分类模型的评估
在许多实际问题中,衡量分类器任务的成功程度是通过固定的性能指标来获取。一般最常见使用的是准确率,即预测结果正确的百分比,方法为estimator.score()
1 混淆矩阵
有时候,我们关注的是样本是否被正确诊断出来。例如,关于肿瘤的的判定,需要更加关心多少恶性肿瘤被正确的诊断出来。也就是说,在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵。

真正例(True Positive,TP):将一个正例判为正例
真反例(True Negative,TN):对一个反例正确的判为反例
伪反例(False Negative,FN,也称):将一个正例判为反例
伪正例(False Positive,TP):对一个反例正确的判为真例
2 精确率(Precision)与召回率(Recall)
精确率:等于TP/(TP+FP),给出的是预测为正例的样本中真实为正例的比例(判断查得准)

召回率:等于TP/(TP+FN),真实为正例的样本中预测结果为正例的比例(判断查的全,对正样本的区分能力)

3 其他分类标准
其他分类标准,除了正确率和精确率这两个指标之外,为了综合考量召回率和精确率,我们计算这两个指标的调和平均数,得到F1(F1-score)指标,反映了模型的稳健型
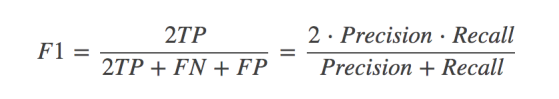
之所以使用调和平均数,是因为它除了具备平均功能外,还会对那些召回率和精确率更加接近的模型给予更高的分数;而这也是我们所希望的,因为那些召回率和精确率差距过大的学习模型,往往没有足够的使用价值。
4 分类模型评估API
sklearn.metrics.classification_report
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
参数:y_true:真实目标值 y_pred:估计器预测目标值
target_names:目标类别名称 return:字符串,三个指标值,每个类别精确率与召回率与F1
from sklearn.naive_bayes import MultinomialNB
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import classification_report
#1加载20类新闻数据,并进行分割
newsgroups = fetch_20newsgroups(subset='all')
#分割
x_train,x_test,y_train,y_test = train_test_split(newsgroups.data,newsgroups.target,test_size=0.25)#2 生成文章特征词,对数据集进行特征抽取
tf = TfidfVectorizer()
#以训练集当中的词的列表进行每篇文章重要性统计
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test = tf.transform(x_test)# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=1.0)
mlt.fit(x_train,y_train)
y_predict = mlt.predict(x_test)
print("预测的文章类别为",y_predict)
score = mlt.score(x_test,y_test)
print("准确率为:", score)
print("每个类别的精确率,召回率和F1:", classification_report(y_test, y_predict, target_names=newsgroups.target_names))  |
)

![[Java]java反射随笔](http://pic.xiahunao.cn/[Java]java反射随笔)






*)

)
)




)

