SKLEARN

Scikit-learn与特征工程
“数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这句话很好的阐述了数据在机器学习中的重要性。大部分直接拿过来的数据都是特征不明显的、没有经过处理的或者说是存在很多无用的数据,那么需要进行一些特征处理,特征的缩放等等,满足训练数据的要求。
Scikit-learn
Python语言的机器学习工具
所有人都适用,可在不同的上下文中重用
基于NumPy、SciPy和matplotlib构建
开源、商业可用 - BSD许可
目前稳定版本0.18
自2007年发布以来,scikit-learn已经成为最给力的Python机器学习库(library)了。scikit-learn支持的机器学习算法包括分类,回归,降维和聚类。还有一些特征提取(extracting features)、数据处理(processing data)和模型评估(evaluating models)的模块。作为Scipy库的扩展,scikit-learn也是建立在Python的NumPy和matplotlib库基础之上。NumPy可以让Python支持大量多维矩阵数据的高效操作,matplotlib提供了可视化工具,SciPy带有许多科学计算的模型。 scikit-learn文档完善,容易上手,丰富的API,使其在学术界颇受欢迎。开发者用scikit-learn实验不同的算法,只要几行代码就可以搞定。scikit-learn包括许多知名的机器学习算法的实现,包括LIBSVM和LIBLINEAR。还封装了其他的Python库,如自然语言处理的NLTK库。另外,scikit-learn内置了大量数据集,允许开发者集中于算法设计,节省获取和整理数据集的时间。
数据的特征工程
从数据中抽取出来的对预测结果有用的信息,通过专业的技巧进行数据处理,是的特征能在机器学习算法中发挥更好的作用。优质的特征往往描述了数据的固有结构。 最初的原始特征数据集可能太大,或者信息冗余,因此在机器学习的应用中,一个初始步骤就是选择特征的子集,或构建一套新的特征集,减少功能来促进算法的学习,提高泛化能力和可解释性。
例如:你要查看不同地域女性的穿衣品牌情况,预测不同地域的穿衣品牌。如果其中含有一些男性的数据,是不是要将这些数据给去除掉
特征工程的意义
更好的特征意味着更强的鲁棒性
更好的特征意味着只需用简单模型
更好的特征意味着更好的结果
特征工程之特征处理
特征工程中最重要的一个环节就是特征处理,特征处理包含了很多具体的专业技巧
特征预处理
单个特征
归一化
标准化
缺失值
多个特征
降维
PCA
特征工程之特征抽取与特征选择
如果说特征处理其实就是在对已有的数据进行运算达到我们目标的数据标准。特征抽取则是将任意数据格式(例如文本和图像)转换为机器学习的数字特征。而特征选择是在已有的特征中选择更好的特征。后面会详细介绍特征选择主要区别于降维。
数据的来源与类型
大部分的数据都来自已有的数据库,如果没有的话也可以交给很多爬虫工程师去采集,来提供。也可以来自平时的记录,反正数据无处不在,大都是可用的。
数据的类型
按照机器学习的数据分类我们可以将数据分成:
标称型:标称型目标变量的结果只在有限目标集中取值,如真与假(标称型目标变量主要用于分类)
数值型:数值型目标变量则可以从无限的数值集合中取值,如0.100,42.001等 (数值型目标变量主要用于回归分析)
按照数据的本身分布特性
离散型
连续型
那么什么是离散型和连续型数据呢?首先连续型数据是有规律的,离散型数据是没有规律的
离散变量是指其数值只能用自然数或整数单位计算的则为离散变量.例如,班级人数、进球个数、是否是某个类别等等
连续型数据是指在指定区间内可以是任意一个数值,例如,票房数据、花瓣大小分布数据
数据的特征抽取
现实世界中多数特征都不是连续变量,比如分类、文字、图像等,为了对非连续变量做特征表述,需要对这些特征做数学化表述,因此就用到了特征提取. sklearn.feature_extraction提供了特征提取的很多方法
分类特征变量提取
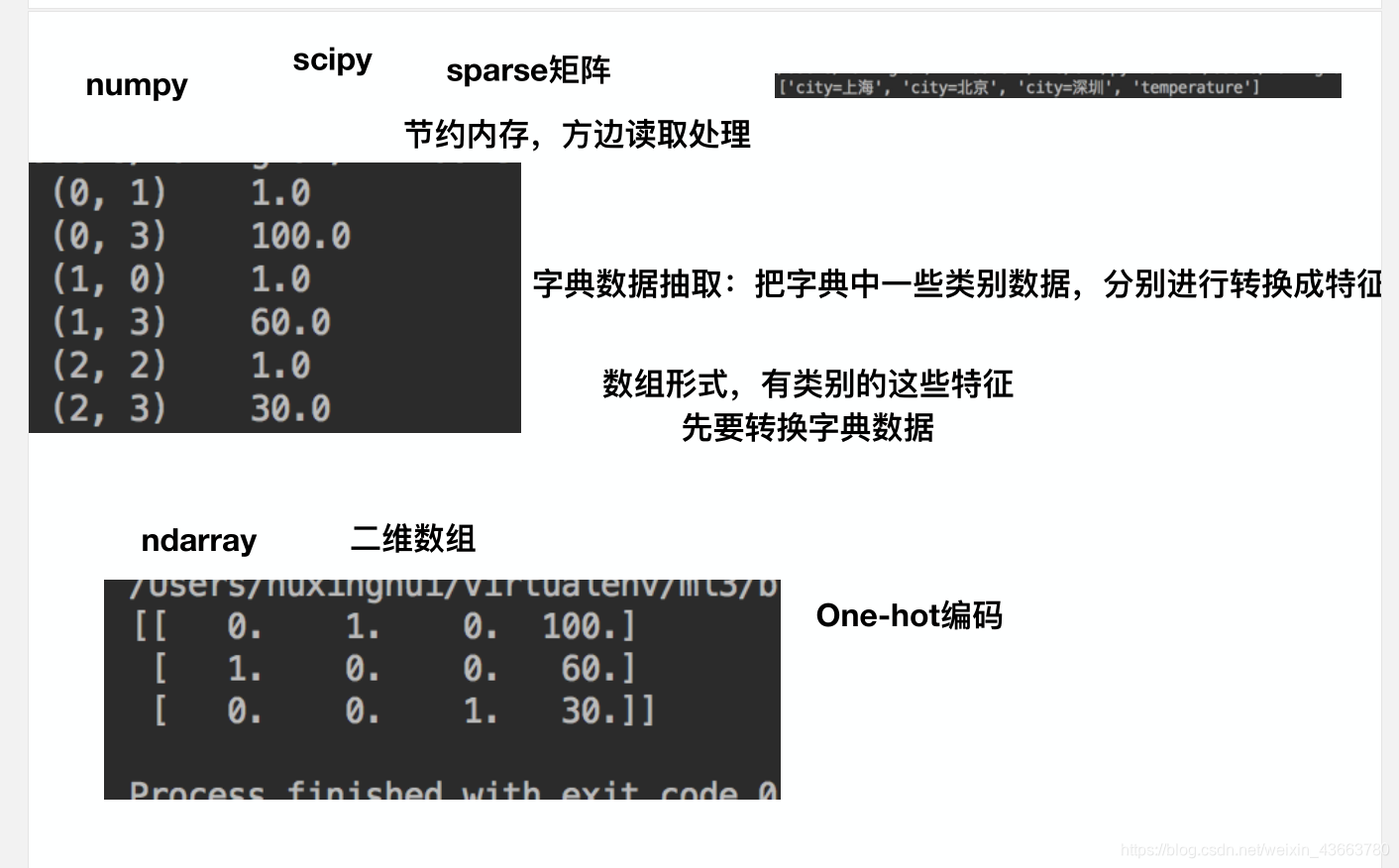
我们将城市和环境作为字典数据,来进行特征的提取。
sklearn.feature_extraction.DictVectorizer(sparse = True)
将映射列表转换为Numpy数组或scipy.sparse矩阵
sparse 是否转换为scipy.sparse矩阵表示,默认开启
方法
fit_transform(X,y)
应用并转化映射列表X,y为目标类型
inverse_transform(X[, dict_type])
将Numpy数组或scipy.sparse矩阵转换为映射列表
from sklearn.feature_extraction import DictVectorizer
onehot = DictVectorizer() # 如果结果不用toarray,请开启sparse=False
instances = [{'city': '北京','temperature':100},{'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]
X = onehot.fit_transform(instances).toarray()
print(onehot.inverse_transform(X))
文本特征提取(只限于英文)
文本的特征提取应用于很多方面,比如说文档分类、垃圾邮件分类和新闻分类。那么文本分类是通过词是否存在、以及词的概率(重要性)来表示。
(1)文档的中词的出现
数值为1表示词表中的这个词出现,为0表示未出现
sklearn.feature_extraction.text.CountVectorizer()
将文本文档的集合转换为计数矩阵(scipy.sparse matrices)
方法
fit_transform(raw_documents,y)
学习词汇词典并返回词汇文档矩阵
from sklearn.feature_extraction.text import CountVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = CountVectorizer()
print(vectorizer.fit_transform(content).toarray())
需要toarray()方法转变为numpy的数组形式
温馨提示:每个文档中的词,只是整个语料库中所有词,的很小的一部分,这样造成特征向量的稀疏性(很多值为0)为了解决存储和运算速度的问题,使用Python的scipy.sparse矩阵结构
(2)TF-IDF表示词的重要性
TfidfVectorizer会根据指定的公式将文档中的词转换为概率表示。(朴素贝叶斯介绍详细的用法)
class sklearn.feature_extraction.text.TfidfVectorizer()


方法
from sklearn.feature_extraction.text import TfidfVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = TfidfVectorizer(stop_words='english')
print(vectorizer.fit_transform(content).toarray())
print(vectorizer.vocabulary_)
fit_transform(raw_documents,y)
学习词汇和idf,返回术语文档矩阵

数据的特征预处理
单个特征
(1)归一化
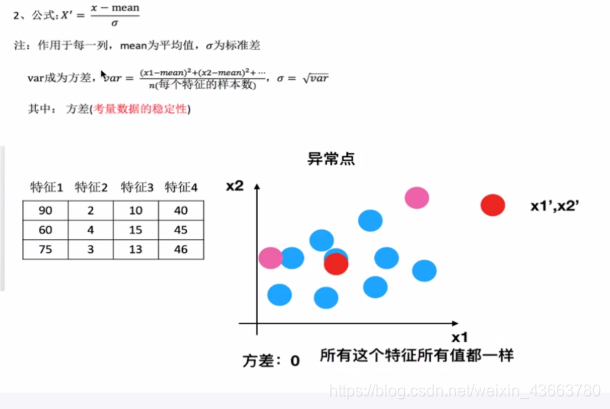
归一化首先在特征(维度)非常多的时候,可以防止某一维或某几维对数据影响过大,也是为了把不同来源的数据统一到一个参考区间下,这样比较起来才有意义,其次可以程序可以运行更快。 例如:一个人的身高和体重两个特征,假如体重50kg,身高175cm,由于两个单位不一样,数值大小不一样。如果比较两个人的体型差距时,那么身高的影响结果会比较大,k-临近算法会有这个距离公式。
min-max方法


常用的方法是通过对原始数据进行线性变换把数据映射到[0,1]之间,变换的函数为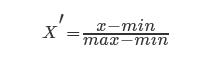
其中min是样本中最小值,max是样本中最大值,注意在数据流场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。

min-max自定义处理
这里我们使用相亲约会对象数据在MatchData.txt,这个样本时男士的数据,三个特征,玩游戏所消耗时间的百分比、每年获得的飞行常客里程数、每周消费的冰淇淋公升数。然后有一个 所属类别,被女士评价的三个类别,不喜欢、魅力一般、极具魅力。 首先导入数据进行矩阵转换处理
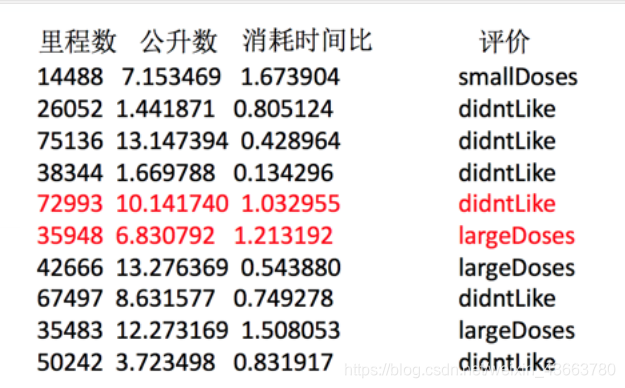
def data_matrix(file_name):"""将文本转化为matrix:param file_name: 文件名:return: 数据矩阵"""fr=open(file_name)array_lines=fr.readlines()number_lines=len(array_lines)return_mat=np.zeros((number_lines,3))index=0for line in array_lines:line=line.strip()#Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。list_line=line.split('\t')return_mat[index,:]=list_line[0:3]return return_mat
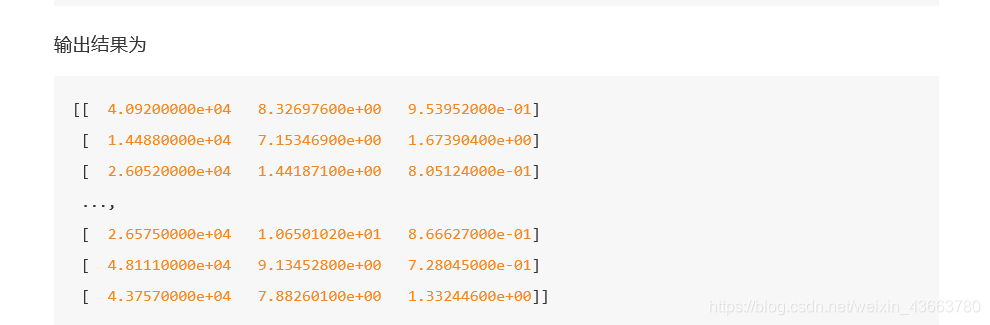
我们查看数据集会发现,有的数值大到几万,有的才个位数,同样如果计算两个样本之间的距离时,其中一个影响会特别大。也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的人觉得这三个特征同等重要,所以需要将数据进行这样的处理。
这样每个特征任意的范围将变成[0,1]的区间内的值,或者也可以根据需求处理到[-1,1]之间,我们再定义一个函数,进行这样的转换
def feature_normal(data_set):"""特征归一化:param data_set::return:"""#每列最小值min_vals=data_set.min(0)# 每列最大值max_vals = data_set.max(0)ranges=max_vals-min_valsnorm_data=np.zeros(np.shape(data_set))#得出行数m=data_set.shape[0]#1为列#矩阵相减norm_data=data_set-np.tile(min_vals,(m,1))#第一个参数为Y轴扩大倍数,第二个为X轴扩大倍数。本例中X轴扩大一倍便为不复制#矩阵相除norm_data=norm_data/np.tile(ranges,(m,1))return norm_data

(3)标准化


常用的方法是z-score标准化,经过处理后的数据均值为0,标准差为1,处理方法是:
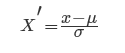
其中
μ\mu
μ是样本的均值,
σ\sigma
σ是样本的标准差,它们可以通过现有的样本进行估计,在已有的样本足够多的情况下比较稳定,适合嘈杂的数据场景
sklearn中提供了StandardScalar类实现列标准化

In [2]: import numpy as npIn [3]: X_train = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])In [4]: from sklearn.preprocessing import StandardScalerIn [5]: std = StandardScaler()In [6]: X_train_std = std.fit_transform(X_train)In [7]: X_train_std
Out[7]:
array([[ 0. , -1.22474487, 1.33630621],[ 1.22474487, 0. , -0.26726124],[-1.22474487, 1.22474487, -1.06904497]])
(3)缺失值
由于各种原因,许多现实世界的数据集包含缺少的值,通常编码为空白,NaN或其他占位符。然而,这样的数据集与scikit的分类器不兼容,它们假设数组中的所有值都是数字,并且都具有和保持含义。使用不完整数据集的基本策略是丢弃包含缺失值的整个行和/或列。然而,这是以丢失可能是有价值的数据(即使不完整)的代价。更好的策略是估算缺失值,即从已知部分的数据中推断它们。
(1)填充缺失值 使用sklearn.preprocessing中的Imputer类进行数据的填充
class Imputer(sklearn.base.BaseEstimator, sklearn.base.TransformerMixin)"""用于完成缺失值的补充:param param missing_values: integer or "NaN", optional (default="NaN")丢失值的占位符,对于编码为np.nan的缺失值,使用字符串值“NaN”:param strategy: string, optional (default="mean")插补策略如果是“平均值”,则使用沿轴的平均值替换缺失值如果为“中位数”,则使用沿轴的中位数替换缺失值如果“most_frequent”,则使用沿轴最频繁的值替换缺失:param axis: integer, optional (default=0)插补的轴如果axis = 0,则沿列排列如果axis = 1,则沿行排列
>>> import numpy as np
>>> from sklearn.preprocessing import Imputer
>>> imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
>>> imp.fit([[1, 2], [np.nan, 3], [7, 6]])
Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0)
>>> X = [[np.nan, 2], [6, np.nan], [7, 6]]
>>> print(imp.transform(X))
[[ 4. 2. ][ 6. 3.666...][ 7. 6. ]]
多个特征
降维
PCA(Principal component analysis),主成分分析。特点是保存数据集中对方差影响最大的那些特征,PCA极其容易受到数据中特征范围影响,所以在运用PCA前一定要做特征标准化,这样才能保证每维度特征的重要性等同
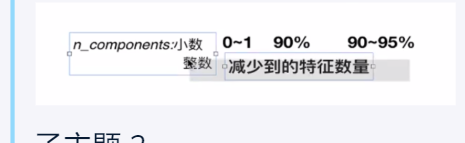
class PCA(sklearn.decomposition.base)"""主成成分分析:param n_components: int, float, None or string这个参数可以帮我们指定希望PCA降维后的特征维度数目。最常用的做法是直接指定降维到的维度数目,此时n_components是一个大于1的整数。我们也可以用默认值,即不输入n_components,此时n_components=min(样本数,特征数):param whiten: bool, optional (default False)判断是否进行白化。所谓白化,就是对降维后的数据的每个特征进行归一化。对于PCA降维本身来说一般不需要白化,如果你PCA降维后有后续的数据处理动作,可以考虑白化,默认值是False,即不进行白化:param svd_solver:选择一个合适的SVD算法来降维,一般来说,使用默认值就够了
>>> import numpy as np
>>> from sklearn.decomposition import PCA
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> pca = PCA(n_components=2)
>>> pca.fit(X)
PCA(copy=True, iterated_power='auto', n_components=2, random_state=None,svd_solver='auto', tol=0.0, whiten=False)
数据的特征选择
降维本质上是从一个维度空间映射到另一个维度空间,特征的多少别没有减少,当然在映射的过程中特征值也会相应的变化。举个例子,现在的特征是1000维,我们想要把它降到500维。降维的过程就是找个一个从1000维映射到500维的映射关系。原始数据中的1000个特征,每一个都对应着降维后的500维空间中的一个值。假设原始特征中有个特征的值是9,那么降维后对应的值可能是3。而对于特征选择来说,有很多方法:
Filter(过滤式):VarianceThreshold
Embedded(嵌入式):正则化、决策树
Wrapper(包裹式)
其中过滤式的特征选择后,数据本身不变,而数据的维度减少。而嵌入式的特征选择方法也会改变数据的值,维度也改变。Embedded方式是一种自动学习的特征选择方法,后面讲到具体的方法的时候就能理解了。
特征选择主要有两个功能:
(1)减少特征数量,降维,使模型泛化能力更强,减少过拟合
(2)增强特征和特征值之间的理解
sklearn.feature_selection
去掉取值变化小的特征(删除低方差特征)
VarianceThreshold 是特征选择中的一项基本方法。它会移除所有方差不满足阈值的特征。默认设置下,它将移除所有方差为0的特征,即那些在所有样本中数值完全相同的特征。

pca



字典数据提取
from sklearn.feature_extraction import DictVectorizerdef dictvec():"""字典数据抽取:return: None"""# 实例化dict=DictVectorizer(sparse=False)#调用fit_transformdata=dict.fit_transform([{'city': '北京','temperature': 100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}])print(dict.get_feature_names())print(dict.inverse_transform(data))print(data)return None['city=上海', 'city=北京', 'city=深圳', 'temperature']
[{'city=北京': 1.0, 'temperature': 100.0}, {'city=上海': 1.0, 'temperature': 60.0}, {'city=深圳': 1.0, 'temperature': 30.0}]
[[ 0. 1. 0. 100.][ 1. 0. 0. 60.][ 0. 0. 1. 30.]]
def dictvec():"""字典数据抽取:return: None"""# 实例化dict=DictVectorizer()#调用fit_transformdata=dict.fit_transform([{'city': '北京','temperature': 100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}])print(dict.get_feature_names())print(dict.inverse_transform(data))print(data)return None['city=上海', 'city=北京', 'city=深圳', 'temperature']
[{'city=北京': 1.0, 'temperature': 100.0}, {'city=上海': 1.0, 'temperature': 60.0}, {'city=深圳': 1.0, 'temperature': 30.0}](0, 1) 1.0(0, 3) 100.0(1, 0) 1.0(1, 3) 60.0(2, 2) 1.0(2, 3) 30.0文本进行特征化
from sklearn.feature_extraction.text import CountVectorizer
def countevc():"""对文本进行特征值化:return: None"""cv=CountVectorizer()data=cv.fit_transform(["人生 苦短,我 喜欢 python", "人生漫长,不用 python"])print(cv.get_feature_names())print(data.toarray())return None['python', '不用', '人生', '人生漫长', '喜欢', '苦短']
[[1 0 1 0 1 1][1 1 0 1 0 0]]中文分词
import jieba
def cutword():con1=jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")#转换成列表content1=list(con1)content2 = list(con2)content3 = list(con3)#转换成字符串c1 = ' '.join(content1)c2 = ' '.join(content2)c3 = ' '.join(content3)print(c1,c2,c3)return c1, c2 ,c3

中文特征值化
def hanzivec():"""中文特征值化:return: None"""c1,c2,c3=cutword()print(c1,c2,c3)cv=CountVectorizer()data=cv.fit_transform([c1,c2,c3])print(cv.get_feature_names())print(data.toarray())return None今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝对 大部分 是 死 在 明天 晚上 , 所以 每个 人 不要 放弃 今天 。 我们 看到 的 从 很 远 星系 来 的 光是在 几百万年 之前 发出 的 , 这样 当 我们 看到 宇宙 时 , 我们 是 在 看 它 的 过去 。 如果 只用 一种 方式 了解 某样 事物 , 你 就 不会 真正 了解 它 。 了解 事物 真正 含义 的 秘密 取决于 如何 将 其 与 我们 所 了解 的 事物 相 联系 。
['一种', '不会', '不要', '之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '取决于', '只用', '后天', '含义', '大部分', '如何', '如果', '宇宙', '我们', '所以', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '秘密', '绝对', '美好', '联系', '过去', '这样']
[[0 0 1 0 0 0 2 0 0 0 0 0 1 0 1 0 0 0 0 1 1 0 2 0 1 0 2 1 0 0 0 1 1 0 0 0][0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 3 0 0 0 0 1 0 0 0 0 2 0 0 0 0 0 1 1][1 1 0 0 4 3 0 0 0 0 1 1 0 1 0 1 1 0 1 0 0 1 0 0 0 1 0 0 0 2 1 0 0 1 0 0]]
中文分割特征处理
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
def tfidfvec():"""中文特征值化:return: None"""c1,c2,c3=cutword()print(c1,c2,c3)tf=TfidfVectorizer()data=tf.fit_transform([c1,c2,c3])print(tf.get_feature_names())print(data.toarray())return None今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝对 大部分 是 死 在 明天 晚上 , 所以 每个 人 不要 放弃 今天 。 我们 看到 的 从 很 远 星系 来 的 光是在 几百万年 之前 发出 的 , 这样 当 我们 看到 宇宙 时 , 我们 是 在 看 它 的 过去 。 如果 只用 一种 方式 了解 某样 事物 , 你 就 不会 真正 了解 它 。 了解 事物 真正 含义 的 秘密 取决于 如何 将 其 与 我们 所 了解 的 事物 相 联系 。
今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝对 大部分 是 死 在 明天 晚上 , 所以 每个 人 不要 放弃 今天 。 我们 看到 的 从 很 远 星系 来 的 光是在 几百万年 之前 发出 的 , 这样 当 我们 看到 宇宙 时 , 我们 是 在 看 它 的 过去 。 如果 只用 一种 方式 了解 某样 事物 , 你 就 不会 真正 了解 它 。 了解 事物 真正 含义 的 秘密 取决于 如何 将 其 与 我们 所 了解 的 事物 相 联系 。
['一种', '不会', '不要', '之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '取决于', '只用', '后天', '含义', '大部分', '如何', '如果', '宇宙', '我们', '所以', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '秘密', '绝对', '美好', '联系', '过去', '这样']
[[0. 0. 0.21821789 0. 0. 0.0.43643578 0. 0. 0. 0. 0.0.21821789 0. 0.21821789 0. 0. 0.0. 0.21821789 0.21821789 0. 0.43643578 0.0.21821789 0. 0.43643578 0.21821789 0. 0.0. 0.21821789 0.21821789 0. 0. 0. ][0. 0. 0. 0.2410822 0. 0.0. 0.2410822 0.2410822 0.2410822 0. 0.0. 0. 0. 0. 0. 0.24108220.55004769 0. 0. 0. 0. 0.24108220. 0. 0. 0. 0.48216441 0.0. 0. 0. 0. 0.2410822 0.2410822 ][0.15698297 0.15698297 0. 0. 0.62793188 0.470948910. 0. 0. 0. 0.15698297 0.156982970. 0.15698297 0. 0.15698297 0.15698297 0.0.1193896 0. 0. 0.15698297 0. 0.0. 0.15698297 0. 0. 0. 0.313965940.15698297 0. 0. 0.15698297 0. 0. ]]
归一化处理
from sklearn.preprocessing import MinMaxScalerdef mm():"""归一化处理:return: NOne"""mm=MinMaxScaler()data=mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])print(data)return None[[1. 0. 0. 0. ][0. 1. 1. 0.83333333][0.5 0.5 0.6 1. ]]
标准化
from sklearn.preprocessing import MinMaxScaler,StandardScaler
def stand():"""标准化缩放:return:"""std=StandardScaler()data=std.fit_transform([[ 1., -1., 3.],[ 2., 4., 2.],[ 4., 6., -1.]])print(data)return None[[-1.06904497 -1.35873244 0.98058068][-0.26726124 0.33968311 0.39223227][ 1.33630621 1.01904933 -1.37281295]]
缺失值处理
from sklearn.preprocessing import MinMaxScaler,StandardScaler,Imputer
import numpy as npdef im():"""缺失值处理:return:NOne"""# NaN, nanim=Imputer(missing_values='NaN',strategy='mean',axis=0)data=im.fit_transform([[1, 2], [np.nan, 3], [7, 6]])print(data)return None[[1. 2.]
C:\Users\HP\Anaconda3\lib\site-packages\sklearn\utils\deprecation.py:58: DeprecationWarning: Class Imputer is deprecated; Imputer was deprecated in version 0.20 and will be removed in 0.22. Import impute.SimpleImputer from sklearn instead.[4. 3.]warnings.warn(msg, category=DeprecationWarning)[7. 6.]]特征选择 删除低方差
from sklearn.feature_selection import VarianceThresholddef var():"""特征选择-删除低方差的特征:return: None"""var=VarianceThreshold(threshold=1.0)data= var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]])print(data)return None[[0][4][1]]PCA
def pca():"""主成分分析进行特征降维:return: None"""pca=PCA(n_components=0.9)data=pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])print(data)return None
[[ 1.22879107e-15 3.82970843e+00][ 5.74456265e+00 -1.91485422e+00][-5.74456265e+00 -1.91485422e+00]]