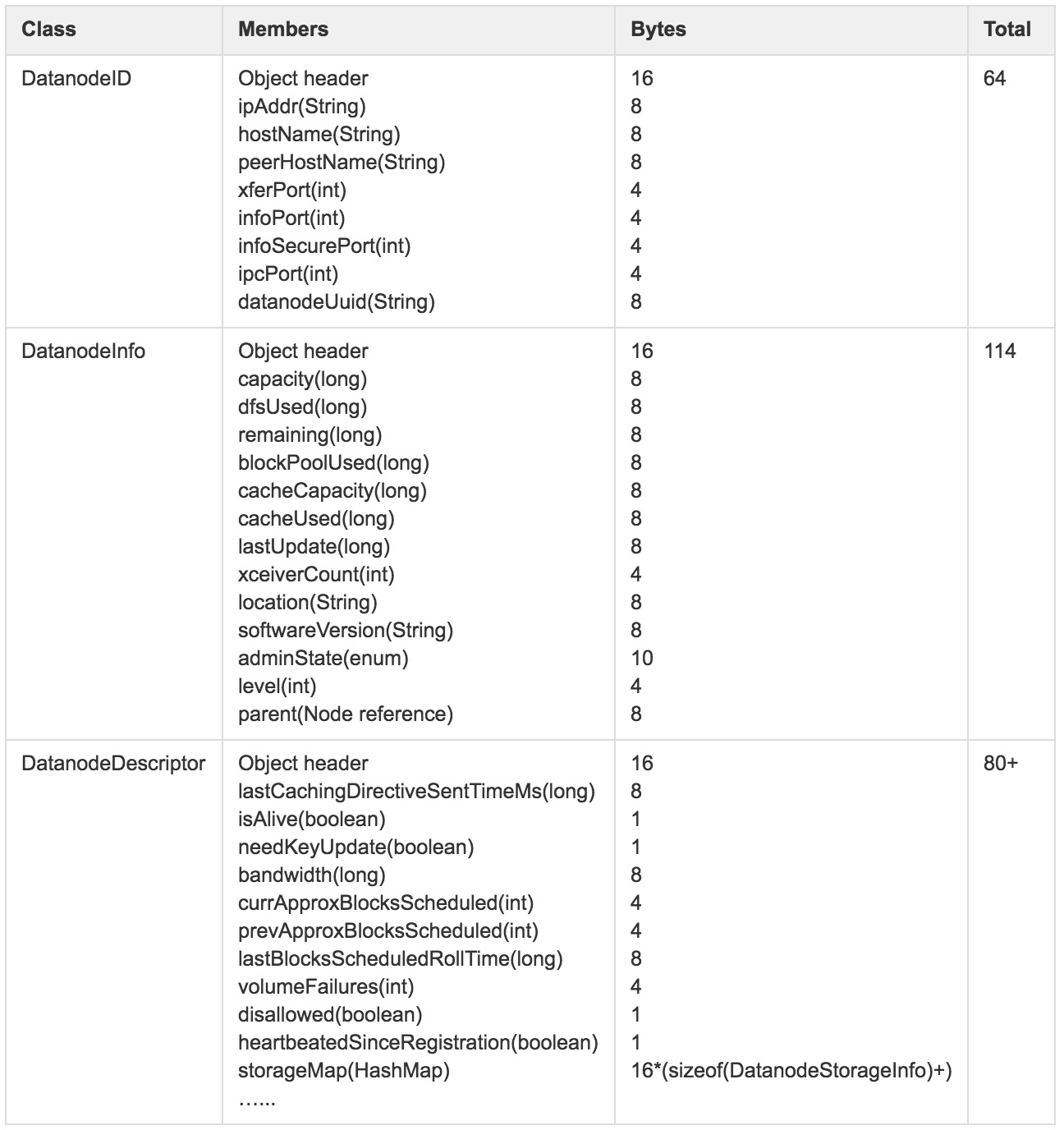
图2 DatanodeDescriptor内存使用详解
由于DataNode节点一般会挂载多块不同类型存储单元,如HDD、SSD等,图2中storageMap描述的正是存储介质DatanodeStorageInfo集合,其详细数据结构如图3所示。
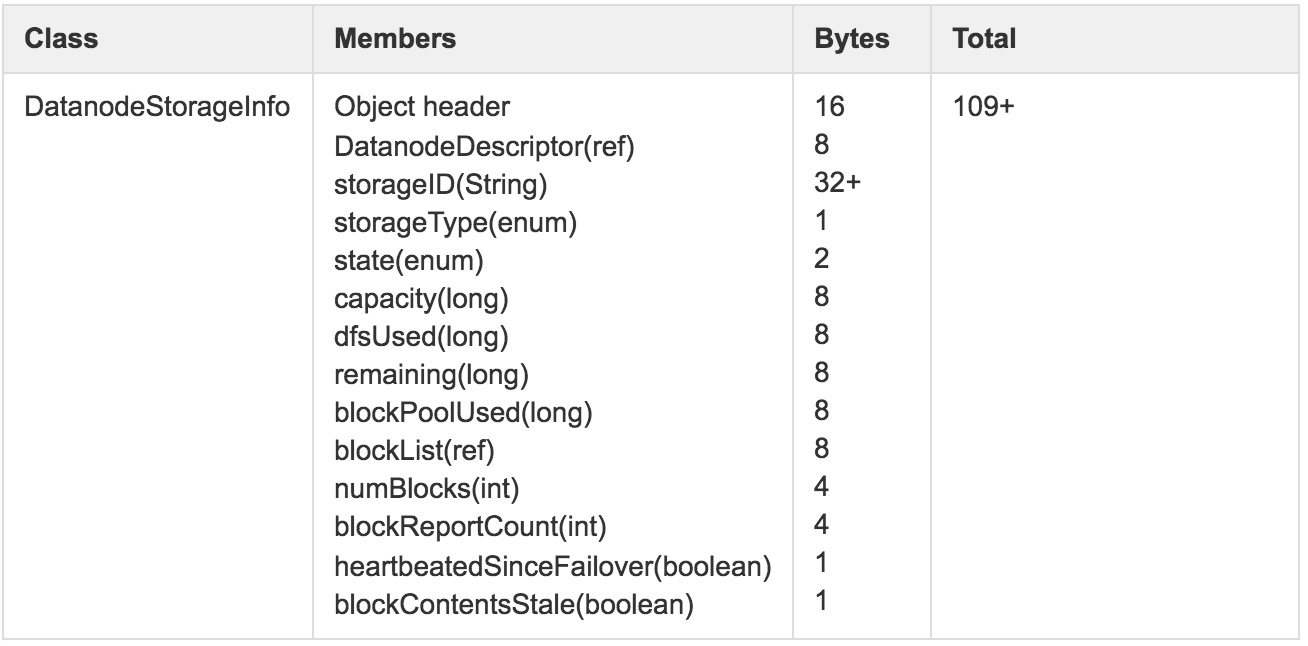
图3 DatanodeStorageInfo内存使用详解
除此之外,DatanodeDescriptor还包括一部分动态内存对象,如replicateBlocks、recoverBlocks和invalidateBlocks等与数据块动态调整相关的数据结构,pendingCached、cached和pendingUncached等与集中式缓存相关的数据结构。由于这些数据均属动态的形式临时存在,随时会发生变化,所以这里没有做进一步详细统计(结果存在少许误差)。
根据前面的分析,假设集群中包括2000个DataNode节点,NameNode维护这部分信息需要占用的内存总量:
(64 + 114 + 56 + 109 ∗ 16)∗ 2000 = ~4MB
在树状机架拓扑结构中,除了叶子节点DatanodeDescriptor外,还包括内部节点InnerNode描述集群拓扑结构中机架信息。

图4 NetworkTopology拓扑结构内部节点内存使用详解
对于这部分描述机架信息等节点信息,假设集群包括80个机架和2000个DataNode节点,NameNode维护拓扑结构中内部节点信息需要占用的内存总量:
(44 + 48) ∗ 80 + 8 ∗ 2000 = ~25KB
从上面的分析可以看到,为维护集群的拓扑结构NetworkTopology,当集群规模为2000时,需要的内存空间不超过5MB,按照接近线性增长趋势,即使集群规模接近10000,这部分内存空间~25MB,相比整个NameNode JVM的内存开销微乎其微。
NameSpace
与传统单机文件系统相似,HDFS对文件系统的目录结构也是按照树状结构维护,NameSpace保存的正是整个目录树及目录树上每个目录/文件节点的属性,包括:名称(name),编号(id),所属用户(user),所属组(group),权限(permission),修改时间(mtime),访问时间(atime),子目录/文件(children)等信息。
下图5为Namespace中INode的类图结构,从类图可以看出,文件INodeFile和目录INodeDirectory的继承关系。其中目录在内存中由INodeDirectory对象来表示,并用List children成员列表来描述该目录下的子目录或文件;文件在内存中则由INodeFile来表示,并用BlockInfo[] blocks数组表示该文件由哪些Blocks组成。其它属性由继承关系的各个相应子类成员变量标识。
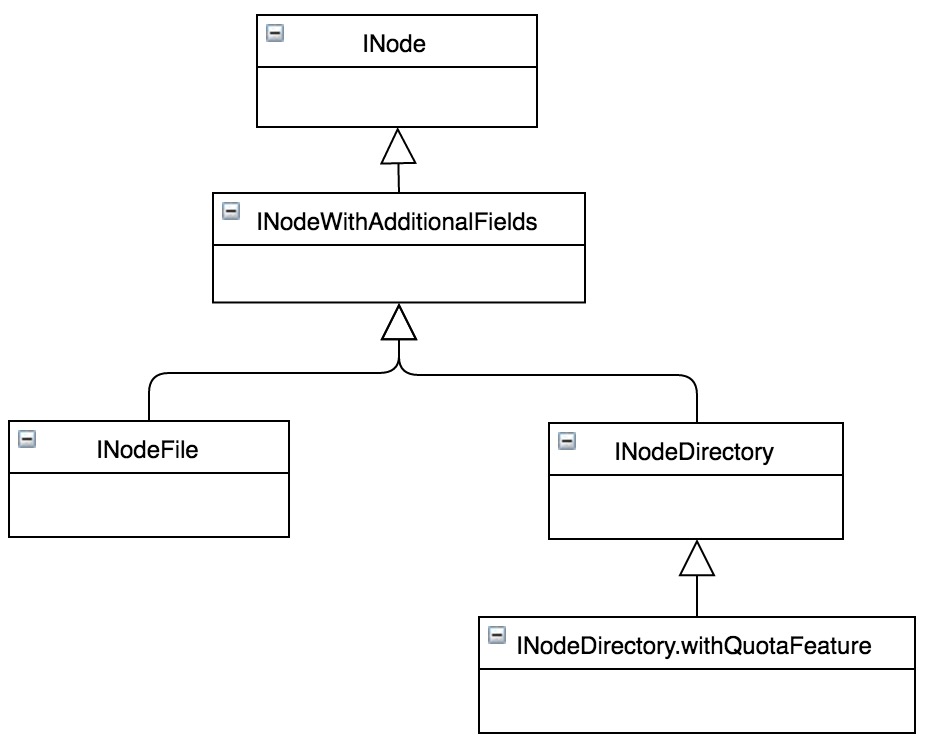
图5 文件和目录继承关系
目录和文件结构在继承关系中各属性的内存占用情况如图6所示。
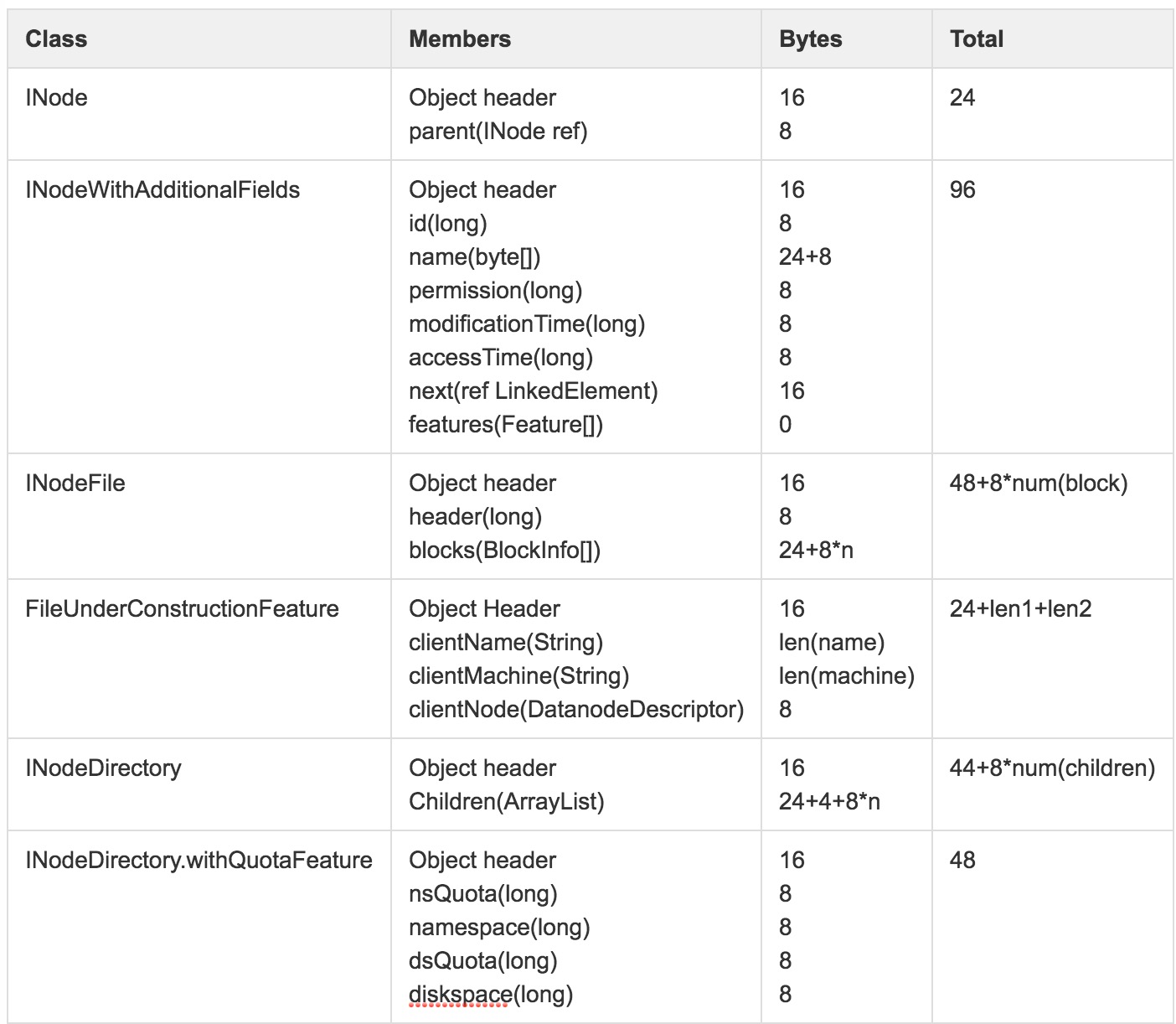
图6 目录和文件内存使用详解
除图中提到的属性信息外,一些附加如ACL等非通用属性,没有在统计范围内。在默认场景下,INodeFile和INodeDirectory.withQuotaFeature是相对通用和广泛使用到的两个结构。
根据前面的分析,假设HDFS目录和文件数分别为1亿,Block总量在1亿情况下,整个Namespace在JVM中内存使用情况:
Total(Directory) = (24 + 96 + 44 + 48) ∗ 100M + 8 ∗ num(total children) Total(Files) = (24 + 96 + 48) ∗ 100M + 8 ∗ num(total blocks) Total = (24 + 96 + 44 + 48) ∗ 100M + 8 ∗ num(total children) + (24 + 96 + 48) ∗ 100M + 8 ∗ num(total blocks) = ~38GB
关于预估方法的几点说明: 1. 对目录树结构中所有的Directory均按照默认INodeDirectory.withQuotaFeature结构进行估算,如果集群开启ACL/Snapshotd等特性,需增加这部分内存开销。 2. 对目录树结构中所有的File按照INodeFile进行估算。 3. 从整个目录树的父子关系上看,num(total children)就是目录节点数和文件节点数之和。 4. 部分数据结构中包括了字符串,按照均值长度为8进行预估,实际情况可能会稍大。
Namespace在JVM堆内存空间中常驻,在NameNode的整个生命周期一直在内存存在,同时为保证数据的可靠性,NameNode会定期对其进行Checkpoint,将Namespace物化到外部存储设备。随着数据规模的增加,文件数/目录树也会随之增加,整个Namespace所占用的JVM内存空间也会基本保持线性同步增加。
BlocksMap
HDFS将文件按照一定的大小切成多个Block,为了保证数据可靠性,每个Block对应多个副本,存储在不同DataNode上。NameNode除需要维护Block本身的信息外,还需要维护从Block到DataNode列表的对应关系,用于描述每一个Block副本实际存储的物理位置,BlockManager中BlocksMap结构即用于Block到DataNode列表的映射关系。BlocksMap内部数据结构如图7所示。
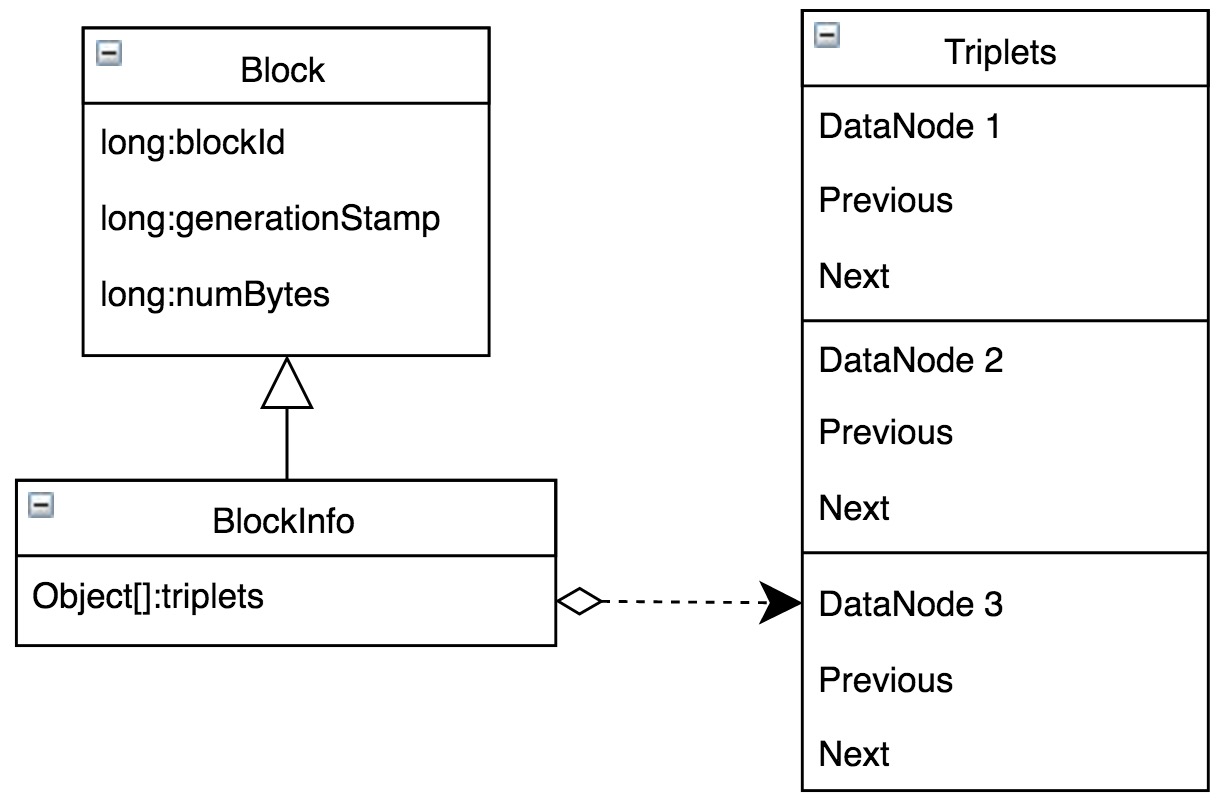
图7 BlockInfo继承关系
BlocksMap经过多次优化形成当前结构,最初版本直接使用HashMap解决从Block到BlockInfo的映射。由于在内存使用、碰撞冲突解决和性能等方面存在问题,之后使用重新实现的LightWeightGSet代替HashMap,该数据结构本质上也是利用链表解决碰撞冲突的HashTable,但是在易用性、内存占用和性能等方面表现更好。关于引入LightWeightGSet细节可参考HDFS-1114。
与HashMap相比,为了尽可能避免碰撞冲突,BlocksMap在初始化时直接分配整个JVM堆空间的2%作为LightWeightGSet的索引空间,当然2%不是绝对值,如果2%内存空间可承载的索引项超出了Integer.MAX_VALUE/8(注:Object.hashCode()结果是int,对于64位JVM的对象引用占用8Bytes)会将其自动调整到阈值上限。限定JVM堆空间的2%基本上来自经验值,假定对于64位JVM环境,如果提供64GB内存大小,索引项可超过1亿,如果Hash函数适当,基本可以避免碰撞冲突。
BlocksMap的核心功能是通过BlockID快速定位到具体的BlockInfo,关于BlockInfo详细的数据结构如图8所示。BlockInfo继承自Block,除了Block对象中BlockID,numbytes和timestamp信息外,最重要的是该Block物理存储所在的对应DataNode列表信息triplets。
图8 BlocksMap内存使用详解
其中LightWeightGSet对应的内存空间全局唯一。尽管经过LightWeightGSet优化内存占用,但是BlocksMap仍然占用了大量JVM内存空间,假设集群中共1亿Block,NameNode可用内存空间固定大小128GB,则BlocksMap占用内存情况:
16 + 24 + 2% ∗ 128GB +( 40 + 128 )∗ 100M = ~20GB
BlocksMap数据在NameNode整个生命周期内常驻内存,随着数据规模的增加,对应Block数会随之增多,BlocksMap所占用的JVM堆内存空间也会基本保持线性同步增加。
小结
NameNode内存数据结构非常丰富,除了前面详细分析的核心数据结构外,其实还包括如LeaseManager/SnapShotManager/CacheManager等管理的数据,由于内存使用非常有限,或特性未稳定没有开启,或没有通用性,这里都不再展开。
根据前述对NameNode内存的预估,对比Hadoop集群历史实际数据:文件目录总量~140M,数据块总量~160M,NameNode JVM配置72GB,预估内存使用情况:
Namespace:(24 + 96 + 44 + 48) ∗ 70M + 8 ∗ 140M + (24 + 96 + 48) ∗ 70M + 8 ∗ 160M = ~27GB BlocksMap:16 + 24 + 2% ∗ 72GB +( 40 + 128 )∗ 160M = ~26GB
说明:这里按照目录文件数占比1:1进行了简化,基本与实际情况吻合,且简化对内存预估结果影响非常小。
二者组合结果~53GB,结果与监控数据显示常驻内存~52GB基本相同,符合实际情况。
从前面讨论可以看出,整个NameNode堆内存中,占空间最大的两个结构为Namespace和BlocksMap,当数据规模增加后,巨大的内存占用势必会给JVM内存管理带来挑战,甚至可能制约NameNode服务能力边界。
针对Namespace和BlocksMap的空间占用规模,有两个优化方向:
- 合并小文件。使用Hive做数据生产时,为避免严重的数据倾斜、人为调小分区粒度等一些特殊原因,可能会在HDFS上写入大量小文件,会给NameNode带来潜在的影响。及时合并小文件,保持稳定的目录文件增长趋势,可有效避免NameNode内存抖动。
- 适当调整BlockSize。如前述,更少的Block数也可降低内存使用,不过BlockSize调整会间接影响到计算任务,需要进行适当的权衡。
对比其他Java服务,NameNode场景相对特殊,需要对JVM部分默认参数进行适当调整。比如Young/Old空间比例,为避免CMS GC降级到FGC影响服务可用性,适当调整触发CMS GC开始的阈值等等。关于JVM相关参数调整策略的细节建议参考官方使用文档。
这里,笔者根据实践提供几点NameNode内存相关的经验供参考:
- 根据元数据增长趋势,参考本文前述的内存空间占用预估方法,能够大体得到NameNode常驻内存大小,一般按照常驻内存占内存总量~60%调整JVM内存大小可基本满足需求。
- 为避免GC出现降级的问题,可将CMSInitiatingOccupancyFraction调整到~70。
- NameNode重启过程中,尤其是DataNode进行BlockReport过程中,会创建大量临时对象,为避免其晋升到Old区导致频繁GC甚至诱发FGC,可适当调大Young区(-XX:NewRatio)到10~15。
据了解,针对NameNode的使用场景,使用CMS内存回收策略,将HotSpot JVM内存空间调整到180GB,可提供稳定服务。继续上调有可能对JVM内存管理能力带来挑战,尤其是内存回收方面,一旦发生FGC对应用是致命的。这里提到180GB大小并不是绝对值,能否在此基础上继续调大且能够稳定服务不在本文的讨论范围。结合前述的预估方法,当可用JVM内存达180GB时,可管理元数据总量达~700M,基本能够满足中小规模以下集群需求。
总结
本文在《HDFS NameNode内存全景》基础上,对NameNode内存使用占比较高的几个核心数据结构进行了详细的介绍。在此基础上,提供了可供参考的NameNode内存数据空间占用预估模型:
Total = 198 ∗ num(Directory + Files) + 176 ∗ num(blocks) + 2% ∗ size(JVM Memory Size)
通过对NameNode内存使用情况的定量分析,可为HDFS优化和发展规划提供可借鉴的数据参考依据。
参考文献
[1] Apache Hadoop. https://hadoop.apache.org/. 2016. [2] Apache Issues. https://issues.apache.org/. 2016. [3] Apache Hadoop Source Code. https://github.com/apache/hadoop/tree/branch-2.4.1/. 2014. [4] HDFS NameNode内存全景. http://tech.meituan.com/namenode.html. 2016. [5] Java HotSpot VM Options. http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html.