逻辑回归(Logistic Regression)是机器学习中的一种分类模型,由于算法的简单和高效,在实际中应用非常广泛。本文作为美团机器学习InAction系列中的一篇,主要关注逻辑回归算法的数学模型和参数求解方法,最后也会简单讨论下逻辑回归和贝叶斯分类的关系,以及在多分类问题上的推广。
逻辑回归
问题
实际工作中,我们可能会遇到如下问题:
- 预测一个用户是否点击特定的商品
- 判断用户的性别
- 预测用户是否会购买给定的品类
- 判断一条评论是正面的还是负面的
这些都可以看做是分类问题,更准确地,都可以看做是二分类问题。同时,这些问题本身对美团也有很重要的价值,能够帮助我们更好的了解我们的用户,服务我们的用户。要解决这些问题,通常会用到一些已有的分类算法,比如逻辑回归,或者支持向量机。它们都属于有监督的学习,因此在使用这些算法之前,必须要先收集一批标注好的数据作为训练集。有些标注可以从log中拿到(用户的点击,购买),有些可以从用户填写的信息中获得(性别),也有一些可能需要人工标注(评论情感极性)。另一方面,知道了一个用户或者一条评论的标签后,我们还需要知道用什么样的特征去描述我们的数据,对用户来说,可以从用户的浏览记录和购买记录中获取相应的统计特征,而对于评论来说,最直接的则是文本特征。这样拿到数据的特征和标签后,就得到一组训练数据:
$$D = {(x^1, y^1), (x^2, y^2) … (x^N, y^N)}$$
其中 \(x^i\) 是一个 \(m\) 维的向量,\(x^i = [x_1^i, x_2^i, … , x_m^i]\) ,\(y\) 在 {0, 1} 中取值。(本文用{1,0}表示正例和负例,后文沿用此定义。)
我们的问题可以简化为,如何找到这样一个决策函数\(y^* = f(x)\),它在未知数据集上能有足够好的表现。至于如何衡量一个二分类模型的好坏,我们可以用分类错误率这样的指标:\(Err = \frac{1}{N} \sum 1[y^* = y]\) 。也可以用准确率,召回率,AUC等指标来衡量。
值得一提的是,模型效果往往和所用特征密切相关。特征工程在任何一个实用的机器学习系统中都是必不可少的,机器学习InAction系列已有一篇文章中对此做了详细的介绍,本文不再详细展开。
模型
sigmoid 函数
在介绍逻辑回归模型之前,我们先引入sigmoid函数,其数学形式是:
$$g(x) = \frac{1}{1 + e ^ {-x}}$$
对应的函数曲线如下图所示:
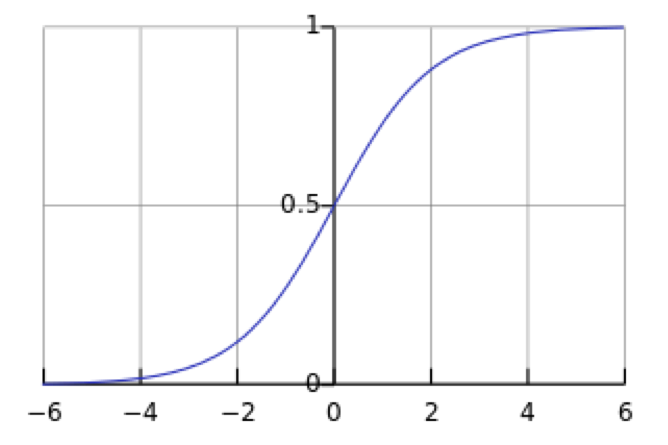
从上图可以看到sigmoid函数是一个s形的曲线,它的取值在[0, 1]之间,在远离0的地方函数的值会很快接近0/1。这个性质使我们能够以概率的方式来解释(后边延伸部分会简单讨论为什么用该函数做概率建模是合理的)。
决策函数
一个机器学习的模型,实际上是把决策函数限定在某一组条件下,这组限定条件就决定了模型的假设空间。当然,我们还希望这组限定条件简单而合理。而逻辑回归模型所做的假设是:
$$P(y=1|x;\theta) = g(\theta^T x) = \frac{1}{1 + e ^ {-\theta^T * x}}$$
这里的 \(g(h)\) 是上边提到的 sigmoid 函数,相应的决策函数为:
$$y^* = 1, \, \textrm{if} \, P(y=1|x) > 0.5$$
选择0.5作为阈值是一个一般的做法,实际应用时特定的情况可以选择不同阈值,如果对正例的判别准确性要求高,可以选择阈值大一些,对正例的召回要求高,则可以选择阈值小一些。
参数求解
模型的数学形式确定后,剩下就是如何去求解模型中的参数。统计学中常用的一种方法是最大似然估计,即找到一组参数,使得在这组参数下,我们的数据的似然度(概率)越大。在逻辑回归模型中,似然度可表示为:
$$L(\theta) = P(D|\theta) = \prod P(y|x;\theta) = \prod g(\theta^T x) ^ y (1-g(\theta^T x))^{1-y}$$
取对数可以得到对数似然度:
$$l(\theta) = \sum {y\log{g(\theta^T x)} + (1-y)\log{(1-g(\theta^T x))}}$$
另一方面,在机器学习领域,我们更经常遇到的是损失函数的概念,其衡量的是模型预测错误的程度。常用的损失函数有0-1损失,log损失,hinge损失等。其中log损失在单个数据点上的定义为\(-y\log{p(y|x)}-(1-y)\log{1-p(y|x)}\)
如果取整个数据集上的平均log损失,我们可以得到
$$J(\theta) = -\frac{1}{N} l(\theta)$$
即在逻辑回归模型中,我们最大化似然函数和最小化log损失函数实际上是等价的。对于该优化问题,存在多种求解方法,这里以梯度下降的为例说明。梯度下降(Gradient Descent)又叫作最速梯度下降,是一种迭代求解的方法,通过在每一步选取使目标函数变化最快的一个方向调整参数的值来逼近最优值。基本步骤如下:
- 选择下降方向(梯度方向,\(\nabla {J(\theta)}\))
- 选择步长,更新参数 \(\theta^i = \theta^{i-1} - \alpha^i \nabla {J(\theta^{i-1})}\)
- 重复以上两步直到满足终止条件
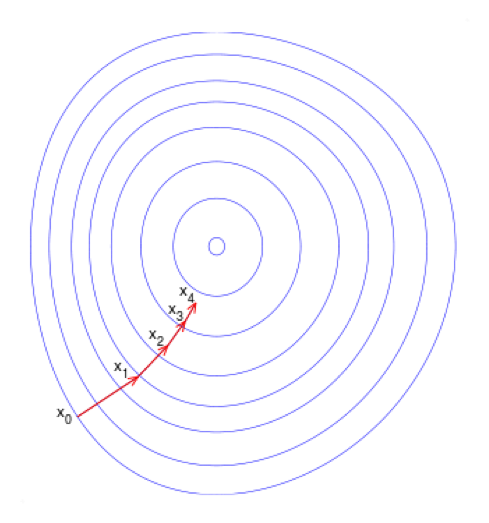
其中损失函数的梯度计算方法为:
$$ \frac{\partial{J}}{\partial{\theta}} = -\frac{1}{n}\sum_i (y_i - y_i^*)x_i + \lambda \theta$$
沿梯度负方向选择一个较小的步长可以保证损失函数是减小的,另一方面,逻辑回归的损失函数是凸函数(加入正则项后是严格凸函数),可以保证我们找到的局部最优值同时是全局最优。此外,常用的凸优化的方法都可以用于求解该问题。例如共轭梯度下降,牛顿法,LBFGS等。
分类边界
知道如何求解参数后,我们来看一下模型得到的最后结果是什么样的。很容易可以从sigmoid函数看出,当\(\theta^T x > 0 \) 时,\(y = 1\),否则 \(y = 0\)。\(\theta^T x = 0 \) 是模型隐含的分类平面(在高维空间中,我们说是超平面)。所以说逻辑回归本质上是一个线性模型,但是,这不意味着只有线性可分的数据能通过LR求解,实际上,我们可以通过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。下面两个图的对比说明了线性分类曲线和非线性分类曲线(通过特征映射)。
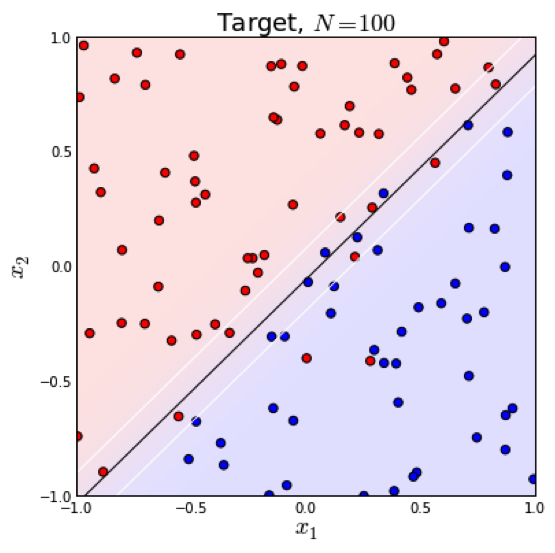
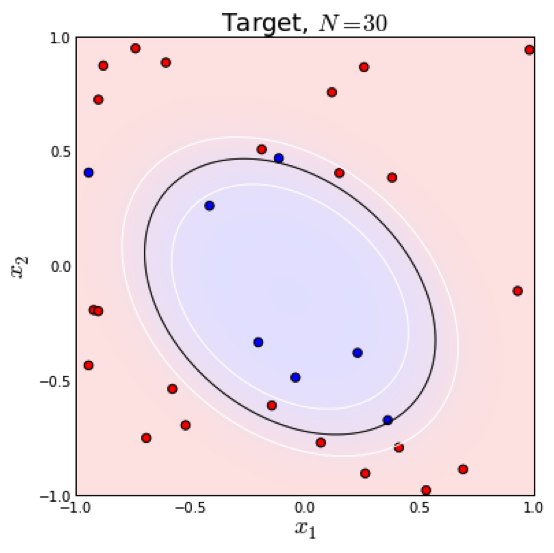
左图是一个线性可分的数据集,右图在原始空间中线性不可分,但是在特征转换 \([x_1, x_2] => [x_1, x_2, x_1^2, x_2^2, x_1x_2]\) 后的空间是线性可分的,对应的原始空间中分类边界为一条类椭圆曲线。
正则化
当模型的参数过多时,很容易遇到过拟合的问题。这时就需要有一种方法来控制模型的复杂度,典型的做法在优化目标中加入正则项,通过惩罚过大的参数来防止过拟合:
$$J(\theta) = -\frac{1}{N}\sum {y\log{g(\theta^T x)} + (1-y)\log{(1-g(\theta^T x))}} + \lambda \Vert w \Vert_p$$
一般情况下,取\(p=1\)或\(p=2\),分别对应L1,L2正则化,两者的区别可以从下图中看出来,L1正则化(左图)倾向于使参数变为0,因此能产生稀疏解。


实际应用时,由于我们数据的维度可能非常高,L1正则化因为能产生稀疏解,使用的更为广泛一些。
延伸
生成模型和判别模型
逻辑回归是一种判别模型,表现为直接对条件概率P(y|x)建模,而不关心背后的数据分布P(x,y)。而高斯贝叶斯模型(Gaussian Naive Bayes)是一种生成模型,先对数据的联合分布建模,再通过贝叶斯公式来计算样本属于各个类别的后验概率,即:
$$p(y|x) = \frac{P(x|y)P(y)}{\sum{P(x|y)P(y)}}$$
通常假设P(x|y)是高斯分布,P(y)是多项式分布,相应的参数都可以通过最大似然估计得到。如果我们考虑二分类问题,通过简单的变化可以得到:
$$ \log\frac{P(y=1|x)}{P(y=0|x)} = \log\frac{P(x|y=1)}{P(x|y=0)} + \log\frac{P(y=1)}{P(y=0)}
= -\frac{(x-\mu_1)^2}{2\sigma_1^2} + \frac{(x-\mu_0)^2}{2\sigma_0^2}\ + \theta_0 $$
如果 \( \sigma_1 = \sigma_0 \),二次项会抵消,我们得到一个简单的线性关系:
$$\log\frac{P(y=1|x)}{P(y=0|x)} = \theta^T x$$
由上式进一步可以得到:
$$P(y=1|x) = \frac{e^{\theta^T x}}{1+e^{\theta^T x}} = \frac{1}{1+e^{-\theta^T x}} $$
可以看到,这个概率和逻辑回归中的形式是一样的。这种情况下GNB 和 LR 会学习到同一个模型。实际上,在更一般的假设(P(x|y)的分布属于指数分布族)下,我们都可以得到类似的结论。
多分类(softmax)
如果\(y\)不是在[0,1]中取值,而是在\(K\)个类别中取值,这时问题就变为一个多分类问题。有两种方式可以出处理该类问题:一种是我们对每个类别训练一个二元分类器(One-vs-all),当\(K\)个类别不是互斥的时候,比如用户会购买哪种品类,这种方法是合适的。如果\(K\)个类别是互斥的,即 \(y = i\) 的时候意味着 \(y\) 不能取其他的值,比如用户的年龄段,这种情况下 Softmax 回归更合适一些。Softmax 回归是直接对逻辑回归在多分类的推广,相应的模型也可以叫做多元逻辑回归(Multinomial Logistic Regression)。模型通过 softmax 函数来对概率建模,具体形式如下:
$$ P(y=i|x, \theta) = \frac{e^{\theta_i^T x}}{\sum_j^K{e^{\theta_j^T x}}} $$
而决策函数为:\(y^* = \textrm{argmax}_i P(y=i|x,\theta)\)
对应的损失函数为:
$$J(\theta) = -\frac{1}{N} \sum_i^N \sum_j^K {1[y_i=j] \log{\frac{e^{\theta_i^T x}}{\sum {e^{\theta_k^T x}}}}}$$
类似的,我们也可以通过梯度下降或其他高阶方法来求解该问题,这里不再赘述。
应用
本文开始部分提到了几个在实际中遇到的问题,这里以预测用户对品类的购买偏好为例,介绍一下美团是如何用逻辑回归解决工作中问题的。该问题可以转换为预测用户在未来某个时间段是否会购买某个品类,如果把会购买标记为1,不会购买标记为0,就转换为一个二分类问题。我们用到的特征包括用户在美团的浏览,购买等历史信息,见下表
| 类别 | 特征 |
|---|---|
| 用户 | 购买频次,浏览频次,时间,地理位置 … |
| 品类 | 销量,购买用户,浏览用户 … |
| 交叉 | 购买频次,浏览频次,购买间隔 … |
其中提取的特征的时间跨度为30天,标签为2天。生成的训练数据大约在7000万量级(美团一个月有过行为的用户),我们人工把相似的小品类聚合起来,最后有18个较为典型的品类集合。如果用户在给定的时间内购买某一品类集合,就作为正例。哟了训练数据后,使用Spark版的LR算法对每个品类训练一个二分类模型,迭代次数设为100次的话模型训练需要40分钟左右,平均每个模型2分钟,测试集上的AUC也大多在0.8以上。训练好的模型会保存下来,用于预测在各个品类上的购买概率。预测的结果则会用于推荐等场景。
由于不同品类之间正负例分布不同,有些品类正负例分布很不均衡,我们还尝试了不同的采样方法,最终目标是提高下单率等线上指标。经过一些参数调优,品类偏好特征为推荐和排序带来了超过1%的下单率提升。
此外,由于LR模型的简单高效,易于实现,可以为后续模型优化提供一个不错的baseline,我们在排序等服务中也使用了LR模型。
总结
逻辑回归的数学模型和求解都相对比较简洁,实现相对简单。通过对特征做离散化和其他映射,逻辑回归也可以处理非线性问题,是一个非常强大的分类器。因此在实际应用中,当我们能够拿到许多低层次的特征时,可以考虑使用逻辑回归来解决我们的问题。
参考资料
- Trevor Hastie et al. The elements of statistical learning
- Andrew Ng, CS 229 lecture notes
- C.M. Bishop, Pattern recognition and machine learning
- Andrew Ng et al. On discriminative vs. generative classifiers:a comparison of logistic regression and naïve bayes
- Wikipedia, http://en.wikipedia.org/wiki/Logistic_regression