文章目录
- 分析目的
- 一、数据采集
- 1、数据来源
- 2、数据说明
- 二、数据传输
- 三、数据处理
- 1、查看数据
- 2、清理无用特征值
- 3、标签列分析
- 4、清理只单一值的列
- 5、空值处理
- 6、数据类型转换
- 四、数据挖掘
- 1、构建模型
- 2、导入算法
- 五、总结
分析目的
本文针对某信贷网站提供的2007-2011年贷款申请人的各项评估指标,建立关于信贷审批达到利润最大化模型,即对贷款人借贷状态(全额借贷、不予借贷)进行分类,从而实现贷款利润最大化,并采用不同算法进行评估。
一、数据采集
1、数据来源
数据来源,这个要注册登录,也可以直接点击下载数据链接下载。下载链接,提取码:nkvk
2、数据说明
本数据集共有四万多头数据,包含52个特征值,其中数据类型分别是 float64型30个, object型22个。本次数据分析主要是实现贷款利润最大化,所以不需这么多特征量,需要对其进行舍弃处理。
二、数据传输
将数据导入到PYTHON软件:
import pandas as pd
loans = pd.read_csv('LoanStats3a.csv', skiprows=1)
half_count = len(loans) / 2
loans = loans.dropna(thresh=half_count, axis=1)
loans = loans.drop(['desc', 'url'],axis=1)
loans.to_csv('loans_2007.csv', index=False)
loans = pd.read_csv("loans_2007.csv")
loans.info()三、数据处理
1、查看数据
#loans.iloc[0]
loans.head(1)
2、清理无用特征值
了解各数据特征在业务中的含义。观察数据特征,主要清理与业务相关性不大的内容,重复特征值(等级下的另一个等级)以及预测后的特征值(批出的额度),此处的相关性大小凭业务知识进行粗略判断,如申请人的id,member_id,url,公司名emp_title等。
loans = loans.drop(["id", "member_id", "funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1)
loans = loans.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1)
loans = loans.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1)
loans.head(1)
删除无关字段后,剩余32个字段
3、标签列分析
#统计不同还款状态对应的样本数量——标签类分析
loans['loan_status'].value_counts()
统计结果显示,共有9种借贷状态,其中我们仅分析"Fully Paid"(全额借款)和"Charged Off"(不借款)这两种状态。“Fully paid”和“Charged Off”(其他取值样本较少,是否贷款含义不明,直接舍弃),表示同意贷款和不同意贷款,将此特征作为及其学习的标签列,由于sklearn中各及其学习模型值接受数值类型的数据类型,所以我们将“loan_status”映射为数值类型。
将“loan_status”映射为数值类型:
loans = loans[(loans['loan_status'] == "Fully Paid") | (loans['loan_status'] == "Charged Off")]
status_replace = {"loan_status" : {"Fully Paid": 1,"Charged Off": 0,}
}
loans= loans.replace(status_replace)
loans.loan_status4、清理只单一值的列
在进行数据分析时,部分字段对应的值只有一个,应删除这些无关字段
#查找只包含一个惟一值的列并删除
orig_columns = loans.columns
drop_columns = []
for col in orig_columns:col_series = loans[col].dropna().unique()#如果字段值都一样,删除该字段if len(col_series) == 1:drop_columns.append(col)
loans= loans.drop(drop_columns, axis=1)
print(drop_columns)
#将清洗后数据存入一个新的文件中
loans.to_csv('filtered_loans_2007.csv', index=False)
5、空值处理
本文的处理原则是:对于某一特征,如果出现空值的样本较少,则删除在此特征商为空值的样本;如果去空值的样本数量较多,则选择删除该特征。有上述原则知,我们需要对各特征出现空值的数量进行统计。
loans = pd.read_csv('filtered_loans_2007.csv')
null_counts = loans.isnull().sum()
null_counts
发现有四个特征有取空值的情况,其中三个空值数量较少,我们删除对应的样本,另外一个特征“pub_rec_bankruptcies”,空值数量较多,我们删除该特征。
loans = loans.drop("pub_rec_bankruptcies", axis=1)
loans = loans.dropna(axis=0)6、数据类型转换
#统计不同数据类型下的字段总和
print(loans.dtypes.value_counts())输出结果如下图,12个列所对应的数据类型为字符型,应转化为数值型。

#输出数据类型为字符型的字段
object_columns_df = loans.select_dtypes(include=["object"])
print(object_columns_df.iloc[0])
#对字符型数据进行分组计数
cols = ['home_ownership', 'verification_status', 'emp_length', 'term', 'addr_state']
for c in cols:print(loans[c].value_counts())
print(loans["purpose"].value_counts())
print(loans["title"].value_counts())
“emp_length”可以直接映射为数值型 ,对于“int_rate”,“revol_util”可以去掉百分号,然后转换为数值型,对于含义重复的特征,如“purpose”和“title”,都表示贷款意图,可选择删除一个,其他与模型训练无关的特征选择删除。剩余的其他字符型特征,此处选择使用pandas的get_dummies()函数,直接映射为数值型。
#将"emp_length"字段转化为字符型数据
mapping_dict = {"emp_length": {"10+ years": 10,"9 years": 9,"8 years": 8,"7 years": 7,"6 years": 6,"5 years": 5,"4 years": 4,"3 years": 3,"2 years": 2,"1 year": 1,"< 1 year": 0,"n/a": 0}
}
loans = loans.drop(["last_credit_pull_d", "earliest_cr_line", "addr_state", "title"], axis=1)
#将百分比类型转化为浮点型(小数类型)
loans["int_rate"] = loans["int_rate"].str.rstrip("%").astype("float")
loans["revol_util"] = loans["revol_util"].str.rstrip("%").astype("float")
loans = loans.replace(mapping_dict)
cat_columns = ["home_ownership", "verification_status", "emp_length", "purpose", "term"]
dummy_df = pd.get_dummies(loans[cat_columns])
loans = pd.concat([loans, dummy_df], axis=1)
loans = loans.drop(cat_columns, axis=1)
loans = loans.drop("pymnt_plan", axis=1)
loans.to_csv('cleaned_loans2007.csv', index=False)
import pandas as pd
#读取最终清洗的数据
loans = pd.read_csv("cleaned_loans2007.csv")
print(loans.info())
四、数据挖掘
1、构建模型
对于二分类问题,一般情况下,首选逻辑回归,这里我们引用sklearn库。首先定义模型效果的评判标准。根据贷款行业的实际情况,为了实现利润最大化,我们不仅要求模型预测正确率较高,同时还要尽可能的让错误率较低,这里采用两个指标tpr和fpr。同时该模型采用交叉验证(KFold,分组数采用默认的最好的分组方式)进行学习。为了比较不同模型的训练效果,建立三个模型。
2、导入算法
初始化处理
#负例预测为正例
fp_filter = (predictions == 1) & (loans["loan_status"] == 0)
fp = len(predictions[fp_filter])
# 正例预测为正例
tp_filter = (predictions == 1) & (loans["loan_status"] == 1)
tp = len(predictions[tp_filter])
# 负例预测为正例
fn_filter = (predictions == 0) & (loans["loan_status"] == 1)
fn = len(predictions[fn_filter])
# 负例预测为负例
tn_filter = (predictions == 0) & (loans["loan_status"] == 0)
tn = len(predictions[tn_filter])逻辑回归:
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
cols = loans.columns
train_cols = cols.drop("loan_status")
features = loans[train_cols]
target = loans["loan_status"]
lr.fit(features, target)
predictions = lr.predict(features)from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
lr = LogisticRegression()
kf = KFold(features.shape[0], random_state=1)
predictions = cross_val_predict(lr, features, target, cv=kf)
predictions = pd.Series(predictions)
# False positives.
fp_filter = (predictions == 1) & (loans["loan_status"] == 0)
fp = len(predictions[fp_filter])
# True positives.
tp_filter = (predictions == 1) & (loans["loan_status"] == 1)
tp = len(predictions[tp_filter])
# False negatives.
fn_filter = (predictions == 0) & (loans["loan_status"] == 1)
fn = len(predictions[fn_filter])
# True negatives
tn_filter = (predictions == 0) & (loans["loan_status"] == 0)
tn = len(predictions[tn_filter])
# Rates
tpr = tp / float((tp + fn))
fpr = fp / float((fp + tn))
print(tpr)
print(fpr)
print predictions[:20]
错误率和正确率都达到99.9%,错误率太高,通过观察预测结果发现,模型几乎将所有的样本都判断为正例,通过对原始数据的了解,分析造成该现象的原因是由于政府样本数量相差太大,即样本不均衡造成模型对正例样本有所偏重,大家可以通过下采样或上采用对数据进行处理,这里采用对样本添加权重值的方式进行调整。
逻辑回归balanced处理不均衡:
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import cross_val_predict
lr = LogisticRegression(class_weight="balanced")
kf = KFold(features.shape[0], random_state=1)
predictions = cross_val_predict(lr, features, target, cv=kf)
predictions = pd.Series(predictions)
# False positives.
fp_filter = (predictions == 1) & (loans["loan_status"] == 0)
fp = len(predictions[fp_filter])
# True positives.
tp_filter = (predictions == 1) & (loans["loan_status"] == 1)
tp = len(predictions[tp_filter])
# False negatives.
fn_filter = (predictions == 0) & (loans["loan_status"] == 1)
fn = len(predictions[fn_filter])
# True negatives
tn_filter = (predictions == 0) & (loans["loan_status"] == 0)
tn = len(predictions[tn_filter])
# Rates
tpr = tp / float((tp + fn))
fpr = fp / float((fp + tn))
print(tpr)
print(fpr)
print predictions[:20]
新的结果降低了错误率约为40%,但正确率也下降约为65%,因此有必要再次尝试,可以采取自定义权重值的方式。
逻辑回归penalty处理不均衡:
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import cross_val_predict
penalty = {0: 5,1: 1}
lr = LogisticRegression(class_weight=penalty)
kf = KFold(features.shape[0], random_state=1)
predictions = cross_val_predict(lr, features, target, cv=kf)
predictions = pd.Series(predictions)
# False positives.
fp_filter = (predictions == 1) & (loans["loan_status"] == 0)
fp = len(predictions[fp_filter])
# True positives.
tp_filter = (predictions == 1) & (loans["loan_status"] == 1)
tp = len(predictions[tp_filter])
# False negatives.
fn_filter = (predictions == 0) & (loans["loan_status"] == 1)
fn = len(predictions[fn_filter])
# True negatives
tn_filter = (predictions == 0) & (loans["loan_status"] == 0)
tn = len(predictions[tn_filter])
# Rates
tpr = tp / float((tp + fn))
fpr = fp / float((fp + tn))
print(tpr)
print(fpr)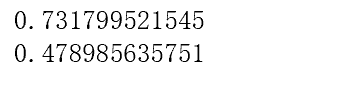
新的结果错误率约为47%,正确率约为73%,可根据需要继续调整,但调整策略并不限于样本权重值这一种,下面使用随机森林建立模型。
随机森林balanced处理不均衡:
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import cross_val_predict
rf = RandomForestClassifier(n_estimators=10,class_weight="balanced", random_state=1)
#print help(RandomForestClassifier)
kf = KFold(features.shape[0], random_state=1)
predictions = cross_val_predict(rf, features, target, cv=kf)
predictions = pd.Series(predictions)
# False positives.
fp_filter = (predictions == 1) & (loans["loan_status"] == 0)
fp = len(predictions[fp_filter])
# True positives.
tp_filter = (predictions == 1) & (loans["loan_status"] == 1)
tp = len(predictions[tp_filter])
# False negatives.
fn_filter = (predictions == 0) & (loans["loan_status"] == 1)
fn = len(predictions[fn_filter])
# True negatives
tn_filter = (predictions == 0) & (loans["loan_status"] == 0)
tn = len(predictions[tn_filter])
# Rates
tpr = tp / float((tp + fn))
fpr = fp / float((fp + tn))
print(tpr)
print(fpr)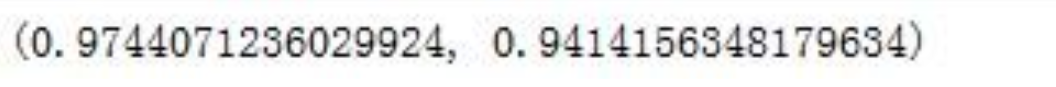
在这里错误率约为97%,正确率约为94%,错误率太高,同时可得到本次分析随机森林模型效果劣于逻辑回归模型的效果
五、总结
当模型效果不理想时,可以考虑的调整策略:
1.调节正负样本的权重参数。
2.更换模型算法。
3.同时几个使用模型进行预测,然后取去测的最终结果。
4.使用原数据,生成新特征。
5.调整模型参数。
)

)




 about Humble Numbers)









)

