urllib库
urllib库是Python中一个最基本的网络请求库。可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据。
一、urlopen函数:
在Python3的urllib库中,所有和网络请求相关的方法,都被集到urllib.request模块下面了,以先来看下urlopen函数基本的使用:
from urllib import parse,requestresp=request.urlopen('http://www.baidu.com')
print(resp.read())
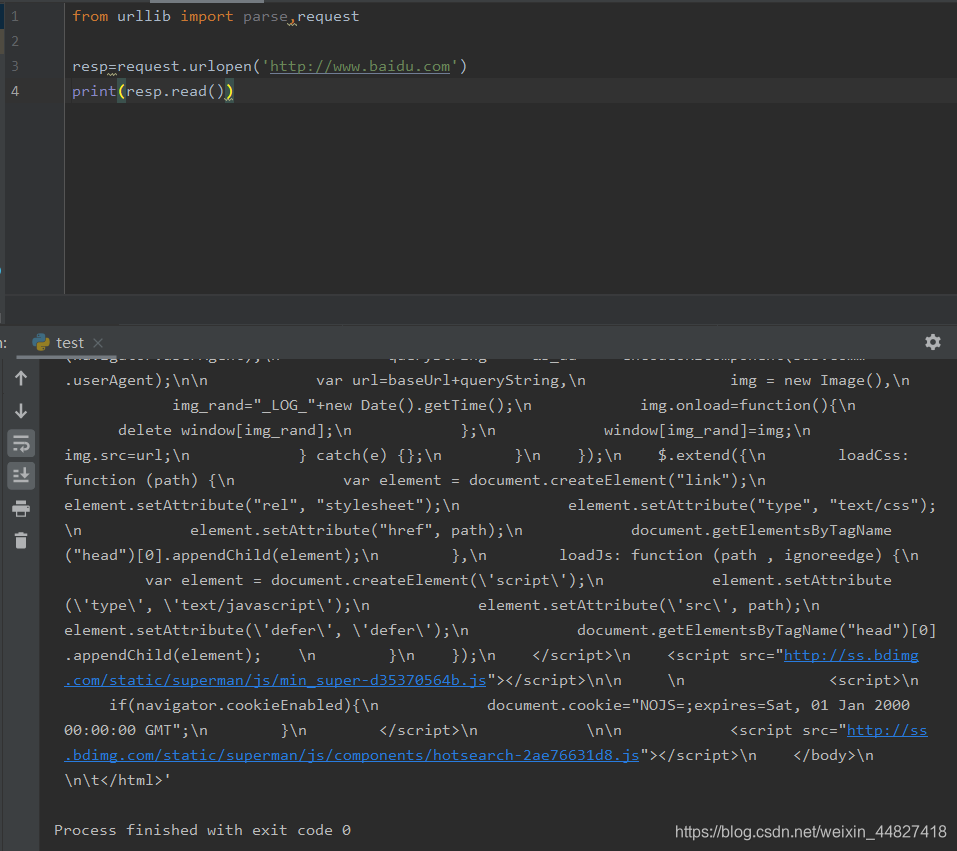
实际上,使用浏览器访问百度,右键查看源代码。你会发现,跟我们刚才打印出来的数据是一模一样的。也就是说,上面的三行代码就已经帮我们把百度的首页的全部代码爬下来了。一个基本的ur请求对应的python代码真的非常简单。
以下对urlopen函数的进行详细讲解:
- ur1:请求的url。
- data:请求的data,如果设置了这个值,那么将变成post请求。
- 返回值:返回值是一个
http.client.HTTPResponse对象,这个对象是一个类文件句柄对象。有read(size)、readline、readlines以及getcode等方法。
二、urlretrieve函数:
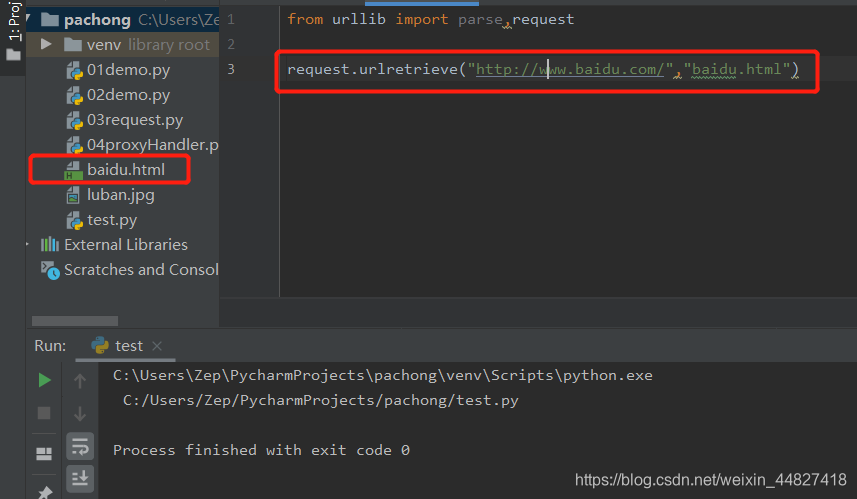
这个函数可以方便的将网页上的一个文件保存到本地。以下代码可以非常方便的将百度的首页下载到本地:
request.urlretrieve("http://www.baidu.com/","baidu.html")
三、urlencode函数:
用浏览器发送请求的时候,如果url中包含了中文或者其他特殊字符,那么浏览器会自动的给我们进行编码。而如果使用代码发送请求,那么就必须手动的进行编码,这时候就应该使用urlencode函数来实现。urlencode 可以把字典数据转换为URL编码的数据。
示例代码如下:
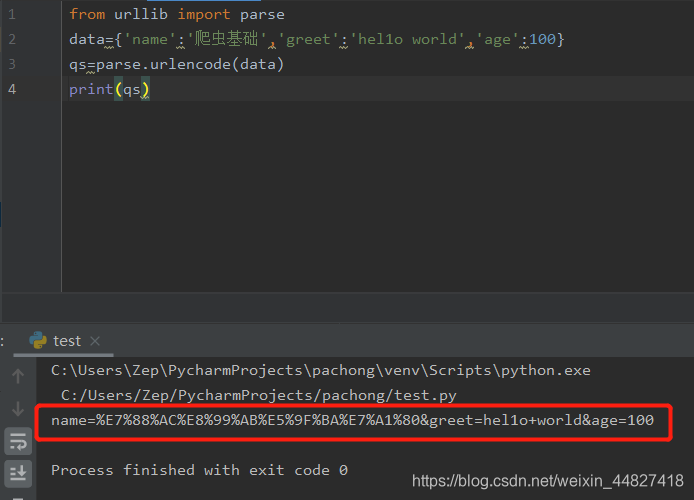
from urllib import parse
data={'name':'爬虫基础','greet':'hel1o world','age':100}
qs=parse.urlencode(data)
print(qs)
四、parse-qs函数:
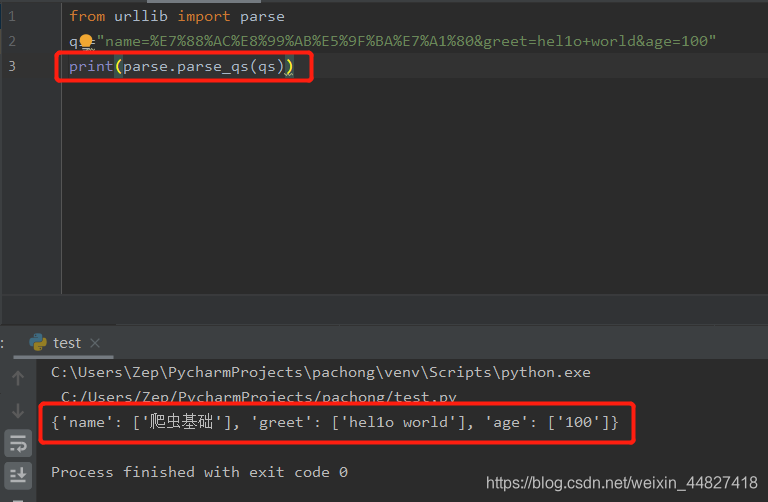
可以将经过编码后的url参数进行解码.示例代码如下:
from urllib import parse
qs="name=%E7%88%AC%E8%99%AB%E5%9F%BA%E7%A1%80&greet=hel1o+world&age=100"
print(parse.parse_qs(qs))
五、urlparse和urlsplit:
有时候拿到一个url想要对这个url中的各个组成部分进行分割,那么这时候就可以使用urlparse 或者是urlsplit来进行分割。
urlparse VS urlsplit:
urlparse和urlsplit基本上是一模一样的。唯一不一样的地方是,'urlparse里面多了一个params属性,而urlsplit 没有这个params 属性。
比如有一个ur1为:url=“http://www.baidu.com/s;he116wd=python&username=abc#1”,那么urlparse可以获取到hello,而urlsplit不可以获取到ur1中的params。不过params也用得比较少。
示例代码如下:
from urllib import parse# urlparse()函数,可以对url中的各个组成部分进行分割
url = 'http://www.baid.com/s;hello?wd=python&username=abc#1'
result = parse.urlparse(url)
print(result)
print('sheme:',result.scheme)
print('netloc:',result.netloc)
print('path:',result.path)
print('params:',result.params)
print('query:',result.query)
print('fragment:',result.fragment)
print("___________________________________________________")# urlsplit()函数,可以对url中的各个组成部分进行分割。
# 与urlparse()函数的区别是获取不到params参数
url = 'http://www.baid.com/s;hello?wd=python&username=abc#1'
result1 = parse.urlsplit(url)
print(result1)
print('sheme:',result1.scheme)
print('netloc:',result1.netloc)
print('path:',result1.path)
print('query:',result1.query)
print('fragment:',result1.fragment)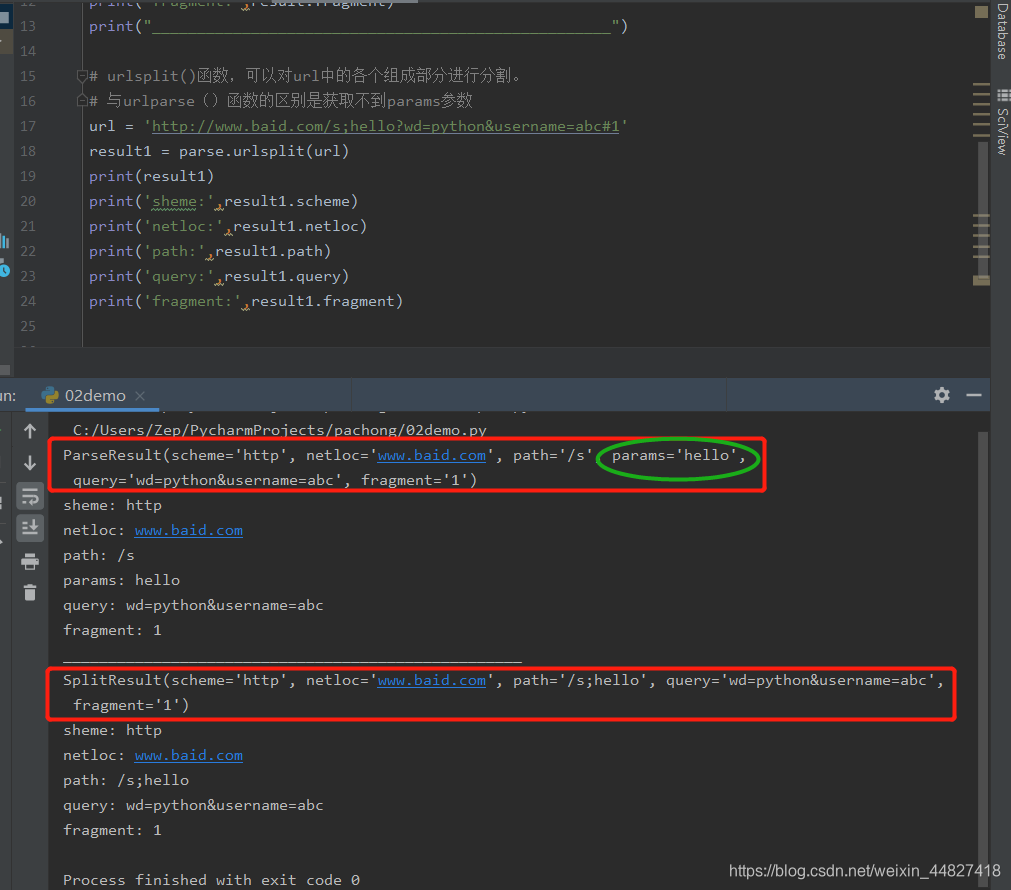
六、request.Request类:
如果想要在请求的时候增加一些请求头,那么就必须使用request.Request类来实现。比如要增加一个user-Agent,示例代码如下:
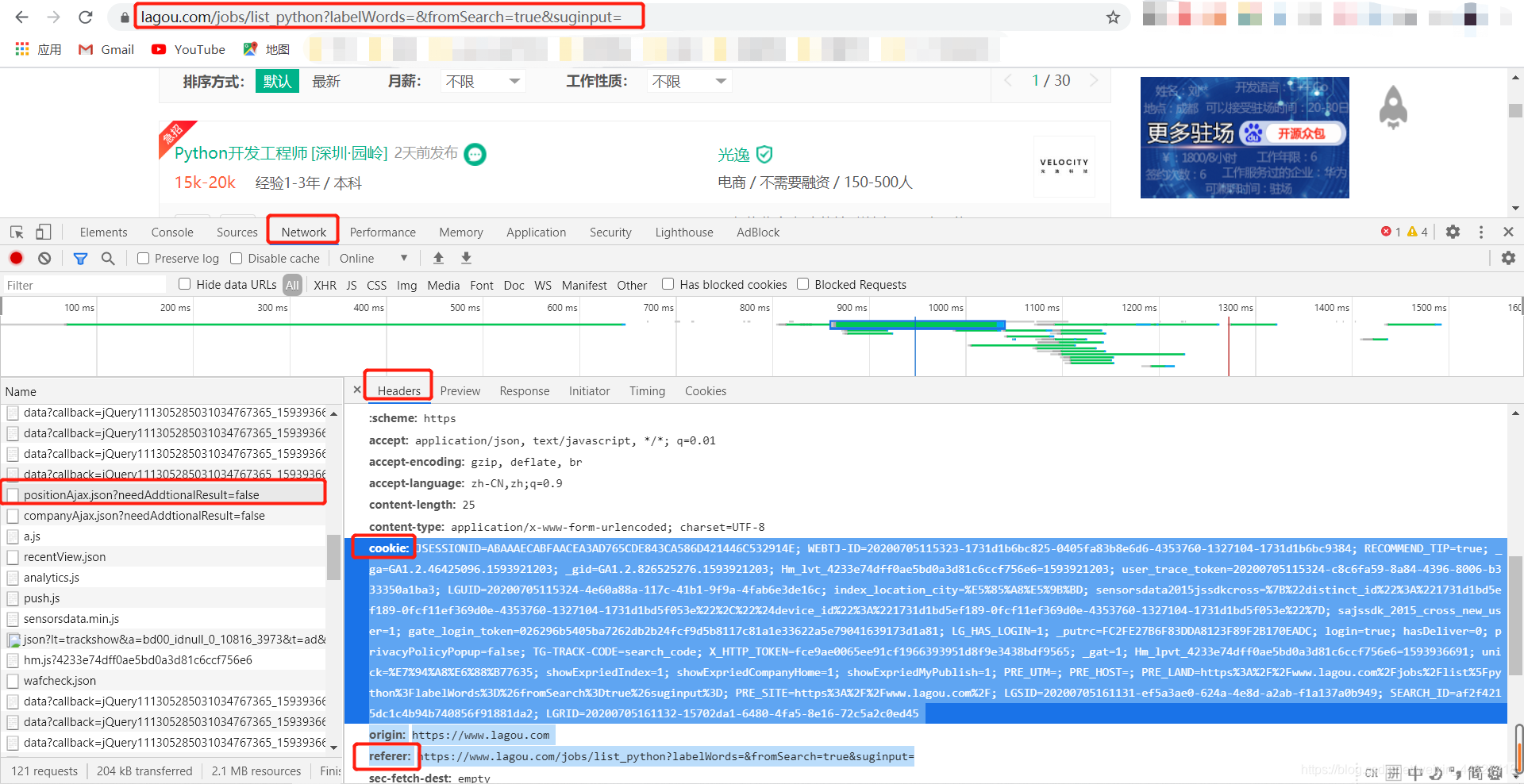
from urllib import request,parse# url = 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='# resp = request.urlopen(url)
# print(resp.read())url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
headers = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36','Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=','cookie':'JSESSIONID=ABAAAECABFAACEA3AD765CDE843CA586D421446C532914E; WEBTJ-ID=20200705115323-1731d1b6bc825-0405fa83b8e6d6-4353760-1327104-1731d1b6bc9384; RECOMMEND_TIP=true; _ga=GA1.2.46425096.1593921203; _gid=GA1.2.826525276.1593921203; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1593921203; user_trace_token=20200705115324-c8c6fa59-8a84-4396-8006-b333350a1ba3; LGUID=20200705115324-4e60a88a-117c-41b1-9f9a-4fab6e3de16c; index_location_city=%E5%85%A8%E5%9B%BD; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221731d1bd5ef189-0fcf11ef369d0e-4353760-1327104-1731d1bd5f053e%22%2C%22%24device_id%22%3A%221731d1bd5ef189-0fcf11ef369d0e-4353760-1327104-1731d1bd5f053e%22%7D; sajssdk_2015_cross_new_user=1; gate_login_token=026296b5405ba7262db2b24fcf9d5b8117c81a1e33622a5e79041639173d1a81; LG_HAS_LOGIN=1; _putrc=FC2FE27B6F83DDA8123F89F2B170EADC; login=true; hasDeliver=0; privacyPolicyPopup=false; TG-TRACK-CODE=search_code; X_HTTP_TOKEN=fce9ae0065ee91cf1966393951d8f9e3438bdf9565; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1593936691; unick=%E7%94%A8%E6%88%B77635; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; PRE_UTM=; PRE_HOST=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist%5Fpython%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2F; LGSID=20200705161131-ef5a3ae0-624a-4e8d-a2ab-f1a137a0b949; SEARCH_ID=af2f4215dc1c4b94b740856f91881da2; LGRID=20200705161132-15702da1-6480-4fa5-8e16-72c5a2c0ed45'
}data = {'first':'true','pn':1,'kd':'python'
}req = request.Request(url,headers=headers,data=parse.urlencode(data).encode('utf-8'),method='POST')
resp = request.urlopen(req)
print(resp.read().decode('utf-8'))
# print(resp.read())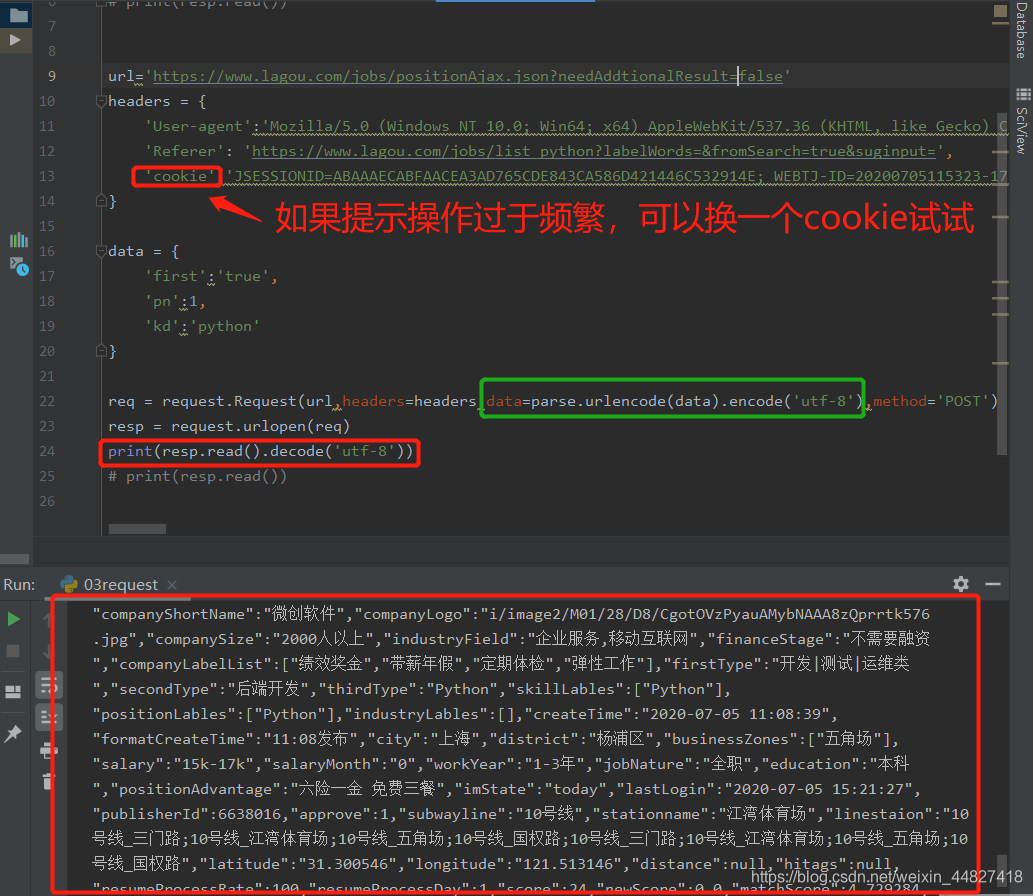
JSON在线解析网站:http://json.cn/
自动获取本地IP地址网站:http://httpbin.org/
七、代码:
from urllib import request
from urllib import parse# resp = request.urlopen('http://www.baidu.com')
# print(resp.read())
# print(resp.read(10))
# print(resp.readline())
# print(resp.readlines())
# print(resp.getcode())# urlretrieve函数,可以将网页上的一个文件保存到本地
# request.urlretrieve("https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1593927965278&di=8749753c6b8d8d142eb37ebac38fe7de&imgtype=0&src=http%3A%2F%2Fcyimg.quji.com%2Fnewsimg%2F2016%2F02%2F19%2F0449ff918e2484761f2dee7af1432108.jpg",'luban.jpg')# urlencode函数,可以把字典数据转换成url编码的数据# data = {'name':'爬虫基础','greet':'hello world','age':100}
# qs = parse.urlencode(data)
# print(qs)# 案例
# url = 'http://www.baidu.com/s?wd=刘德华'
url = 'http://www.baidu.com/s'
params = {"wd":"刘德华"}
qs = parse.urlencode(params)
print(qs)
url = url + "?" + qs
print(url)
resp = request.urlopen(url)
print(resp.read())# parse_qs函数,可以将经过编码后的url参数进行解码
print(parse.parse_qs(qs))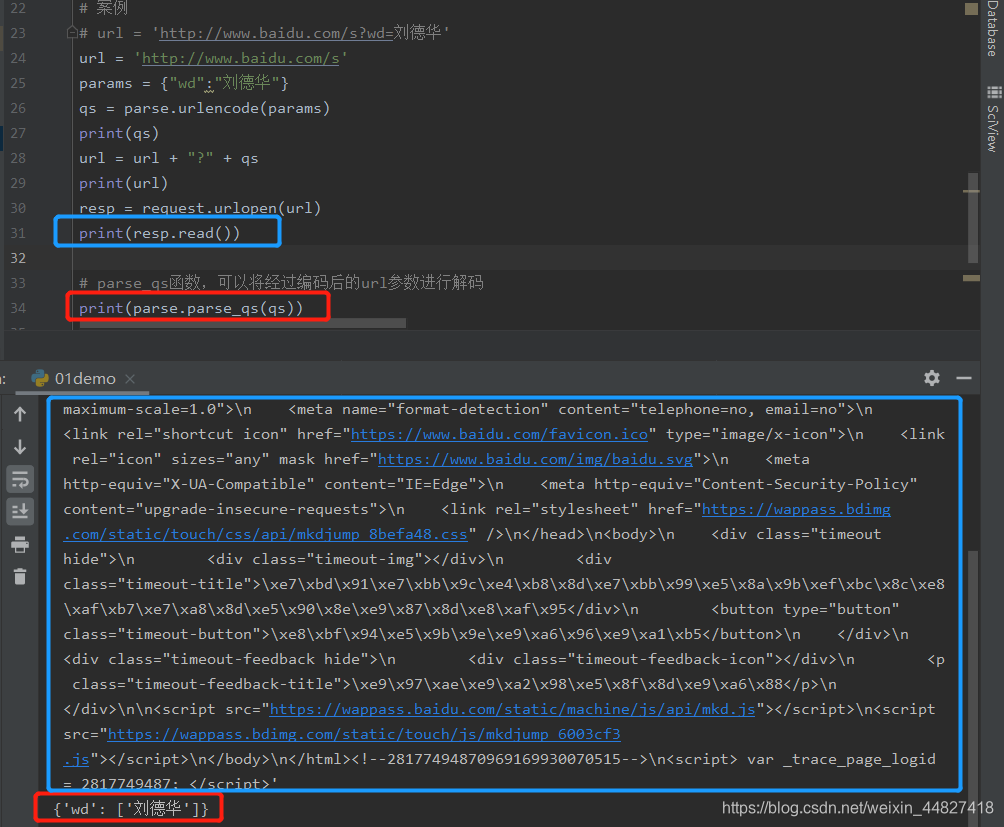
)

)
——cookie的原理、保存与加载)
)
-钱,收入和支出)
——requests模块)
)
——爬虫概述 http协议复习)



)
——数据提取 jsonpath模块)

)

——数据提取 lxml模块)

——selenium的介绍 selenium定位获取标签对象并提取数据 selenium的其它使用方法)