同学你好!本文章于2021年末编写,获得广泛的好评!
故在2022年末对本系列进行填充与更新,欢迎大家订阅最新的专栏,获取基于Pytorch1.10版本的理论代码(2023版)实现,
Pytorch深度学习·理论篇(2023版)目录地址为:
CSDN独家 | 全网首发 | Pytorch深度学习·理论篇(2023版)目录本专栏将通过系统的深度学习实例,从可解释性的角度对深度学习的原理进行讲解与分析,通过将深度学习知识与Pytorch的高效结合,帮助各位新入门的读者理解深度学习各个模板之间的关系,这些均是在Pytorch上实现的,可以有效的结合当前各位研究生的研究方向,设计人工智能的各个领域,是经过一年时间打磨的精品专栏!https://v9999.blog.csdn.net/article/details/127587345欢迎大家订阅(2023版)理论篇
以下为2021版原文~~~~

注意力机制可以使神经网络忽略不重要的特征向量,而重点计算有用的特征向量。在抛去无用特征对拟合结果于扰的同时,又提升了运算速度。
1 注意力机制
所谓Attention机制,便是聚焦于局部信息的机制,比如图像中的某一个图像区域。随着任务的变化,注意力区域往往会发生变化。

面对上面这样的一张图,如果你只是从整体来看,只看到了很多人头,但是你拉近一个一个仔细看就了不得了,都是天才科学家。
图中除了人脸之外的信息其实都是无用的,也做不了什么任务,Attention机制便是要找到这些最有用的信息,可以想见最简单的场景就是从照片中检测人脸了。
1.1 注意力机制的实现
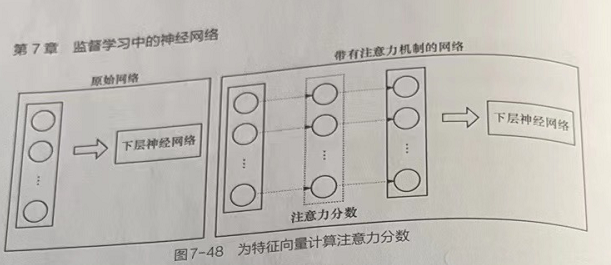
神经网络中的注意力机制主要是通过注意力分数来实现的。注意力分数是一个0-1的值,注意力机制作用下的所有分数和为1。每个注意力分数代表当前项被分配的注意力权重。
任意力分激常由神经网络的权重参数在模型的训练中学习得来,并最终使用Softmax函数进计算。这种机制可以作用在任何神经网络模型中。
(1)注意力机制可以作用在RNN模型中的每个序列上,令RNN模型对序列中的单个样本给予不同的关注度, 这种方式常用在RNN层的输出结果之后。

(2)注意力机制也可以作用在模型输出的特征向量上,这种针对特征向量进行注意力计算的方式适用范围更为广泛。该方式不但可以应用于循环神经网络,而且可以用于卷积神经网络,甚至图神经网络。
1.2 注意力控制的两种形式
1.2.1 软模式
所有数据均被主注意,计算相应的权重值,不设置筛选条件。
1.2.2 硬模式
在生成注意力权重之后删除一部分不符合条件的注意力,使其注意力权值为0,即不再注意不符合条件的部分。
1.3 注意力机制模型的原理
注意力机制模型是指完全使用注意力机制搭建起来的模型。注意力机制可以辅助其他神经网络,本身也具有拟合能力
1.3.1 数学模型的推导

1.3.2注意力机制模型的应用
注意力机制模型非常适合序列到序列(Sq2Sg)的拟合任务。例如,在实现文字阅读理解任务中,可以把文章当成Q。阅读理解的问题和答案当成K和V(形成键值对)。下面以个翻译任务为例,详细介绍其拟合过程。

1.4 多头注意力机制
注意力机制因2017年谷歌公司发表的一篇论文Attention is All You Need而受到广泛关注。多头注意力机制就是这篇论文中使用的主要技术之一。多头注意力机制是对原始注意力机制的改进。多头注意力机制可以表示为:Y=MultiHead(Q,K,V),Y代表多头注意力结果,其原理如图所示。
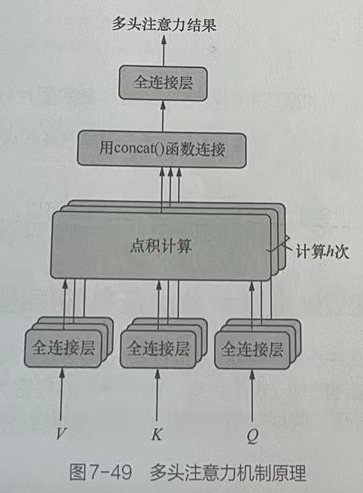
多头注意力机制的工作原理介绍如下。
- 把Q、K、V通过参数矩阵进行全连接层的映射转化。
- 对第(1)步中所转化的3个结果做点积运算。
- 将第(1)步和第(2)步重复运行h次,并且每次进行第(1)步操作时,都使用全新的参数矩阵(参数不共享)。
- 用concat()函数把计算h次之后的最终结果拼接起来。操作与多分支卷积技术非常相似,其理论可以解释为:每一次的注意力机制运算,都会使原数据中某个方面的特征发生注意力转化(得到部分注意力特征);当发生多次注意力机制运算之后,会得到更多方向的局部注意力特征;将所有的局部注意力特征合并起来,再通过神经网络将其转化为整体的特征,从达到拟合效果。
1.5 自注意力机制
自注意力机制,又称内部注意力机制,用于发现序列数据的内部特征。其具体做法是将Q、K、V都变成X,即计算Attention(X,X,X),这里的X代表待处理的输入数据。
使用多头注意力机制训练出的自注意力特征可以用于Seq2Seq模型(输入和输出都是序列数据的模型)、分类模型等各种任务,并能够得到很好的效果,即Y=MultiHead(X,X,X),Y代表多头注意力结果。
2 扩展
2.1 使用梯度剪辑技巧优化训练过程
2.1.1 梯度抖动的原因
梯度剪辑是一种训练模型的技巧,用来改善模型训练过程中抖动较大的问题:在模型使用反向传播训练的过程中,可能会出现梯度值剧烈抖动的情况。而某些优化器的学习率是通过策略算法在训练过程中自学习产生的。当参数值在较为“平坦”的区域进行更新时,由于该区域梯度值比较小,学习率一般会变得较大,如果突然到达了“陡峭”的区域,梯度值陡增,再与较大的学习率相乘,参数就有很大幅度的更新,因此学习过程非常不稳定。
2.1.2 梯度剪辑的具体做法
将反向求导的梯度值控制在一定区间之内,将超过区间的梯度值按照区间边界进行截断,这样,在训练过程中,权重参数的更新幅度就不会过大,使得模型更容易收敛。
2.1.3 在PyTorch中,实现梯度剪辑的三种方式
1.简单方式直接使用cclip_grad_value_()函数即可实现简单的梯度剪辑。
torch.nn.utils.clip_grad_value_(parameters=network.parameters(),clip_value=1.0)该代码可以将梯度按照[-1,1]区间进行剪辑。这种方法能设剪辑区间的上限和下限,且绝对值必须一致。如果想对区间的上限和下限设置不同的值,那么需要使用其他方法。
2.自定义方式可以使用钩子函数,为每一个参数单独指定剪辑区间。
for param in network.parameters():param.register_hook(lambda gradient:torch.clamp(gradient,-0.1,1.0))该代码为实例化后的模型权重添加了钩子函数,并在钩子函数内部实现梯度剪辑的设置。
这种方式最为灵活。在训练时,每当执行完反向传播(loss.backward)之后,所计算的梯度会触发钩子函数进行剪辑处理。
3.使用范数的方式
直接使用clip_grad_norm_()函数即可以范数的方式对梯度进行剪辑。
torch.nn.utils.clip_grad_norm_(network.parameters(),max_norm=1,norm_type=2)函数clip_grad_norm_()会迭代模型中的所有参数,并将它们的梯度当成向量进行统的范数处理。第2个参数值1表示最大范数,第3个参数值2表示使用L2范数的计算方法。
2.2 使用JANET单元完成RNN
在GitHub网站中,搜索pytorch-janet关键词,在使用时,只需要将pytorch-janet项目中的源码复制到本地,并在代码中导入。
在pytorch-janet项目中,JANET类的实例化参数与torch.nn.LSTM类完全一致,可以直接替换。如果要将LSTM模型替换成JANET,那么需要如下3步实现。
(1)将pytorch-janet项目中的源码复制到本地。
(2)在代码文件LSTMModel.py的开始处添加如下代码,导入JANET类。
from pytorch_janet import JANET(3)将代码文件LSTMModel.py中的torch.nn.LSTM替换成JANET。
2.3 使用indRNN单元实现RNN
在GitHub网站中,搜索indrnn-pytorch关键词,该项目中实现了两个版本的IndRNN单元。这两个版本的IndRNN接口分别为IndRNN、IndRNNv2类,可以直接替换torch.nn.LSTM类。


















![[haoi2011]防线修建](http://pic.xiahunao.cn/[haoi2011]防线修建)
