转载公众号 | 老刘说NLP
C端是知识图谱应用的一个重要领域,这个领域有大量的用户行为数据,存在着包括搜索、推荐、广告投放等业务。
当前,主流的互联网公司,如美团、阿里、腾讯都在尝试相关落地,在此当中,概念图谱的建设和应用受到关注。
概念图谱可以用于特征的补充,实体的召回等数据增强等实际工作当中。
本文主要从工业界的角度,对已有开放的大厂工作进行汇总、介绍,并对C端场景的概念图谱构成、构建与应用进行总结。
最近也在做这个方面的工作,写出来,与大家一起思考,对于进一步的扩展阅读,大家可以从延伸阅读的链接中查询。
一、美团常识性概念图谱
《常识性概念图谱建设以及在美团场景中的应用》 一文中提出了常识性概念图谱,常识性概念图谱就是建立概念与概念之间的关系,帮助自然语言文本的理解。特别的,常识性概念图谱侧重美团场景,帮助提升美团场景中的搜索、推荐、Feeds流等的效果。
1、图谱构成
常识性概念图谱涵盖“是什么”的概念Taxonomy体系结构,“什么样”的概念属性关系,“给什么”的概念承接关系。
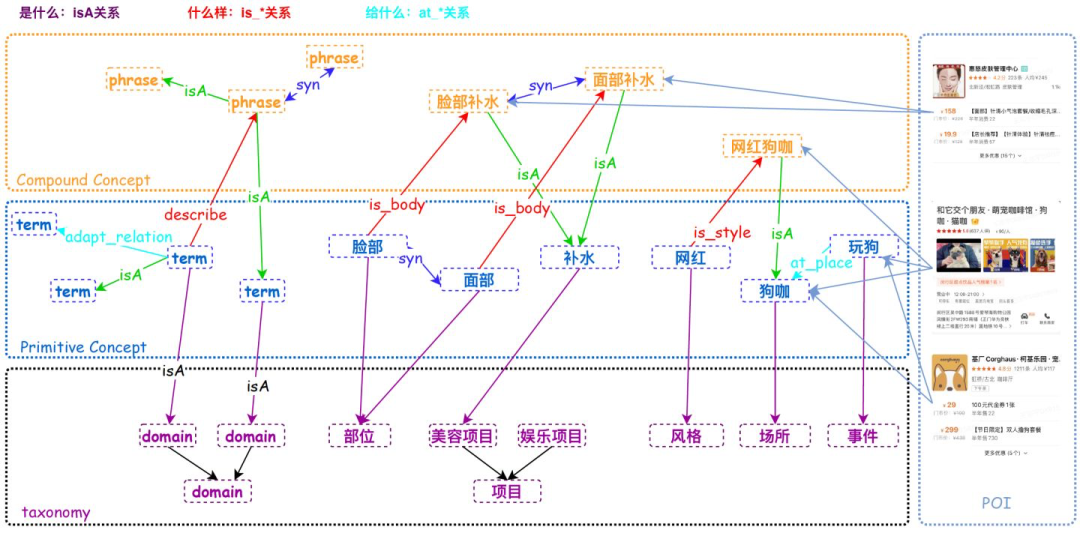
同时POI(Point of Interesting)、SPU(Standard Product Unit)、团单作为美团场景中的实例,需要和图谱中的概念建立连接。
从构成上看,该图谱包括Taxonomy节点、原子概念节点、复合概念节点、同义/上下位关系、概念属性关系、概念承接关系、POI/SPU-概念关系等信息。
2、图谱构建
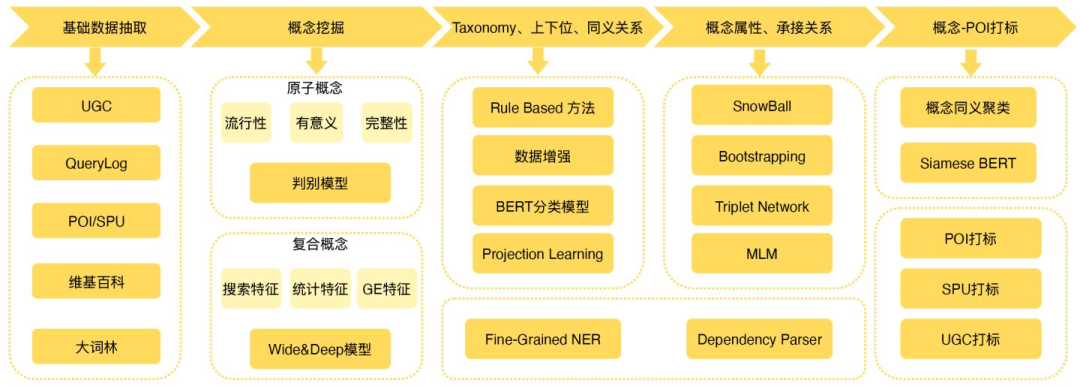
如下图所示,在构建流程上,该图谱包括基础数据抽取,从UGC,用户搜索日志中展开,并进行概念挖掘,包括原子概念、复合概念,随后进行上下文,同义关系抽取等一系列流程。
3、图谱应用
基于美团的业务,常识性概念图谱可以支持以下场景。
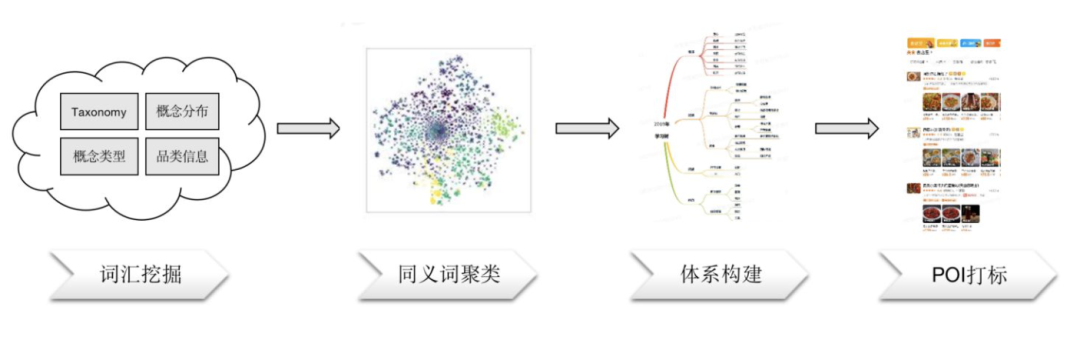
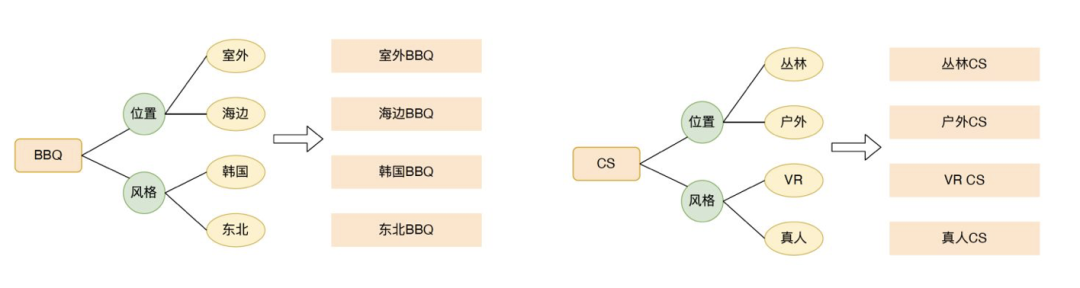
1、到综品类词图谱建设。 借助常识性图谱,补充欠缺的品类词数据,构建合理的品类词图谱,帮助通过搜索改写,POI打标等方式提升搜索召回。目前在教育领域,图谱规模从起初的1000+节点扩展到2000+,同时同义词从千级别扩展到2万+,取得了不错的效果。
2、点评搜索引导。 点评搜索SUG推荐,在引导用户认知的同时帮助减少用户完成搜索的时间,提升搜索效率。所以在SUG推荐上需要聚焦两个方面的目标:帮助丰富用户的认知,从对点评的POI、类目搜索增加自然文本搜索的认知;精细化用户搜索需求,当用户在搜索一些比较泛的品类词时,帮助细化用户的搜索需求。
在常识性概念图谱中,建立了很丰富的概念以及对应属性及其属性值的关系,通过一个相对比较泛的Query,可以生成对应细化的Query。例如蛋糕,可以通过口味这个属性,产出草莓蛋糕、芝士蛋糕,通过规格这个属性,产出6寸蛋糕、袖珍蛋糕等等。
3、到综医美内容打标。 在医美内容展示上,用户通常会对某一特定的医美服务内容感兴趣,所以在产品形态上会提供一些不同的服务标签,帮助用户筛选精确的医美内容,精准触达用户需求。但是在标签和医美内容进行关联时,关联错误较多,用户筛选后经常看到不符合自己需求的内容。提升打标的准确率能够帮助用户更聚焦自己的需求。借助图谱的概念-POI打标能力和概念-UGC的打标关系,提升标签-内容的准确率。通过图谱能力打标,在准确率和召回率上均有明显提升。
延伸阅读:
https://zhuanlan.zhihu.com/p/384740848
二、阿里巴巴概念图谱AliCG
《机器知道哪吒是部电影吗?解读阿里巴巴概念图谱AliCG》 一文中介绍了阿里巴巴的概念图谱 AliCG。
该图谱由海量的概念核心实例、数万的细粒度概念和概念-实例三元组组成,这些数据包括了常见的人物、地点等通用实例。相较于传统的知识图谱,AliCG 包含大量中文细粒度概念,且具备自动更新、自动扩充的能力。
比如对于“刘德华”这一实例,AliCG 不仅包含“香港歌手”、“演员”等传统概念,还具有“华语歌坛不老男歌手”、“娱乐圈绝世好男人”等细粒度标签。
1、图谱构成
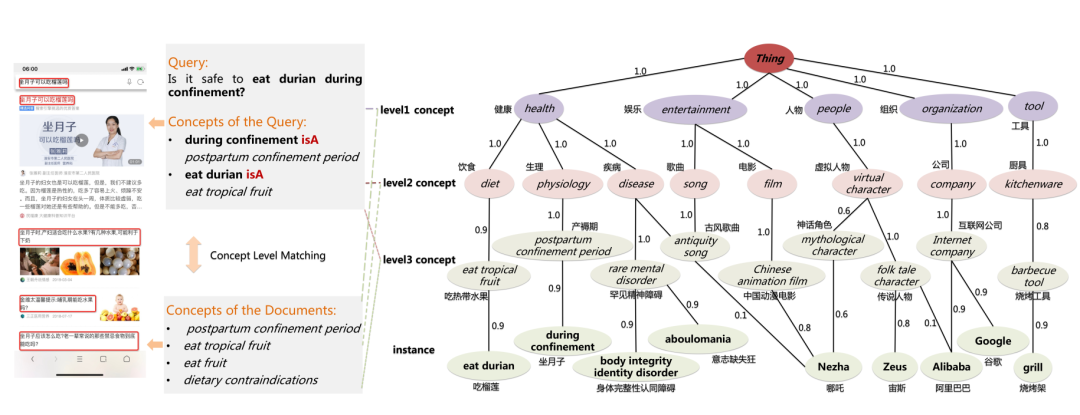 AliCG 分为四个级别的层次结构,其中,
AliCG 分为四个级别的层次结构,其中,
Level1 层由表示这些实例所属的领域概念组成;
Level2 层由实例类型或子类的概念组成;
Level3 层由基础概念组成,这些概念是实例的细粒度概念化;
Instance 层包括实体和非实体短语等所有实例。
2、图谱构建
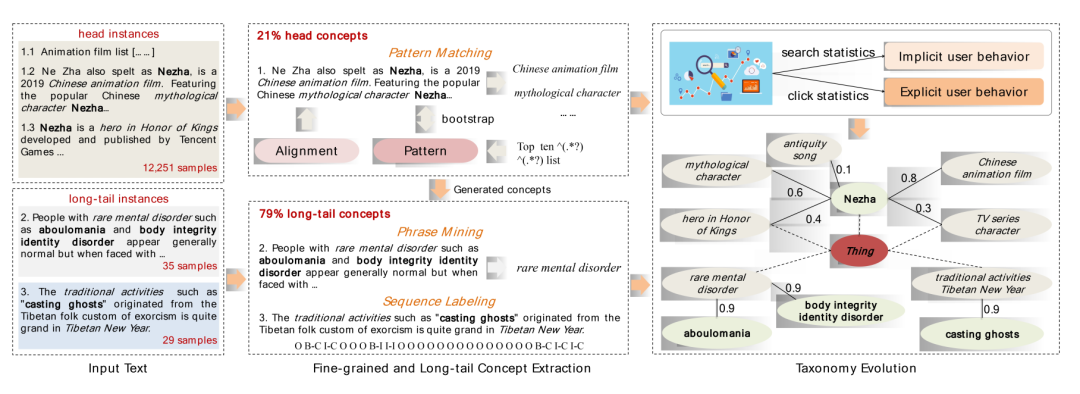
该工作主要聚焦于细粒度概念挖掘、长尾概念挖掘以及自动概念更新三个部分,如下图所示。
其中,
细粒度概念获取。不同于粗粒度概念,细粒度的概念有助于提升搜索的召回率。
在实现上,定义了一组精准的模板来从高置信度的匹配查询中利用 Bootstrapping 方法提取概念短语。例如,“十大XXX”是一种可用于提取种子概念的模式。基于这种模式,可以抽取出“十大手机游戏”等概念。
长尾概念挖掘。传统的概念抽取方法通常是基于 Hearst 模板提取概念。该系统首先基于短语挖掘算法,并利用外部领域知识图谱中的术语进行长尾的概念挖掘。
具体来说,首先过滤停用词,然后使用现成的短语挖掘工具 AutoPhrase 在无监督的情况下对语料库进行短语挖掘。同时采用了一种基于自训练的序列标注算法,用于长尾概念的挖掘,进一步提取一些分散的概念。
自动概念更新。传统的方法无法随着时间的推移更新概念的信息。例如,“哪吒”在不同的时期有着不同的含义,可以指神话作品人物或者上映影片。因此,必须将时间演化纳入概念分类体系构建中。
在实现上,首先将部分概念与预定义的同义词词典对齐。然后,通过通过每天的用户搜索实例热度计算置信度得分,并根据用户的点击行为来估计概念置信度分布。最后,将两个不同粒度的置信度得分联合构建实例-概念分类。
3、图谱应用
AliCG 在四种不同场景下的潜在应用案例:
(1)交互式搜索系统。 例如,“哪吒”链接到概念层 level3 的浅层概念,可引导用户依据列出的概念进行实时交互,实现实体消歧,精准定位搜索内容,最终索引到“哪吒之魔童降世”内容,高层级的概念有助于帮助定位目的实例;
(2)开放式对话系统。 可根据用户给定的实例联系概念知识图谱,实例-概念、概念-概念之间的链接通路使对话更有信息量,提高交互能力;
(3)阅读理解系统。 可根据文本内容对链接到“李白”这一实例的概念进行置信度排序,向用户展示最有可能的理解输出,在这里系统根据上下文可以准确判断“李白”并不是指代高频概念“盛唐时期的诗人”,这说明了细粒度的概念知识图谱对于识别精度有很大帮助;
(4)广告推荐系统。 根据用户历史购物信息,向中文概念图谱中索引高层次概念实例,多个概念之间进行组合推断,识别到“运动装备”、“工业产品”、“用具”,可以有效向用户推送户外相关产品,并给出推荐理由。
延伸阅读:https://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw%3D%3D&idx=1&mid=2247530031&scene=21&sn=8628218cbf4386a2ff667305d3d8d3cd#wechat_redirect
三、腾讯兴趣点概念图谱
《腾讯信息流内容理解技术实践》一文介绍了兴趣图谱的概念。
其应用场景在于推荐系统需要积累用户模型,因此需要保留完整的上下文,语义粒度要完整;不同的人消费同一篇文章背后原因可能不同,因此需要有一定的推理能力。因此,推出了兴趣点图谱。
1、图谱构成
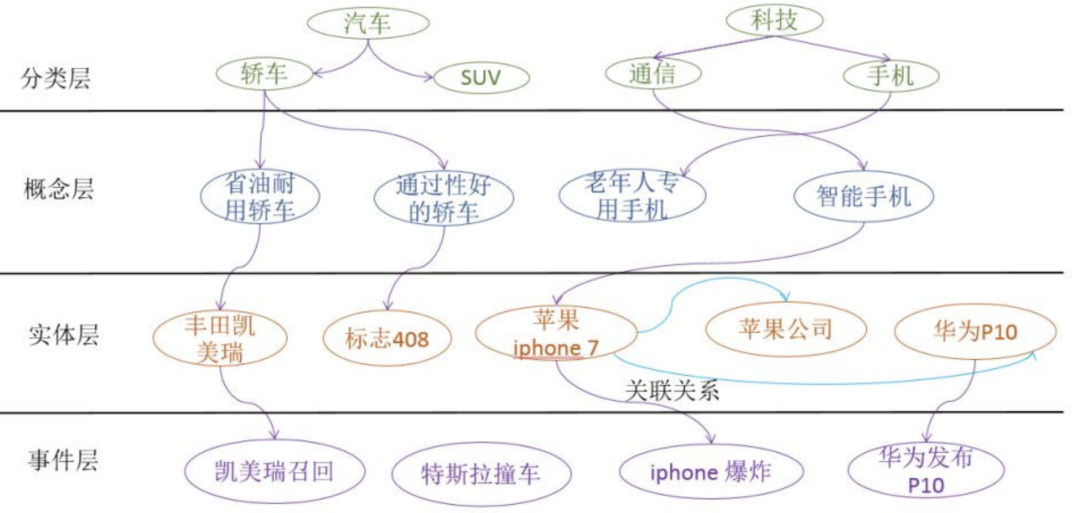
如上图所示,兴趣点图谱由四层组成:分别为分类层、概念层、实体词和事件层。
其中,分类层一般是由 PM 建设,是一个严格树状的结构,一般在1000左右个节点,主要解决人工运营的需求;
概念层指的是有相同属性的一类实体称之为概念,例如老年人专用手机、省油耐用车等,用于推理用户消费的真实意图,负责一般兴趣点的召回;
实体层指的是知识图谱中的实体,如:刘德华,华为 P10 等;
事件层:用来刻画某一个事件,例如:王宝强离婚、三星手机爆炸等。
在关系刻画上,兴趣点图包括三种关系:
上下位关系,例如“红米note2”的上位词是“性价比高的智能手机”;
关联关系;
参与关系,比如在“凯美瑞召回”事件中,“凯美瑞”是“凯美瑞召回”的一个参与实体。
2、图谱构建
图谱构建包括概念挖掘、 热门事件挖掘、关联关系挖掘等步骤。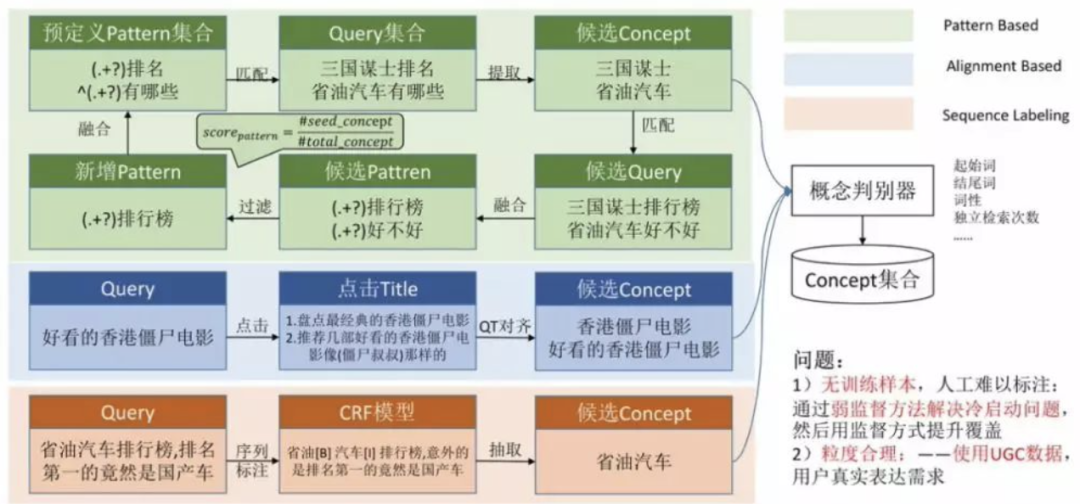
其中,例挖掘概念使用的是搜索数据,每一个概念都有多个点击的网页,对网页进行实体抽取,然后统计实体和概念的共现频次就可以获得较为准确的上下位关系。进一步的,文章 《腾讯提出概念挖掘系统ConcepT》 一文中对该部分的实现做了更为细致的分析。
事件指的是热门事件。如果一个事件比较热门,网友就会有了解需求,会通过搜索引擎来查询事件,因此使用 query 作为热门事件挖掘的来源。
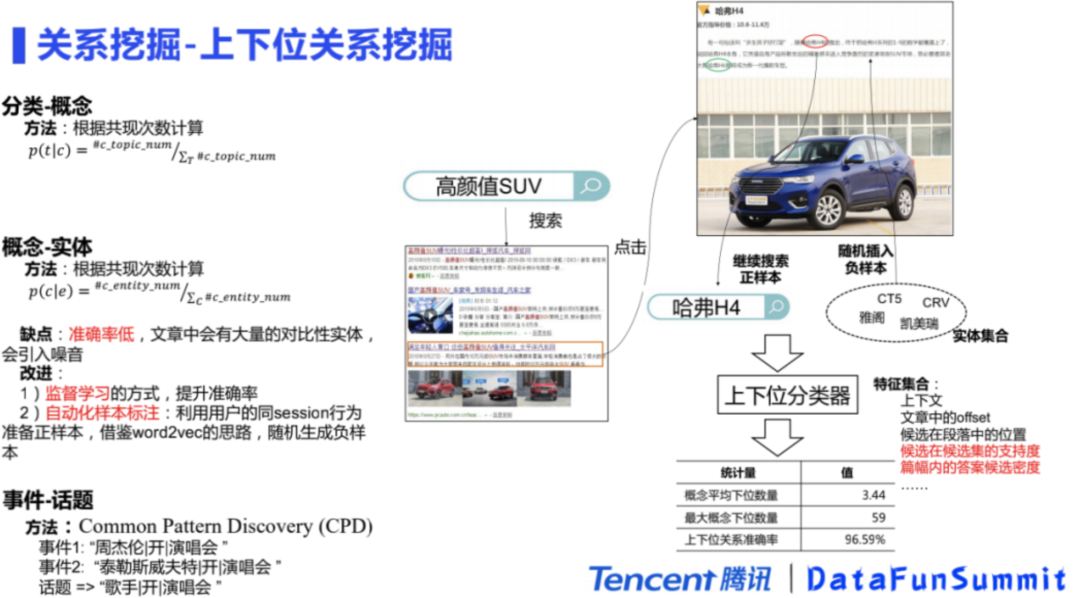
在关联关系的挖掘上,利用实体之间的共现数据进行训练,可以作为正例,负样本采用同类实体随机负采样,通过 pair wise 的 loss 进行训练,得到每个实体的 embedding,然后计算任意两个实体的关联度。
3、图谱应用
作为拥有微信等强流量的腾讯,主要应用于信息流等内容理解场景。例如,下面介绍了对于每一篇文章,希望能预测出适合描述该文章的兴趣点的需求,兴趣图谱主要用于召回。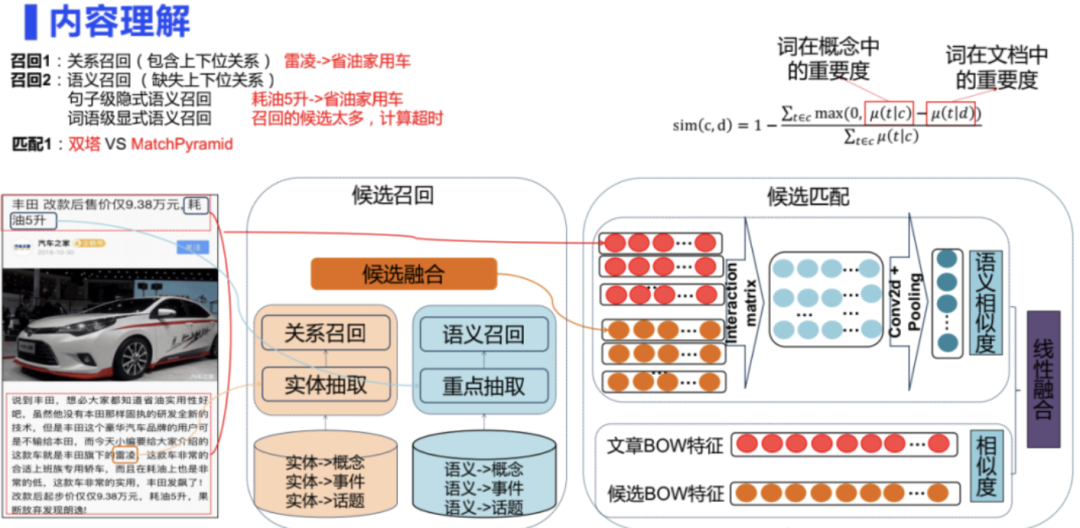
在整个兴趣点的理解上,可以拆解成两步,第一步是召回,第二步是匹配。召回又可以分为基于关系的召回和基于语义的召回。基于关系的召回主要是利用图谱中的上下位关系。例如一篇文章中出现了“雷凌”这个实体,它的上位概念是“省油家用车”,就可以把“省油家用车”作为候选的兴趣点召回。
延伸阅读:https://zhuanlan.zhihu.com/p/94706925?from_voters_page=true
总结
C端是知识图谱应用的一个重要领域,这个领域有大量的用户行为数据,存在着包括搜索、推荐、广告投放等业务。
建立概念图谱,百科图谱,甚至是事件图谱、事理图谱作为基础底库,对于特征扩充,召回扩展有重要意义。
当然,我们很明显的能够看到,这些工作很费人力,很脏,是一个基础设施建设的范畴,也必须去做。
概念图谱的工作之前也有做过,深有体会,大家可以一起加入进来去建设。
关于老刘
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
就职于360人工智能研究院、曾就职于中国科学院软件研究所。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。