同学你好!本文章于2021年末编写,获得广泛的好评!
故在2022年末对本系列进行填充与更新,欢迎大家订阅最新的专栏,获取基于Pytorch1.10版本的理论代码(2023版)实现,
Pytorch深度学习·理论篇(2023版)目录地址为:
CSDN独家 | 全网首发 | Pytorch深度学习·理论篇(2023版)目录本专栏将通过系统的深度学习实例,从可解释性的角度对深度学习的原理进行讲解与分析,通过将深度学习知识与Pytorch的高效结合,帮助各位新入门的读者理解深度学习各个模板之间的关系,这些均是在Pytorch上实现的,可以有效的结合当前各位研究生的研究方向,设计人工智能的各个领域,是经过一年时间打磨的精品专栏!https://v9999.blog.csdn.net/article/details/127587345欢迎大家订阅(2023版)理论篇
以下为2021版原文~~~~

1 过拟合问题的描述
1.1 过拟合问题概述
深度额学习训练过程中,在训练阶段得到了较好的准确率,但在识别非数据集数据时存在精度下降的问题,这种现象称为过拟合现象。
主要原因:由于模型的拟合度过高,导致模型不仅学习样本的群体规律,也学习样本的个体规律。
1.2 过拟合问题模型的设计
1.2.1 构建数据集---Over_fitting.py(第1部分)
import sklearn.datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
from LogicNet_fun import LogicNet,moving_average,predict,plot_decision_boundary# 1 构建数据集
np.random.seed(0) # 设置随机数种子
X , Y =sklearn.datasets.make_moons(40,noise=0.2) # 生成两组半圆形数据
arg = np.squeeze(np.argwhere(Y==0),axis=1) # 获取第1组数据索引
arg2 = np.squeeze(np.argwhere(Y==1),axis=1) # 获取第2组数据索引
# 显示数据
plt.title("train moons data")
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+',label = 'data1')
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o',label = 'data2')
plt.legend()
plt.show()
1.2.2 搭建网络模型---Over_fitting.py(第2部分)
# 2 搭建网络模型
model = LogicNet(inputdim=2,hiddendim=500,outputdim=2) # 实例化模型,增加拟合能力将hiddendim赋值为500
optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器:反向传播过程中使用。1.2.3 训练模型,并将训练过程可视化---Over_fitting.py(第3部分)
# 3 训练模型+训练过程loss可视化
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor) # 将numpy数据转化为张量
epochs = 1000 # 定义迭代次数
losses = [] # 损失值列表
for i in range(epochs):loss = model.getloss(xt,yt)losses.append(loss.item()) # 保存损失值中间状态optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播损失值optimizer.step() # 更新参数
avgloss = moving_average(losses) # 获得损失值的移动平均值
plt.figure(1)
plt.subplot(211)
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs Training loss')
plt.show()1.2.4 将模型结果可视化,观察过拟合现象---Over_fitting.py(第4部分)
# 4 模型结果可视化,观察过拟合现象
plot_decision_boundary(lambda x: predict(model,x),X,Y)
from sklearn.metrics import accuracy_score
print("训练时的准确率",accuracy_score(model.predict(xt),yt))
# 重新生成两组半圆数据
Xtest,Ytest = sklearn.datasets.make_moons(80,noise=0.2)
plot_decision_boundary(lambda x: predict(model,x),Xtest,Ytest)
Xtest_t = torch.from_numpy(Xtest).type(torch.FloatTensor) # 将numpy数据转化为张量
Ytest_t = torch.from_numpy(Ytest).type(torch.LongTensor)
print("测试时准确率",accuracy_score(model.predict(Xtest_t),Ytest_t))
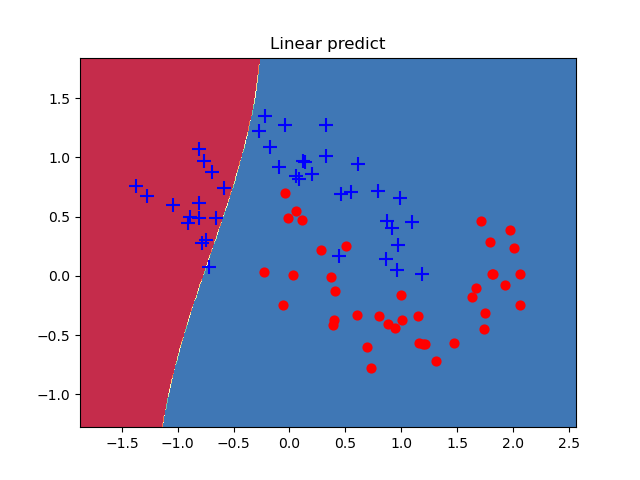
1.2.5 模型代码总览---Over_fitting.py(总结)
#####Over_fitting.pyimport sklearn.datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
from LogicNet_fun import LogicNet,moving_average,predict,plot_decision_boundary# 1 构建数据集
np.random.seed(0) # 设置随机数种子
X , Y =sklearn.datasets.make_moons(40,noise=0.2) # 生成两组半圆形数据
arg = np.squeeze(np.argwhere(Y==0),axis=1) # 获取第1组数据索引
arg2 = np.squeeze(np.argwhere(Y==1),axis=1) # 获取第2组数据索引
# 显示数据
plt.title("train moons data")
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+',label = 'data1')
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o',label = 'data2')
plt.legend()
plt.show()# 2 搭建网络模型
model = LogicNet(inputdim=2,hiddendim=500,outputdim=2) # 实例化模型,增加拟合能力将hiddendim赋值为500
optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器:反向传播过程中使用。# 3 训练模型+训练过程loss可视化
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor) # 将numpy数据转化为张量
epochs = 1000 # 定义迭代次数
losses = [] # 损失值列表
for i in range(epochs):loss = model.getloss(xt,yt)losses.append(loss.item()) # 保存损失值中间状态optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播损失值optimizer.step() # 更新参数
avgloss = moving_average(losses) # 获得损失值的移动平均值
plt.figure(1)
plt.subplot(211)
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs Training loss')
plt.show()# 4 模型结果可视化,观察过拟合现象
plot_decision_boundary(lambda x: predict(model,x),X,Y)
from sklearn.metrics import accuracy_score
print("训练时的准确率",accuracy_score(model.predict(xt),yt))
# 重新生成两组半圆数据
Xtest,Ytest = sklearn.datasets.make_moons(80,noise=0.2)
plot_decision_boundary(lambda x: predict(model,x),Xtest,Ytest)
Xtest_t = torch.from_numpy(Xtest).type(torch.FloatTensor) # 将numpy数据转化为张量
Ytest_t = torch.from_numpy(Ytest).type(torch.LongTensor)
print("测试时准确率",accuracy_score(model.predict(Xtest_t),Ytest_t))LogicNet_fun.py
### LogicNet_fun.pyimport torch.nn as nn #引入torch网络模型库
import torch
import numpy as np
import matplotlib.pyplot as plt# 1.2 定义网络模型
class LogicNet(nn.Module): #继承nn.Module类,构建网络模型def __init__(self,inputdim,hiddendim,outputdim): #初始化网络结构 ===》即初始化接口部分super(LogicNet,self).__init__()self.Linear1 = nn.Linear(inputdim,hiddendim) #定义全连接层self.Linear2 = nn.Linear(hiddendim,outputdim) #定义全连接层self.criterion = nn.CrossEntropyLoss() #定义交叉熵函数def forward(self,x):# 搭建用两个全连接层组成的网络模型 ===》 即正向接口部分:将网络层模型结构按照正向传播的顺序搭建x = self.Linear1(x)# 将输入传入第一个全连接层x = torch.tanh(x)# 将第一个全连接层的结果进行非线性变化x = self.Linear2(x)# 将网络数据传入第二个全连接层return xdef predict(self,x):# 实现LogicNet类的预测窗口 ===》 即预测接口部分:利用搭建好的正向接口,得到模型预测结果#调用自身网络模型,并对结果进行softmax()处理,分别的出预测数据属于每一个类的概率pred = torch.softmax(self.forward(x),dim=1)# 将正向结果进行softmax(),分别的出预测结果属于每一个类的概率return torch.argmax(pred,dim=1)# 返回每组预测概率中最大的索引def getloss(self,x,y):# 实现LogicNet类的损失值接口 ===》 即损失值计算接口部分:计算模型的预测结果与真实值之间的误差,在反向传播时使用y_pred = self.forward(x)loss = self.criterion(y_pred,y)# 计算损失值的交叉熵return loss# 1.5 训练可视化
def moving_average(a,w=10): #计算移动平均损失值if len(a) < w:return a[:]return [val if idx < w else sum(a[(idx - w):idx]) / w for idx, val in enumerate(a)]def moving_average_to_simp(a,w=10): #if len(a) < w:return a[:]val_list = []for idx, val in enumerate(a):if idx < w:# 如果列表 a 的下标小于 w, 直接将元素添加进 xxx 列表val_list.append(val)else:# 向前取 10 个元素计算平均值, 添加到 xxx 列表val_list.append(sum(a[(idx - w):idx]) / w)def plot_losses(losses):avgloss = moving_average(losses)#获得损失值的移动平均值plt.figure(1)plt.subplot(211)plt.plot(range(len(avgloss)),avgloss,'b--')plt.xlabel('step number')plt.ylabel('Training loss')plt.title('step number vs Training loss')plt.show()# 1.7 数据可视化模型
def predict(model,x): #封装支持Numpy的预测接口x = torch.from_numpy(x).type(torch.FloatTensor)model = LogicNet(inputdim=2, hiddendim=3, outputdim=2)ans = model.predict(x)return ans.numpy()def plot_decision_boundary(pred_func,X,Y): #在直角模型中实现预测结果的可视化#计算范围x_min ,x_max = X[:,0].min()-0.5 , X[:,0].max()+0.5y_min ,y_max = X[:,1].min()-0.5 , X[:,1].max()+0.5h=0.01xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))#根据数据输入进行预测Z = pred_func(np.c_[xx.ravel(),yy.ravel()])Z = Z.reshape(xx.shape)#将数据的预测结果进行可视化plt.contourf(xx,yy,Z,cmap=plt.cm.Spectral)plt.title("Linear predict")arg = np.squeeze(np.argwhere(Y==0),axis=1)arg2 = np.squeeze(np.argwhere(Y==1),axis=1)plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+')plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o')plt.show()2 改善过拟合现象的方法
2.1 过拟合现象产生的原因
因为神经网络在训练过程中,只看到有限的信息,在数据量不足的情况下,无法合理地区分哪些属于个体特征,哪些属于群体特征。而在真实场景下,所有的样本特征都是多样的,很难在训练数据集中将所有的样本情况全部包括。
2.2 有效改善过拟合现象的方法
2.2.1 early stopping
在发生过拟合之前提前结束训l练。这个方法在理论上是可行的,但是这个结束的时间点不好把握。
2.2.2 数据集扩增(data augmentation)
让模型见到更多的情况,可以最大化满足全样本,但实际应用中,对于未来事件的颈测却显得力不丛心。
2.2.3 正则化
通过范数的概念,增强模型的泛化能力,包括L1正则化、L2正则化(L2正则化也称为weight decay).
2.2.4 dropout
每次训练时舍去一些节点来增强泛化能力
3 正则化
在神经网络计算损失值的过程中,在损失后面再加一项。这样损失值所代表的输出与标准结果间的误差就会受到干扰,导致学习参数w和b无法按照目标方向来调整。实现模型无法与样本完全拟合的结果,达到防止过拟合的效果。
3.1 正则化效果描述
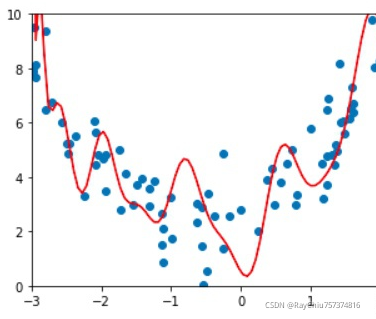
不加正则化训练出来的模型:
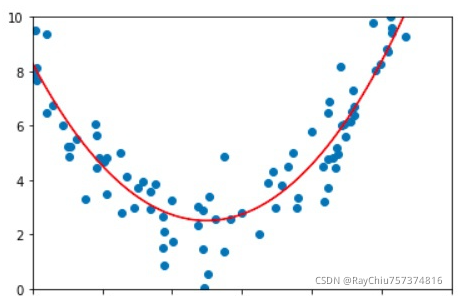
加了正则的模型表现
可以看到训练出来的模型太复杂,会影响使用,容易过拟合。
3.2 正则化的分类与公式
3.2.1 干扰项的特性
当欠拟合(模型的拟合能力不足)时,希望它对模型误差影响尽量小,让模型快速来拟合实际。
当过拟合(模型的拟合能力过强)时,希望它对模型误差影响尽量大,让模型不要产生过拟合的情况。
3.2.2 范数
L1:所有学习参数w的绝对值的和
L2:所有学习参数w的平方和,然后求平方根
3.2.3 正则化的损失函数-L1

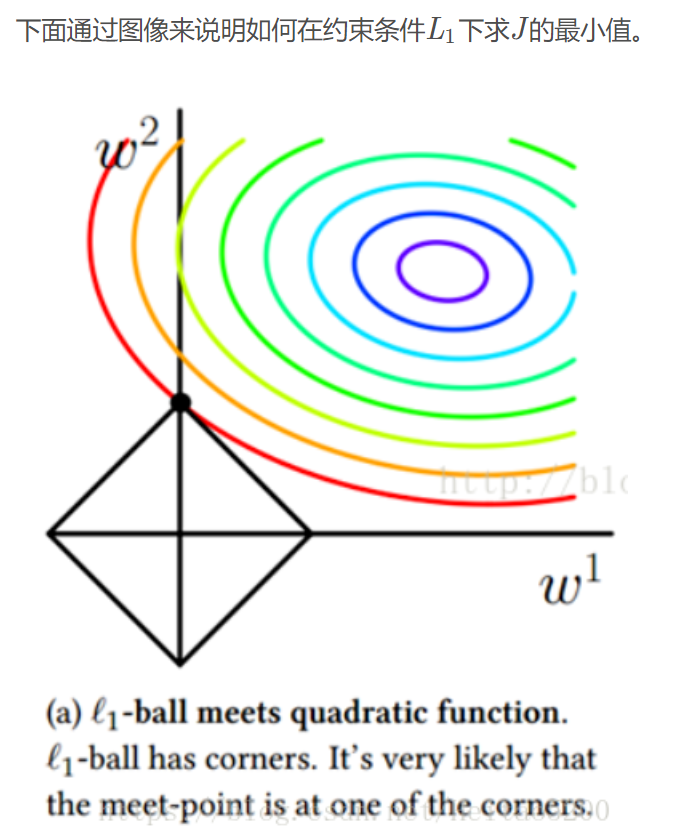

3.2.4 正则化的损失函数-L2

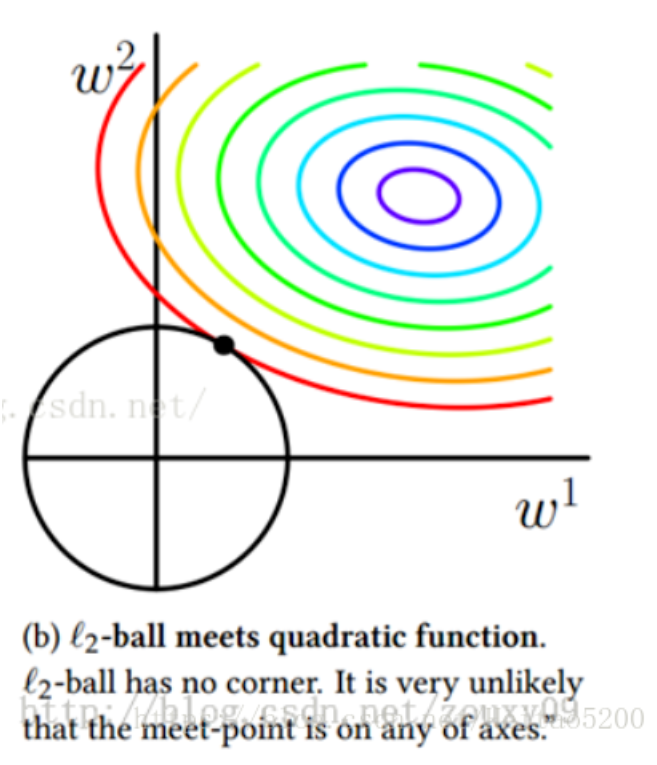
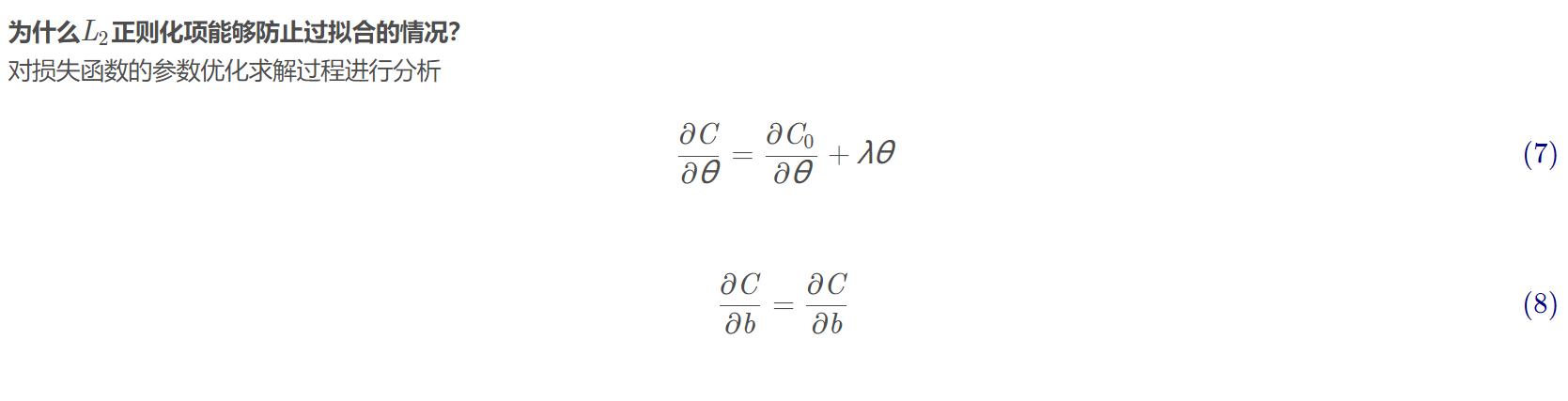
 3.3 L2正则化的实现
3.3 L2正则化的实现
3.3.1 正则化实现
使用weight_decay参数指定权重衰减率,相当于L2正则化中的正则化系数,用来调整正则化对loss的影响。
weight_decay参数默认对模型中的所有参数进行L2正则化处理,包括权重w和偏置b。
3.3.2 优化器参数的方式实现正则化:字典的方式实现
optimizer =torch.optim.Adam([{'params':weight_p,'weight_decay':0.001},{'params':bias_p,'weight_decay':0}],lr=0.01)字典中的param以指的是模型中的权重。将具体的权重张量放入优化器再为参数weight_decay赋值,指定权重值哀减率,便可以实现为指定参数进行正则化处理。
如何获得权重张量weight_p与bias_p?
# 主要通过实例化后的模型对象得到
weight_p , bias_p =[],[]
for name , p in model.named_parameters():if 'bias' in name:bias_p += [p]else:weight_p += [p]3.4 使用L2正则化改善模型的过拟合状况
3.4.1 修改Over_fitting.py 中的优化器部分
import sklearn.datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
from LogicNet_fun import LogicNet,moving_average,predict,plot_decision_boundary# 1 构建数据集
np.random.seed(0) # 设置随机数种子
X , Y =sklearn.datasets.make_moons(40,noise=0.2) # 生成两组半圆形数据
arg = np.squeeze(np.argwhere(Y==0),axis=1) # 获取第1组数据索引
arg2 = np.squeeze(np.argwhere(Y==1),axis=1) # 获取第2组数据索引
# 显示数据
plt.title("train moons data")
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+',label = 'data1')
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o',label = 'data2')
plt.legend()
plt.show()# 2 搭建网络模型
model = LogicNet(inputdim=2,hiddendim=500,outputdim=2) # 实例化模型,增加拟合能力将hiddendim赋值为500
#optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器:反向传播过程中使用。
# 修改为:
#添加正则化处理
weight_p , bias_p =[],[]
for name , p in model.named_parameters(): # 获取模型中的所有参数及参数名字if 'bias' in name:bias_p += [p] # 收集偏置参数else:weight_p += [p] # 收集权重
optimizer =torch.optim.Adam([{'params':weight_p,'weight_decay':0.001},{'params':bias_p,'weight_decay':0}],lr=0.01) # 带有正则化处理的优化器3.4.2 regularization01.py 总览
import sklearn.datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
from LogicNet_fun import LogicNet,moving_average,predict,plot_decision_boundary# 1 构建数据集
np.random.seed(0) # 设置随机数种子
X , Y =sklearn.datasets.make_moons(40,noise=0.2) # 生成两组半圆形数据
arg = np.squeeze(np.argwhere(Y==0),axis=1) # 获取第1组数据索引
arg2 = np.squeeze(np.argwhere(Y==1),axis=1) # 获取第2组数据索引
# 显示数据
plt.title("train moons data")
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+',label = 'data1')
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o',label = 'data2')
plt.legend()
plt.show()# 2 搭建网络模型
model = LogicNet(inputdim=2,hiddendim=500,outputdim=2) # 实例化模型,增加拟合能力将hiddendim赋值为500
#optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器:反向传播过程中使用。
# 修改为:
#添加正则化处理
weight_p , bias_p =[],[]
for name , p in model.named_parameters(): # 获取模型中的所有参数及参数名字if 'bias' in name:bias_p += [p] # 收集偏置参数else:weight_p += [p] # 收集权重
optimizer =torch.optim.Adam([{'params':weight_p,'weight_decay':0.001},{'params':bias_p,'weight_decay':0}],lr=0.01) # 带有正则化处理的优化器# 3 训练模型+训练过程loss可视化
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor) # 将numpy数据转化为张量
epochs = 1000 # 定义迭代次数
losses = [] # 损失值列表
for i in range(epochs):loss = model.getloss(xt,yt)losses.append(loss.item()) # 保存损失值中间状态optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播损失值optimizer.step() # 更新参数
avgloss = moving_average(losses) # 获得损失值的移动平均值
plt.figure(1)
plt.subplot(211)
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs Training loss')
plt.show()# 4 模型结果可视化,观察过拟合现象
plot_decision_boundary(lambda x: predict(model,x),X,Y)
from sklearn.metrics import accuracy_score
print("训练时的准确率",accuracy_score(model.predict(xt),yt))
# 重新生成两组半圆数据
Xtest,Ytest = sklearn.datasets.make_moons(80,noise=0.2)
plot_decision_boundary(lambda x: predict(model,x),Xtest,Ytest)
Xtest_t = torch.from_numpy(Xtest).type(torch.FloatTensor) # 将numpy数据转化为张量
Ytest_t = torch.from_numpy(Ytest).type(torch.LongTensor)
print("测试时准确率",accuracy_score(model.predict(Xtest_t),Ytest_t))4 数据集扩增(data augmentation)
4.1 数据集增广
增加数据集
4.2 通过增大数据集的方式改善过拟合的状况
4.2.1 修改Over_fitting.py 中的优化器部分
# 2 搭建网络模型
model = LogicNet(inputdim=2,hiddendim=500,outputdim=2) # 实例化模型,增加拟合能力将hiddendim赋值为500
optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器:反向传播过程中使用。# 3 训练模型+训练过程loss可视化
# xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
# yt = torch.from_numpy(Y).type(torch.LongTensor) # 将numpy数据转化为张量
# epochs = 1000 # 定义迭代次数
# losses = [] # 损失值列表
# for i in range(epochs):
# loss = model.getloss(xt,yt)
# losses.append(loss.item()) # 保存损失值中间状态
# optimizer.zero_grad() # 清空梯度
# loss.backward() # 反向传播损失值
# optimizer.step() # 更新参数
# avgloss = moving_average(losses) # 获得损失值的移动平均值# 修改为
epochs = 1000 # 定义迭代次数
losses = [] # 损失值列表
for i in range(epochs):X ,Y = sklearn.datasets.make_moons(40,noise=0.2)xt = torch.from_numpy(X).type(torch.FloatTensor)yt = torch.from_numpy(Y).type(torch.LongTensor)loss = model.getloss(xt,yt)losses.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()
4.2.2 Data_increase.py
import sklearn.datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
from LogicNet_fun import LogicNet,moving_average,predict,plot_decision_boundary# 1 构建数据集
np.random.seed(0) # 设置随机数种子
X , Y =sklearn.datasets.make_moons(40,noise=0.2) # 生成两组半圆形数据
arg = np.squeeze(np.argwhere(Y==0),axis=1) # 获取第1组数据索引
arg2 = np.squeeze(np.argwhere(Y==1),axis=1) # 获取第2组数据索引
# 显示数据
plt.title("train moons data")
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+',label = 'data1')
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o',label = 'data2')
plt.legend()
plt.show()# 2 搭建网络模型
model = LogicNet(inputdim=2,hiddendim=500,outputdim=2) # 实例化模型,增加拟合能力将hiddendim赋值为500
optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器:反向传播过程中使用。# 3 训练模型+训练过程loss可视化
# xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
# yt = torch.from_numpy(Y).type(torch.LongTensor) # 将numpy数据转化为张量
# epochs = 1000 # 定义迭代次数
# losses = [] # 损失值列表
# for i in range(epochs):
# loss = model.getloss(xt,yt)
# losses.append(loss.item()) # 保存损失值中间状态
# optimizer.zero_grad() # 清空梯度
# loss.backward() # 反向传播损失值
# optimizer.step() # 更新参数
# avgloss = moving_average(losses) # 获得损失值的移动平均值# 修改为
epochs = 1000 # 定义迭代次数
losses = [] # 损失值列表
for i in range(epochs):X ,Y = sklearn.datasets.make_moons(40,noise=0.2)xt = torch.from_numpy(X).type(torch.FloatTensor)yt = torch.from_numpy(Y).type(torch.LongTensor)loss = model.getloss(xt,yt)losses.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()plt.figure(1)
plt.subplot(211)
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs Training loss')
plt.show()# 4 模型结果可视化,观察过拟合现象
plot_decision_boundary(lambda x: predict(model,x),X,Y)
from sklearn.metrics import accuracy_score
print("训练时的准确率",accuracy_score(model.predict(xt),yt))
# 重新生成两组半圆数据
Xtest,Ytest = sklearn.datasets.make_moons(80,noise=0.2)
plot_decision_boundary(lambda x: predict(model,x),Xtest,Ytest)
Xtest_t = torch.from_numpy(Xtest).type(torch.FloatTensor) # 将numpy数据转化为张量
Ytest_t = torch.from_numpy(Ytest).type(torch.LongTensor)
print("测试时准确率",accuracy_score(model.predict(Xtest_t),Ytest_t))



:Dropout()方法)
![bzoj2435: [Noi2011]道路修建 树上dp](http://pic.xiahunao.cn/bzoj2435: [Noi2011]道路修建 树上dp)

:批量归一化)











