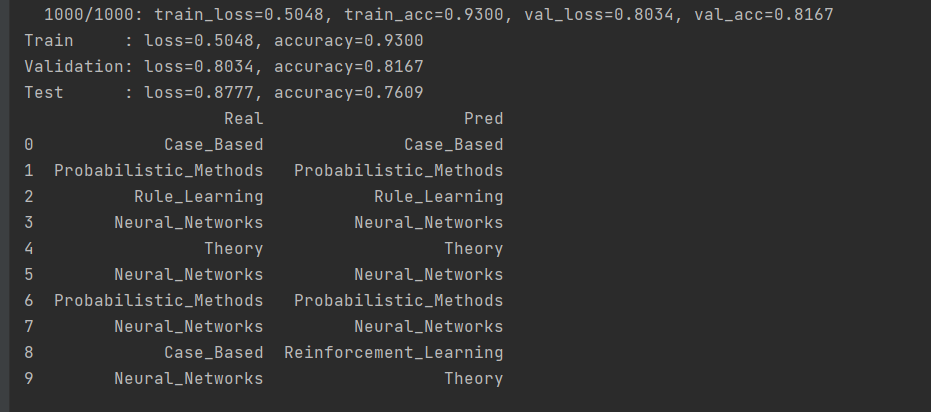
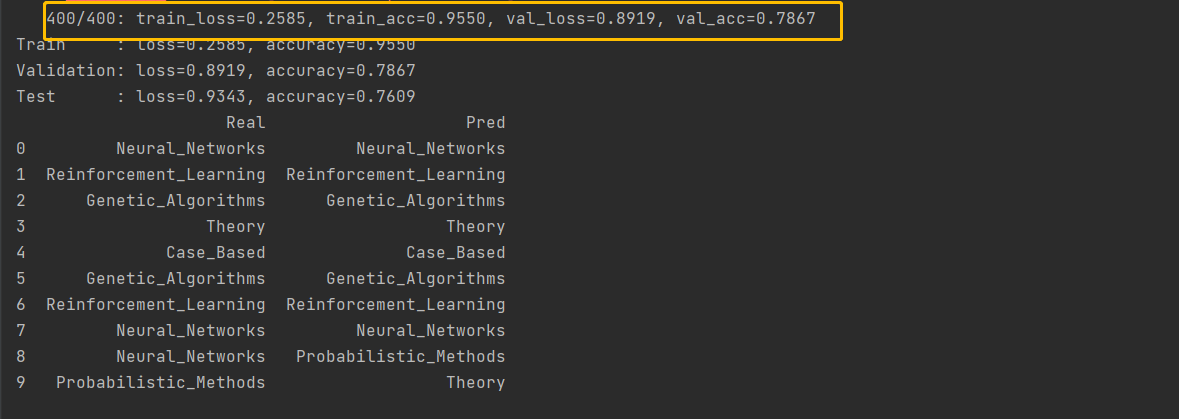
1 条件变分自编码神经网络生成模拟数据案例说明
在实际应用中,条件变分自编码神经网络的应用会更为广泛一些,因为它使得模型输出的模拟数据可控,即可以指定模型输出鞋子或者上衣。
1.1 案例描述
在变分自编码神经网络模型的技术上构建条件变分自编码神经网络模型,实现向模型输入标签,并使其生成与标签类别对应的模拟数据的功能。
1.2 条件变分自编码神经网络的实现条件
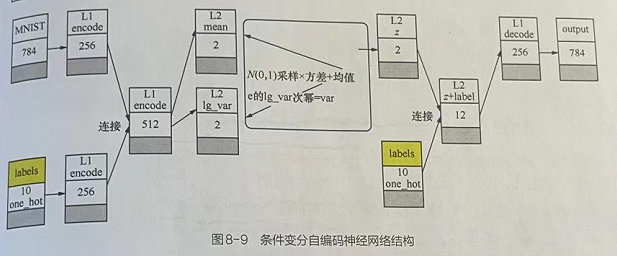
变分自编码神经网络在变分自编码神经网络基础之上,增加指导性条件。在编码阶段的输入端添加了与标签对应的特征,在解码阶段同样添加标签特征。这样,最终得到的模型将会把输入的标签特征当成原始数据的一部分,实现通过标签来生成可控模拟数据的效果。
在输入端添加标签时,一般是通过一个全连接层的变换将得到的结果连接到原始输入。
在解码阶段也将标签作为样本输入,与高斯分布的随机值一并运算,生成模拟样本。
1.2.1 条件变分自编码神经网络结构
2 实例代码编写
2.1 代码实战:引入模块并载入样本----Variational_cond_selfcoding.py(第1部分)
import torch
import torchvision
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import transforms
import numpy as np
from scipy.stats import norm # 在模型可视化时使用该库的norm接口从标准的高斯分布中获取数值
import matplotlib.pylab as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 可能是由于是MacOS系统的原因# 1.1 引入模块并载入样本:定义基础函数,并且加载FashionMNIST数据集
# 定义样本预处理接口
img_transform = transforms.Compose([transforms.ToTensor()])def to_img(x): # 将张量转化为图片x = 0.5 * (x + 1)x = x.clamp(0,1)x = x.reshape(x.size(0),1,28,28)return xdef imshow(img): # 显示图片npimg = img.numpy()plt.axis('off')plt.imshow(np.transpose(npimg,(1,2,0)))plt.show()data_dir = './fashion_mnist/' # 加载数据集
train_dataset = torchvision.datasets.FashionMNIST(data_dir,train=True,transform=img_transform,download=True)
# 获取训练数据集
train_loader = DataLoader(train_dataset,batch_size=128,shuffle=True)
# 获取测试数据集
val_dataset = torchvision.datasets.FashionMNIST(data_dir,train=False,transform=img_transform)
test_loader = DataLoader(val_dataset,batch_size=10,shuffle=False)
# 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("所使用的设备为:",device)2.2 代码实战:定义变分自编码神经网络的正向模型----Variational_cond_selfcoding.py(第2部分)
# 1.2 定义变分自编码神经网络模型的正向结构
class VAE(nn.Module):def __init__(self,hidden_1=256,hidden_2=256,in_decode_dim=2,hidden_3=256):super(VAE, self).__init__()self.fc1 = nn.Linear(784, hidden_1)self.fc21 = nn.Linear(hidden_2, 2)self.fc22 = nn.Linear(hidden_2, 2)self.fc3 = nn.Linear(in_decode_dim, hidden_3)self.fc4 = nn.Linear(hidden_3, 784)def encode(self,x): # 编码器方法:使用两层全连接网络将输入的图片进行压缩,对第二层中两个神经网络的输出结果代表均值(mean)与取对数(log)以后的方差(lg_var)。h1 = F.relu(self.fc1(x))return self.fc21(h1),self.fc22(h1)def reparametrize(self,mean,lg_var): # 采样器方法:对方差(lg_var)进行还原,并从高斯分布中采样,将采样数值映射到编码器输出的数据分布中。std = lg_var.exp().sqrt()# torch.FloatTensor(std.size())的作用是,生成一个与std形状一样的张量。然后,调用该张量的normal_()方法,系统会对该张量中的每个元素在标准高斯空间(均值为0、方差为1)中进行采样。eps = torch.FloatTensor(std.size()).normal_().to(device) # 随机张量方法normal_(),完成高斯空间的采样过程。return eps.mul(std).add_(mean)# 在torch.FloatTensor()# 函数中,传入Tensor的size类型,返回的是一个同样为size的张量。假如std的size为[batch,dim],则返回形状为[batch,dim]的未初始化张量,等同于torch.FloatTensor(# batch,dim),但不等同于torchFloatTensor([batch,dim),这是值得注意的地方。def decode(self,z): # 解码器方法:输入映射后的采样值,用两层神经网络还原出原始图片。h3 = F.relu(self.fc3(z))return self.fc4(h3)def forward(self,x,*arg): # 正向传播方法:将编码器,采样器,解码器串联起来,根据输入的原始图片生成模拟图片mean,lg_var = self.encode(x)z = self.reparametrize(mean=mean,lg_var=lg_var)return self.decode(z),mean,lg_var2.3 代码实战:损失函数与训练函数的完善----Variational_cond_selfcoding.py(第3部分)
# 1.3 完成损失函数和训练函数
reconstruction_function = nn.MSELoss(size_average=False)def loss_function(recon_x,x,mean,lg_var): # 损失函数:将MSE的损失缩小到一半,再与KL散度相加,目的在于使得输出的模拟样本可以有更灵活的变化空间。MSEloss = reconstruction_function(recon_x,x) # MSE损失KLD = -0.5 * torch.sum(1 + lg_var - mean.pow(2) - lg_var.exp())return 0.5 * MSEloss + KLDdef train(model,num_epochs = 50): # 训练函数optimizer = torch.optim.Adam(model.parameters(),lr=1e-3)display_step = 5for epoch in range(num_epochs):model.train()train_loss = 0for batch_idx, data in enumerate(train_loader):img,label = dataimg = img.view(img.size(0),-1).to(device)y_one_hot = torch.zeros(label.shape[0],10).scatter_(1,label.view(label.shape[0],1),1).to(device)optimizer.zero_grad()recon_batch, mean, lg_var = model(img, y_one_hot)loss = loss_function(recon_batch, img, mean, lg_var)loss.backward()train_loss += loss.dataoptimizer.step()if epoch % display_step == 0:print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(loss.data))print("完成训练 cost=",loss.data)2.4 代码实战:定义条件变分自编码神经网络模型----Variational_cond_selfcoding.py(第3部分)
# 1.4 定义条件变分自编码神经网络模型
class CondVAE(VAE): # 继承VAE类,实现条件变分自编码神经网络模型的正向结构。def __init__(self, hidden_1=256, hidden_2=512,in_decode_dim=2 + 10, hidden_3=256):super(CondVAE, self).__init__(hidden_1, hidden_2, in_decode_dim, hidden_3)self.labfc1 = nn.Linear(10, hidden_1)def encode(self, x, lab):h1 = F.relu(self.fc1(x))lab1 = F.relu(self.labfc1(lab))h1 = torch.cat([h1, lab1], axis=1)return self.fc21(h1), self.fc22(h1)def decode(self, z, lab):h3 = F.relu(self.fc3(torch.cat([z, lab], axis=1)))return self.fc4(h3)def forward(self, x, lab):mean, lg_var = self.encode(x, lab)z = self.reparametrize(mean, lg_var)return self.decode(z, lab), mean, lg_var
2.5 代码实战:训练模型并输出可视化结果----Variational_cond_selfcoding.py(第4部分)
# 1.5 训练模型并输出可视化结果
if __name__ == '__main__':model = CondVAE().to(device) # 实例化模型train(model, 50)# 将指定的one_hot标签输入模型,便可得到对应的模拟数据sample = iter(test_loader) # 取出10个样本,用于测试images, labels = sample.next()# 将标签转化为one_hot编码,取10个测试样本与标签。y_one_hots = torch.zeros(labels.shape[0], 10).scatter_(1, labels.view(labels.shape[0], 1), 1)# 将标签输入模型,生成模拟数据images2 = images.view(images.size(0), -1)with torch.no_grad():pred, mean, lg_var = model(images2.to(device), y_one_hots.to(device))pred = to_img(pred.cpu().detach()) # 将生成的模拟数据转化为图片print("标签值:", labels) # 输出标签# 标签值: tensor([9, 2, 1, 1, 6, 1, 4, 6, 5, 7])# 输出可视化结果z_sample = torch.randn(10, 2).to(device)x_decoded = model.decode(z_sample, y_one_hots.to(device)) # 将取得的10个标签与随机的高斯分布采样值z_sample一起输入模型,得到与标签相对应的模拟数据。rel = torch.cat([images, pred, to_img(x_decoded.cpu().detach())], axis=0)imshow(torchvision.utils.make_grid(rel, nrow=10))plt.show()# 根据标签生成模拟数据一共有3行图片,第1行是原始图片,第2行是将原始图片输入模型后所得到的模拟图片,第3行是将原始标签输入模型后生成的模拟图片。# 比较第2行和第3行图片可以看出,使用原始图片生成的模拟图片还会带有一些原来的样子,而使用标签生成的模拟图片已经学会了数据的分布规则,并能生成截然不同却带有相同意义的数据。
3 代码汇总(Variational_cond_selfcoding.py)
import torch
import torchvision
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import transforms
import numpy as np
from scipy.stats import norm # 在模型可视化时使用该库的norm接口从标准的高斯分布中获取数值
import matplotlib.pylab as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 可能是由于是MacOS系统的原因# 1.1 引入模块并载入样本:定义基础函数,并且加载FashionMNIST数据集
# 定义样本预处理接口
img_transform = transforms.Compose([transforms.ToTensor()])def to_img(x): # 将张量转化为图片x = 0.5 * (x + 1)x = x.clamp(0,1)x = x.reshape(x.size(0),1,28,28)return xdef imshow(img): # 显示图片npimg = img.numpy()plt.axis('off')plt.imshow(np.transpose(npimg,(1,2,0)))plt.show()data_dir = './fashion_mnist/' # 加载数据集
train_dataset = torchvision.datasets.FashionMNIST(data_dir,train=True,transform=img_transform,download=True)
# 获取训练数据集
train_loader = DataLoader(train_dataset,batch_size=128,shuffle=True)
# 获取测试数据集
val_dataset = torchvision.datasets.FashionMNIST(data_dir,train=False,transform=img_transform)
test_loader = DataLoader(val_dataset,batch_size=10,shuffle=False)
# 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("所使用的设备为:",device)# 1.2 定义变分自编码神经网络模型的正向结构
class VAE(nn.Module):def __init__(self,hidden_1=256,hidden_2=256,in_decode_dim=2,hidden_3=256):super(VAE, self).__init__()self.fc1 = nn.Linear(784, hidden_1)self.fc21 = nn.Linear(hidden_2, 2)self.fc22 = nn.Linear(hidden_2, 2)self.fc3 = nn.Linear(in_decode_dim, hidden_3)self.fc4 = nn.Linear(hidden_3, 784)def encode(self,x): # 编码器方法:使用两层全连接网络将输入的图片进行压缩,对第二层中两个神经网络的输出结果代表均值(mean)与取对数(log)以后的方差(lg_var)。h1 = F.relu(self.fc1(x))return self.fc21(h1),self.fc22(h1)def reparametrize(self,mean,lg_var): # 采样器方法:对方差(lg_var)进行还原,并从高斯分布中采样,将采样数值映射到编码器输出的数据分布中。std = lg_var.exp().sqrt()# torch.FloatTensor(std.size())的作用是,生成一个与std形状一样的张量。然后,调用该张量的normal_()方法,系统会对该张量中的每个元素在标准高斯空间(均值为0、方差为1)中进行采样。eps = torch.FloatTensor(std.size()).normal_().to(device) # 随机张量方法normal_(),完成高斯空间的采样过程。return eps.mul(std).add_(mean)# 在torch.FloatTensor()# 函数中,传入Tensor的size类型,返回的是一个同样为size的张量。假如std的size为[batch,dim],则返回形状为[batch,dim]的未初始化张量,等同于torch.FloatTensor(# batch,dim),但不等同于torchFloatTensor([batch,dim),这是值得注意的地方。def decode(self,z): # 解码器方法:输入映射后的采样值,用两层神经网络还原出原始图片。h3 = F.relu(self.fc3(z))return self.fc4(h3)def forward(self,x,*arg): # 正向传播方法:将编码器,采样器,解码器串联起来,根据输入的原始图片生成模拟图片mean,lg_var = self.encode(x)z = self.reparametrize(mean=mean,lg_var=lg_var)return self.decode(z),mean,lg_var# 1.3 完成损失函数和训练函数
reconstruction_function = nn.MSELoss(size_average=False)def loss_function(recon_x,x,mean,lg_var): # 损失函数:将MSE的损失缩小到一半,再与KL散度相加,目的在于使得输出的模拟样本可以有更灵活的变化空间。MSEloss = reconstruction_function(recon_x,x) # MSE损失KLD = -0.5 * torch.sum(1 + lg_var - mean.pow(2) - lg_var.exp())return 0.5 * MSEloss + KLDdef train(model,num_epochs = 50): # 训练函数optimizer = torch.optim.Adam(model.parameters(),lr=1e-3)display_step = 5for epoch in range(num_epochs):model.train()train_loss = 0for batch_idx, data in enumerate(train_loader):img,label = dataimg = img.view(img.size(0),-1).to(device)y_one_hot = torch.zeros(label.shape[0],10).scatter_(1,label.view(label.shape[0],1),1).to(device)optimizer.zero_grad()recon_batch, mean, lg_var = model(img, y_one_hot)loss = loss_function(recon_batch, img, mean, lg_var)loss.backward()train_loss += loss.dataoptimizer.step()if epoch % display_step == 0:print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(loss.data))print("完成训练 cost=",loss.data)# 1.4 定义条件变分自编码神经网络模型
class CondVAE(VAE): # 继承VAE类,实现条件变分自编码神经网络模型的正向结构。def __init__(self, hidden_1=256, hidden_2=512,in_decode_dim=2 + 10, hidden_3=256):super(CondVAE, self).__init__(hidden_1, hidden_2, in_decode_dim, hidden_3)self.labfc1 = nn.Linear(10, hidden_1)def encode(self, x, lab):h1 = F.relu(self.fc1(x))lab1 = F.relu(self.labfc1(lab))h1 = torch.cat([h1, lab1], axis=1)return self.fc21(h1), self.fc22(h1)def decode(self, z, lab):h3 = F.relu(self.fc3(torch.cat([z, lab], axis=1)))return self.fc4(h3)def forward(self, x, lab):mean, lg_var = self.encode(x, lab)z = self.reparametrize(mean, lg_var)return self.decode(z, lab), mean, lg_var# 1.5 训练模型并输出可视化结果
if __name__ == '__main__':model = CondVAE().to(device) # 实例化模型train(model, 50)# 将指定的one_hot标签输入模型,便可得到对应的模拟数据sample = iter(test_loader) # 取出10个样本,用于测试images, labels = sample.next()# 将标签转化为one_hot编码,取10个测试样本与标签。y_one_hots = torch.zeros(labels.shape[0], 10).scatter_(1, labels.view(labels.shape[0], 1), 1)# 将标签输入模型,生成模拟数据images2 = images.view(images.size(0), -1)with torch.no_grad():pred, mean, lg_var = model(images2.to(device), y_one_hots.to(device))pred = to_img(pred.cpu().detach()) # 将生成的模拟数据转化为图片print("标签值:", labels) # 输出标签# 标签值: tensor([9, 2, 1, 1, 6, 1, 4, 6, 5, 7])# 输出可视化结果z_sample = torch.randn(10, 2).to(device)x_decoded = model.decode(z_sample, y_one_hots.to(device)) # 将取得的10个标签与随机的高斯分布采样值z_sample一起输入模型,得到与标签相对应的模拟数据。rel = torch.cat([images, pred, to_img(x_decoded.cpu().detach())], axis=0)imshow(torchvision.utils.make_grid(rel, nrow=10))plt.show()# 根据标签生成模拟数据一共有3行图片,第1行是原始图片,第2行是将原始图片输入模型后所得到的模拟图片,第3行是将原始标签输入模型后生成的模拟图片。# 比较第2行和第3行图片可以看出,使用原始图片生成的模拟图片还会带有一些原来的样子,而使用标签生成的模拟图片已经学会了数据的分布规则,并能生成截然不同却带有相同意义的数据。